【分散型アーキテクチャを試してみる】第1章 〜Apache Mesos,Zookeeper,Marathon,Chronos編〜
あらすじ
最近は日本にいなかったり、インタビューや講演ばっかり受けてて、Qiitaサボリ気味でしたが、少しずつ再開しようと思ってます。
膨大なデータを取り扱ったり、大規模向けシステムが当たり前になってきている中、機会がないと触れることがない分散型アーキテクチャを試してみようという事で、勉強会で使った資料を公開していきます。
※後々、リクエストに応じて更新することが多いのでストックしておくことをおすすめします。
自分は某社でCTOをしていますが、頭でっかちに理論ばっかり学習するよりは、イメージがなんとなく掴めるように学習し、実践の中で知識を深めていく方が効率的に学習出来ると考えています。
未経験者の教育についてインタビューされた記事もあるので紹介しておきます。ご興味ある方は御覧ください。
エンジニアは「即戦力」より理念に共感した「未経験者」を育てるほうが費用対効果が高い。
教育スタイルとしては正しい事をきっちりかっちり教えるのではなく、未経験レベルの人がなんとなく掴めるように、資料を構成していきます。
以下のようなシリーズネタで進めます。
では、今回もはじめていきましょう!
はじめに
今回はこのような構成でvagrant上のubuntu使って構築してみます。

slaveノードがsparkになっているのは気にしないでください。
実際の勉強会ではspark clusterも制御する感じにしたのでそういう命名規則になっています
| No. | hostname | ip | 備考 |
|---|---|---|---|
| 1 | mesos1 | 172.168.1.11 | マスターノード |
| 2 | mesos2 | 172.168.1.12 | マスターノード |
| 3 | mesos3 | 172.168.1.13 | マスターノード |
| 4 | spark1 | 172.168.1.21 | スレーブノード |
| 5 | spark2 | 172.168.1.22 | スレーブノード |
| 6 | spark3 | 172.168.1.23 | スレーブノード |
個別の簡単な紹介を行った後に、能書きも程々に実際に環境構築をしてみます。
時間の関係上で、自動で構築する部分は適当に、dockerは手動でいれてみるって想定で進めました。
実際に勉強会で使ったソース
も公開しておきます。
はじめに断っておきますが、勉強会のネタ用にレポジトリ作りましたが糞極まりないソース です。
前日にあぁだこうだやりながら、スレーブの数とかマスターの数を変えながらベンチマーク取るのに作ったので即興ソースですみません。誰か好きにリファクタしてください。
Apache Mesosとは
Hadoopのような分散アプリケーションを複数のノード上で動かすためもクラスタ管理ツール。
簡単な違い
・Hadoop YARN
JAVA製。リソース分配のベースはメモリ。管理対象はプロセス。
・Apache Mesos
C++製。リソース分配はCPUとメモリ。管理対象はLXCコンテナ。
Apache ZooKeeperとは
分散アプリケーション向けの高パフォーマンスなオーケストラサービス。同期, 設定管理, グルーピング, 名前管理, などの機能を提供する。
リーダー
Zookeeper サーバーのクラスタの1つが、すべての書き込み処理・受理するリーダーとなる。他のサーバーはマスターのリードオンリーレプリカ。マスターがダウンするとどれか他のサーバーが代理となって直ちにリクエストの処理を続行するスタンバイサーバーが読み込みを処理することができる。
Marathon
Dockerのオーケストレーションサービス。Mesos自体は短い時間での分散処理に特化しているので、永続稼働するような分散管理は弱い。MarathonでDockerのコンテナを使った永続稼働を実現する。
利用用途
所謂マイクロサービスアーキテクチャ的な構成。Sinatraのような軽いフレームワークサービスであったり、RailsのようなアプリケーションサーバをDockerでコンテナ運用する際にはすごく重宝する。
Chronos
ChronosはMesosのクラスタ上でcronの一括管理をするシステム。10分に1回繰り返し何かをやるとか、1日毎に何か処理を走らせるなどが出来る。
やってみよう
能書きもほどほどにやってみましょう。
事前準備
基本的には、githubからcloneしてvagrant upだけですが
勉強会で少しでもコマンドなれるために、dockerだけは手動で入れてもらいました。
$ mkdir {対象フォルダ}
$ cd {対象フォルダ}
$ git clone https://github.com/TEMONA/mesos_cluster.git
$ cd mesos_cluster
$ vagrant up
$ vagrant reload
6台構築すると後ろで構築させても2時間程度かかります
※vagrantのプロビジョンでネットワークの関係などで落ちた場合はvagrant provisionで個別に再実行してください
手動作業
作業はspark1,spark2,spark3です。
Macから以下のようにvagrant上に作ったマシンにログインして
Dockerをインストールしてみましょう。
$ vagrant ssh spark1
Dockerのインストール
$ sudo wget -qO- https://get.docker.com/ | sh
$ sudo usermod -aG docker $USER
実際に試してみる
Mesosとzookeeper
vagrantで無事に環境が構築出来たら、MesosMasterの管理画面にアクセスしてみましょう。
ブラウザで各マシンのURLにアクセスしてみましょう。
http://172.168.1.11:5050/
http://172.168.1.12:5050/
http://172.168.1.13:5050/
下記の画像のようにMesosMaster3台の中でZookeeperによって
リーダーが選出されているのがわかると思います。
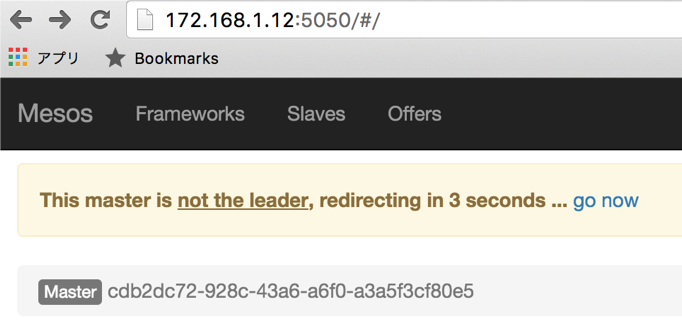
リーダーを停止させてみる
ブラウザでマスターになっているマシンを確認したら、そのマシンにvagrant sshでログインして
mesos-masterを停止させてみましょう。
$ sudo service mesos-master stop
再度ブラウザからMesos Masterの管理画面にアクセスしてみましょう。
http://172.168.1.11:5050/
http://172.168.1.12:5050/
http://172.168.1.13:5050/
他のMesos Masterのスタンバイマシンがリーダーに選出されたのがわかりましたか?
停止させたマシンの画面はリダイレクトされないのが正しいです。
Marathon
では次にDockerのオーケストレーションサービスのMarathonを試してみましょう。
今回はslaveノードに8080ポートにWEBアプリケーションをイメージしたものを試してみます。
Mesos masterのリーダーとなっているマシンの
http://172.168.1.1x:8080/
にアクセスしてみましょう。
アプリケーション新規作成
管理画面にアクセスしたら、画面右上の「Create Application」の青いボタンをクリックしましょう。
| 項目 | 内容 |
|---|---|
| ID | hello-world |
| Instances | 1 |
| Command | while true; do ( echo "HTTP/1.0 200 Ok"; echo; echo "Hello World" ) |
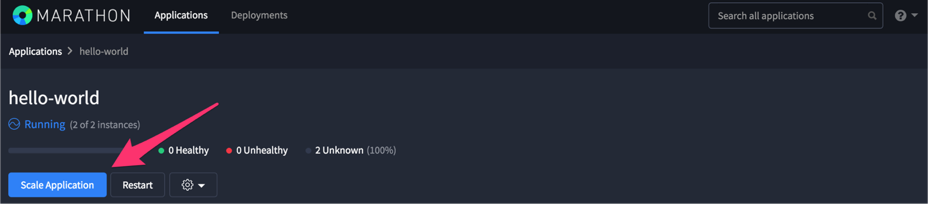
無事にデプロイが終わると
以下の画像のようにStatusがRuningでアプリケーションが追加されます。
アプリケーション名をクリックするとデプロイされたアプリケーションの詳細が表示されるので見てみましょう。

以下のURLのうち1つでHello Wolrdが表示されれば成功です。
http://172.168.1.21:8080/
http://172.168.1.22:8080/
http://172.168.1.23:8080/
スケールさせてみる
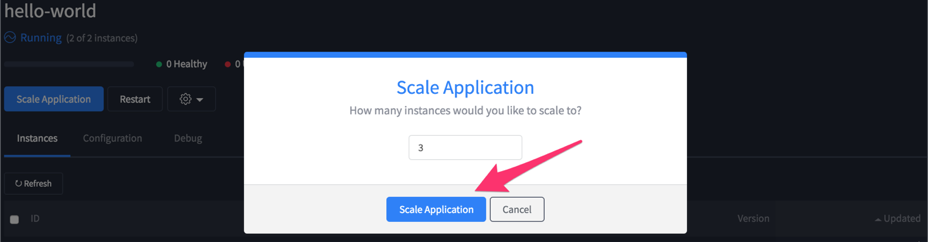
Applicationの詳細画面の画面中央左にある「Scale Application」をクリックしましょう。
モーダルが以下のように開くので
「1」から「2」に変更して「Scale Application」と押下します。
以下のURLのうち2つでHello Wolrdが表示されれば成功です。
http://172.168.1.21:8080/
http://172.168.1.22:8080/
http://172.168.1.23:8080/
Choronos
次にChronosを試して見ます。
同様にMesos Masterでリーダーのマシンにアクセスします。
http://172.168.1.1x:4040/
以下の画像のように、「New Job」を押下しましょう

ジョブ内容
| 項目 | 内容 |
|---|---|
| NAME | test-job |
| DESCRIPTION | testjob |
| Command | date >> /tmp/date.txt |
| Schedule | ∞ / 今日 / 時間(世界標準時)Z/P T5M |
世界標準時なので日本時間からマイナス9時間する必要があります
※T5Mは5分毎という表記です。
確認
Slaveのマシンにログインし
下記のコマンドを確認してみましょう。
$ cat /tmp/date.txt
今回の内容は以上で終わります。
編集後記
AWSのような便利なもの使えばいいじゃんって思う人も多くいると思いますが、どのような仕組みで動いているかを理解して使うのと、理解しないまま使うのだと大きく違うので、なるべく手元では自前で構築し、理解深めてから便利なものを使うようにしましょう。
今回の勉強会では
Marathonを使って、Dockerでアプリをデプロイ完了した瞬間に当社ベトナム人メンバが「すっげぇ」って歓声をあげていて、笑いました。
最近彼らも日本語を覚えてきて
「めっちゃ」、「むっちゃ」、「すげえ」という日本語は乱発してます。
次回は第2章 〜Apache Hadoop,YARN Zookeeper,Spark編〜を公開する予定です。