はじめに
前々回(前々回の記事はこちら)ではAutoML(Sony Prediction One)を使用し予測を出したが、今回はPythonを使って予測を出したい。
データサイエンス初学者の私でもハンズオンながら1つの成果物を作成したいと思い、前回、前々回記事同様にKaggleコンペのタイタニック生存者予測問題に挑戦したいと思う。
筆者のデータサイエンスに関連するスキル・経験
- 機械学習:独学レベル(書籍やサイト、無料動画を利用)
- 数学知識:大学1年生程度
- 統計学:大学1年生程度
- プログラミング:Excel VBA独学レベル(書籍やサイト、無料動画を利用)
※VBAエキスパート(Excelベーシック)取得 - ビジネス:前職で自社開発の業務効率化ツールを活用するための社内募集にて、担当業務の効率化を提案した経験あり(開発者と定期的に話し合いツール作成。今までの工数を半分にできた。)
ハンズオン資料
素晴らしいサイト記事を見つけたので、こちらを参考にハンズオンさせて頂く。
分析環境
- Python 3 (ipykemel)
- Pandas
- Numpy
- scikit-learn
- ChatGPT(調べ物に使用)
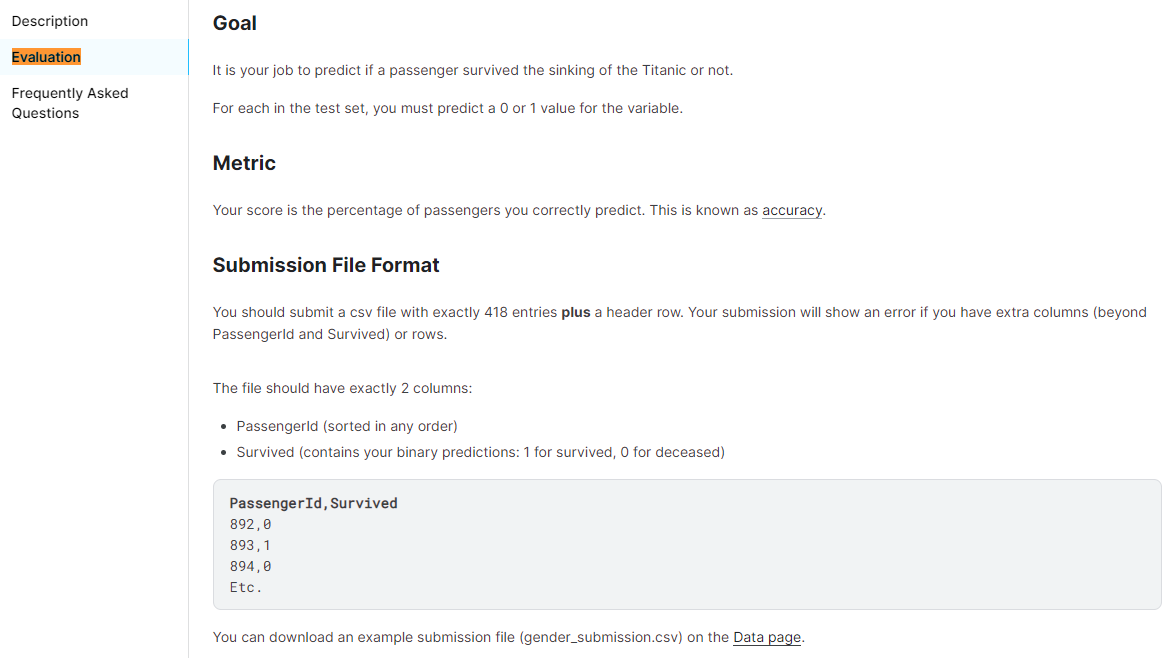
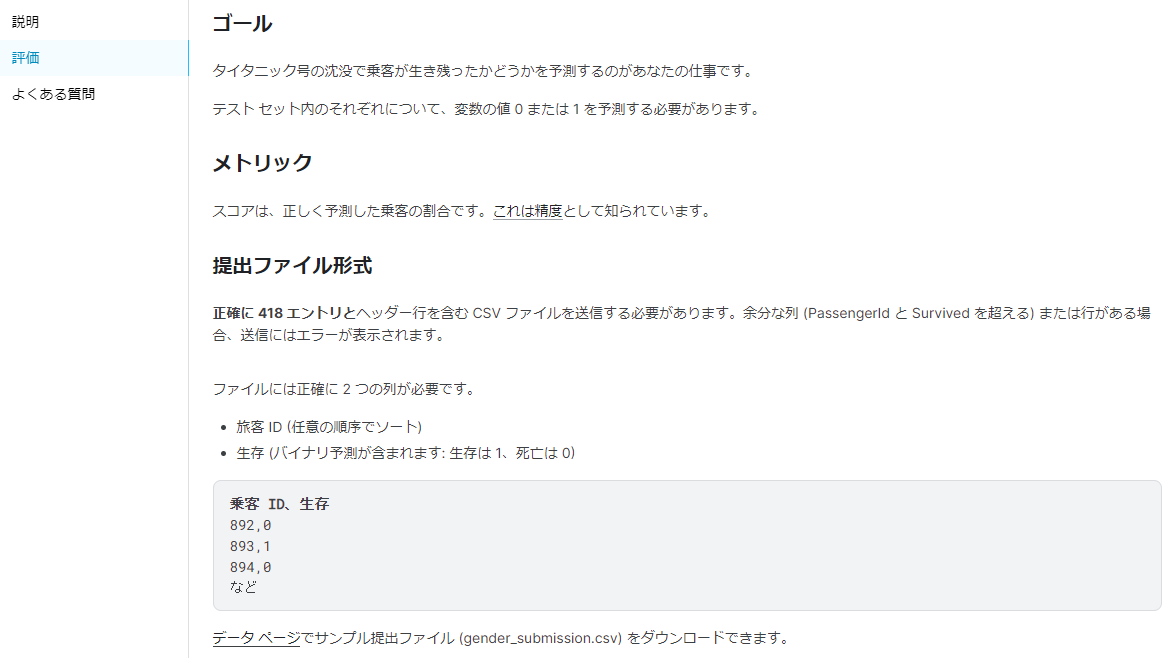
目次
データ処理の工程
以下のような工程でデータ分析を進めていく。
-
Kaggleからデータをダウンロードする。
-
ダウンロードしたデータをもとに、最適化したモデルを作成する。
-
2.で作成したモデルをもとに、別のデータに対してモデルを適用することで生存しているかを予測する。
-
Kaggleにアップロードして生存率(正答率)を判定する。
kaggleとは
Kaggleとは、主に機械学習モデルを構築するコンペティションのプラットフォームです。企業や研究機関などが提供す> るデータについて、世界中から集まる参加者が機械学習モデルの性能を競います。
(Kaggler-ja Wikiより抜粋)
今回のKaggleコンペの目的はタイタニック号の乗客の属性(性別、年齢など)から、生存を予測することである。
サイトはこちら
データをダウンロードする
- まず、データ分析を行う元となるデータをこちらのサイトからダウンロードする。

2. 次にダウンロードしたzipファイルを展開すると以下2つのファイルを入手できる。
- train.csv(学習用データ)
- test.csv(テスト用データ)
上記2つと同様にダウンロードしたファイル「gender_submission.csv」は回答例データであり、こちらをkaggleの提出場所へアップロードすると予測データの正解率が表示される。正答率は76%であった。
この正答率76%を基準とし、これよりも高い正答率を目指すこととなる。
また、提出する時のフォーマットであり、予測データファイルはこちらのフォーマットに合わせ提出する。
データセットの確認
CSVを読み込む
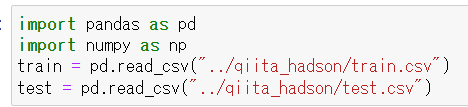
PandasとNumpyを使い上記でダウンロードした「train.csv」「test.csv」をデータフレーム形式で読み込む。
CSVの格納先はディレクトリは任意に指定しする。
■Pandas:
PandasはPythonのデータ操作および分析ライブラリであり、高速で柔軟なデータ構造を提供する。主なデータ構造はDataFrameとSeriesであり、テーブルのような形式でデータを操作する。Pandasはデータの読み込みや書き出し、欠損値の処理、データのフィルタリングや集計などの機能を提供し、データの前処理や特徴エンジニアリングに広く使用される。
■Nump:
NumPy(Numerical Python)は、Pythonの数値計算を効率的に行うためのライブラリである。主要なデータ構造は多次元配列であり、高速な数値演算や行列操作が可能。NumPyは科学計算やデータ処理の領域で広く使用され、他の数値計算やデータ分析ライブラリ(Pandasなど)との統合も提供している。
各csvに何が含まれているか確認する。
まずはtrain.csvを確認する。
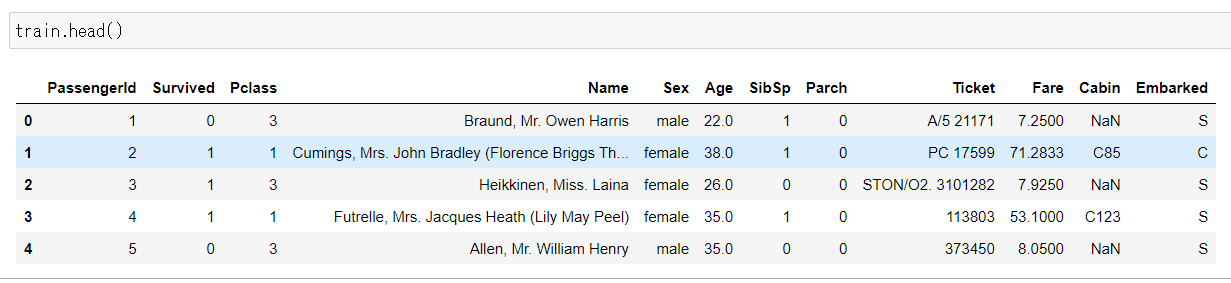
Pandasのhead()を使うと、データフレームの最上部5段がデフォルトで表示される。
つまり、上の表は「train.csv」のカラム(列)名と最上部5段の情報となる。
各カラム(列)の簡単な説明をは以下の通り。
| 属性 | 内容 |
|---|---|
| PassengerId | 乗客ID |
| Survived | 生死(0 = No; 1 = Yes)※train.csvのみに存在。test.csvのこの値を予測する。 |
| Pclass | 乗客の社会階級(1 = 1st(High); 2 = 2nd(Middle); 3 = 3rd(Low)) |
| Name | 乗客の氏名 |
| Sex | 性別 |
| Age | 年齢 |
| SibSp | 船船している夫婦、兄弟姉妹の数 |
| Parch | 乗船している親、子供の数 |
| Ticket | チケットNo |
| Fare | 乗船料金 |
| Cabin | 客室番号 |
| Embarked | 出港地(タイタニックへ乗った港)(C = Cherbourg; Q = Queenstown; S = Southampton) |
以上が訓練データとして提供されている項目となる。さらに各変数の簡単な説明も記載する。
■pclass = 社会階級
1 = 上層クラス(高い社会的地位を持つ人々や富裕層)
2 = 中級クラス(一般的な中間の社会的地位を持つ人々)
3 = 下層クラス(社会的に低い地位や経済的に困難な状況にある人々)
■Embarked = 各変数の定義
C = Cherbourg
Q = Queenstown
S = Southampton
次にtest.csvを確認する。
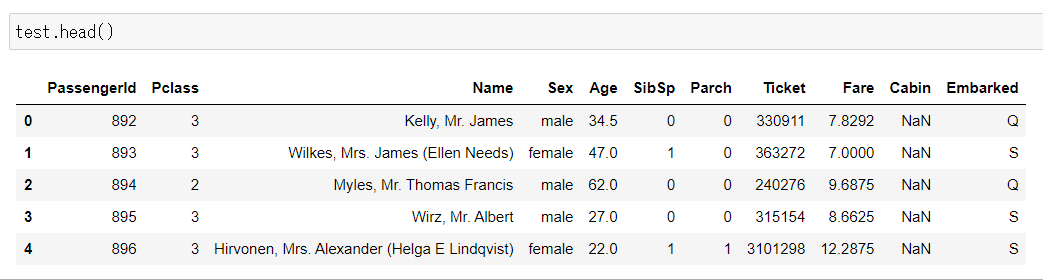
こちらのtest.csvにはSurvivedのカラムが無いのが確認できる。それ以外ののカラムはtrain.csvと同様である。
つまり、train.csvの乗客の情報と「Survived(生存したかどうか)」の回答を機械学習して、test.csvで提供されている乗客情報を元に生存したか死亡したかの予測を作成することが課題ということである。
train.csvとtest.csvの簡単な統計情報とサイズも確認しておく。

train.csvは891名の乗客情報であり、test.csv418名の乗客情報である。
カラム数が異なるのは、前述したがtrain.csvには「Survived」のカラムがあるからである。
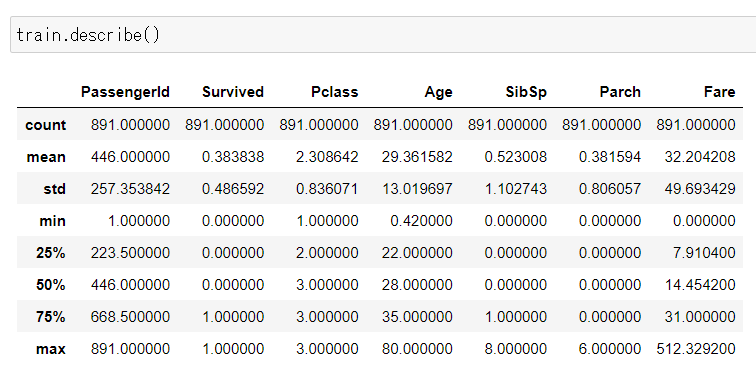
次にpandasのdescribe()を使って、各データセットの基本統計量も確認しておく。
【train.csvの統計量情報】
【test.csvの統計量情報】
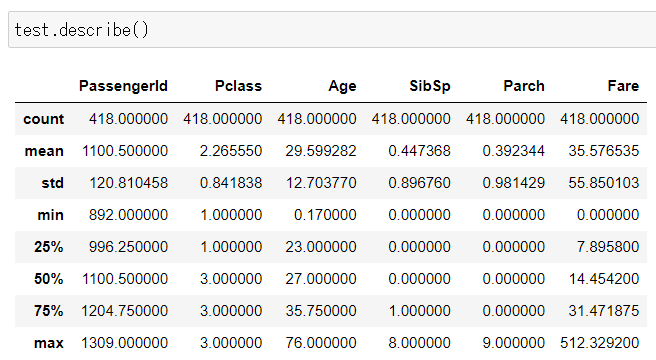
各データのshape(データフレームの行数と列数を表す属性)を確認した通り、両データ共に「PassengerId」はTrain=891カウント、test=418カウントと一致している。しかし、「Age」など一部のカラムでカウント数が少ないものがある。これは、つまり欠損データがあると読み取れる。
次は両データセットの欠損データを確認していく。
データセットの欠損の確認
提供されている(もしくは使う)データセットで100%データが揃っていることの方が珍しいくらいでである。どこかのデータが欠損してたり、信用性が低いため使えなかったりする場合がほとんどである。
dataframeの欠損データをisnull()で探して、カラム毎に返す関数kesson_table()を作って、train.csvとtest.csvのデータフレームの欠損を確認する。
■dataframe:
PandasというPythonのライブラリで提供されるデータ構造の一つ。
■isnull():
PandasのDataFrameに対して使用できるメソッド。このメソッドを呼び出すことによって、データフレームの各要素が欠損値(NaN、null)であるかどうかを示す真偽値のデータフレームを返す。
■関数kesson_table():
kesson_table()は、Pythonのpandasライブラリで使用される関数で、欠損値を含むデータフレームの欠損値を補完するために使用される。タイタニックデータの場合、kesson_table()は欠損値を補完するために使用される。
【train.csvの欠損データ】
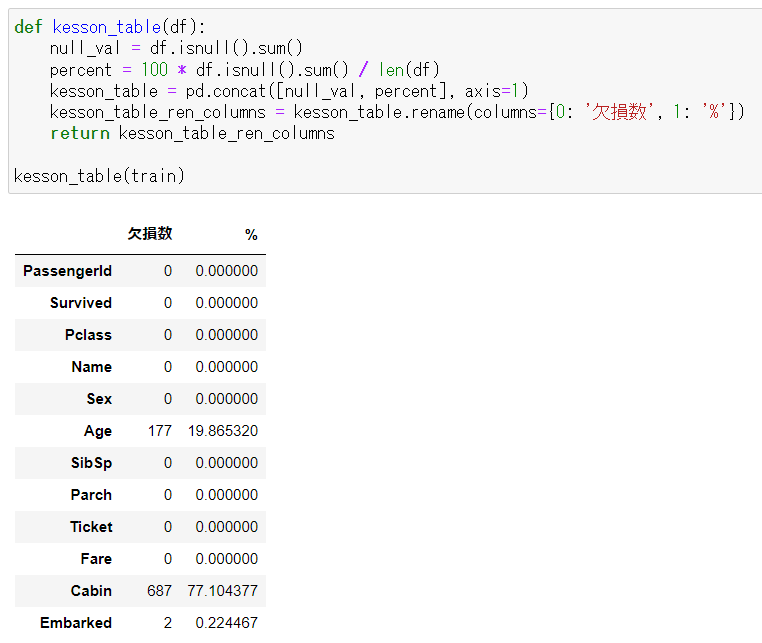
上記の表を確認すると、train.csvでは「Age」「Cabin」「Embarked」に欠損があるのがわかる。
【test.csvの欠損データ】
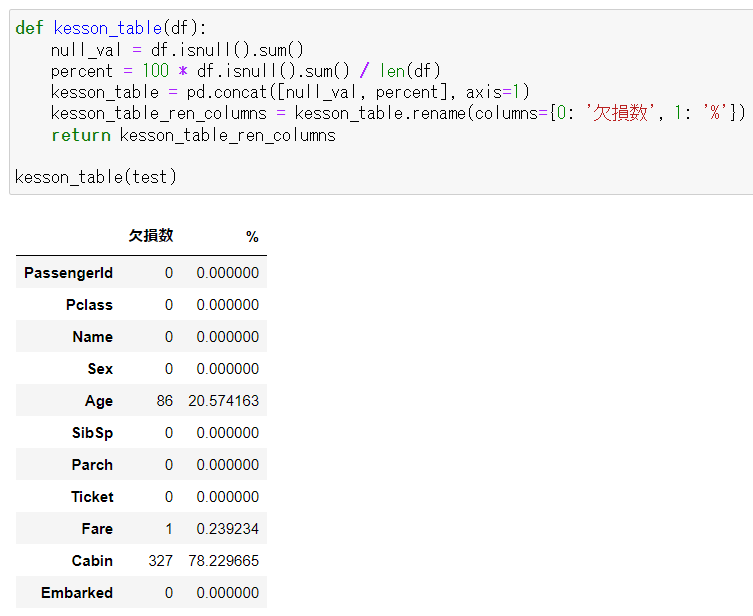
上記の表を確認すると、test.csvでは「Age」「Cabin」「Fare」に欠損があるのがわかる。
では、次は欠損データを含めたデータの事前処理を行っていく。
データセットの事前処理
データの事前処理とは
機械学習の元となるデータをAIに学習させる前にデータを加工することである。
また、収集した生のデータをAIが学習しやすいようにきれいに整える作業である。
データ事前処理の必要性
収集したデータが完璧な状態でそのまま使える可能性は限りなく低い。ほとんどのデータにはエラーやノイズ、欠損値などが含まれていたり、データによってフォーマットが異なることもある。このようなデータをそのまま機械学習に使用すると学習の精度が下がったり、エラーが出てしまうなどの問題が起こる。
そのため、機械学習を行う前にデータを適切な状態に加工するデータの前処理が欠かせないのである。
データセットの事前処理が一番重要であるが、今回はあくまでKaggle初心者向けチュートリアルなので、基本的なことを行なっていく。このチュートリアルで行う内容としては以下2点。
- 欠損データを代理データに入れ替える
- 文字列カテゴリカルデータを数字へ変換
まずは、欠損データを代理データに入れ替える処理をする。
train.csvから綺麗にしていく。先に確認したがtrain.csvでは「Age」「Cabin」「Embarked」の3カラムに欠損データがあった。今回のチュートリアルでは「Cabin」は予測モデルで使わないので、「Age」と「Embarked」の2つの欠損データを綺麗にしていく。
まず「Age」だが、シンプルにtrain.csvの全データの中央値(Median)を代理として使う。(代理データで何を使うか、どのような処理を加えるかは非常に重要かつ大きな議論ではあるが、ここはシンプルに考えて進める。)
次に「Embarked」(出港地)だが、こちらも2つだけ欠損データがtrain.csvに含まれている。他のデータを確認すると「S」が一番多い値だったので、代理データとして「S」を使う。
各カラムでfillna()を使って代理となるデータを入れる。先ほど作ったkesson_table()で念のため欠損データがないかどうか確認をする。Cabinは今回は使わないので欠損データがあっても大丈夫だが、「Age」「Embarked」の欠損は埋まったことがわかる。
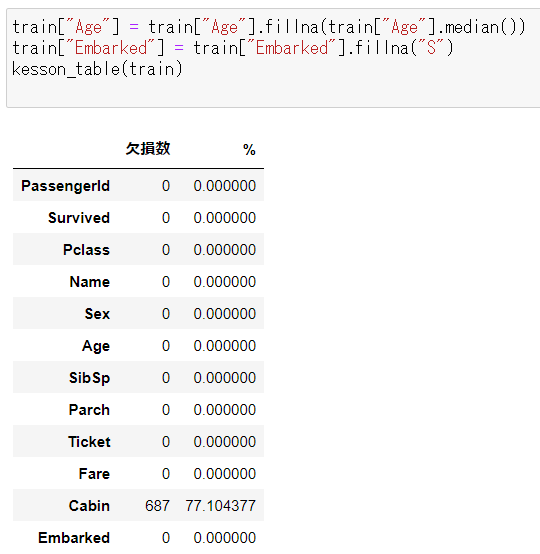
欠損データの処理が終ったので、次はカテゴリカルデータの文字列を数字に変換する。今回の予想で使う項目で文字列を値として持っているカラムは「Sex」と「Embarked」の2種類。Sexは「male」「female」の2つのカテゴリー文字列、Embarkedは「S」「C」「Q」の3つの文字列となる。これらを数字に変換する。
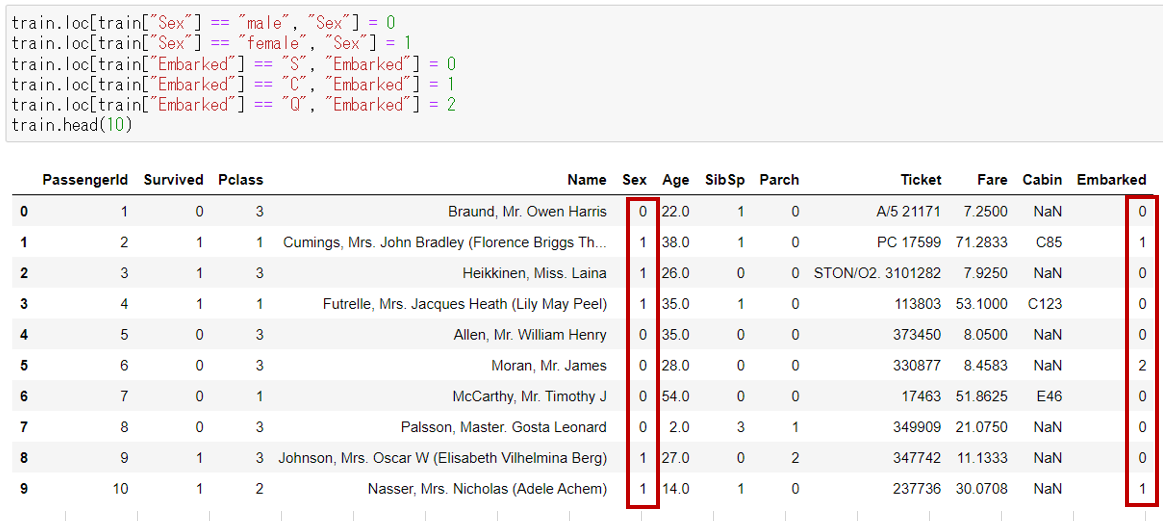
上記の通り、SexとEmbarkedに入っていた文字列の値が、数字へ変換されていることが確認できた。これでtrain.csvの事前処理は終わったが、次はtest.csvも同様の処理を行う。
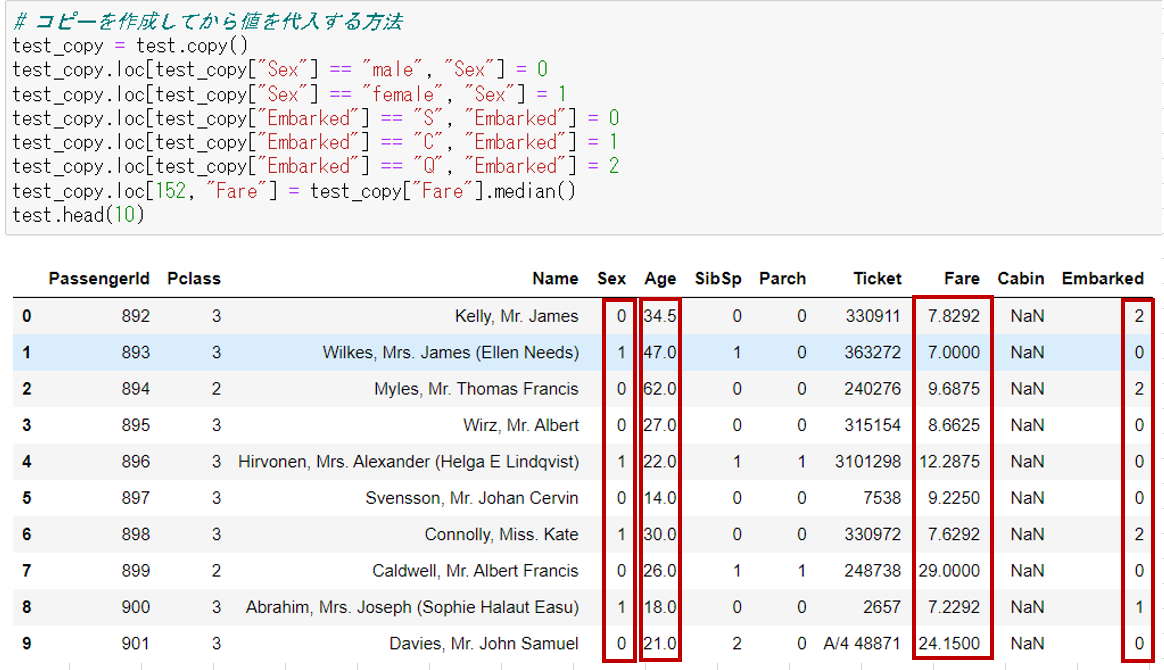
同様に「Age」へは中央値(Median)の代入、また文字列の値(SexとEmbarked)は数字に変換した。さらに、test.csv では「Fare」に一つだけ欠損があったので、こちらも年齢と同様に中央値(Median)を代理で入れている。念のためhead()でデータの中身も確認をしておく。
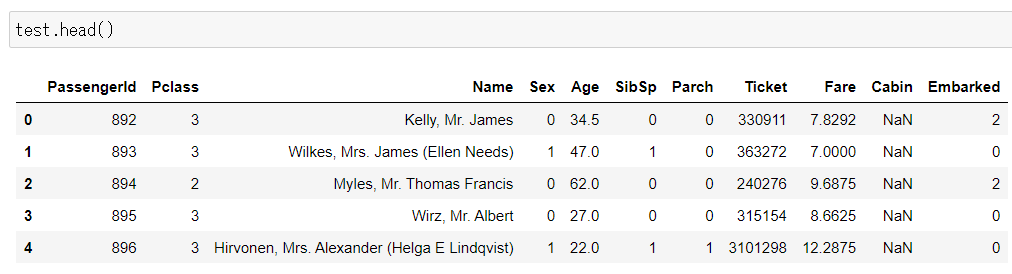
最適化したモデルを作成する
本記事では予測モデル「決定木」を異なるデータで訓練して、結果を比較してみようと思う。
予測モデル「決定木」とは
決定木は、データの特徴量を用いて分類や回帰を行う予測モデルである。木構造を用いてデータを分割し、属性の値に基づいてデータを分類する。決定木は直感的に解釈でき、特徴量の重要度を評価できるという利点がある。また、非線形な関係を表現できるが、過剰適合のリスクやデータの小さな変化への敏感さがある。決定木は様々な分野で利用され、ランダムフォレストや勾配ブースティングなどのモデルの基礎としても活用されている。
【例】
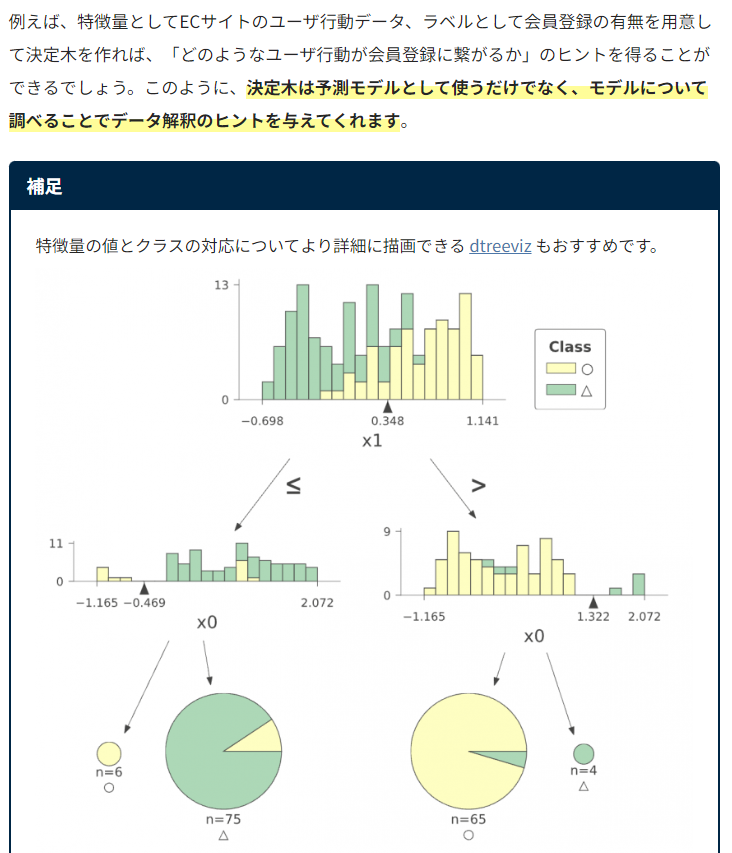
引用元:https://blog.kikagaku.co.jp/decision-tree-visualization
予測モデル その1 「決定木」
データの確認、事前処理も終わったので、予測モデルを作り実際に予測をしてみる。本記事では予測モデル「決定木」を異なるデータで訓練して、結果を比較してみる。
「決定木」だが、scikit-learnとNumpyを使えば非常に簡単に作成することが可能である。
■scikit-learn:
scikit-learnはPythonのオープンソース機械学習ライブラリであり、統一されたAPIと多様な機械学習手法を提供している。さまざまな機能やツールを備えており、データの前処理からモデルの選択、評価までの機械学習のタスクを効率的に実行できる。ドキュメンテーションとコミュニティのサポートも充実しており、広く使われている。
まず初めに作る予測モデル「その1」だが「Pclass」「Sex」「Age」「Fare」の4つの項目を使って「Survived(生存可否)」を予測してみる。別の言い方で表すと、タイタニックに乗船していた客の「チケットクラス(社会経済的地位)」「性別」「年齢」「料金」のデータを元に生存したか死亡したかを予測するとも言える。
では実際に作っていく。
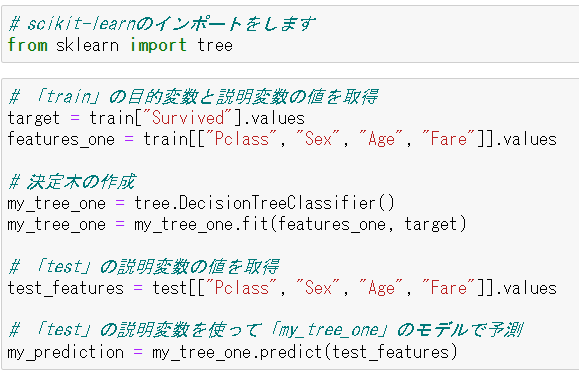
-
scikit-learnのインポートを行う。
-
決定木で使うTargetとFeatureの値をtrain.csvから取得して格納しておく。
scikit-learnの「DecisionTreeClassifier()」を使って「my_tree_one」という決定木モデルを作成した。 -
事前に綺麗に処理をしておいたtest.csvから、train.csvで使ったFeatureと同様の項目の値を「test_features」へ入れて、predict()を使って予測をした。
■Feature:
Feature(特徴量)は、機械学習やデータ分析で使用されるデータセット内の個々の属性や情報を表す要素である。データの性質や特性を表現し、モデルの学習や予測に使用される。特徴量は数値やカテゴリカルなデータを取り、モデルの性能に大きく影響を与える重要な要素である。例えば、タイタニックの乗客データセットの特徴量には、年齢、性別、乗船クラスなどがある。これらの特徴量は、乗客の生存予測モデルの学習や予測に使用される。
■predict():
predict()は、機械学習モデルによって訓練されたモデルを使用して、新しい入力データに対して予測を行うためのメソッドである。モデルが学習した関数を使用して、未知のデータに対して予測値を生成する。入力データをモデルに渡すことで、モデルは学習したパターンや関係性に基づいて予測結果を出力する。予測値の具体的な形式や応用は、使用する機械学習アルゴリズムやタスクによって異なる。
予測されたデータを確認してみる。
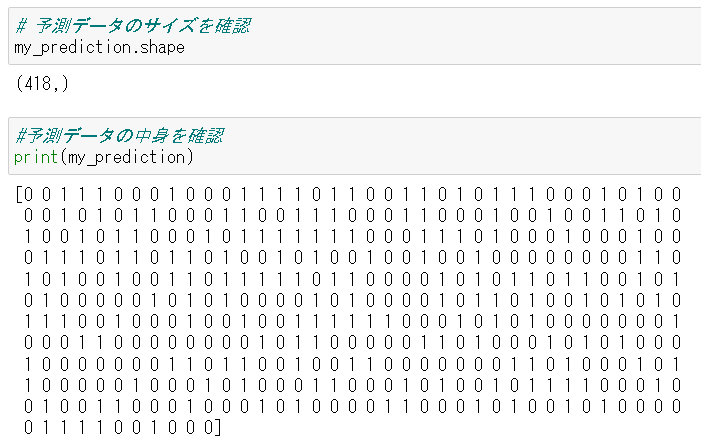
予測をしなくてはいけないデータ数、つまり test のデータ数は418個であったが、上記の通りmy_predictionも同じ数の予測数が結果として出力されている。今回の予測は「0か1(生存か死亡)」だが、念のため中身も確認してみると0と1で構成されているのが確認できる。
では、この予測データをCSVへ書き出してKaggleへ提出する。下記のコードでPassengerIdと予測値を取得してCSVファイルを書き出す。
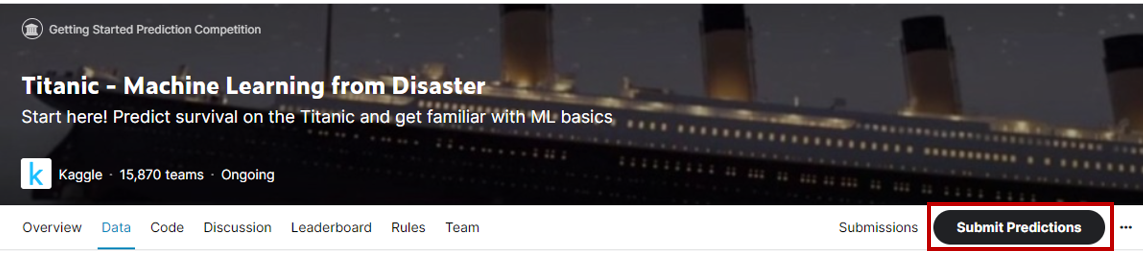
Kaggleへログインをしてタイタニックページへ移動をすると、上部メニューに「Submit Predictions」という項目があるので、こちらをクリックする。
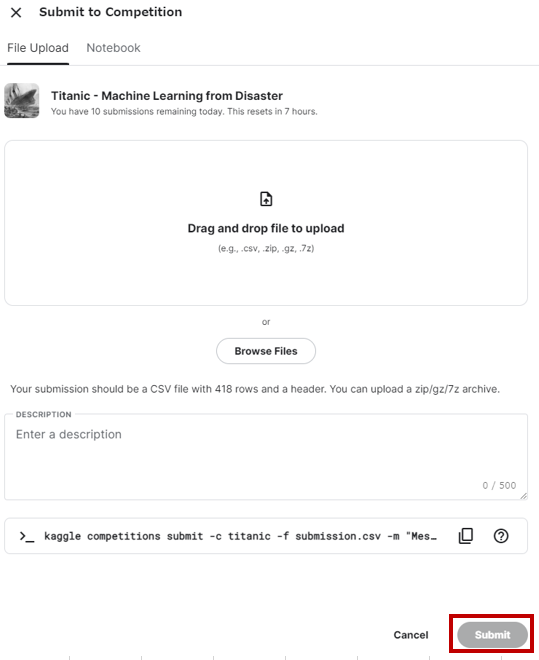
同ページの下部にファイルアップローダーがあるので、こちらで先ほど書き出した「my_tree_one.csv」をアップロードして「Submit」をクリックする。
投稿をすると次のページへ自動的に遷移し生存者予測の正解率の結果が表示される。
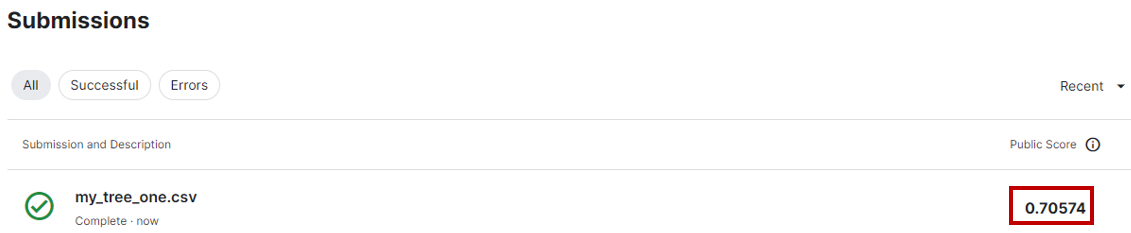
ファイルがKaggleの投稿基準を満たしていると、即座にスコアを計算して表示してる。
「my_tree_one」は「チケットクラス(社会経済的地位)」「性別」「年齢」「乗船料金」の4つのデータを用いて「決定木」のモデルを使い予測を行ったが、結果として「0.70574」のスコアが獲得できた。
Kaggleのスコアはコンペにより異なる。各コンペの「Evaluation」のページに詳細が記載されている。今回予測を行なったタイタニックのコンペでは予測スコアは単純に「Accuracy(正解率)」が使われているので、今作った「my_tree_one」は約71.0%の確率で正解を予測できたということになる。
【日本語翻訳】
では、次はこの71.0%のスコアよりももう少し正確なモデル作成する。
予測モデル その2 「決定木 + 7つの説明変数」
予測モデルその1では「タイタニックに乗船していた客の「チケットクラス」「性別」「年齢」「料金」のデータを元に生存したか死亡したかを予測」した。Kaggleで答え合わせをすると「約71.0%」の正解率であった。
では、この正解率を上げるためにはどうすればよいのか。
色々と試せることはあるかと思うが、パッと思いつく限りだと、予測モデルの訓練で使うデータに他の変数も加味してみてはどうだろうか。
では、「その1」では4つのデータしか予測モデルに反映しなかったが、他で使えそうなデータも予測モデルに使ってみることにする。
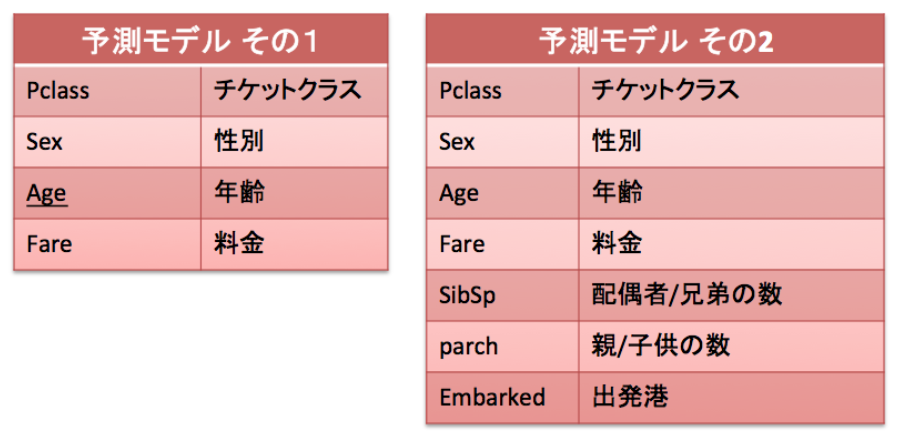
抜粋元:https://www.codexa.net/kaggle-titanic-beginner/
映画「タイタニック」でも家族や子供と一緒に船から脱出を試みるシーンがあったように記憶しているが、これは恐らく生存確率に影響をしそうである。また出発港も3つのカテゴリしかないが、生存確率に何かしらの影響があるのではと考えられるので追加をしてみる。
まずはtrain.csvのデータセットから今回追加になった項目の値も追加して「features_two」に取り出す。
また、予測モデルその2では簡単であるが「過学習(Overfitting)」についても考えてみる。その1で作成した決定木のモデルではmax_depthとmin_samples_slitのアーギュメントを指定しなかったが、その2のモデルではアーギュメントを設定してみる。
■過学習(Overfitting):
過学習(Overfitting)は、機械学習モデルが訓練データに過度に適合し、未知のデータに対する予測性能が低下する現象である。過学習はモデルの複雑さや訓練データの不足などの要因によって引き起こされる。過学習を防ぐためには、モデルの単純化、データの増加、特徴量の選択・削減などの対策を取る必要がある。過学習を避けることは、モデルの性能向上に重要であり、訓練データだけでなく検証データやテストデータを使用してモデルを評価する必要がある。
■max_depth:
max_depthは、決定木やランダムフォレストなどの決定木ベースのアルゴリズムにおけるパラメータであり、木の深さを制限する役割を持つ。深さが増えるほどモデルの複雑さが増し、過学習のリスクが高まる。適切なmax_depthの設定は、モデルの複雑さを調整し、過学習を防ぐために重要である。最適なmax_depthの値を見つけるには、交差検証などの手法を使用してモデルの性能を評価することが一般的である。
■min_samples_slit:
min_samples_splitは決定木やランダムフォレストなどの決定木ベースのアルゴリズムにおけるパラメータであり、ノードを分割するために必要な最小サンプル数を指定する。この値を調整することでモデルの複雑さや過学習のリスクを調整できる。小さな値を設定するとモデルは細かな特徴にフィットしやすくなり、過学習のリスクが高まる。大きな値を設定すると一般化された特徴を学習しやすくなり、過学習のリスクが低下する。最適な値はデータセットや問題に依存し、交差検証などを用いて評価することが一般的である。
■アーギュメント:
アーギュメントはプログラムや関数に渡される値やオプションであり、関数の呼び出し時に指定される。位置引数とキーワード引数の2つのタイプがあり、位置引数は順序に従って値を渡し、キーワード引数は引数名と値をセットで指定する。アーギュメントはプログラムの柔軟性や再利用性を高め、関数の動作をカスタマイズするために使用される。

さて、モデルの作成もできたので、実際に「my_tree_two」を使って予測をしてみる。

上記のコードを正しく打ち込んでいれば、「my_tree_two.csv」として新しく作成した決定木による予測のCSVファイルが書き出されているはずである。
では、早速、Kaggleへ戻って結果をアップロードする。
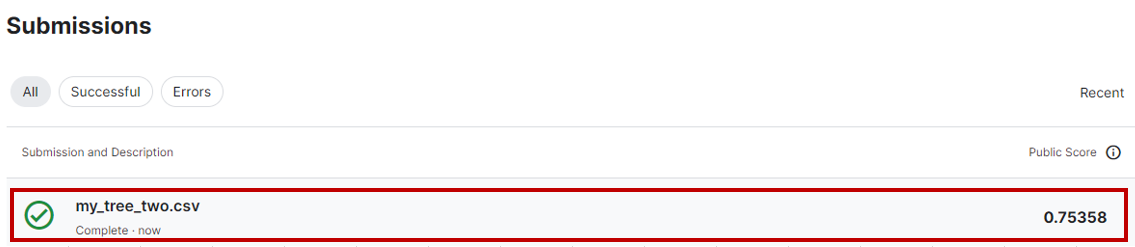
スコア「0.75358」であった。つまり、正解確率が約75.0%と少し改善されている。その1では正解率が約71.0%だったので、訓練データを増やしたことにより約4%の改善ができた。
所感
決定木前までは理解でき、スムーズに進められていたが、決定木から難しくなった。この経験から機械学習の知識定着が必須だと改めて感じた。昨今AutoMLやChatGPTなど便利なツールが沢山でてきたが、これらを活用するためにも知識/スキルの習得が必須だと改めてわかった。今後、もっと沢山の機械学習のスキル学習を頑張らなければいけない。
おわりに
今回のハンズオンは貴重な体験であった。経験者のやり方を1つ1つ理解し、実際に手を動かすことにより、ただ書籍など情報を読むだけより数段知識/スキルが身に付いたと感じた。
今後はさらに機械学習における知識/スキルを身に付け、AutoMLやChatGPTなども上手く活用し、他のKaggleコンペの課題に挑戦したい。
最後に、今回参考させて頂いたサイト記事に心から感謝いたします。
参考
https://myafu-python.com/datascience/kaggle-titanic/
https://mukai-lab.info/pages/classes/intelligence_information_system/chapter14/
https://blog.kikagaku.co.jp/decision-tree-visualization
https://pycarnival.com/fit_predict_scikitlearn/