はじめに
データサイエンスのスキル初学者である私でも少しでも早く向上したいと思い、データサイエンスのコンペティションで有名なkaggleに挑戦しようと思った。
しかし、機械学習や統計学・数学、プログラミング等のスキルにおいて初学者レベルの私では挑戦できるレベルではない思っていたところ、AotoML=自動機械学習の存在を知り色々と調べていくうちに専門スキルを必要とせずに予測分析ができるソニーネットワークコミュニケーションズ株式会社開発のソフトウエアPrediction Oneを知り、こちらを使用しkaggleに挑戦することにした。
また、他にもAotoMLがあったが、有料や登録に条件(クレジットカード必須)があったことから、無料体験30日間の条件があるもののデストトップにインストールし自由に使える利便性の高いPrediction Oneを使用することに決めた。
筆者のデータサイエンスに関連するスキル・経験
- 機械学習:独学レベル(書籍やサイト、無料動画を利用)
- 数学知識:大学1年生程度
- 統計学:大学1年生程度
- プログラミング:Excel VBA独学レベル(書籍やサイト、無料動画を利用)
※VBAエキスパート(Excelベーシック)取得 - ビジネス:前職で自社開発の業務効率化ツールを活用するための社内募集にて、担当業務の効率化を提案した経験あり(開発者と定期的に話し合いツール作成。今までの工数を半分にできた。)
目次
- データ処理の工程
- kaggleとは
- データをダウンロードする
- データ定義の確認
- データの前処理とは
- データ前処理の必要性
- preditiononeとは注1
- predictiononeを使用し予測モデルを作成する注1
- 予測モデルを使用し予測する
- 予測データを提出する
- predictiononeで精度が上がるか試してみた注1
- データの前処理をpythonを使い処理をしてみる注1
- kaggleへ挑戦したことで身に付いたこと
- おわりに
- 参考
データ処理の工程
以下のような工程でデータ分析を進めていく。
-
Kaggleからデータをダウンロードする。
-
ダウンロードしたデータをもとに、最適化したモデルを作成する。
-
2.で作成したモデルをもとに、別のデータに対してモデルを適用することで生存しているかを予測する。
-
Kaggleにアップロードして生存率(正答率)を判定する。
kaggleとは
Kaggleとは、主に機械学習モデルを構築するコンペティションのプラットフォームです。企業や研究機関などが提供す> るデータについて、世界中から集まる参加者が機械学習モデルの性能を競います。
(Kaggler-ja Wikiより抜粋)
今回のKaggleコンペの目的はタイタニック号の乗客の属性(性別、年齢など)から、生存を予測することである。
サイトはこちら
データをダウンロードする
- まず、データ分析を行う元となるデータをこちらのサイトからダウンロードする。

2. 次にダウンロードしたzipファイルを展開すると以下2つのファイルを入手できる。
- train.csv(学習用データ)
- test.csv(テスト用データ)
上記2つと同様にダウンロードしたファイル「gender_submission.csv」は回答例データであり、こちらをkaggleの提出場所へアップロードすると予測データの正当率が表示される。正答率は76%であった。
この正答率76%を基準とし、これよりも高い正答率を目指すこととなる。
また、提出する時のフォーマットであり、予測データファイルはこちらのフォーマットに合わせ提出する。
データ定義の確認
データセットは下記のとおりである。
| 属性 | 内容 |
|---|---|
| PassengerId | 乗客ID |
| Survived | 生死(0 = No; 1 = Yes)※train.csvのみに存在。test.csvのこの値を予測する。 |
| Pclass | 乗客の社会階級(1 = 1st(High); 2 = 2nd(Middle); 3 = 3rd(Low)) |
| Name | 乗客の氏名 |
| Sex | 性別 |
| Age | 年齢 |
| SibSp | 船している夫婦、兄弟姉妹の数 |
| Parch | 乗船している親、子供の数 |
| Ticket | チケットNo |
| Fare | 乗船料金 |
| Cabin | 船室 |
| Embarked | 乗船場所(C = Cherbourg; Q = Queenstown; S = Southampton) |
データの前処理とは
機械学習の元となるデータをAIに学習させる前にデータを加工することである。
また、収集した生のデータをAIが学習しやすいようにきれいに整える作業である。
データ前処理の必要性
収集したデータが完璧な状態でそのまま使える可能性は限りなく低い。ほとんどのデータにはエラーやノイズ、欠損値などが含まれていたり、データによってフォーマットが異なることもある。このようなデータをそのまま機械学習に使用すると学習の精度が下がったり、エラーが出てしまうなどの問題が起こる。
そのため、機械学習を行う前にデータを適切な状態に加工するデータの前処理が欠かせないのである。
predictiononeとは注1

Prediction Oneは、データさえ用意すれば、数クリックで高度な予測分析を自動的に実行できるソフトウエアです。
必ずしも専門スキルを必要とせずに予測分析ができ、ビジネスに活用できます。専門家の方にとっては、予測モデルの構築作業が飛躍的に効率化します。
(SONY Prediction Oneのサイトから抜粋)
predictiononeを使用し予測モデルを作成する注1
(アカウント作成から導入までの説明は割愛)
-
デスクトップから起動後に表示される画面左上にある「予測モデルの新規作成」ボタンを押下する。

-
以下の画面中央にある指示文通りに従い事前に用意したtrain.csv(学習用データ)を読み込む。

-
予測タイプは自動的に「二値分類」が選択されている。予測したい項目は任意に1つ選択する。
生存者を予測したいので「Survived」を押下し、以下画面の右下の「予測モデルを作成」ボタンを押下する。

-
自動で予測モデルが作成されるので、作成完了後、以下画面の右下「完了」ボタンを押下する。

-
以下のとおり予測モデルが作成される。

予測モデルを使用し予測する
-
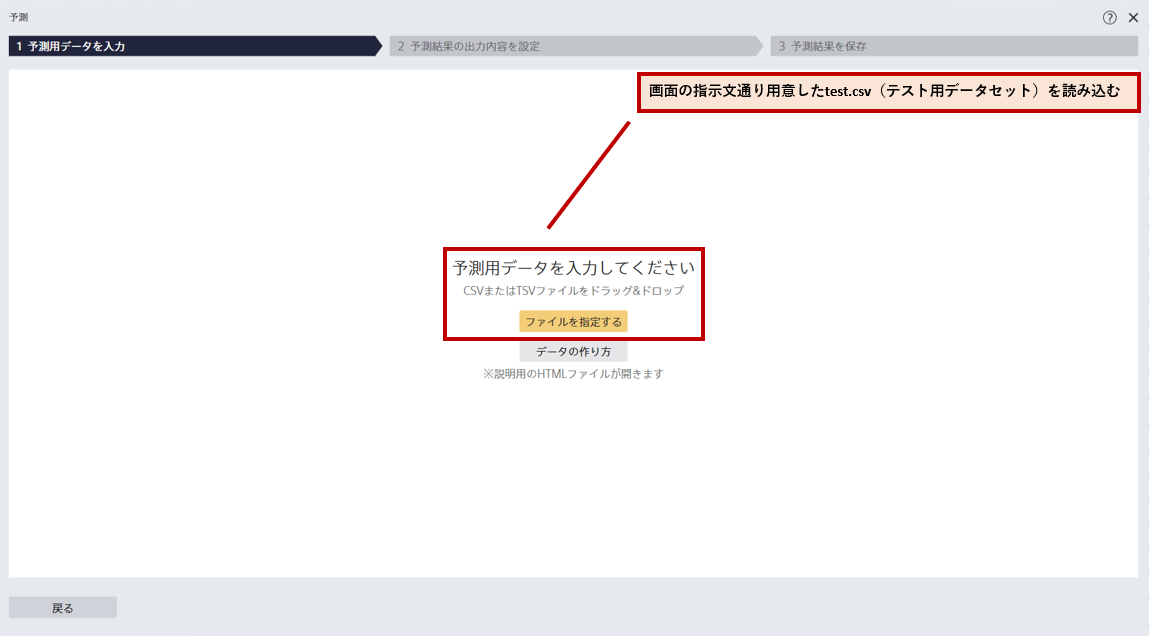
以下画面の指示文通り用意したtest.csv(テスト用データセット)を読み込む。
-
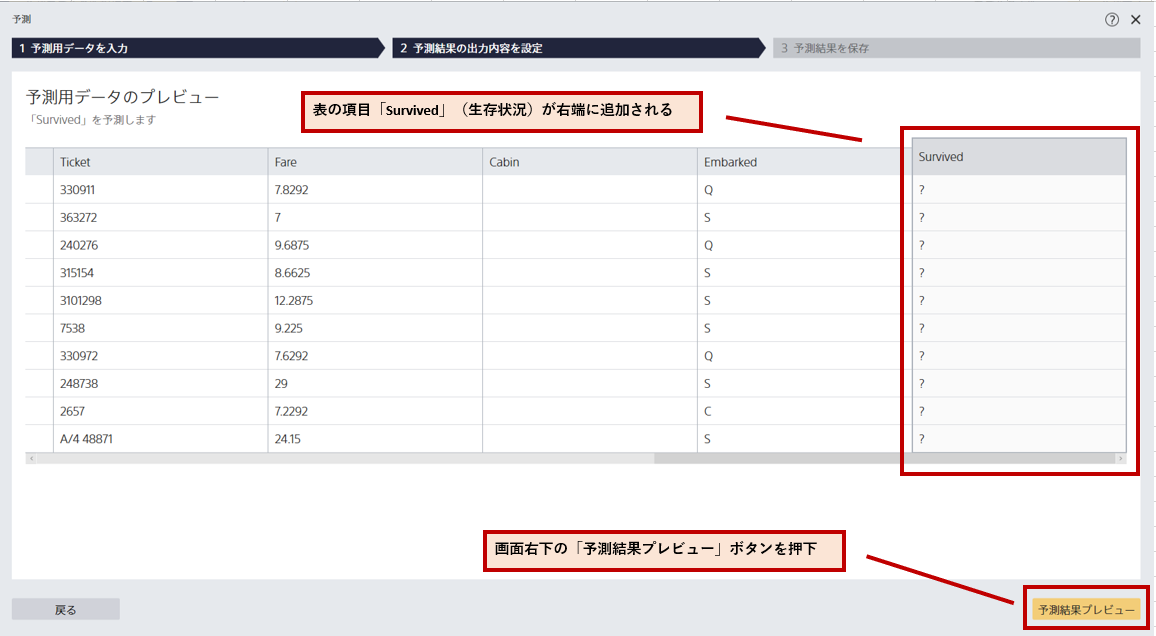
表の項目「Survived」(生存状況)が右端に追加されるのが確認できたら、以下画面の右下「予測結果プレビュー」ボタンを押下する。
-
項目「Surivived」(生存状況)の右隣に「0」と「1」の項目がある。
分類結果の閾値が0.46なので、それより大きな値は「0」、小さな値は「1」となる。つまり、「0」は死亡、「1」は生存を表している。確認できたら、以下画面の右下にある「予測して保存」ボタンを押下する。そうすると、ファイル保存画面が表示されるので、今回は任意にファイル名「taitanic_predicton」として保存した。

-
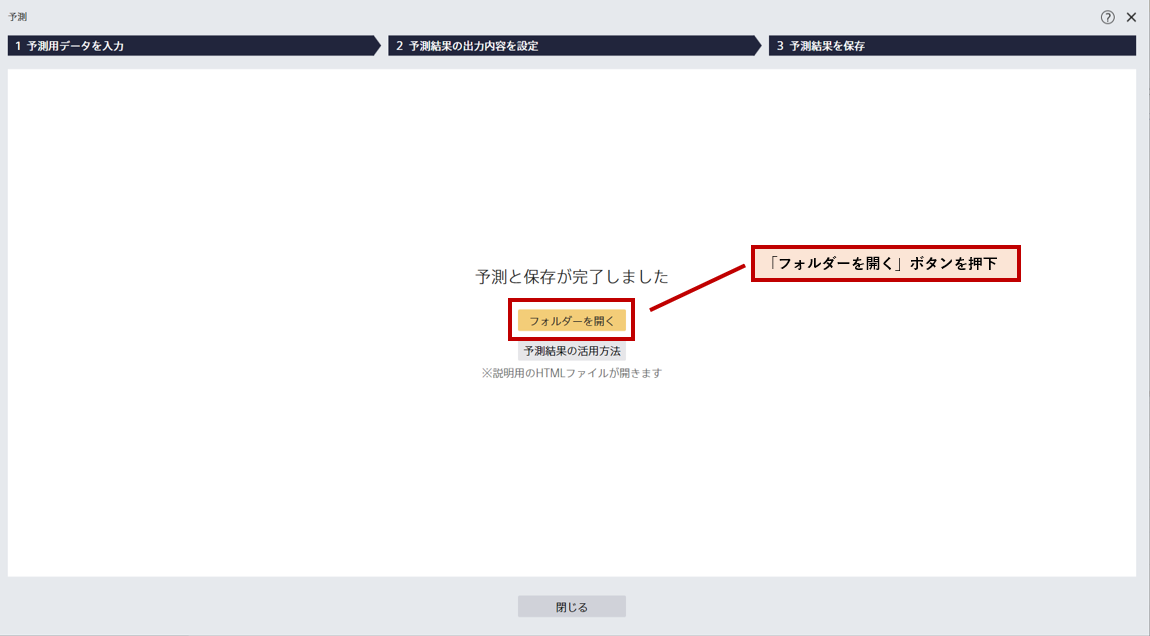
予測と保存が完了すると以下の画面となる。「フォルダーを開く」ボタンを押下する。
-
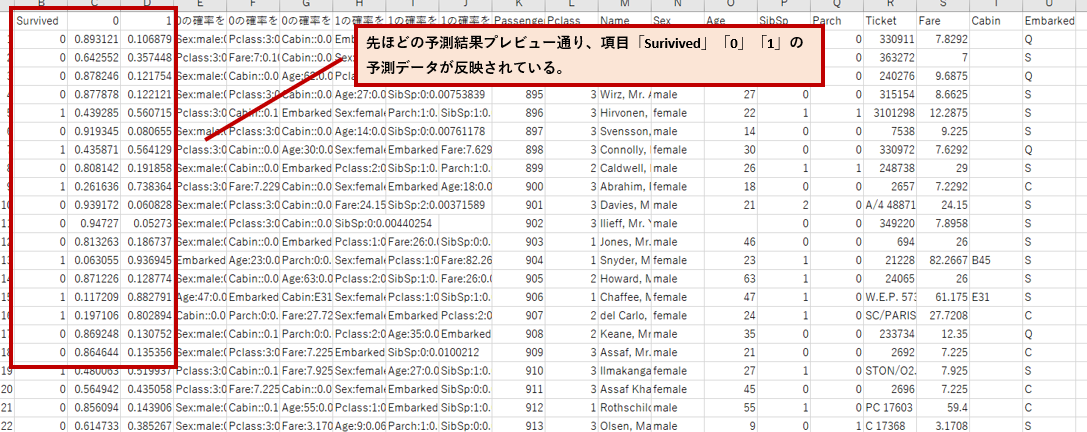
先ほど保存したファイル「taitanic_predicton」を開く。予測したデータが以下である。
-
予測したデータをKaggleに提出するため、先ほど説明したgender_submission.csvのフォーマット形式に合わせ項目「PassengerId」と「Survived」の2列のみ表示させる。ファイル名を任意に「taitanic_submit.csv」とした。

-
以上で、Prediction Oneを使用した予測は完了する。
予測データを提出する
先ほど作成した予測ファイル「taitanic_submit.csv」をKaggleの課題ページにアップロードする。
-
項目タブ「Leaderboard」を押下する。

-
画面右端の「Submit Prediction」ボタンを押下する。

-
作成した予測ファイル「taitanic_submit.csv」をアップロードする。

-
以下画面の右下「Submit」ボタンを押下する。これでKaggleへ予測データを提出したことになる。

-
作成した予測ファイル「taitanic_submit.csv」は予測正解率は約75%であることがわかる。
以下画像のファイル「taitanic_submit.csv」の下にある青枠で囲まれたファイル「gender_submission.csv」の予測正解率は約76%でああり、今回予測したデータはこれより約1%正解率が低いことになる。
予測精度の平均中央値は76%とのことなので、まずまずの精度が出ていることがわかる。

predictiononeで精度が上がるか試してみた注1
Prediction Oneでは予測精度を上げるためのヒントが載っている。

欠損値処理はPrediction Oneで自動補正してくるとのこと。
自分で操作できることを試してみる。
交差検証にチェックを入れると精度が上がる可能性があるとのこと。

交差検証とは?

交差検証とはデータの解析と評価を交差させることで、より正確な推定値を求める手法です。交差検証の定義はこれだけ> なのですが、実際の使われ方にはいくつかの種類が存在します。
【結果】
Prediction Oneの予測精度は85.4%、Kaggleの正当率は74.4%となった。
Prediction One予測精度は上がったのにKaggleの正当率は下がった事に対し相関関係がわからなかった。
他にはPrediction Oneで自動で定められた特徴量を外したりした(例えば「Parch」や「Cabin」)が、予測精度は上がるが正答率は下がってしまった。
このことからPrediction Oneは自動でベストな設定をしてくれていると確認できた。
ただ、Prediction Oneの使い方が不慣れであったり、機械学習のスキルが未熟なので、これらを習得すればもっと使いこなし正答率を上げる可能性はある。
データの前処理をpythonを使い処理をしてみる注1
【環境】
・Anaconda
・Pandas
・Jupyter Notebook
Anaconda(アナコンダ)とは
Pythonの実行環境で、データサイエンスに必要とされる各種ツールやライブラリを提供するプラットフォームである。
Pandas(パンダス)とは
例えば、Pandasでは下記のようなことが出来ます。
・CSVやExcel、RDBなどにデータを入出力できる
・データ前処理(NaN / Not a Number、欠損値)
・データの結合や部分的な取り出しやピボッド(pivot)処理
・データの集約及びグループ演算
・データに対しての統計処理及び回帰処理`
引用元:https://aiacademy.jp/media/?p=152
■train.csvの属性「Age」の欠損値を補完する
欠損値の補完とは
欠損値の定義、処理についてはこちら参照。
▼Ageの欠損値を補完したコード

▼補完前のデータ ※わかりやすいようにセルに色を付けている。

▼補完後のデータ ※わかりやすいようにセルに色を付けている。

▼補完後のデータで再度Prediction Oneを使い予測した。
予測精度は79.95%であった。欠損値補完前のデータ(予測精度79.08%)に比べ少し上がった。

▼test.csvも同様に補完し、再度kaggleへ提出した。
1回目の正当率76.6%より低い72.2%であった。
私の処理方法が間違っていたのか、それとも属性Ageは欠損値を補完しても精度、正答率へのファクターとはいえないのかわからなかった。こういう事に対し、様々なスキル習得が必要なのだと改めて痛感した。

▼上記に加え、補完後のデータにPOの「交差検証」にチェックを入れ再度予測した

▼上記の予測データを再度kaggleへ提出した。
【結果】
正当率は71.2%となり、さらに下がった。

残念ながらデータ処理をしても精度は上がらなかった。
他にもデータ処理の方法はあるが時間の関係上今回はここで終える。
現状(初学者)ではPrediction Oneを素直に使用した方が良さそうである。
kaggleへ挑戦したことで身に付いたこと
・データの内容をしっかり把握すること
・データ処理の必要さ
・データクレンジング(欠損値補完など)
・Jupyter Notebook
・Python(anaconda,pandas)
特に予測精度を高めるためのデータ処理の重要さを身を持って経験できたこと一番の収穫であった。
おわりに
Prediction Oneはデータサイエンスのスキル初学者の私でも使いやすい上に、きちんと予測結果を出せるソフトウエアだと身を持って感じた。今後の課題は今回出した予測正解率を高めていくスキルが必要であり、そのためにはもっと沢山のデータサイエンスのスキルを身に付けなければいけないと思った。今回は初学者対象でも使用できるPrediction Oneを使用したが、以前から知見のあった、同じくソニーネットワークコミュニケーションズ株式会社開発のソフトウエア「Sony NNC」を使用して挑戦したい。こちらは知識・スキルがまだ足りない理由から使用できるレベルではないと判断し断念したが近いうちに挑戦したい。
参考
https://kaggler-ja.wiki/5b3add39773cad001a6e7fb2
https://github.com/seosoft/Titanic_MachineLearningStudio/blob/master/01_preparedata.md
https://blog.kikagaku.co.jp/microsoft-azureml
https://myafu-python.com/datascience/kaggle-titanic/
https://niigata.insight-lab.co.jp/blog/ai-predictionone-review2
https://predictionone.sony.biz/cloud_manual/tips/result/improve_model/
https://bunkyudo.co.jp/ai-prediction-one-01/
https://predictionone.sony.biz/cloud_manual/terminology/missing_value/
https://qiita.com/seri28/items/ae98aa1965fc29cd864d
https://www.hinomaruc.com/titanic-dataset-analytics-2-1/
https://www.codexa.net/cross_validation/
https://maru.nagoya/index.php/2022/08/22/ml-data-preprocessing/
https://and-engineer.com/articles/YRXgARAAACRz12i3
https://best-biostatistics.com/summary/missing_value.html
注1‥‥リンクの関係上英字は全て小文字表記としている。またスペースも入れていない。