ChainerからPyTorchへ乗り換えるため、PyTorchを完全にいちから使い始めてみた結果。MNISTの手書き数字の識別を行う学習器をとりあえず作成(NNモデルはConv4層→FC2層)、動作を確認、98%前後の精度(Accuracy)となり、良好。
PyTorchのインストール試行
成功の模様。
https://pytorch.org/get-started/locally/
1.5 Stable、Windows、Python3.7、CUDAなし(CPU)の設定のコマンドを実行。
!pip install torch==1.5.0+cpu torchvision==0.6.0+cpu -f https://download.pytorch.org/whl/torch_stable.html
Looking in links: https://download.pytorch.org/whl/torch_stable.html
Collecting torch==1.5.0+cpu
Downloading https://download.pytorch.org/whl/cpu/torch-1.5.0%2Bcpu-cp37-cp37m-win_amd64.whl (109.2MB)
Collecting torchvision==0.6.0+cpu
Downloading https://download.pytorch.org/whl/cpu/torchvision-0.6.0%2Bcpu-cp37-cp37m-win_amd64.whl (456kB)
Requirement already satisfied: numpy in ...\wpy64-3741\python-3.7.4.amd64\lib\site-packages (from torch==1.5.0+cpu) (1.16.5+mkl)
Requirement already satisfied: future in ...\wpy64-3741\python-3.7.4.amd64\lib\site-packages (from torch==1.5.0+cpu) (0.17.0)
Requirement already satisfied: pillow>=4.1.1 in ...\wpy64-3741\python-3.7.4.amd64\lib\site-packages (from torchvision==0.6.0+cpu) (6.1.0)
Installing collected packages: torch, torchvision
Found existing installation: torch 1.3.1+cpu
Uninstalling torch-1.3.1+cpu:
Successfully uninstalled torch-1.3.1+cpu
Found existing installation: torchvision 0.4.2+cpu
Uninstalling torchvision-0.4.2+cpu:
Successfully uninstalled torchvision-0.4.2+cpu
Successfully installed torch-1.5.0+cpu torchvision-0.6.0+cpu
Note: you may need to restart the kernel to use updated packages.
WARNING: You are using pip version 19.2.3, however version 20.1 is available.
You should consider upgrading via the 'python -m pip install --upgrade pip' command.
!pip show torch
Name: torch
Version: 1.5.0+cpu
Summary: Tensors and Dynamic neural networks in Python with strong GPU acceleration
Home-page: https://pytorch.org/
Author: PyTorch Team
Author-email: packages@pytorch.org
License: BSD-3
Location: ...\wpy64-3741\python-3.7.4.amd64\lib\site-packages
Requires: future, numpy
Required-by: torchvision
Libs
import numpy as np
import matplotlib.pyplot as plt
import torch
import torchvision
PyTorch初歩試用
参考:
- https://qiita.com/miyamotok0105/items/1fd1d5c3532b174720cd
- https://qiita.com/north_redwing/items/30f9619f0ee727875250
- https://www.hellocybernetics.tech/entry/2017/10/19/070522
# sec: 行列生成のテスト
torch.rand(5, 3)
tensor([[0.7130, 0.1860, 0.6266],
[0.9275, 0.5629, 0.7507],
[0.7500, 0.7341, 0.9597],
[0.5301, 0.7026, 0.3152],
[0.2197, 0.3942, 0.8452]])
# sec: 勾配計算のテスト
x = torch.arange(4, dtype=torch.float32).view(2, 2)
print(x)
x.requires_grad_(True)
print(x)
y = x**2 - 2*x + 1
print(y)
y_ave = y.mean()
print(y_ave)
y_ave.backward()
print(x.grad)
print(y.grad)
tensor([[0., 1.],
[2., 3.]])
tensor([[0., 1.],
[2., 3.]], requires_grad=True)
tensor([[1., 0.],
[1., 4.]], grad_fn=<AddBackward0>)
tensor(1.5000, grad_fn=<MeanBackward0>)
tensor([[-0.5000, 0.0000],
[ 0.5000, 1.0000]])
None
torchvision初歩試用
# sec: MNISTデータの初回呼び出し ダウンロードのテスト
ds = torchvision.datasets.MNIST(root="trains/pytorch-mnist", train=True, download=True)
ds
Downloading http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz to trains/pytorch-mnist\MNIST\raw\train-images-idx3-ubyte.gz
HBox(children=(IntProgress(value=1, bar_style='info', max=1), HTML(value='')))
Extracting trains/pytorch-mnist\MNIST\raw\train-images-idx3-ubyte.gz to trains/pytorch-mnist\MNIST\raw
Downloading http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz to trains/pytorch-mnist\MNIST\raw\train-labels-idx1-ubyte.gz
HBox(children=(IntProgress(value=1, bar_style='info', max=1), HTML(value='')))
Extracting trains/pytorch-mnist\MNIST\raw\train-labels-idx1-ubyte.gz to trains/pytorch-mnist\MNIST\raw
Downloading http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz to trains/pytorch-mnist\MNIST\raw\t10k-images-idx3-ubyte.gz
HBox(children=(IntProgress(value=1, bar_style='info', max=1), HTML(value='')))
Extracting trains/pytorch-mnist\MNIST\raw\t10k-images-idx3-ubyte.gz to trains/pytorch-mnist\MNIST\raw
Downloading http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz to trains/pytorch-mnist\MNIST\raw\t10k-labels-idx1-ubyte.gz
HBox(children=(IntProgress(value=1, bar_style='info', max=1), HTML(value='')))
Extracting trains/pytorch-mnist\MNIST\raw\t10k-labels-idx1-ubyte.gz to trains/pytorch-mnist\MNIST\raw
Processing...
..\torch\csrc\utils\tensor_numpy.cpp:141: UserWarning: The given NumPy array is not writeable, and PyTorch does not support non-writeable tensors. This means you can write to the underlying (supposedly non-writeable) NumPy array using the tensor. You may want to copy the array to protect its data or make it writeable before converting it to a tensor. This type of warning will be suppressed for the rest of this program.
Done!
Dataset MNIST
Number of datapoints: 60000
Root location: trains/pytorch-mnist
Split: Train
# sec: MNISTデータの2回目呼び出し
ds = torchvision.datasets.MNIST(root="trains/pytorch-mnist", train=True, download=True)
ds
Dataset MNIST
Number of datapoints: 60000
Root location: trains/pytorch-mnist
Split: Train
# sec: MNISTデータのデータ取り出し・表示
img = np.asarray(ds[0][0])
print(img[20:25, 10:15], img.shape)
img = np.asarray(ds[0][0].convert('F'))
print(img[20:25, 10:15], img.shape)
plt.imshow(img, cmap='gray', interpolation='None')
plt.show()
[[ 24 114 221 253 253]
[213 253 253 253 253]
[253 253 253 195 80]
[253 244 133 11 0]
[132 16 0 0 0]] (28, 28)
[[ 24. 114. 221. 253. 253.]
[213. 253. 253. 253. 253.]
[253. 253. 253. 195. 80.]
[253. 244. 133. 11. 0.]
[132. 16. 0. 0. 0.]] (28, 28)
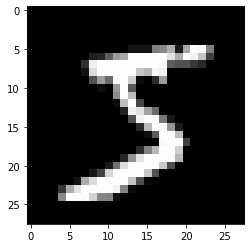
# sec: TorchのTensorを出力する
ds = torchvision.datasets.MNIST(root="trains/pytorch-mnist", train=True, download=True,
transform=torchvision.transforms.ToTensor())
# sec: MNISTデータのデータ取り出し・表示
img = ds[0][0]
print(img[0, 20:25, 10:15], ds[0][0].shape)
plt.imshow(img[0, :, :], cmap='gray', interpolation='None')
plt.show()
tensor([[0.0941, 0.4471, 0.8667, 0.9922, 0.9922],
[0.8353, 0.9922, 0.9922, 0.9922, 0.9922],
[0.9922, 0.9922, 0.9922, 0.7647, 0.3137],
[0.9922, 0.9569, 0.5216, 0.0431, 0.0000],
[0.5176, 0.0627, 0.0000, 0.0000, 0.0000]]) torch.Size([1, 28, 28])
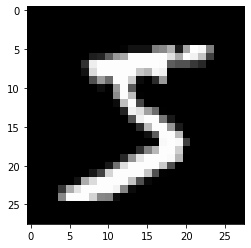
NNモデル
import torch.nn as nn
import torch.nn.functional as F
class MyConvNet1(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 5, 3, stride=1, padding=0)
self.conv2 = nn.Conv2d(5, 10, 3, stride=1, padding=0)
self.conv3 = nn.Conv2d(10, 15, 3, stride=1, padding=0)
self.conv4 = nn.Conv2d(15, 20, 3, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(5)
self.bn2 = nn.BatchNorm2d(10)
self.bn3 = nn.BatchNorm2d(15)
self.bn4 = nn.BatchNorm2d(20)
self.pool1 = nn.MaxPool2d(2)
self.pool2 = nn.MaxPool2d(2)
self.fc1 = nn.Linear(20*4*4, 20)
self.fc2 = nn.Linear(20, 10)
self.drop1 = nn.Dropout(0.5)
self.drop2 = nn.Dropout(0.5)
def forward(self, x):
x = F.relu(self.bn1(self.conv1(x)))
x = F.relu(self.bn2(self.conv2(x)))
x = self.pool1(x)
x = F.relu(self.bn3(self.conv3(x)))
x = F.relu(self.bn4(self.conv4(x)))
x = self.pool2(x)
x = x.view(-1, 20*4*4)
x = F.relu(self.fc1(self.drop1(x)))
x = self.fc2(self.drop2(x))
return x
TargetNet = MyConvNet1
# sec: test (順伝播計算 ゼロ値を入力)
model = TargetNet()
y = model(torch.zeros(1, 1, 28, 28))
print(y)
# sec: test (順伝播計算 MNISTデータを入力)
ds = torchvision.datasets.MNIST(root="trains/pytorch-mnist", train=True, download=True,
transform=torchvision.transforms.ToTensor())
y = model(ds[0][0].view(1, 1, 28, 28))
print(y)
tensor([[ 0.2101, 0.0317, -0.0457, -0.0219, 0.1032, 0.0080, -0.2413, -0.2003,
0.0222, -0.0821]], grad_fn=<AddmmBackward>)
tensor([[-0.1699, 0.5580, -0.1396, -0.6204, 0.3966, -0.0115, -0.0553, -0.0156,
-0.3096, -0.1288]], grad_fn=<AddmmBackward>)
学習
参考:
- https://qiita.com/fukuit/items/215ef75113d97560e599
- https://qiita.com/takurooo/items/e4c91c5d78059f92e76d
- https://qiita.com/kazetof/items/6a72926b9f8cd44c218e
# sec: データセット
ds_train = torchvision.datasets.MNIST(root="trains/pytorch-mnist", train=True, download=True,
transform=torchvision.transforms.ToTensor())
dl_train = torch.utils.data.DataLoader(ds_train, batch_size=128, shuffle=True, num_workers=2)
print(len(ds_train))
# sec: 設定
model = TargetNet()
criterion = nn.CrossEntropyLoss()
# case: SGD
# optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
# case: Adam
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# case: end
print(model)
60000
MyConvNet1(
(conv1): Conv2d(1, 5, kernel_size=(3, 3), stride=(1, 1))
(conv2): Conv2d(5, 10, kernel_size=(3, 3), stride=(1, 1))
(conv3): Conv2d(10, 15, kernel_size=(3, 3), stride=(1, 1))
(conv4): Conv2d(15, 20, kernel_size=(3, 3), stride=(1, 1))
(bn1): BatchNorm2d(5, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(bn2): BatchNorm2d(10, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(bn3): BatchNorm2d(15, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(bn4): BatchNorm2d(20, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(pool1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(pool2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(fc1): Linear(in_features=320, out_features=20, bias=True)
(fc2): Linear(in_features=20, out_features=10, bias=True)
(drop1): Dropout(p=0.5, inplace=False)
(drop2): Dropout(p=0.5, inplace=False)
)
# sec: 学習ループ
model.train()
for i_ep in range(10): # loop over the dataset multiple times
loss_sum = 0.0
for ds_i in dl_train:
inputs, labels = ds_i
optimizer.zero_grad()
outputs = model(inputs) # 順伝播
loss = criterion(outputs, labels)
loss.backward() # 逆伝播
optimizer.step()
loss_sum += loss.item()
# sec: print
print('%dep loss: %.5f' % (i_ep + 1, loss_sum / len(ds_train)))
n_ep = i_ep + 1
print('Finished Training')
1ep loss: 0.00700
2ep loss: 0.00359
3ep loss: 0.00310
4ep loss: 0.00290
5ep loss: 0.00272
6ep loss: 0.00258
7ep loss: 0.00247
8ep loss: 0.00243
9ep loss: 0.00237
10ep loss: 0.00232
Finished Training
バリデーション
# sec: データセット
ds_vali = torchvision.datasets.MNIST(root="trains/pytorch-mnist", train=True, download=True,
transform=torchvision.transforms.ToTensor())
ds_vali, _ = torch.utils.data.random_split(ds_vali, [1000, len(ds_vali) - 1000]) # イマイチな書き方
dl_vali = torch.utils.data.DataLoader(ds_vali, batch_size=128, shuffle=False, num_workers=2)
print(len(ds_vali))
1000
# sec: バリデーション例
model.eval() # 必要 trainのままだとdropoutの効果が残り精度劣化 90.0%で低迷
loss_sum = 0
n_correct = 0
for ds_i in dl_vali:
inputs, labels = ds_i
with torch.no_grad():
outputs = model(inputs) # 順伝播
loss = criterion(outputs, labels)
loss_sum += loss.item()
_, preds = torch.max(outputs, dim=1) # (max values, arg indices)
n_correct += (preds == labels).sum()
# sec: print
print('loss: %.2e, accuracy: %.2f' % (loss_sum / len(ds_vali), float(n_correct) / len(ds_vali) * 100))
loss: 2.43e-04, accuracy: 99.03
1回の評価結果
# sec: 画像を描画
ds_test = torchvision.datasets.MNIST(root="trains/pytorch-mnist", train=False, download=True,
transform=torchvision.transforms.ToTensor())
x, label = ds_test[np.random.randint(0, len(ds_test))]
plt.imshow(x[0], cmap='gray', interpolation="none")
plt.show()
# sec: 1回の評価
model.eval()
x = x[None] # 1軸を追加
with torch.no_grad():
y = model(x)
print("予測ラベル:", y.numpy().argmax(axis=1)[0], "| 真値ラベル:", label)
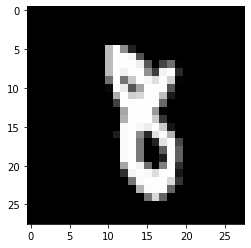
予測ラベル: 8 | 真値ラベル: 8
テスト
# sec: データセット
ds_test = torchvision.datasets.MNIST(root="trains/pytorch-mnist", train=False, download=True,
transform=torchvision.transforms.ToTensor())
dl_test = torch.utils.data.DataLoader(ds_test, batch_size=128, shuffle=False, num_workers=2)
print(len(ds_test))
10000
# sec: テスト例
model.eval()
loss_sum = 0
list_pred, list_label = [], []
for ds_i in dl_test:
inputs, labels = ds_i
with torch.no_grad():
outputs = model(inputs) # 順伝播
loss = criterion(outputs, labels)
loss_sum += loss.item()
_, preds = torch.max(outputs, dim=1) # (max values, arg indices)
list_pred.extend(preds)
list_label.extend(labels)
list_pred = np.array(list_pred)
list_label = np.array(list_label)
# sec: print
print('loss: %.2e, accuracy: %.2f' % (loss_sum / len(ds_test), (list_pred == list_label).sum() / len(ds_test) * 100))
loss: 2.84e-04, accuracy: 99.03
他のWeb記事のMNISTデータを用いる評価結果で「精度98.13%」程度なので、結果は妥当。
http://torch.classcat.com/2018/07/26/pytorch-040-examples-mnist-cnn/
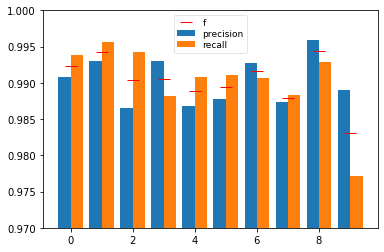
# sec: precision, recall, fscore, supportを見る
res_prf = sklearn.metrics.precision_recall_fscore_support(list_label, list_pred)
print("precision, recall, fscore, supportを見る:")
print(res_prf)
fig = plt.figure()
ax = fig.add_subplot(111)
ax.bar(np.arange(10) - 0.2, res_prf[0], width=0.4, label="precision")
ax.bar(np.arange(10) + 0.2, res_prf[1], width=0.4, label="recall")
ax.plot(np.arange(10), res_prf[2], 'r_', ms=12, label="f")
ax.legend(fontsize=9, framealpha=0.5, labelspacing=0.2)
ax.set_ylim([0.97, 1.0])
plt.show()
precision, recall, fscore, supportを見る:
(array([0.99084435, 0.99297012, 0.98653846, 0.99303483, 0.98681542,
0.9877095 , 0.99267782, 0.98736638, 0.99588054, 0.9889669 ]), array([0.99387755, 0.99559471, 0.99418605, 0.98811881, 0.99083503,
0.99103139, 0.99060543, 0.98832685, 0.99281314, 0.97720515]), array([0.99235863, 0.99428069, 0.99034749, 0.99057072, 0.98882114,
0.98936766, 0.99164054, 0.98784638, 0.99434447, 0.98305085]), array([ 980, 1135, 1032, 1010, 982, 892, 958, 1028, 974, 1009],
dtype=int64))
# sec: 混同行列を見る
sklearn.metrics.confusion_matrix(list_label, list_pred)
array([[ 974, 0, 1, 0, 0, 0, 4, 1, 0, 0],
[ 0, 1130, 4, 0, 0, 0, 0, 1, 0, 0],
[ 1, 0, 1026, 1, 0, 0, 0, 2, 2, 0],
[ 0, 0, 1, 998, 0, 5, 0, 4, 2, 0],
[ 0, 0, 0, 0, 973, 0, 1, 0, 0, 8],
[ 1, 0, 0, 4, 0, 884, 2, 1, 0, 0],
[ 3, 3, 0, 0, 0, 3, 949, 0, 0, 0],
[ 0, 5, 5, 1, 0, 0, 0, 1016, 0, 1],
[ 2, 0, 3, 0, 0, 0, 0, 0, 967, 2],
[ 2, 0, 0, 1, 13, 3, 0, 4, 0, 986]],
dtype=int64)
NNモデルパラメータ保存・読込評価
# sec: save
torch.save(model.state_dict(), "results/pytorch-mnist/model.pkl")
# sec: load
model_e = TargetNet()
model_e.load_state_dict(torch.load("results/pytorch-mnist/model.pkl"))
<All keys matched successfully>
model_e.state_dict()
OrderedDict([('conv1.weight', tensor([[[[-0.1193, -0.1967, 0.0337],
[-0.2103, 0.2067, 0.3707],
[-0.0072, 0.2572, -0.0811]]],
[[[ 0.2073, 0.0639, -0.2909],
[ 0.2432, -0.2954, -0.1945],
[ 0.0062, -0.1348, 0.1976]]],
[[[ 0.2244, 0.2394, 0.2029],
[ 0.0774, -0.1356, -0.1406],
[-0.1890, -0.1105, -0.2486]]],
[[[-0.0757, -0.1669, -0.3270],
[ 0.2795, 0.2242, 0.1612],
[-0.0702, 0.2889, 0.0423]]],
[[[-0.0672, 0.1286, -0.2042],
[-0.0348, -0.2120, -0.2940],
[-0.3711, -0.1960, 0.1867]]]])),
('conv1.bias',
tensor([ 0.0740, 0.0062, 0.1578, -0.1330, 0.2352])),
('conv2.weight', tensor([[[[-0.1560, -0.1605, -0.0265],
[ 0.2078, 0.0014, -0.1418],
[ 0.0111, 0.0764, -0.0443]],
[[-0.0406, -0.0301, -0.0977],
[-0.0876, -0.1847, -0.2042],
[ 0.0244, 0.1091, -0.1029]],
...(略)...
[[-1.2396e-01, -4.7989e-02, 6.0982e-03],
[ 1.0323e-01, 7.4295e-02, 4.4253e-02],
[ 1.0707e-01, 1.2724e-01, 1.9893e-01]],
[[-5.0636e-02, -1.1169e-01, -1.8197e-02],
[ 8.4612e-02, -4.1535e-02, 5.4119e-03],
[-5.3175e-03, -9.3789e-02, 2.2890e-02]],
[[ 7.8540e-02, -1.1353e-01, -1.2255e-01],
[ 1.1991e-02, -6.8789e-02, -1.7400e-01],
[ 9.7441e-05, -8.2435e-02, 4.7667e-03]]]])),
('conv4.bias',
tensor([ 0.0580, -0.0452, -0.0356, -0.0077, -0.0707, -0.0301, -0.0416, 0.0149,
0.1250, 0.0470, 0.0371, -0.0528, -0.0887, -0.0169, 0.0178, 0.0726,
-0.0794, 0.0061, -0.0065, 0.0043])),
('bn1.weight', tensor([0.9750, 1.0013, 0.9576, 0.9376, 1.2138])),
('bn1.bias',
tensor([-0.0668, -0.0248, 0.1255, 0.1388, 0.2274])),
('bn1.running_mean',
tensor([ 0.1101, -0.0276, 0.1465, -0.0831, 0.0740])),
('bn1.running_var',
tensor([0.0280, 0.0244, 0.0326, 0.0298, 0.0951])),
('bn1.num_batches_tracked', tensor(4690)),
('bn2.weight',
tensor([1.1731, 0.8839, 0.8436, 1.0764, 1.0680, 1.0759, 0.9479, 0.8768, 1.1014,
0.9595])),
('bn2.bias',
tensor([-2.8445e-01, -4.5570e-02, 2.4080e-04, -6.8240e-03, -1.9356e-02,
-9.8832e-02, -3.8079e-02, -1.0984e-01, -1.7605e-01, 1.1987e-01])),
('bn2.running_mean',
tensor([-0.2551, -0.3085, 0.6618, 0.3906, -0.5419, -0.8479, 0.0599, -0.3507,
-0.1456, -0.0181])),
('bn2.running_var',
tensor([0.2021, 0.7583, 0.4969, 0.4905, 0.2947, 0.1725, 0.2593, 0.2616, 0.2963,
0.2185])),
('bn2.num_batches_tracked', tensor(4690)),
('bn3.weight',
tensor([1.0696, 0.8160, 0.9060, 1.0633, 1.0389, 0.9895, 0.8915, 0.8183, 1.1316,
0.9516, 0.9707, 0.8907, 1.0231, 0.8617, 1.0554])),
('bn3.bias',
tensor([-0.2997, -0.0583, -0.2442, -0.0981, -0.2548, -0.2014, -0.1782, -0.2454,
-0.3477, -0.0327, -0.2671, -0.3008, -0.3205, -0.5982, -0.1280])),
('bn3.running_mean',
tensor([-0.9035, 0.2130, 0.2813, -1.3235, -0.5512, 0.0552, -0.1724, 0.1172,
-1.5437, -0.0501, -0.5553, -0.0547, -1.1366, 0.3776, -1.5574])),
('bn3.running_var',
tensor([0.6823, 0.9488, 0.7111, 1.3630, 1.0511, 0.8177, 1.0470, 1.0047, 1.1058,
1.9996, 1.1460, 1.3993, 1.0603, 0.4562, 1.7725])),
('bn3.num_batches_tracked', tensor(4690)),
('bn4.weight',
tensor([1.2947, 1.3268, 1.2583, 1.2611, 1.2759, 1.3348, 1.3097, 1.3204, 1.3608,
1.2124, 1.3248, 1.2563, 1.3738, 1.2736, 1.2208, 1.2850, 1.3084, 1.3131,
1.2993, 1.2804])),
('bn4.bias',
tensor([-0.5450, -0.5422, -0.3926, -0.4930, -0.5669, -0.4537, -0.5399, -0.5409,
-0.5684, -0.4720, -0.5032, -0.5454, -0.5353, -0.4670, -0.4292, -0.5145,
-0.3628, -0.6174, -0.5858, -0.4986])),
('bn4.running_mean',
tensor([ 0.4598, 0.2837, -0.1339, 0.0366, -0.3407, 0.1557, 0.2131, -0.6676,
0.0993, 0.9765, 0.7372, 0.2057, -0.3129, -0.2075, 0.2524, -0.2052,
0.7763, -0.3153, -0.8190, 0.8294])),
('bn4.running_var',
tensor([0.2823, 0.3211, 0.3877, 0.3735, 0.2755, 0.3754, 0.3229, 0.3310, 0.3055,
0.2756, 0.4847, 0.3380, 0.3030, 0.3383, 0.3769, 0.2427, 0.5124, 0.2893,
0.3855, 0.3065])),
('bn4.num_batches_tracked', tensor(4690)),
('fc1.weight',
tensor([[ 0.1167, 0.1003, 0.1363, ..., -0.0632, -0.1001, -0.1384],
[ 0.0219, 0.0128, 0.0546, ..., -0.0419, 0.0384, 0.1337],
[ 0.0895, 0.0410, 0.0538, ..., 0.0491, 0.0248, -0.1246],
...,
[ 0.0377, 0.0342, 0.0202, ..., -0.0412, 0.0019, 0.0041],
[ 0.0659, 0.0783, 0.0530, ..., 0.0059, 0.0661, 0.0319],
[ 0.0553, 0.0511, -0.0325, ..., 0.0109, -0.0564, -0.1748]])),
('fc1.bias',
tensor([-0.0930, -0.0096, -0.0934, -0.0489, 0.1413, 0.0640, 0.0702, 0.0313,
0.0491, 0.1809, 0.0214, -0.1256, 0.0015, 0.0511, 0.0580, 0.0494,
-0.0177, -0.0066, 0.0417, 0.0478])),
('fc2.weight',
tensor([[-0.3481, 0.1943, -0.1167, -0.3848, 0.2522, -0.5797, -0.3552, 0.2499,
-0.4902, 0.1876, -0.6010, 0.1155, 0.1638, -0.3284, -0.3364, 0.2158,
-0.3198, 0.1905, 0.2642, -0.1496],
[-0.4746, -0.5199, -0.3840, -0.2805, 0.2469, 0.2020, 0.2321, -0.3990,
0.2874, 0.2119, -0.4917, -0.2028, -0.3293, -0.4795, 0.2659, -0.4735,
-0.3607, -0.2774, -0.3733, 0.2061],
[ 0.1365, -0.1580, -0.2591, -0.1550, -0.3192, -0.4425, 0.2455, -0.2653,
-0.3550, -0.1905, 0.0099, 0.1221, 0.2218, -0.3097, 0.3020, -0.2191,
-0.3595, 0.1949, -0.2289, -0.3345],
[ 0.1819, -0.2019, -0.5650, 0.2102, -0.2937, -0.3966, 0.1748, -0.4076,
0.2246, 0.2166, 0.2953, -0.4493, 0.1728, -0.2740, -0.0933, 0.2476,
0.2063, -0.1891, -0.1732, -0.3121],
[-0.4458, -0.6537, 0.1651, 0.1682, -0.2137, 0.2296, 0.1956, 0.2499,
0.3215, -0.3628, 0.2233, 0.1229, -0.4657, 0.0259, -0.2530, -0.4996,
0.1364, -0.0745, -0.2714, -0.0395],
[ 0.1569, 0.2018, -0.2388, 0.1967, 0.2599, 0.1737, -0.4559, -0.2330,
-0.1793, -0.0934, -0.1260, -0.3630, -0.2875, -0.2901, -0.4317, 0.2435,
0.2380, -0.1329, 0.2140, 0.2101],
[-0.2263, -0.0485, 0.1833, -0.5683, 0.3253, -0.1906, -0.3670, 0.0325,
-0.2744, -0.3122, -0.4359, 0.1418, -0.3495, -0.6060, -0.4037, -0.1927,
0.2340, 0.2258, -0.2329, 0.2628],
[-0.2519, 0.1679, -0.3764, 0.1616, -0.3912, -0.3314, 0.2476, 0.1835,
-0.1459, 0.1911, 0.2524, -0.3639, -0.1660, 0.1537, 0.2604, -0.2612,
-0.4262, -0.3990, 0.2768, -0.5895],
[ 0.1794, 0.2254, 0.1708, -0.1893, -0.0620, -0.2753, -0.1750, -0.0990,
-0.1114, -0.3117, 0.2690, -0.2005, 0.1797, 0.1494, -0.3352, -0.1336,
-0.0673, 0.1785, -0.1971, 0.2140],
[ 0.1075, 0.0880, 0.1336, 0.1675, -0.3566, 0.1433, -0.1642, 0.2479,
0.2795, -0.3182, -0.2066, -0.1676, -0.2736, 0.1719, -0.2884, 0.1781,
-0.2009, -0.2304, 0.2601, -0.2920]])),
('fc2.bias',
tensor([-0.3426, 0.7404, 0.7441, -0.2981, -0.2907, -0.5408, -0.0061, 0.0115,
-0.1341, -0.0474]))])
# sec: データセット
ds_test = torchvision.datasets.MNIST(root="trains/pytorch-mnist", train=False, download=True,
transform=torchvision.transforms.ToTensor())
dl_test = torch.utils.data.DataLoader(ds_test, batch_size=128, shuffle=False, num_workers=2)
print(len(ds_test))
10000
# sec: 評価
model_e.eval()
loss_sum = 0
n_correct = 0
for ds_i in dl_test:
inputs, labels = ds_i
with torch.no_grad():
outputs = model_e(inputs) # 順伝播
loss = criterion(outputs, labels)
loss_sum += loss.item()
_, preds = torch.max(outputs, dim=1) # (max values, arg indices)
n_correct += (preds == labels).sum()
# sec: print
print('loss: %.2e, accuracy: %.2f' % (loss_sum / len(ds_test), float(n_correct) / len(ds_test) * 100))
loss: 2.43e-04, accuracy: 99.20
最適計算パラメータ保存・計算再開
# sec: save
torch.save({
'epoch': n_ep,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': loss },
"results/pytorch-mnist/model&opt.pkl")
ここでJupyterの実行中のPythonのカーネルをリスタート可。
Libs
import numpy as np
import matplotlib.pyplot as plt
import torch
import torchvision
NNモデモ
import torch.nn as nn
import torch.nn.functional as F
class MyConvNet1(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 5, 3, stride=1, padding=0)
self.conv2 = nn.Conv2d(5, 10, 3, stride=1, padding=0)
self.conv3 = nn.Conv2d(10, 15, 3, stride=1, padding=0)
self.conv4 = nn.Conv2d(15, 20, 3, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(5)
self.bn2 = nn.BatchNorm2d(10)
self.bn3 = nn.BatchNorm2d(15)
self.bn4 = nn.BatchNorm2d(20)
self.pool1 = nn.MaxPool2d(2)
self.pool2 = nn.MaxPool2d(2)
self.fc1 = nn.Linear(20*4*4, 20)
self.fc2 = nn.Linear(20, 10)
self.drop1 = nn.Dropout(0.5)
self.drop2 = nn.Dropout(0.5)
def forward(self, x):
x = F.relu(self.bn1(self.conv1(x)))
x = F.relu(self.bn2(self.conv2(x)))
x = self.pool1(x)
x = F.relu(self.bn3(self.conv3(x)))
x = F.relu(self.bn4(self.conv4(x)))
x = self.pool2(x)
x = x.view(-1, 20*4*4)
x = F.relu(self.fc1(self.drop1(x)))
x = self.fc2(self.drop2(x))
return x
TargetNet = MyConvNet1
# sec: load
model = TargetNet()
optimizer = torch.optim.Adam(model.parameters())
d = torch.load("results/pytorch-mnist/model&opt.pkl")
model.load_state_dict(d['model_state_dict'])
optimizer.load_state_dict(d['optimizer_state_dict'])
n_ep = d['epoch']
loss = d['loss']
# sec: 内容を確認
optimizer.state_dict()
{'state': {2202322517592: {'step': 4690,
'exp_avg': tensor([[[[ 4.9681e-03, -1.3392e-02, -1.1919e-02],
[-1.8946e-02, -1.5522e-02, 3.7579e-03],
[-2.7534e-02, -1.6930e-02, -3.9333e-05]]],
[[[ 8.3556e-03, 8.2333e-03, -4.6917e-03],
[ 8.6733e-03, 1.3580e-02, 1.3980e-03],
[-1.4740e-02, -1.8268e-02, -2.1180e-02]]],
[[[ 2.6981e-02, 2.1422e-02, 8.6973e-03],
[ 2.2680e-02, 2.4799e-02, 1.8023e-02],
[ 1.1921e-02, 1.9067e-02, 2.0821e-02]]],
[[[ 2.6852e-02, 2.1411e-02, 2.4557e-02],
[ 2.6102e-02, 1.6432e-02, 1.0814e-02],
[ 2.2461e-02, 9.3432e-03, -1.2549e-02]]],
[[[ 1.7876e-03, 3.0547e-03, 9.6555e-03],
[-2.2322e-03, -2.0686e-03, 2.5197e-03],
[-2.8117e-03, -6.4745e-03, -2.8697e-03]]]]),
'exp_avg_sq': tensor([[[[0.0133, 0.0118, 0.0097],
[0.0132, 0.0078, 0.0049],
[0.0131, 0.0075, 0.0063]]],
[[[0.0202, 0.0155, 0.0092],
[0.0155, 0.0083, 0.0045],
[0.0224, 0.0151, 0.0118]]],
[[[0.0066, 0.0051, 0.0060],
[0.0069, 0.0056, 0.0052],
[0.0061, 0.0047, 0.0038]]],
[[[0.0056, 0.0047, 0.0053],
[0.0032, 0.0026, 0.0039],
[0.0025, 0.0015, 0.0030]]],
[[[0.0048, 0.0020, 0.0013],
[0.0007, 0.0001, 0.0004],
[0.0001, 0.0003, 0.0017]]]])},
2202322517672: {'step': 4690,
'exp_avg': tensor([-1.5162e-06, -1.2697e-06, -1.2059e-07, -4.3583e-06, 6.9085e-07]),
'exp_avg_sq': tensor([8.3501e-10, 1.5377e-11, 3.3076e-12, 3.5197e-10, 6.3042e-12])},
2202322517272: {'step': 4690,
'exp_avg': tensor([[[[-3.1205e-03, 1.0635e-02, 1.7947e-02],
[ 3.0011e-02, 4.7265e-02, 5.7637e-02],
[ 4.3873e-02, 4.3586e-02, 5.4873e-02]],
[[ 1.4990e-02, 8.2882e-03, -5.3019e-04],
[ 6.4136e-03, 1.4983e-03, -3.0395e-03],
[ 9.1574e-04, -3.6870e-03, -1.4301e-02]],
[[ 1.5993e-02, 1.2531e-02, 8.5470e-03],
[-3.2829e-03, -3.5228e-03, -1.0266e-02],
[-2.1787e-03, -4.9055e-03, 8.4147e-03]],
[[ 1.3000e-02, 1.4188e-02, 2.3311e-02],
[ 5.2523e-02, 5.6909e-02, 6.5983e-02],
[ 7.4201e-02, 6.4654e-02, 5.4315e-02]],
[[-1.1624e-02, -1.2903e-02, -1.5316e-02],
[-2.2582e-02, -1.3517e-02, -1.4352e-02],
[-1.2509e-02, -1.4768e-02, -2.3715e-02]]],
...(略)...
2202322530536: {'step': 4690,
'exp_avg': tensor([ 0.0005, -0.0052, 0.0022, 0.0002, 0.0017, 0.0033, -0.0029, 0.0005,
-0.0030, 0.0028]),
'exp_avg_sq': tensor([0.0001, 0.0001, 0.0001, 0.0001, 0.0001, 0.0001, 0.0001, 0.0001, 0.0001,
0.0001])}},
'param_groups': [{'lr': 0.001,
'betas': (0.9, 0.999),
'eps': 1e-08,
'weight_decay': 0,
'amsgrad': False,
'params': [2202322517592,
2202322517672,
2202322517272,
2202322517192,
2202322516952,
2202322516792,
2202322517032,
2202322514152,
2202322489656,
2202322491896,
2202322492216,
2202322492296,
2202322492616,
2202322492696,
2202322493016,
2202322493096,
2202322493336,
2202322530376,
2202322530456,
2202322530536]}]}
最適化の内部の状態変数もすべて保存される模様。
学習ループ再開
# sec: データセット
ds_train = torchvision.datasets.MNIST(root="trains/pytorch-mnist", train=True, download=True,
transform=torchvision.transforms.ToTensor())
dl_train = torch.utils.data.DataLoader(ds_train, batch_size=128, shuffle=True, num_workers=2)
print(len(ds_train))
# sec: 学習再開
criterion = nn.CrossEntropyLoss()
model.train()
for i_ep in range(n_ep, n_ep + 10): # loop over the dataset multiple times
loss_sum = 0.0
for ds_i in dl_train:
inputs, labels = ds_i
optimizer.zero_grad()
outputs = model(inputs) # 順伝播
loss = criterion(outputs, labels)
loss.backward() # 逆伝播
optimizer.step()
loss_sum += loss.item()
# sec: print
print('%dep loss: %.5f' % (i_ep + 1, loss_sum / len(ds_train)))
n_ep = i_ep + 1
print('Finished Training')
11ep loss: 0.00227
12ep loss: 0.00225
13ep loss: 0.00220
14ep loss: 0.00220
15ep loss: 0.00215
16ep loss: 0.00211
17ep loss: 0.00207
18ep loss: 0.00207
19ep loss: 0.00204
20ep loss: 0.00204
Finished Training
初回学習では「10ep loss: 0.00232」で終わっていた状態。「11ep loss: 0.00227」から始まり、最適化の続きが開始されている模様。
# sec: データセット
ds_test = torchvision.datasets.MNIST(root="trains/pytorch-mnist", train=False, download=True,
transform=torchvision.transforms.ToTensor())
dl_test = torch.utils.data.DataLoader(ds_test, batch_size=128, shuffle=False, num_workers=2)
print(len(ds_test))
10000
# sec: テスト例
model.eval()
loss_sum = 0
list_pred, list_label = [], []
for ds_i in dl_test:
inputs, labels = ds_i
with torch.no_grad():
outputs = model(inputs) # 順伝播
loss = criterion(outputs, labels)
loss_sum += loss.item()
_, preds = torch.max(outputs, dim=1) # (max values, arg indices)
list_pred.extend(preds)
list_label.extend(labels)
list_pred = np.array(list_pred)
list_label = np.array(list_label)
# sec: print
print('loss: %.2e, accuracy: %.2f' % (loss_sum / len(ds_test), (list_pred == list_label).sum() / len(ds_test) * 100))
loss: 2.48e-04, accuracy: 99.03
他のWeb記事のMNISTデータを用いる評価結果で「精度98.13%」程度なので、結果は妥当。
http://torch.classcat.com/2018/07/26/pytorch-040-examples-mnist-cnn/
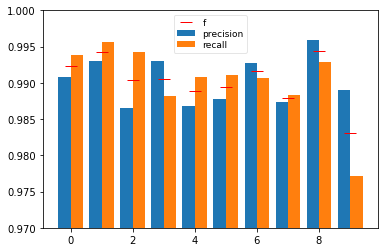
# sec: precision, recall, fscore, supportを見る
res_prf = sklearn.metrics.precision_recall_fscore_support(list_label, list_pred)
print("precision, recall, fscore, supportを見る:")
print(res_prf)
fig = plt.figure()
ax = fig.add_subplot(111)
ax.bar(np.arange(10) - 0.2, res_prf[0], width=0.4, label="precision")
ax.bar(np.arange(10) + 0.2, res_prf[1], width=0.4, label="recall")
ax.plot(np.arange(10), res_prf[2], 'r_', ms=12, label="f")
ax.legend(fontsize=9, framealpha=0.5, labelspacing=0.2)
ax.set_ylim([0.97, 1.0])
plt.show()
precision, recall, fscore, supportを見る:
(array([0.99084435, 0.99297012, 0.98653846, 0.99303483, 0.98681542,
0.9877095 , 0.99267782, 0.98736638, 0.99588054, 0.9889669 ]), array([0.99387755, 0.99559471, 0.99418605, 0.98811881, 0.99083503,
0.99103139, 0.99060543, 0.98832685, 0.99281314, 0.97720515]), array([0.99235863, 0.99428069, 0.99034749, 0.99057072, 0.98882114,
0.98936766, 0.99164054, 0.98784638, 0.99434447, 0.98305085]), array([ 980, 1135, 1032, 1010, 982, 892, 958, 1028, 974, 1009],
dtype=int64))
# sec: 混同行列を見る
sklearn.metrics.confusion_matrix(list_label, list_pred)
array([[ 974, 0, 1, 0, 0, 0, 4, 1, 0, 0],
[ 0, 1130, 4, 0, 0, 0, 0, 1, 0, 0],
[ 1, 0, 1026, 1, 0, 0, 0, 2, 2, 0],
[ 0, 0, 1, 998, 0, 5, 0, 4, 2, 0],
[ 0, 0, 0, 0, 973, 0, 1, 0, 0, 8],
[ 1, 0, 0, 4, 0, 884, 2, 1, 0, 0],
[ 3, 3, 0, 0, 0, 3, 949, 0, 0, 0],
[ 0, 5, 5, 1, 0, 0, 0, 1016, 0, 1],
[ 2, 0, 3, 0, 0, 0, 0, 0, 967, 2],
[ 2, 0, 0, 1, 13, 3, 0, 4, 0, 986]],
dtype=int64)
保存・読込
# sec: save
torch.save(model.state_dict(), "results/pytorch-mnist/model2.pkl")
# sec: load
model = TargetNet()
model.load_state_dict(torch.load("results/pytorch-mnist/model2.pkl"))
<All keys matched successfully>