前回は、LangGraphを用いた対話エージェントにおいて、SQLiteによるナレッジ(知識)管理と、LLMの出力をナレッジとして蓄積する機能を追加した。
LangGraphで分岐・ループ処理付きの対話エージェントを作ってみた② 〜ナレッジをDBに保存して成長させる〜
今回はその発展として、以下の2つの機能を追加する:
- SQLiteに格納されたナレッジの検索精度の向上
- 重複ナレッジの検出と回避
対話エージェントの基本的なフローは前回と同様だが、今回は検索時の意味理解力の強化と、ナレッジの 品質担保(重複排除) にフォーカスして改善を行う。
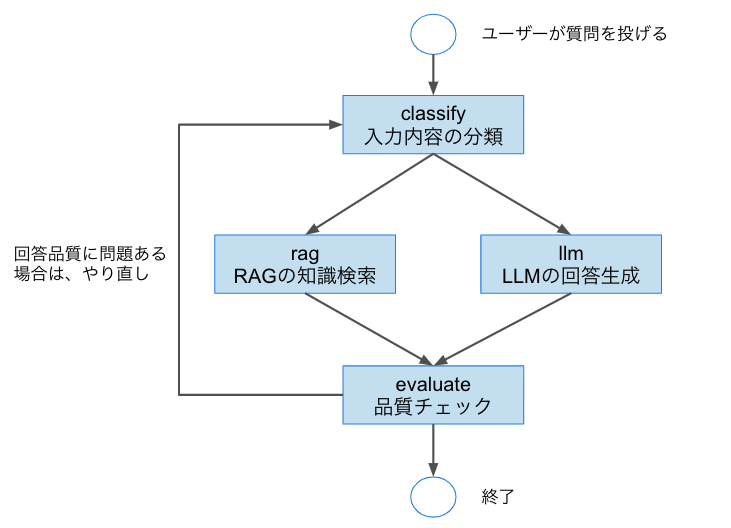
1. 本記事における変更箇所
本記事では、LangGraphで構築した対話エージェントに以下の機能を追加し、ナレッジの検索性と管理性の向上 を目指す。
- SQLiteに格納されたナレッジの検索精度の向上
- ナレッジの重複登録の検出および抑制
これらは「蓄積された知識をいかに効果的に活用するか?」という観点での改善である。
なお、本記事で作成したコードは以下である。
LangGraphknowledge
1.1 検索精度の向上
前回は、ユーザー発話に含まれる単語ベースでナレッジを抽出していたが、今回は以下のような意味理解に基づく改善を行った:
- ユーザー入力に対して、LLMを用いて意味的な要約文を生成
- 要約文をクエリとして、SQLite内のナレッジと意味ベースで照合
これにより、表現の揺れや言い換えに強い柔軟な検索が可能になる。
1.2 ナレッジの重複検出と登録抑制
ナレッジが重複して登録されると、検索結果にノイズが混じり、回答の信頼性や一貫性が低下する恐れがある。
そのため、以下のような対応を追加した:
- 追加しようとしているナレッジと、既存ナレッジの意味的な類似度を比較
- 類似度が高い(≒重複している)と判断した場合は、登録処理をスキップ
2. 検索精度を向上させる
前回は、クエリに "RAG" という語句が含まれているかどうかで、RAGノードとLLMノードのどちらを使うかを決定していた。
しかし、この単純なルールでは「実際にナレッジベースに有用な情報があるかどうか」を考慮できず、RAGが有効かどうかの判断が不十分だった。
そこで今回は、クエリと知識ベースとの類似度をベクトル検索で評価し、その結果に応じてノードを分岐させるようロジックを改良した。
- 変更前(単純な文字列マッチ)
def classify_intent(state):
query = state["input"]
if "RAG" in query:
state["intent"] = "rag"
else:
state["intent"] = "llm"
return state
- 変更後(ベクトル検索に基づく判断)
def classify_intent(state):
query = state["input"]
# 検索によって知識ベースにどの程度マッチするか確認
retriever = vectorstore.as_retriever(search_kwargs={"k": 1})
retrieved_docs = retriever.invoke(query)
# 類似度スコア付きで取得できるならスコアで判断(今回は取得できない想定なのでテキストで判断)
if retrieved_docs and len(retrieved_docs) > 0:
# 簡易的に文字長で「それなりの知識がある」とみなす
if len(retrieved_docs[0].page_content) > 30:
state["intent"] = "rag"
else:
state["intent"] = "llm"
else:
state["intent"] = "llm"
return state
3. 重複ナレッジの検出と回避
これまでの実装では、LLMノードの出力をそのままナレッジとして登録していたため、同じような知識が重複登録されるリスクがあった。
今回の改善では、LLMが生成した新規ナレッジと既存ナレッジとの類似度をベクトルで計算し、重複と判断された場合は登録をスキップするようにした。
- 変更前
def llm_node(state):
user_input = state.get("input", "")
messages = [HumanMessage(content=user_input)]
response = llm.invoke(messages)
answer = response.content
# LLMの出力をナレッジベースに追加
conn = sqlite3.connect("knowledge.db")
c = conn.cursor()
c.execute("INSERT INTO knowledge (title, content) VALUES (?, ?)", (user_input, answer))
conn.commit()
conn.close()
return {"response": answer}
- 変更後
def llm_node(state):
user_input = state.get("input", "")
messages = [HumanMessage(content=user_input)]
response = llm.invoke(messages)
answer = response.content
# 重複チェック(ここを追加)
if is_duplicate_knowledge(answer):
response_text = f"(※この内容は既にナレッジとして登録されています)\n{answer}"
else:
# DB保存
conn = sqlite3.connect("knowledge.db")
c = conn.cursor()
c.execute("INSERT INTO knowledge (title, content) VALUES (?, ?)", (user_input, answer))
conn.commit()
conn.close()
# Chromaへの追加(これを行わないと次回検索で使えない)
new_doc = Document(page_content=f"{user_input}\n{answer}")
vectorstore.add_documents([new_doc])
response_text = answer
return {"response": response_text}
- 類似度判定ロジック
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
def is_duplicate_knowledge(new_content: str, threshold: float = 0.85) -> bool:
# 既存知識取得
conn = sqlite3.connect("knowledge.db")
c = conn.cursor()
rows = c.execute("SELECT title, content FROM knowledge").fetchall()
conn.close()
if not rows:
return False
# 文章をDocumentにしてベクトル化
documents = [Document(page_content=f"{title}\n{content}") for title, content in rows]
splitter = CharacterTextSplitter(chunk_size=500, chunk_overlap=50)
docs = splitter.split_documents(documents)
docs_contents = [doc.page_content for doc in docs]
# ベクトル化
existing_vecs = embedding.embed_documents(docs_contents)
new_vec = embedding.embed_query(new_content)
# 類似度計算
sims = cosine_similarity([new_vec], existing_vecs)[0]
max_sim = np.max(sims)
return max_sim >= threshold
4. まとめ
今回は、前回作成したLangGraphベースの対話エージェントに対して、以下の2点を中心に機能拡張を行った:
- ナレッジ検索の精度向上
- 重複ナレッジの検出と回避
これらの改善により、ナレッジベースを信頼性高く成長させるための土台が整った。
特に、自然文における意味の類似性評価は、RAGやナレッジエンジンを構築する上で不可欠な技術である。
次回は、以下のような実用面での発展に取り組む予定である:
- RAGに格納するナレッジの収集方法の検討と実装
- 対話エージェントとのやり取りを行うUI(ユーザーインターフェース)の構築