【分散型アーキテクチャを試してみる】第2章 〜Apache Ambari,Hadoop,YARN,Zookeeper,Spark編〜
あらすじ
最近は日本にいなかったり、インタビューや講演ばっかり受けてて、Qiitaサボリ気味でしたが、少しずつ再開しようと思ってます。
膨大なデータを取り扱ったり、大規模向けシステムが当たり前になってきている中、機会がないと触れることがない分散型アーキテクチャを試してみようという事で、勉強会で使った資料を公開していきます。
※後々、リクエストに応じて更新することが多いのでストックしておくことをおすすめします。
自分は某社でCTOをしていますが、頭でっかちに理論ばっかり学習するよりは、イメージがなんとなく掴めるように学習し、実践の中で知識を深めていく方が効率的に学習出来ると考えています。
未経験者の教育についてインタビューされた記事もあるので紹介しておきます。ご興味ある方は御覧ください。
エンジニアは「即戦力」より理念に共感した「未経験者」を育てるほうが費用対効果が高い。
教育スタイルとしては正しい事をきっちりかっちり教えるのではなく、未経験レベルの人がなんとなく掴めるように、資料を構成していきます。
以下のようなシリーズネタで進めます。
では、今回もはじめていきましょう!
はじめに
今回はこのような構成でvagrant上のcentos使って構築してみます。
いつもの通りに学習するためにAnsibleでベースは作って一部は手動で構築にしています。

| No. | hostname | ip | 備考 |
|---|---|---|---|
| 1 | node1 | 172.168.1.11 | マスターノード |
| 2 | node2 | 172.168.1.12 | ノード |
| 3 | node3 | 172.168.1.13 | ノード |
前回と同様に、個別の簡単な紹介を行った後に、能書きも程々に実際に環境構築をしてみます。
サービスを個別に構築するのは地味なので、今回はAmabariを使った構築をしてみます。
実際に勉強会で使ったソースも公開しておきます。
追記:2016/07/21にambari 2.1.1から2.2.2に変更してます
Apache Hadoopとは
Apache Hadoopは大規模データの分散処理を支えるオープンソースのソフトウェアフレームワークであり、Javaで書かれている。自分で構築して、運用しようとすると結構ずっしりくるボリューム。
Apache Ambari
一回使ったらもう病みつきになるやつです。ボクはもう自力でHadoopは構築しません。はいっ。
Hadoopクラスタのプロビジョニング
Ambariは、任意の数のホスト全体でのHadoopサービスをインストールするためのステップバイステップのウィザードが用意されています。
Hadoopクラスタの一元管理
Ambariは、起動、停止、およびクラスタ全体のHadoopサービスを再構成するための集中管理を提供します。
Hadoopクラスタの監視
Hadoopクラスタを監視します
Ambariは、Hadoopクラスタの稼動状況を監視するためのダッシュボード、データの収集のためのメトリックシステム、監視システムを提供します。
Hadoop YARN
YARNは、"Yet-Another-Resource-Negotiator"の略です。任意の分散処理フレームワークやアプリケーションの作成を容易にする新しいフレームワーク。YARNは、汎用的な分散アプリケーションの開発や、そのようなアプリケーションからの(メモリやCPUといった)リソース要求のハンドリング、スケジューリングを行い、実行を監督するためのデーモンとAPIを提供します。
Apache ZooKeeperとは
分散アプリケーション向けの高パフォーマンスなオーケストラサービス。同期, 設定管理, グルーピング, 名前管理, などの機能を提供する。
リーダー
Zookeeper サーバーのクラスタの1つが、すべての書き込み処理・受理するリーダーとなる。他のサーバーはマスターのリードオンリーレプリカ。マスターがダウンするとどれか他のサーバーが代理となって直ちにリクエストの処理を続行するスタンバイサーバーが読み込みを処理することができる。
Apache Sparkとは
クラスターコンピューティングフレームワーク。Hadoopよりも、インラインキャッシュ使えるので、繰り返し行う計算処理に強い。短い処理が得意。
対応言語
- Java
- Scala
- Python
- R
これだけの対応があるとSpark Application書こうと思うよね。うん。助かる。
やってみよう
能書きもほどほどにやってみましょう。
事前準備
基本的には、githubからcloneしてvagrant upだけですが
勉強会で少しでもコマンドなれるために、dockerだけは手動で入れてもらいました。
$ mkdir {対象フォルダ}
$ cd {対象フォルダ}
$ git clone https://github.com/TEMONA/hadoop_spark_cluster.git
$ cd hadoop_spark_cluster
$ vagrant up
$ vagrant reload
手動作業
作業はnode1です。
$ vagrant ssh node1
$ sudo su -
パスワードなしログイン対応
node1でrootにて作業。
以下の#のコマンドを実行していってください。
鍵生成
# ssh-keygen
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Created directory '/root/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
公開鍵設置
※vagrantなので聞かれるパスワードはvagrantです
node1
# ssh-copy-id root@node1
The authenticity of host 'node1 (172.168.1.11)' can't be established.
ECDSA key fingerprint is .
Are you sure you want to continue connecting (yes/no)? yes
/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@node1's password:
Number of key(s) added: 1
node2
# ssh-copy-id root@node2
The authenticity of host 'node2 (172.168.1.12)' can't be established.
ECDSA key fingerprint is .
Are you sure you want to continue connecting (yes/no)? yes
/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@node2's password:
Number of key(s) added: 1
node3
# ssh-copy-id root@node3
The authenticity of host 'node3 (172.168.1.13)' can't be established.
ECDSA key fingerprint is .
Are you sure you want to continue connecting (yes/no)?
/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@node3's password:
Number of key(s) added: 1
パスワードなしログイン確認
node1
# ssh root@node1
Welcome to your Vagrant-built virtual machine.
node2
# ssh root@node2
Welcome to your Vagrant-built virtual machine.
node3
# ssh root@node3
Welcome to your Vagrant-built virtual machine.
Ambari Serverのインストール
引き続きnode1での作業です。
対話式スクリプトでセットアップされます。
今回は全てデフォルトなので聞かれるたびにEnterを押してください。
# ambari-server setup
Ambari Server起動
# ambari-server start
実際に試してみる
Hadoopクラスタのセットアップ
http://172.168.1.11:8080/
にブラウザでアクセスしましょう。
ログイン
Username:admin
Password:admin
でログインしてみましょう。

Launch Install Wizard
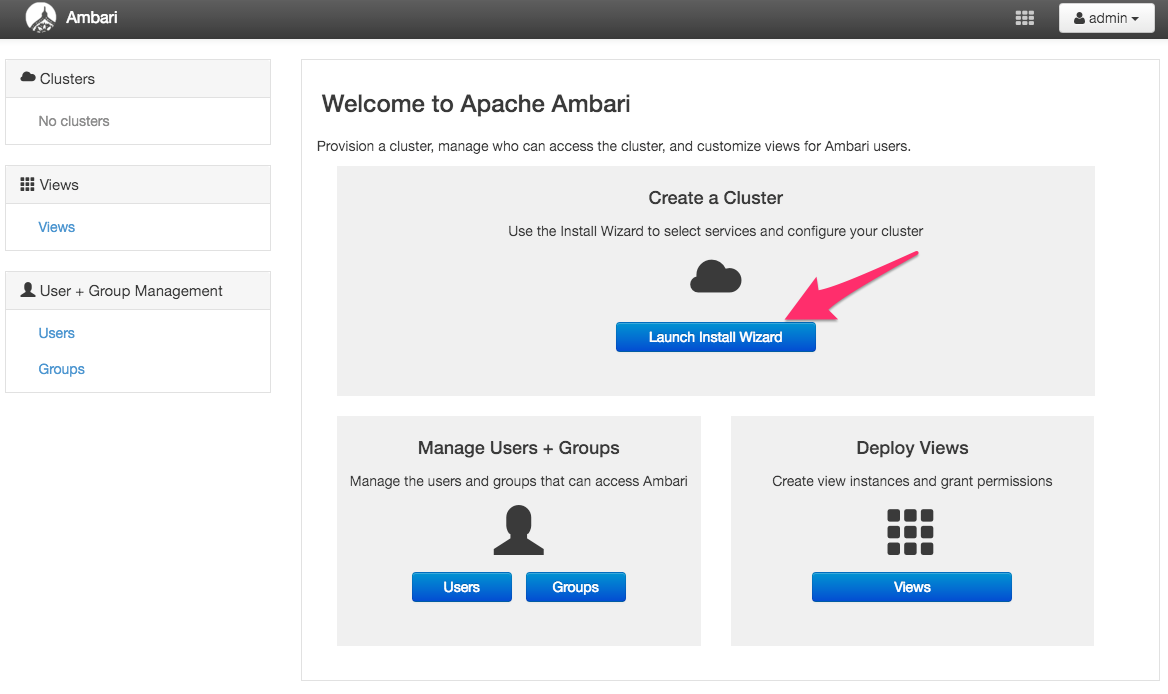
クラスタ名設定
作るクラスタの名前を設定しましょう。
cluster name: test_cluster
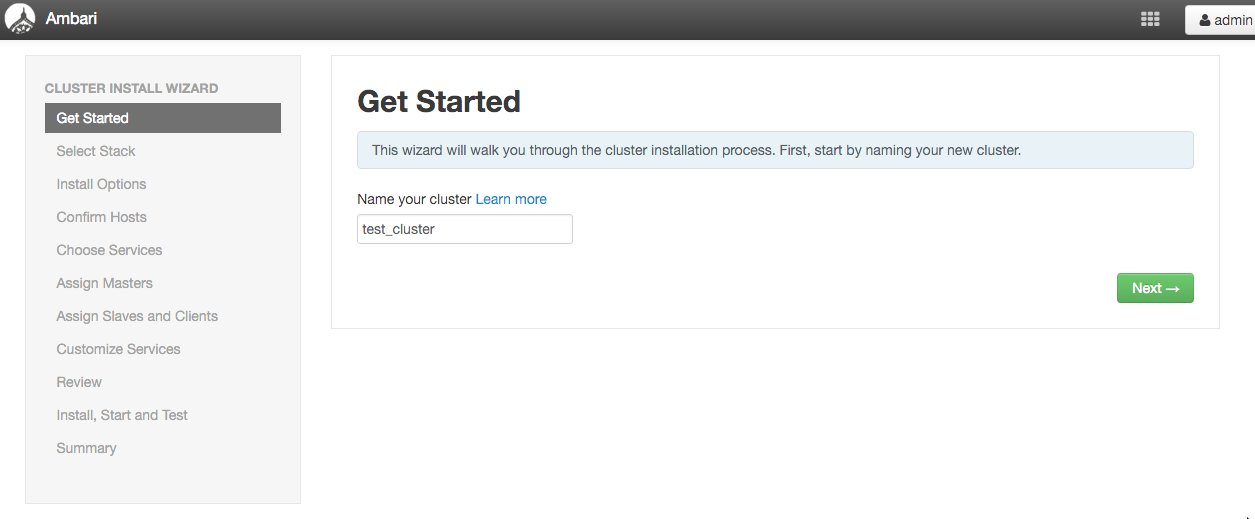
Stack
Hadoopクラスタのバージョンを選択しましょう。
迷わずHDP2.4
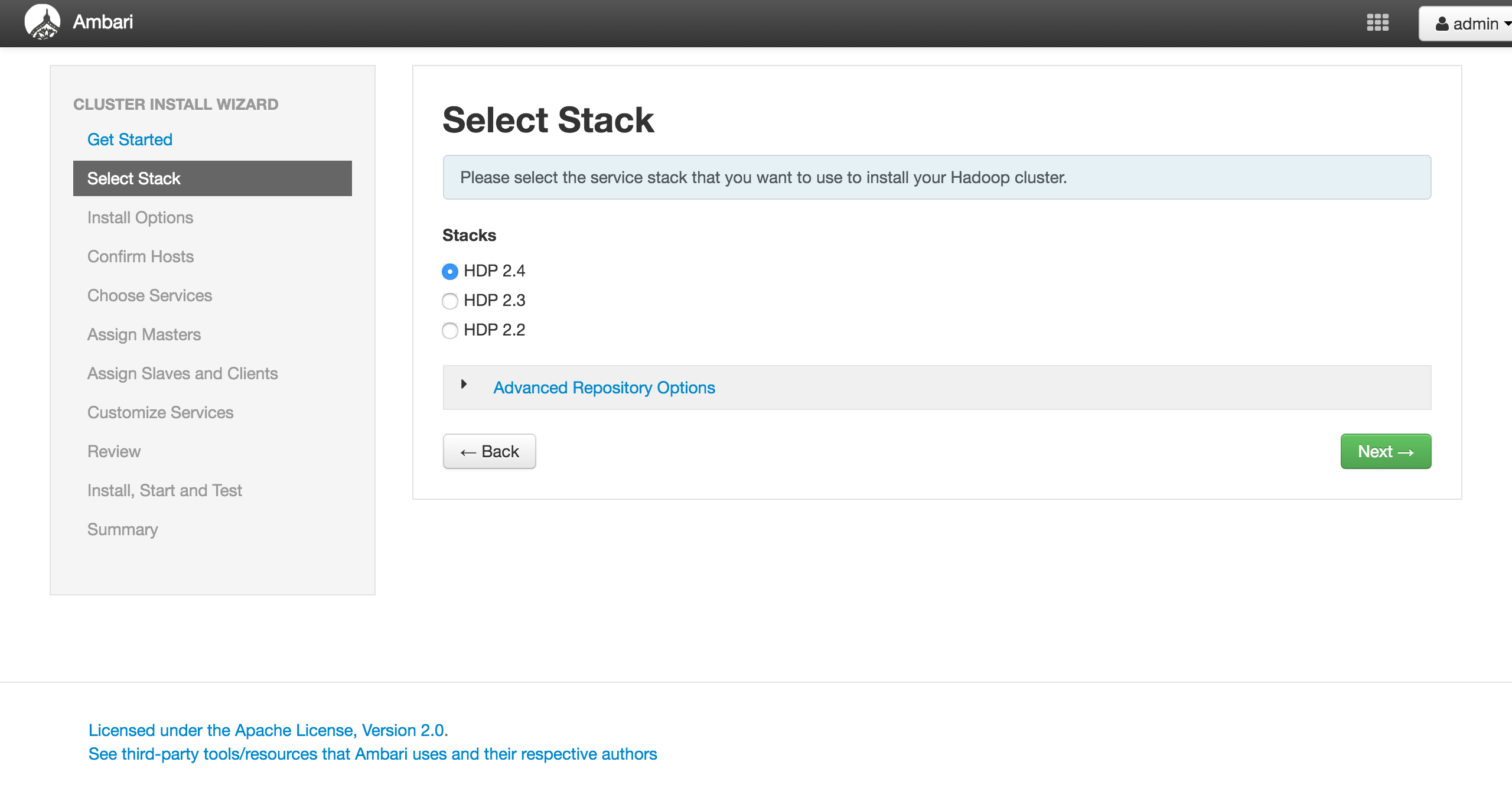
Install Options
クラスタを構築するノードの設定とSSHでログインするための秘密鍵を設定します。
Target Hostsは
- node1
- node2
- node3
です。
秘密鍵は、node1にログインした後に以下のコマンドで表示される内容をコピーして
テキストエリアに貼り付けましょう。
# cat ~/.ssh/id_rsa
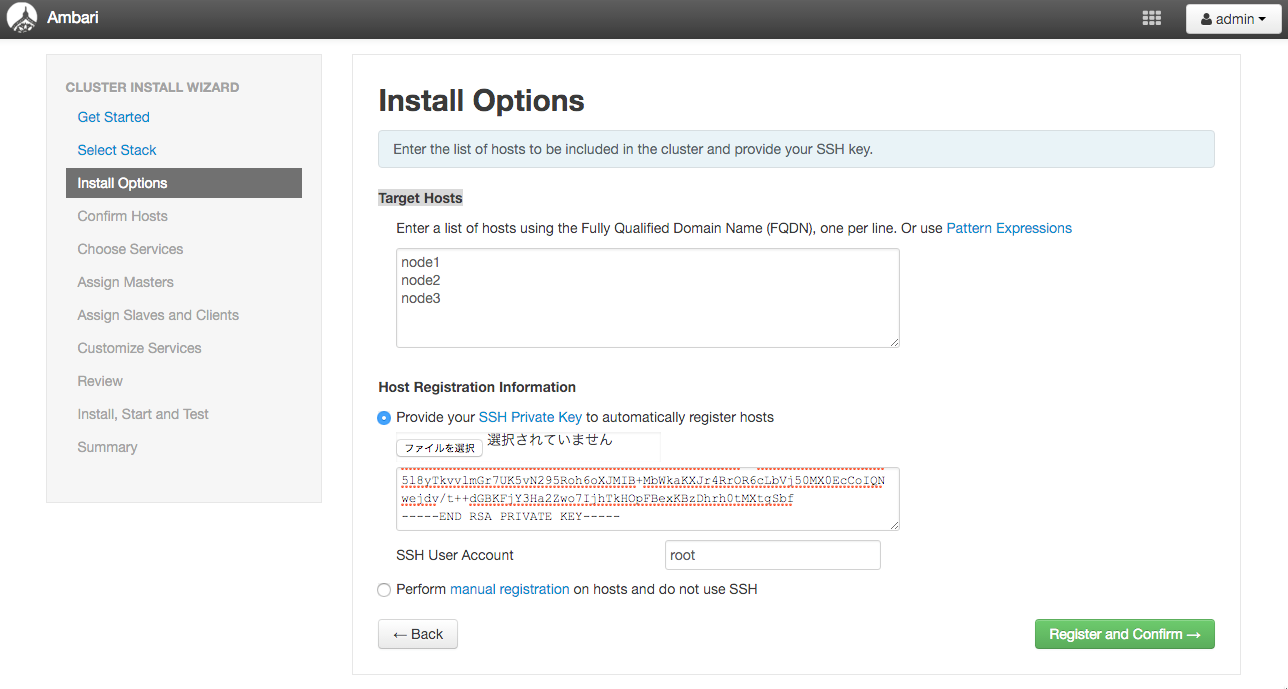
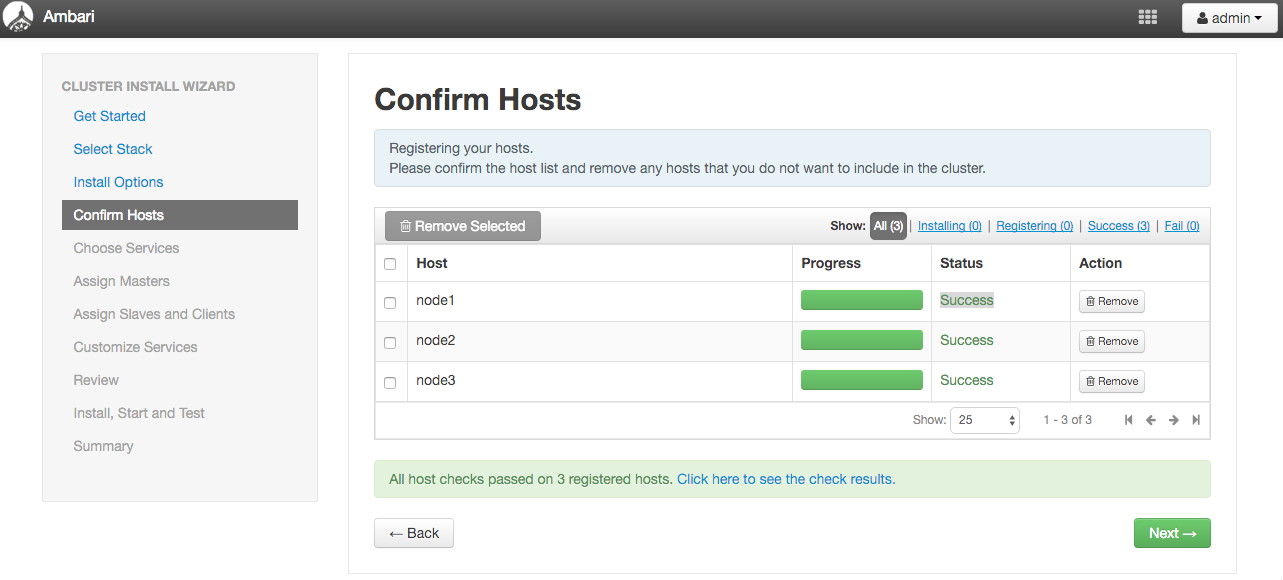
Confirm Hosts
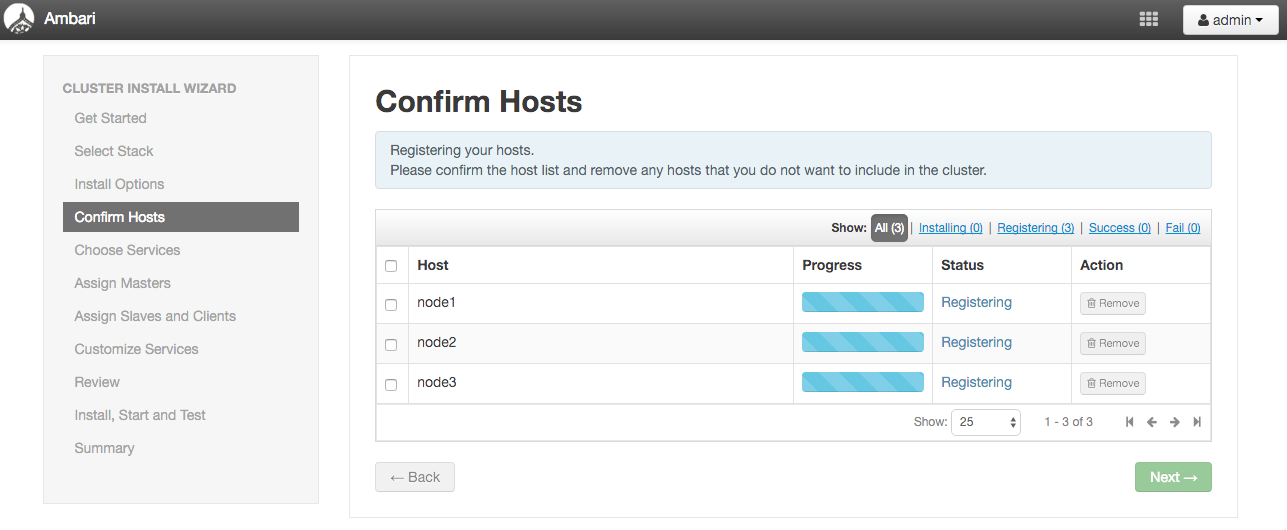
上手くいくとStatusがSuccessになります。
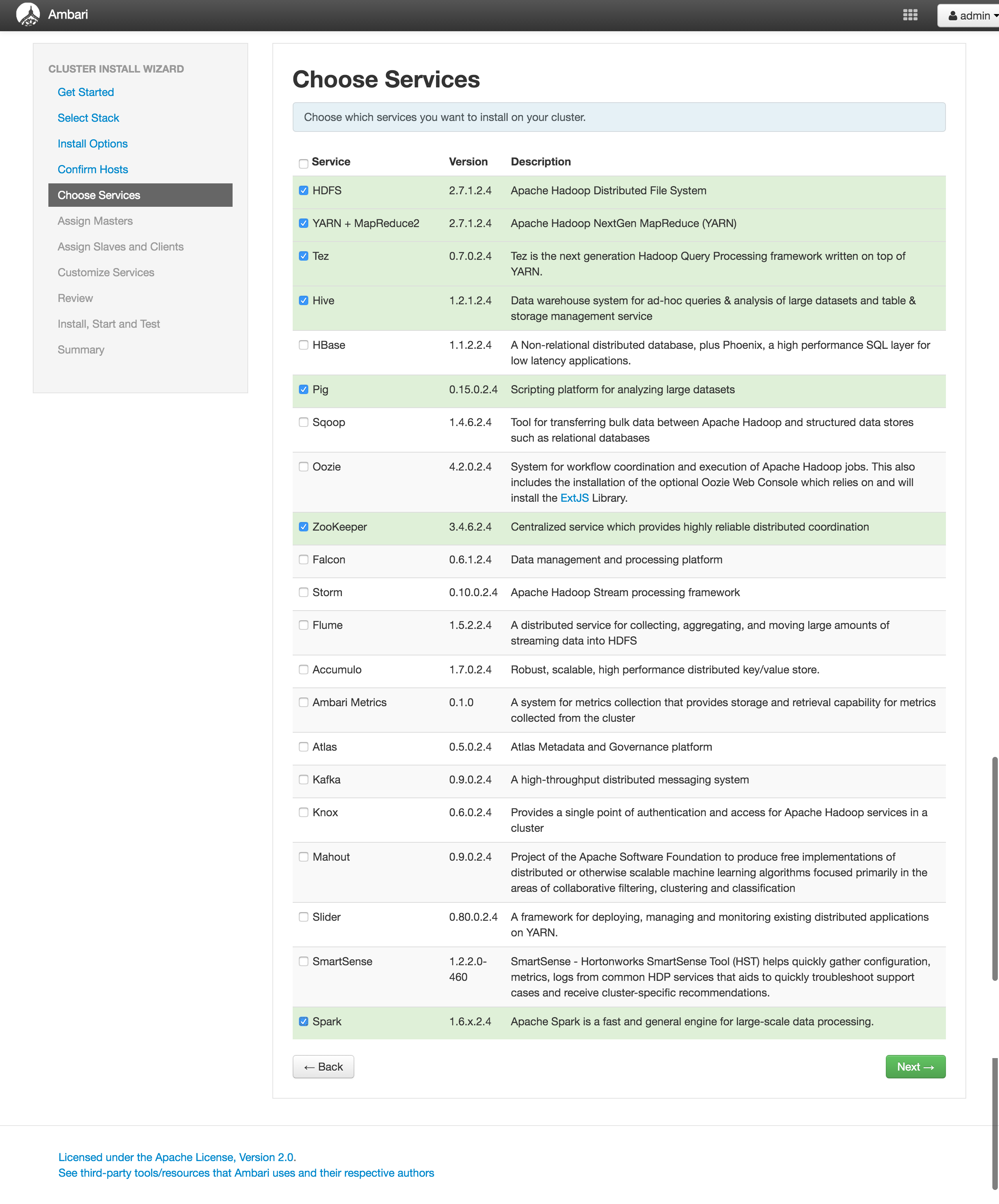
Choose Services
Hadoopクラスタをどのようなサービスで構成するかを選択します。
とりあえず鉄板で説明するので以下をチェックしてみましょう。
- HDFS
- YARN + MapReduce2
- Tez
- Hive
- Pig
- Zookeeper
- Ambari Metrics
- Spark
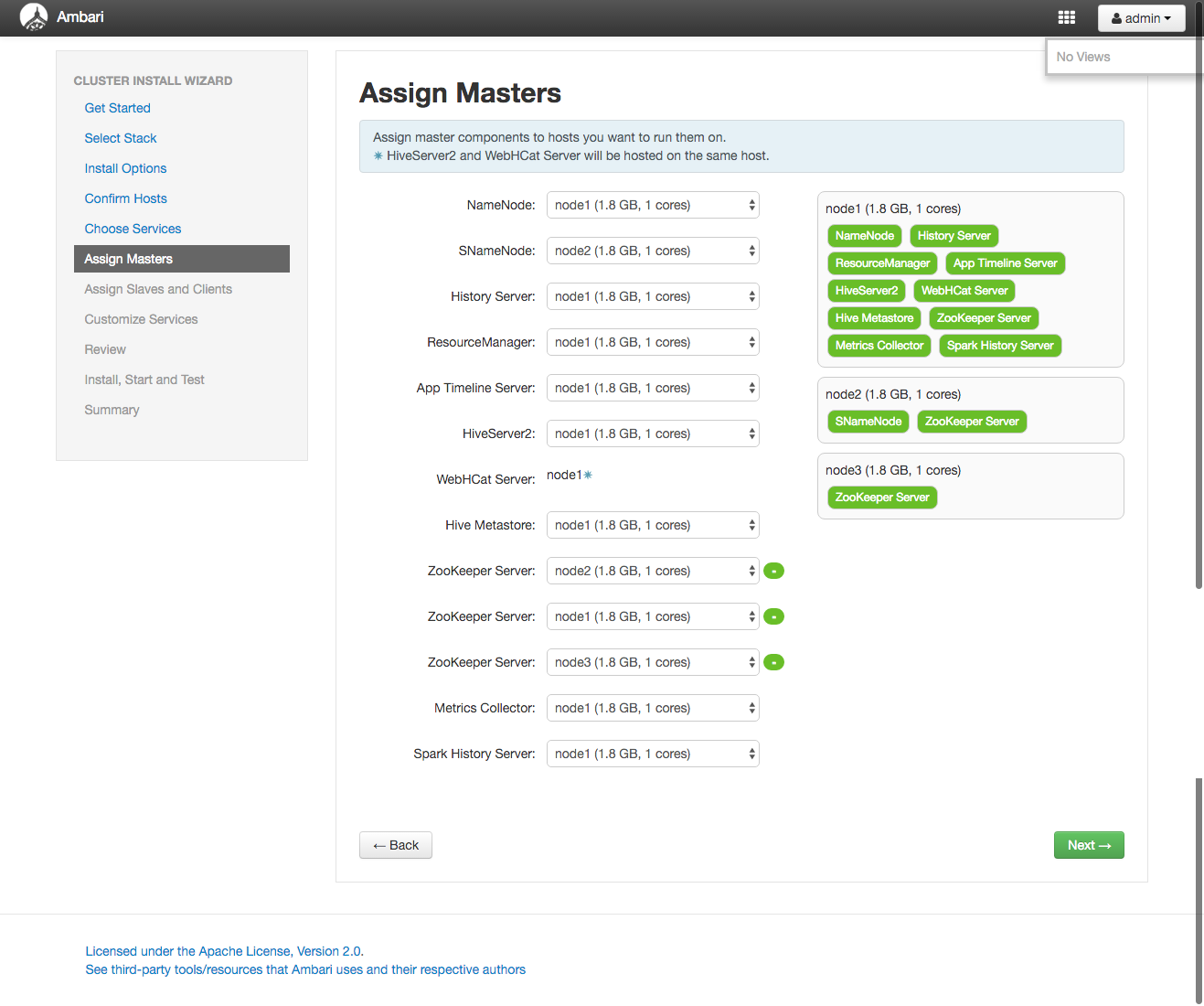
Assign Masters
| Role | Node |
|---|---|
| NameNode | node1 |
| SNameNode | node2 |
| History Server | node1 |
| ResourceManager | node1 |
| App Timeline Server | node1 |
| HiveServer2 | node1 |
| WebHCat Server | node1 |
| Hive Metastore | node1 |
| ZooKeeper Server | node1 |
| ZooKeeper Server | node2 |
| ZooKeeper Server | node3 |
| Metrics Collector | node1 |
| Spark History Server | node1 |
SNameNodeはnode2
zookeeperも推奨構成の3ノード構成
それ以外はnode1
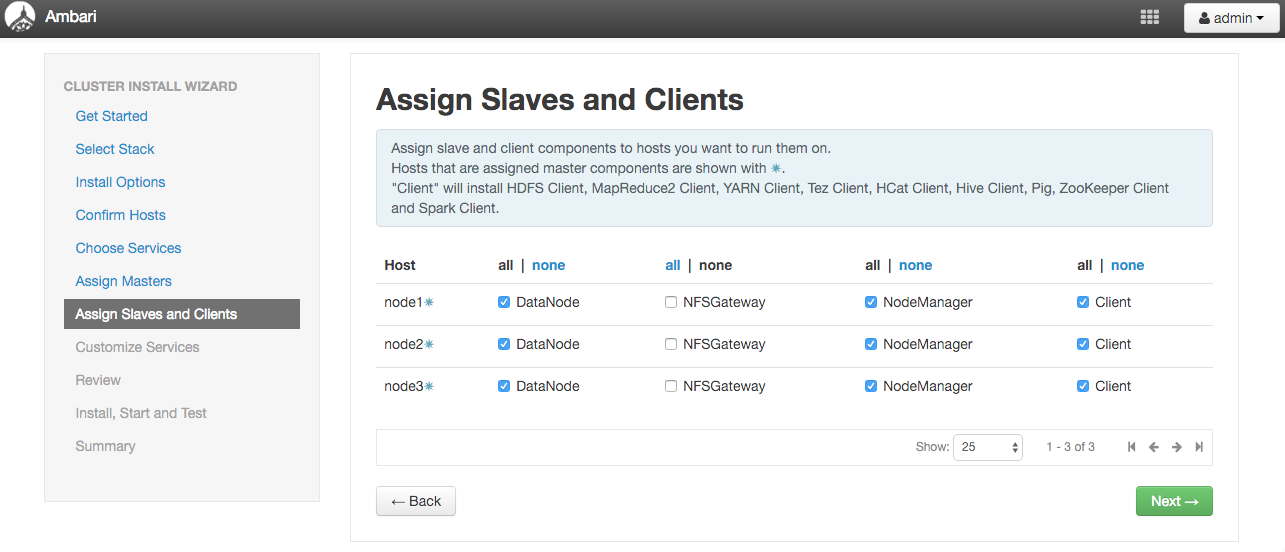
Assign Slaves and Clients
スレーブの役割をどこにするかを設定します。
今回はHadoopのHDFSのデータノードとしては、全部のサーバでデータを共有させ
ノードマネージャとしても機能させます。
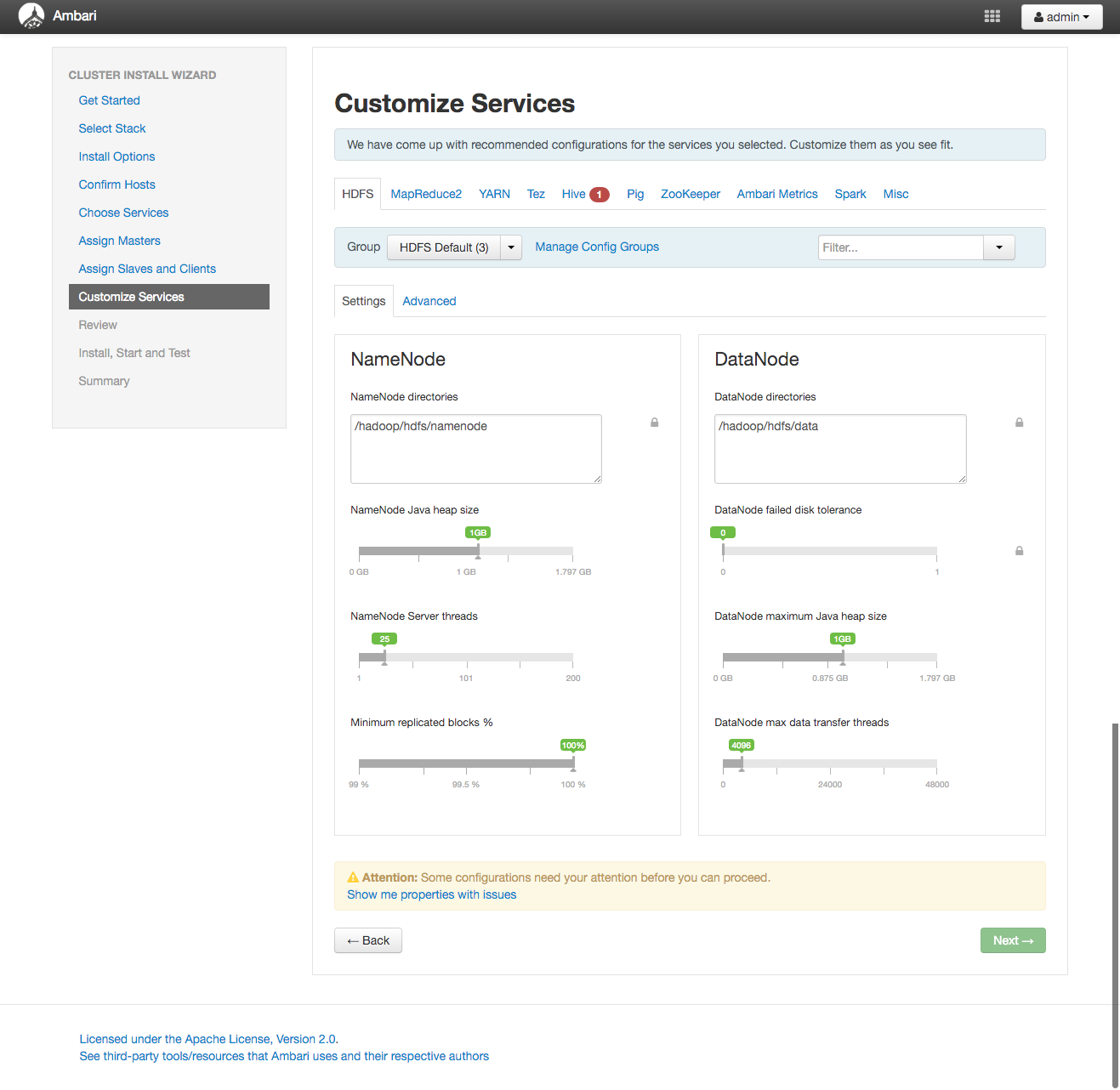
Customize Services
各種サービスに関するリソースの割当やパラメータを変更する必要がある場合は
ここのページで設定をします。
今回は必要最低限のHiveが使うMySQLのパスワードだけ設定します。
タブからHiveを選択してAdvancedの押下しましょう。
もしくはページ下部に出ているAttentionメッセージからShow me propertioes with issuesから移動してもOKです。
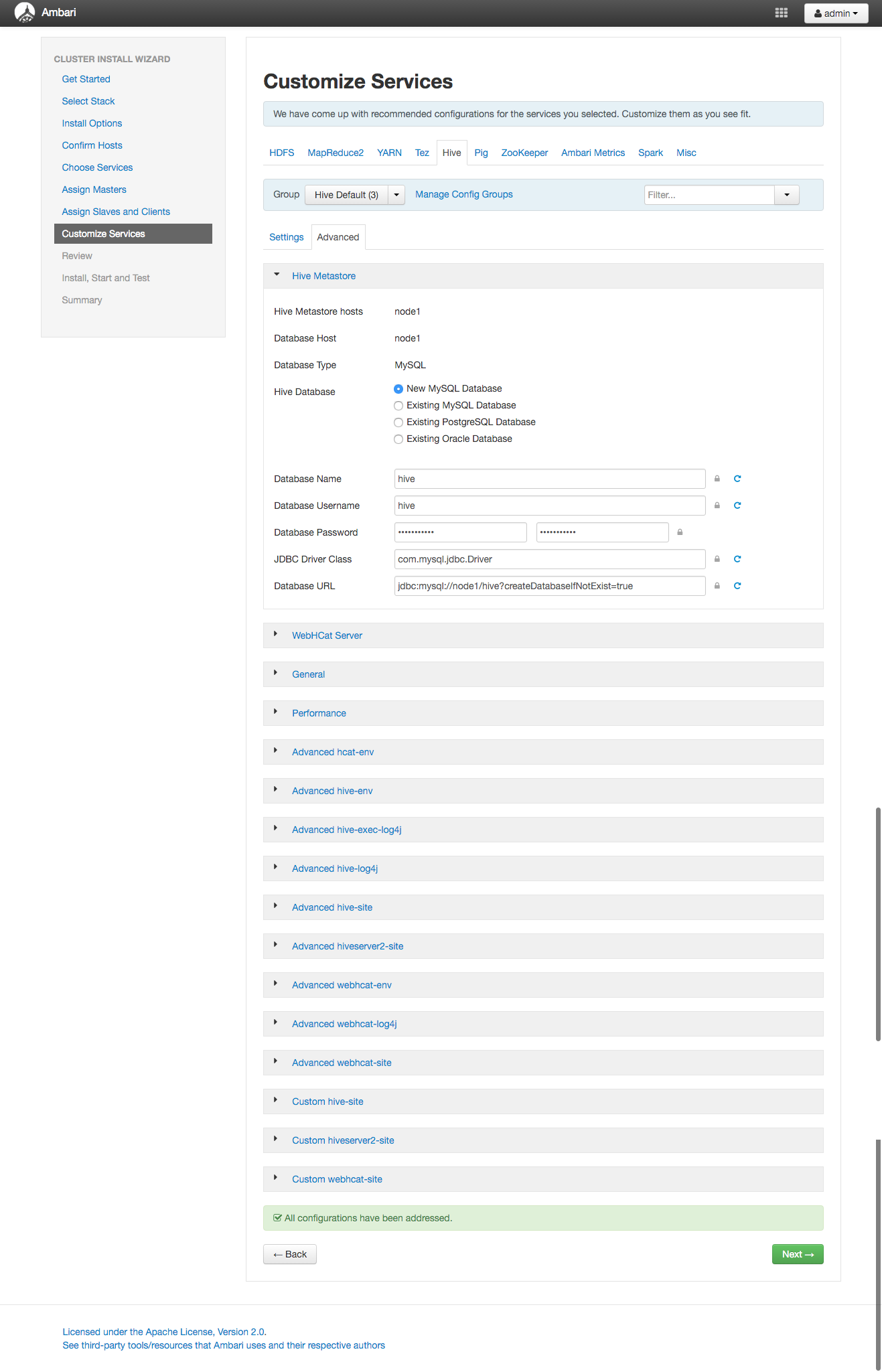
Vagrantの環境で非力なマシンリソース割り当てしているのでWarningが出ますが無視して進めてください。
Review
今回構築する設定内容が表示されます。
あともうちょっと、頑張ってください。
Admin Name : admin
Cluster Name : test_cluster
Total Hosts : 3 (3 new)
Repositories:
redhat6 (HDP-2.3):
http://public-repo-1.hortonworks.com/HDP/centos6/2.x/updates/2.3.6.0
redhat6 (HDP-UTILS-1.1.0.20):
http://public-repo-1.hortonworks.com/HDP-UTILS-1.1.0.20/repos/centos6
redhat7 (HDP-2.3):
http://public-repo-1.hortonworks.com/HDP/centos7/2.x/updates/2.3.6.0
redhat7 (HDP-UTILS-1.1.0.20):
http://public-repo-1.hortonworks.com/HDP-UTILS-1.1.0.20/repos/centos7
suse11 (HDP-2.3):
http://public-repo-1.hortonworks.com/HDP/suse11sp3/2.x/updates/2.3.6.0
suse11 (HDP-UTILS-1.1.0.20):
http://public-repo-1.hortonworks.com/HDP-UTILS-1.1.0.20/repos/suse11sp3
Services:
HDFS
DataNode : 3 hosts
NameNode : node1
NFSGateway : 0 host
SNameNode : node2
YARN + MapReduce2
App Timeline Server : node1
NodeManager : 3 hosts
ResourceManager : node1
Tez
Clients : 3 hosts
Hive
Metastore : node1
HiveServer2 : node1
WebHCat Server : node1
Database : MySQL (New Database)
Pig
Clients : 3 hosts
ZooKeeper
Server : 3 hosts
Ambari Metrics
Metrics Collector : node1
Spark
History Server : node1
Install, Start and Test
デプロイが開始されたら表示されるページです。
プログレスバーで進捗が確認出来ます。
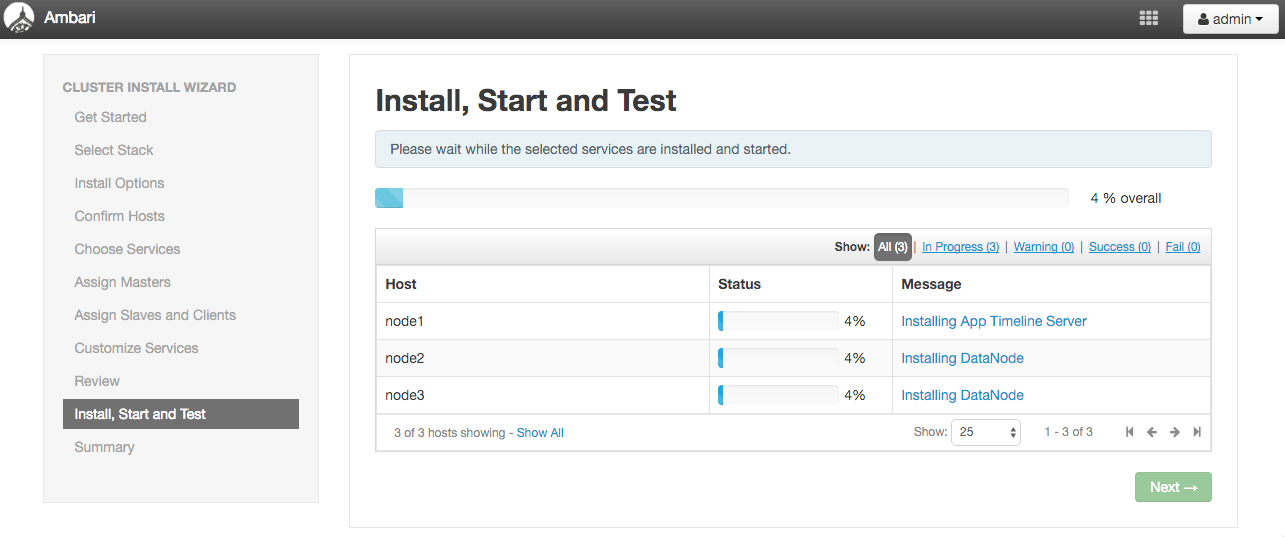
自分の手元では15分程度かかりました。
Summary
結果が表示された後に、データのローディングとなります。
メモリとかが足りず、起動出来ない場合は以下のように
mac側のVagrantfileを編集してあげてください。
VMの停止
$ vagrant halt
Vagrantfileの修正
$ vi Vagrantfile
以下をのメモリを編集。
---
cluster = {
"node1" => { :ip => "172.168.1.11", :cpus => 1, :mem => 2048 },
"node2" => { :ip => "172.168.1.12", :cpus => 1, :mem => 2048 },
"node3" => { :ip => "172.168.1.13", :cpus => 1, :mem => 2048 },
}
---
VMマシン起動
$ vagrant up
編集後記
前回と違って今回はambariを使って構築しています。
ansibleやchefを使ってぐりぐりとコンパイルして構築してもいいですが
分散アーキテクチャ周りは依存関係が多いのでambariなどを使うとだいぶ幸せになります。
次回以降はSparkの話を少しだけ紹介したいと思います。