【新人教育 資料】SQLへの道 〜DB編〜
あらすじ
新人がいっぱい入ってくる。新人のレベルもバラバラ。教育資料も古くなっているので、更新しましょう。
どうせなら、公開しちゃえばいいじゃん。という流れになり、新人教育用の資料を順次更新していくことにしました。
※後々、リクエストに応じて更新することが多いのでストックしておくことをおすすめします。
自分はTEMONA株式会社でCTOをしていますが、頭でっかちに理論ばっかり学習するよりは、イメージがなんとなく掴めるように学習し、実践の中で知識を深めていく方が効率的に学習出来ると考えています。
※他の登壇やインタビュー記事はWantedlyから見てください。
教育スタイルとしては正しい事をきっちりかっちり教えるのではなく、未経験レベルの人がなんとなく掴めるように、資料を構成していきます。
以下のようなシリーズネタで進めます。
では、今回もはじめていきましょう!
DB(データベース)とは
今回からはSQLへの道題して、DB周りを勉強しSQLを学びましょうという内容でお送りします。DB、DBって当たり前のように会話が出てくるようになるので、業務で会話についていけるように勉強していきましょう。
DB(DataBase:データベース)とは、データの集まりです。以下のようなアイコンで表現されたりします。

データファイルが整理整頓されて格納されていて、DBMS(データベース管理システム)によって管理されています。
DBとDBMSをまとめてデータベースシステムという。
DBMSで管理されるデータとしては、大きく分けて以下の3つで構成されています。
- データ・ファイル
- ログ・ファイル
- コントロール・ファイル
難しい言葉がたくさん出てきますが、最終的にはデータの集まりだと認識してくれればいいと思います。
データベースは基本的に以下の特徴を持ちます。
- 特定のプログラムに依存しない。
- 構造や格納形式(Schema:スキーマ)が公開されている。
スキーマという言葉は頻出するのでちょっと調べておいてください。
データベースの種類
データベースの種類は色々あったりしますが、リレーショナル型データベースシステム(RMDBS)を勉強していきましょう。初めのうちは、それ以外のものは存在することだけ理解出来ていればOKです。
- リレーショナル型データベース
- PostgreSQL
- MySQL
- SQLite
- Microsoft SQL server
- oracle
- db2
- カラム指向型データベース(列指向型)
- PureData System for Analytics(旧Netezza)
- exadata
- SAP HANA
- Cassandra
- DynamoDB
- memcached
- redis
- bigtable
- hbase
- ドキュメント指向型データベース
- mongodb
- couchdb
- グラフデータベース
- neo4j
- 時系列データベース
- Graphite
- InfluxDB
- opentsdb
リレーショナル型データベース
複数のテーブルの集まり。個々のテーブルは、その他のテーブルとリレーション(関連性)を持つ。
まずはリレーショナル型データベースを使って勉強していく形にしましょう。
以下はチューニンニングなんかによってもだいぶ変わるのでなんともいえませんが、defaultで使った場合って感じで特徴書いておきます。
| 名称 | 概要 | 無償/有償 |
|---|---|---|
| PostgreSQL | 複雑クエリは得意。スケールアウトに弱い。基本はスケールアップで対応。 | 無償 |
| MySQL | WEBサーバなどの参照用には向いている。スケールアウト構成が柔軟に組める。 | 無償 |
| Microsoft SQL server | Microsoftの出しているDB、linuxでは動作しない。監査やセキリティ対応などは比較的容易に対応出来る | 有償 |
| oracle | linux上で動かす方が断然パフォーマンスがいい(昔の話かも!?)大規模向き。実はMySQLから移行出来るツールなんかもあったりする | 有償 |
| db2 | IBM製のDB。昔はくせがあったが、最近のバージョンは使いやすくなった印象。 | 有償 |
テーブルとは
行(column:カラム)と列(record:レコード)で構成される二次元の表。Excel等のスプレッドシートのようなものです。
リレーショナル型データベースの基本単位。
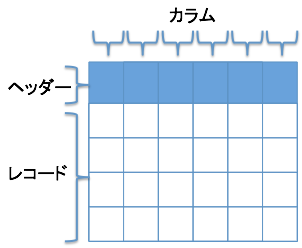
行指向と列指向(カラム型)
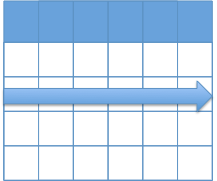
行指向データベース
1つの行をひとかたまりのデータとして扱う。1レコードずつ取り出し処理を行う。
例えば、「特定の条件をみたす行を検索して取り出す」等はよくある操作。
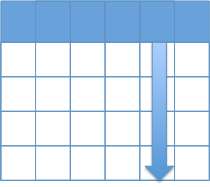
列指向(カラム型)データベース
1つの列をひとかたまりのデータとして扱う。
例えば、「テーブル内の全レコードに対し、あるカラムの値を一斉に更新する」等の操作に便利。特定の列に関する集計など、列に対してまとめて操作をするような処理が得意。
カラムとデータ型
テーブルをつくる時、どんなデータを入れるか構造を指定します。カラム型には以下のようなものがあります。
標準SQLでは定義されていますが、各RMDBにより異なるので、必ず事前に調べるようにデータ型の違いを調べるようにしましょう。
| 名称 | 例 | 概要 |
|---|---|---|
| SMALLINT | 真数型 | -32,768~32,767の整数 |
| INTEGER | 真数型 | -2,147,483,648~2,147,483,647の整数 |
| FLOAT [(p)] | 概数型 | 仮数部が-2p~2pの概数 |
| DOUBLE PRECISION | 概数型 | 8バイトの浮動小数点数 |
| REAL | 概数型 | 4バイトの浮動小数点数 |
| DECIMAL [(p [,q])] | 真数型 | 桁数p、小数点以下q桁のパック形式10進数 |
| NUMERIC [(p [,q])] | 真数型 | 桁数p、小数点以下q桁のゾーン形式10進数 |
| CHARACTER [(n)] | 文字列型 | 固定長でnn文字の文字列 |
| NATIONAL CHARACTER [(n)] | 各国語文字列型 | 固定長でnn文字の日本語文字列 |
| CHARACTER VARYING (n) | 文字列型 | 可変長でn最大n文字の文字列 |
| NATIONAL CHARACTER VARYING (n) | 各国語文字列型 | 可変長でn最大n文字の日本語文字列 |
| CHARACTER LARGE OBJECT *1 | CLOB型 | 指定された文字コードのデータで格納 |
| DATE | 日時型 | 年から日までの10文字の日付を格納 |
| TIMESTAMP [(p)] [WITH TIME ZONE] | 日時型 | 時から秒までの8文字の時刻を格納 |
| TIME [(p)] [WITH TIME ZONE] | 日時型 | 年から秒までの19文字の時刻印を格納 |
| INTERVAL | 時間隔修飾子 | 時間隔型 |
| BINARY LARGE OBJECT *1 | BLOB型 | バイナリ属性のデータを格納 |
| BIT [(n)] | BIT型 | 0,1,nullのデータを格納 |
| BIT VARYING (n) | BIT型 | 最大n文字までのビット列データを格納 |
| BOOLEAN *1 | BOOLEAN型 | true,false,unknownのデータを格納 |
インデックスとデータ
インデックス(索引)とは、テーブルに格納されているデータに素早くたどり着くための仕組みです。
本の索引のようなものだと理解しましょう。テーブルを作成する際に、カラムに対して必要に応じて定義します。
カラムに対して、インデックスを作成することを「インデックスを張る」とも言ったりします。
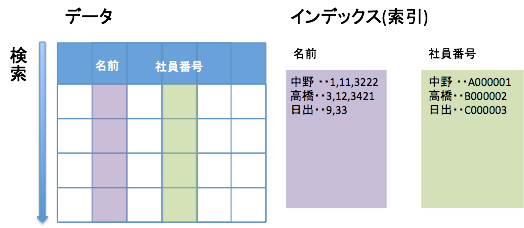
カラムに対して、やらためったらインデックスを張っても意味がありません。むしろ、テーブルに対して参照以外の操作をする際に合わせてインデックスを更新したりしなければならないため、遅くなったりします。またインデックスを保存するインデックスファイルの分だけ、ファイル容量も大きくなります。
開発の際には、実際に本番に近い想定データを用意し、利用したいSQLコマンドを試しながら、コマンドでRDBMSの統計情報からキャッシュヒット率がどうなっているが、カーディナリ値がどうなっているかなど、調べながらindexの張る事になります。
例)インデックスの種類
RDBMSによって異なりますが、インデックスにも種類があります。取りうる値の分布や特性に合わせてインデックスを選択しましょう。
- ビットマップインデックス
- Btreeインデックス
- ハッシュインデックス
標準SQL
SQL(エスキューエル)とは、リレーショナルデータベース管理システム(RDBMS)において、データに問い合わせるための言語です。
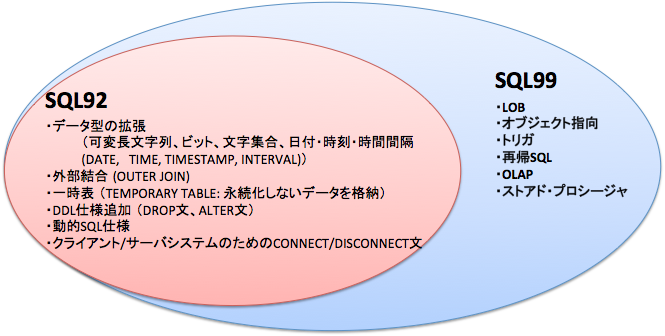
当初は、各RDBMSごとに言語の仕様が異なっていました。そこで、国際標準として規格化されています。その標準化された規格に合わせたものを標準SQLといいます。SQL92規格など呼ばれますが、SQL92規格、SQL99規格を押さえておけば大抵のSQLが使えます。SQL92規格などは一般公開されているものではないので、すぐにネットで取得するような事が出来ないのですが、書籍などでは解説しているものが多いため、興味がある人は購入をおすすめします。
日本でもJIS規格としてSQLが定義されているので興味がある人は見てください。
JISX3005-2
※Macだと見れないかもしれないです。
各種RDBMSも基本的には標準SQLに沿うように設計させています。実際に開発する際も特定のRDBMSに依存したSQLでなく、標準SQLをベースに使用することで、規模が大きくなった際にDBを他のものに移行させなければならなくなった時も少ない工数で対応することが出来ます。
自分の書いたSQLが標準SQLに準拠しているのかチェックしてくれるサイトなどもあるので、試してみると面白いです。
標準SQL92規格チェッカー
MySQLインストール
手元の学習環境として、リレーショナル型データベースのMySQLを使って勉強していきましょう。
本格的には「【新人教育 資料】SQLの道 〜SQL基本操作編〜」から使う予定ですが、先走ってMySQLをインストールしちゃいましょう。
HomeBrewインストール(入っている人はSKIP)
$ ruby -e "$(curl -fsSL https://raw.github.com/Homebrew/homebrew/go/install)"
【Mac】HomeBrewでバージョンを指定してMySQLインストール
brewのアップデート
$ brew update
MySQLのバージョン確認
% brew search mysql
automysqlbackup mysql mysql-connector-c++
homebrew/versions/mysql51 mysql++ mysql-sandbox
homebrew/versions/mysql55 mysql-cluster mysql-search-replace
homebrew/versions/mysql56 mysql-connector-c mysqltuner
homebrew/php/php53-mysqlnd_ms Caskroom/cask/mysql-connector-python
homebrew/php/php54-mysqlnd_ms Caskroom/cask/mysql-utilities
homebrew/php/php55-mysqlnd_ms Caskroom/cask/mysqlworkbench
homebrew/php/php56-mysqlnd_ms Caskroom/cask/navicat-for-mysql
brew
$ brew install homebrew/versions/mysql56
MySQL確認
$ brew info mysql
MySQL起動
$ mysql.server start
Starting MySQL
. SUCCESS!
MySQL接続
$ mysql -uroot
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 1
Server version: 5.6.25 Homebrew
MySQLセキリティ設定(必要に応じて)
セキリティ設定をする癖をつけましょう。
$ mysql_secure_installation
- root ユーザのパスワード設定
- anonymous ユーザの削除
- root ユーザがリモートサーバからログインできないようにする
- 初期サンプルDBの削除
接続確認
$ mysql -uroot -p
Enter password:[設定したパスワード]
あとがき
最近便利なフレームワークばっか出てきているので、SQLって殆ど触った事ありませんって人が多いように感じます。
実際便利なものはドンドン利用すべきだとは思いますが、あわせて理論部分もしっかり理解出来るように頑張っていきましょう。
開発時にはSQLだけでなく、システムをどのように定義づけていくかというモデリングも必要になるので、以下のUMLまでの道シリーズも暇があれば読んでみてください。