Apacheのアプリを調べてたところ、AzureDataFactoryのようなものを発見しました。
こちらになります。
SaaSではなく、コードベースになっているデータインテグレーションフレームワークになります。
まだ詳しくない状況ですが、GUI等がないので、直感的にわかりにくいです。
これを使う利点として、他のApacheのアプリと結合しやすい点ぐらいしか思い浮かばないのです。
早速ですが、上記のページの公式ドキュメントについて説明になります。
使うテストデータ
Apache Beamのところから適当に取得しました。
ここはセットしたいデータで問題ないです。
The SDK-provided Count transform is a generic transform that takes a PCollection of any type, and returns a PCollection of key/value pairs. Each key represents a unique element from the input collection, and each value represents the number of times that key appeared in the input collection.
In this pipeline, the input for Count is the PCollection of individual words generated by the previous ParDo, and the output is a PCollection of key/value pairs where each key represents a unique word in the text and the associated value is the occurrence count for each.
使うソースコード
公式のソースコードを使います。が、Goバージョンは現在一部の障害があります。
その点について最後に取り上げます。
package main
//https://beam.apache.org/get-started/quickstart-go/
import (
"context"
"flag"
"fmt"
"regexp"
"github.com/apache/beam/sdks/v2/go/pkg/beam"
"github.com/apache/beam/sdks/v2/go/pkg/beam/io/textio"
"github.com/apache/beam/sdks/v2/go/pkg/beam/runners/direct"
"github.com/apache/beam/sdks/v2/go/pkg/beam/transforms/stats"
_ "github.com/apache/beam/sdks/v2/go/pkg/beam/io/filesystem/local"
)
var (
input = flag.String("input", "data/*", "File(s) to read.")
output = flag.String("output", "outputs/wordcounts.txt", "Output filename.")
)
var wordRE = regexp.MustCompile(`[a-zA-Z]+('[a-z])?`)
func main() {
flag.Parse()
beam.Init()
pipeline := beam.NewPipeline()
root := pipeline.Root()
lines := textio.Read(root, *input)
words := beam.ParDo(root, func(line string, emit func(string)) {
for _, word := range wordRE.FindAllString(line, -1) {
emit(word)
}
}, lines)
counted := stats.Count(root, words)
formatted := beam.ParDo(root, func(word string, count int) string {
return fmt.Sprintf("%s: %v", word, count)
}, counted)
//https://github.com/apache/beam/issues/21998
textio.Write(root, *output, formatted)
direct.Execute(context.Background(), pipeline)
}
-
実行の引数として、
--inputと--outputを指定します。 -
Beamを初期化します。
beam.Init() -
PipeLineを定義します。
pipeline := beam.NewPipeline() root := pipeline.Root() -
Inputデータを指定します。
lines := textio.Read(root, *input) -
Inputデータから各単語単位で分割するジョブです。
words := beam.ParDo(root, func(line string, emit func(string)) { for _, word := range wordRE.FindAllString(line, -1) { emit(word) } }, lines) -
各単語が使われた回数を集計します。
counted := stats.Count(root, words) -
結果を出力するためのフォマットを設定します。
formatted := beam.ParDo(root, func(word string, count int) string { return fmt.Sprintf("%s: %v", word, count) }, counted) -
結果をファイルへ書き記みます。
textio.Write(root, *output, formatted) -
設定したバッチを実行します。
direct.Execute(context.Background(), pipeline)
結果
Goで実行することになると、無限ループに入ることになります。Commnad+Cで抜けられます。
ソースコードのどこが悪いかかと最初に思うかもしれませんが、どうやら別の問題のようです。
https://github.com/apache/beam/issues/21998
こちらの障害報告のチケットがありました。結果をファイルに書き込む際に無限ループに入ることになってそうです。
すぐ解決は出来無さそうですので原因について調べてます。そこはまた別の記事で扱います。
無限ループの途中に抜けた際の結果ですが、下記のようになります。
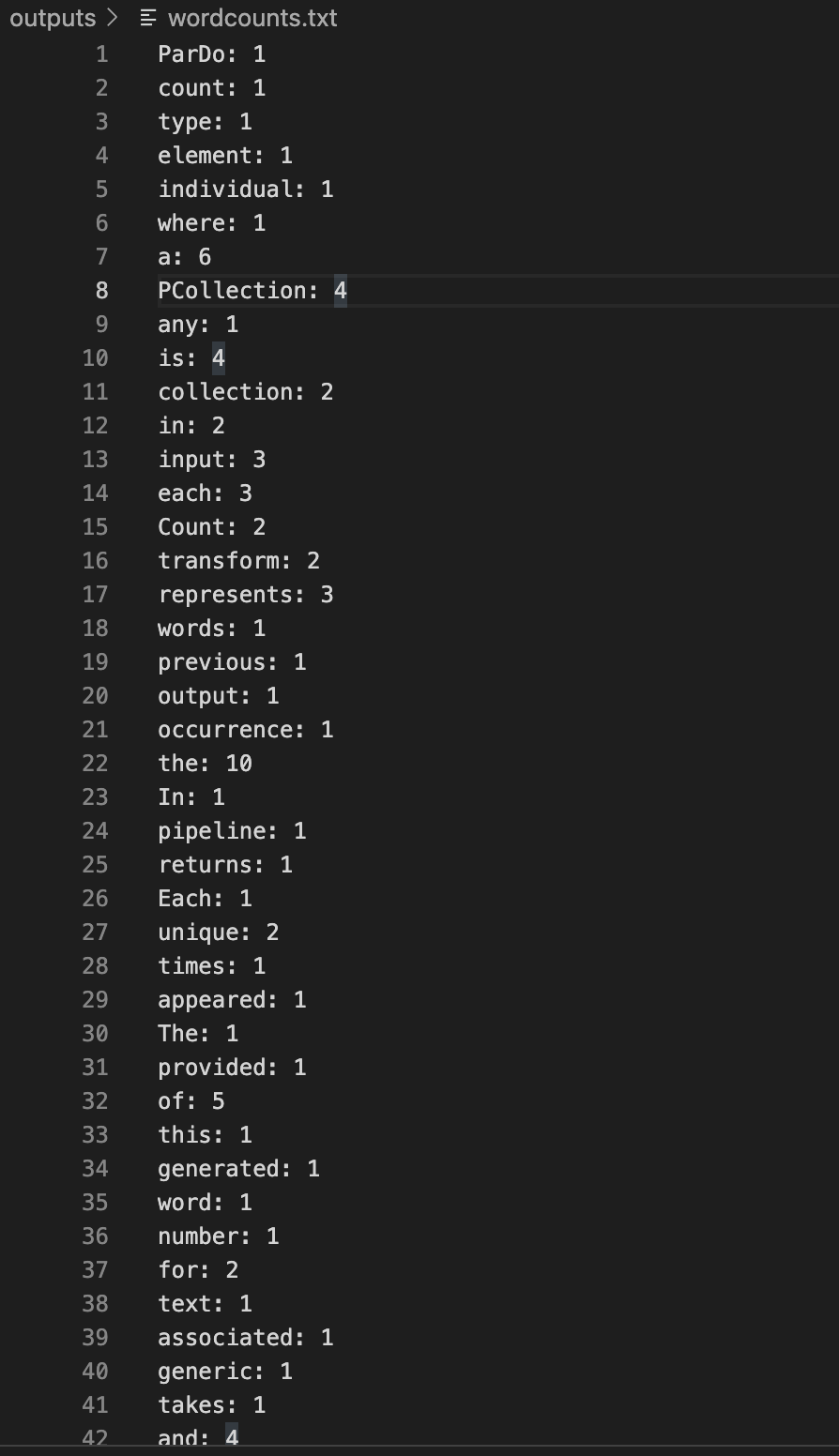
想定通り、各単語が使われた頻度が集計されておリます。
終わり
今回はBeamのTutorialを行い、動作確認レベルで実演してみました。Pipelineで行う操作についてソースコードで書くことでカスタマイズできるのでBatchシステムでも使えそうです。また、Triggerの設定でバッチが動くタイミングを設定もできると記載があります。上記の障害を調べながらApache BeamのLife Cycleや内部Systemについて少し気になったので次回はそこの確認をしたいと思います。