はじめに
Watson Discovery News とは、情報検索・探索用APIであるWatson Discovery上にIBM(Watson)が自ら世界中の10万件を超えるニュースやブログのサイトの情報を収集し、情報サービスとして提供しているサービスになります。
Watson Discovery News の主な特徴は以下のとおりです。
・Publicな参照専用のコレクションでデータ登録の必要なしにすぐに活用可能
・IBMが選定した10万のニュースソース
・1日30万件のニュース・ブログ記事
・記事の保持期間は2か月間
現在世界で、何の情報がホットなのかひと目で確認することができ、グローバル・マーケティングや評判分析、最先端技術動向の調査として、既に多くの企業で利用されているソリューションとなります。
ここでは、Watson Discovery Newsの紹介を簡単にしたいと思います。
またWatson Discovery News はAPIベースでも利用することができます。
Discovery Newsでは何のサイトがクロールされているのは特許などの兼ね合いにより公開されていないことから、APIのサンプルとして「自分の興味あるサイトがその分析対象に入っているのか確認する方法も記載いたします。
1. Watson Discovery Newsとは
Watson Discovery Newsは、 自然言語の分析機能である「Watson Discovery」の1つの機能となります。Watson Discoveryについては以下のサイトなどを参考にしてください。
参考サイト:
・Watson Discovery News
・Watson Discovery Serviceが日本語対応したので、触ってみた【何、それ?】編
Watson Discoveryのサービスを IBM Cloud上で作成すると、Watson Discovery Newsも利用することが可能になります。
# IBM Cloudの利用方法とかはIBM Cloud デベロッパーズ・ラウンジとかを参照にしてください。

Queryの実行は、Watson Discovery Newsの管理画面上でも実行できますので、ぜひサンプルクエリーをベースに試してみてください。

またサービスを作成しなくても、デモ画面がこちらから利用できます。
こちらのサイトでは、自分の興味のある会社名を入れてみると、記事とかをみることができます。
Watson Discovery Demo
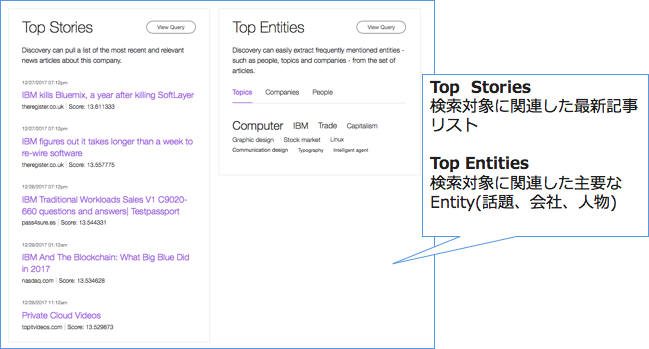
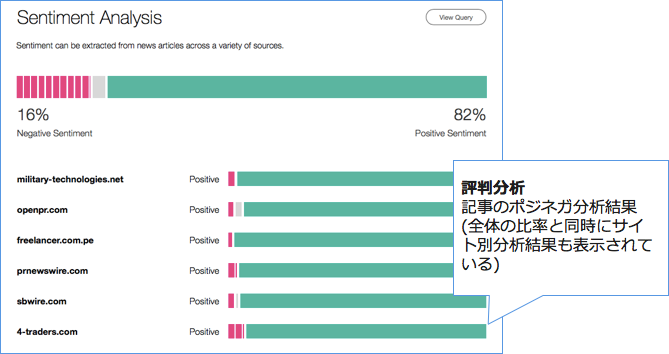
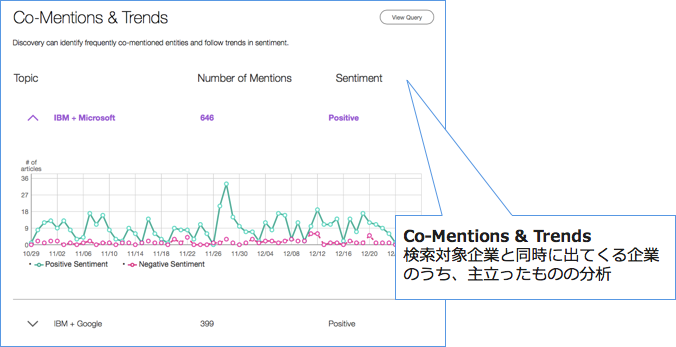
2.API実行方法(自分の興味あるサイトがクロールされているか確認する方法)
APIの実行例として、
Discovery Newsでは何のサイトがクロールされているの公開されておりませんので、ここでは自分に興味あるのサイトがクロールされているかチェックする方法について記載します。基本的には、Watson Discovery NewsのAPIを利用してcURLを使って確認するかたちとなります。
APIの利用方法はこちらに記載されております。
・Watson Discovery News
・APIドキュメント
・Watson Discovery サービスでのサンプル Watson News クエリー
2-1. Discovery-APIの基本系
cURLを使って、DiscoveryのAPIを利用する基本系は以下になります。
curl -u "{username}":"{password}" "https://gateway.watsonplatform.net/discovery/api/v1/environments/{environment_id}/collections/{collection_id}/query?version=2017-11-07&query=relations.action.lemmatized:acquire&count=15&filter=entities.text:IBM&return=text"
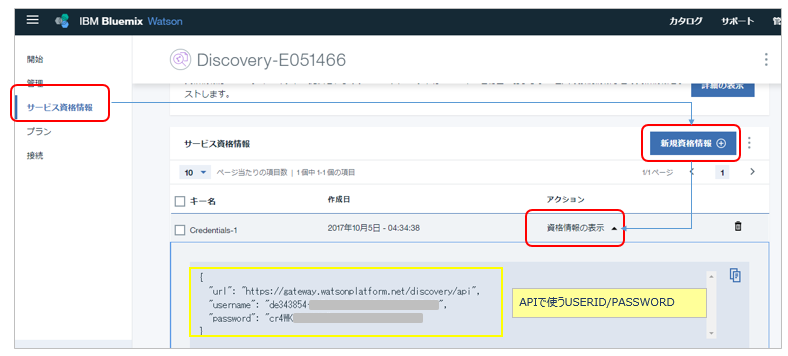
username, passwordの箇所には、ご自身で作成した「Watson Discovery」のサービス資格情報のユーザとパスワードを記載ください。
2-2 サンプルQuery
Queryのサンプルについては、Watson Discoveryの管理画面上でも確認できますので、是非参考にしてください。
2-3 特定のサイトに対して、文字列検索する方法
Watson Discovery NewsのAPIは、個別サイトに対して検索をすることが可能です。自分の興味あるサイトがに対して、そのサイトに記載しているであろう文言を検索することで、そのサイトがクロールされているかどうか確認することができます。
具体的には以下のコマンドになります。{検索する単語}に検索する単語を、{サイト名}に検索するサイトのURL(http://,https://は除く)を記載してください。count=1にすることで、1件の記事だけ結果として表示します。
curl -u "{username}":"{password}" 'https://gateway.watsonplatform.net/discovery/api/v1/environments/system/collections/news-en/query?version=2017-11-07&filter=text%3A%22{検索する単語}%22&count=1&query=host%3A%3Aa{サイト名}'
なお、URLの頭に "www." が頭に付く場合、それを取り除いてください。
https://www.nikkei.com -> nikkei.com
出力結果は、以下のようなjsonのかたちで出力され、matching_resultsに検索件数が出力されます。
{"matching_results":125,"results":[{"id":"XXXXX","result_metadata":
jqコマンドを利用するとmatching_resultsの件数だけ出力することができます。
curl -u "{username}":"{password}" 'https://gateway.watsonplatform.net/discovery/api/v1/environments/system/collections/news-en/query?version=2017-11-07&filter=text%3A%22{検索する単語}%22&count=1&query=host%3A%3Aa{サイト名}' | jq .matching_results
参考:一括確認方法
興味あるサイト一覧をファイル(web_list.txt)にリスト化すれば、以下のかたちで一括でcurlの確認コマンドの実行ファイルを作ることができます。
# !/bin/bash
sed -e "s/www\.//g" web_list.txt | while read line
do
echo $line
echo "curl -u \"{username}\":\"{password}\" 'https://gateway.watsonplatform.net/discovery/api/v1/environments/system/collections/news-en/query?version=2017-11-07&filter=text%3A%22{検索する単語}%22&count=1&query=host%3A%3A$line' | jq .matching_results >> num.txt"
done
おわりに
もし自分が興味あるサイトがクロールされていないような場合、IBMに対してリクエストすればクロール対象に加えてもらうことが可能なケースがございます。IBM営業などを介して、リクエストしてみてください。
Watson Discovery Newsを活用して、 マーケティング活動や企画立案などに活かしてください。