【新人教育 資料】第4章 SQLへの道 〜SQL基本操作編〜
あらすじ
新人がいっぱい入ってくる。新人のレベルもバラバラ。教育資料も古くなっているので、更新しましょう。
どうせなら、公開しちゃえばいいじゃん。という流れになり、新人教育用の資料を順次更新していくことにしました。
※後々、リクエストに応じて更新することが多いのでストックしておくことをおすすめします。
自分はTEMONA株式会社でCTOをしていますが、頭でっかちに理論ばっかり学習するよりは、イメージがなんとなく掴めるように学習し、実践の中で知識を深めていく方が効率的に学習出来ると考えています。
※他の登壇やインタビュー記事はWantedlyから見てください。
教育スタイルとしては正しい事をきっちりかっちり教えるのではなく、未経験レベルの人がなんとなく掴めるように、資料を構成していきます。
以下のようなシリーズネタで進めます。
では、今回もはじめていきましょう!
SQL基本操作
SQLの4大命令
標準SQL規格では大きく以下の3つが定義されています。
- データ定義言語(CREATE,DROP,ALTER等)
- データ操作言語(INSERT,UPDATE,DELETE,SELECT)
- データ制御言語(GRANT,REVOKE,SET TRANSACTION,BEGIN,COMMIT,ROLLBACK,SAVEPOINT,LOCK)
今回はデータ操作言語に該当するSQLの4大命令について勉強していきましょう。
4大命令
| 命令 | 説明 | 文法 |
|---|---|---|
| INSERT | データを追加する。 | INSERT INTO テーブル名 (カラム名1, カラム名2, ...) VALUES (値1, 値2, ...); |
| SELECT | データを参照する。 | SELECT カラム名1, カラム名2, ... FROM テーブル名 [WHERE 絞込条件]; |
| UPDATE | データを更新する。 | UPDATE テーブル名 SET カラム名1=値1 [, カラム名2=値2 ...] [WHERE 絞込条件]; |
| DELETE | データを削除する。 | DELETE FROM テーブル名 [WHERE 絞込条件]; |
上記の4つです。簡単ですね。
※[]で囲んでいる所は、オプションです。
4章では、以前にインストールしたMySQLを使って実際にDB操作をして学習していきましょう。
まだMySQLをインストールしていない人は【新人教育 資料】SQLへの道 〜DB編〜を参考に手元のMacにMySQLをインストールしてください。
下記のようなテーブルを作るとして、話しを進めていきます。
テーブル名 members
| id | name | sex | birth_day |
|---|---|---|---|
| 1 | tarou | male | 1992-11-30 |
| 2 | hanako | female | 1993-01-14 |
学習の準備
データ定義言語の1つである「CREATE」も一部使いますが、SQLの4大命令を学習していきましょう。
MySQLへ接続する
MySQLの起動
$ mysql.server start
MySQLへの接続
以下のコマンドでMySQLに接続をします。
クライアントとサーバーのようなお話もありますがここでは割愛します。
$ mysql -uroot
CREATE DATABASE
RMDBSの1つであるMySQLの中にデータベースを作っていきましょう。
テーブルなどの、実際のデータだけでなく、DBを管理するためのデータ等も含まれる
1つのデータのセットだと思ってください。
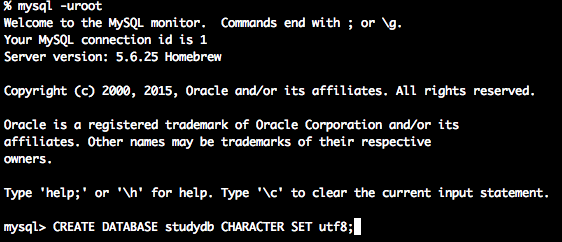
上記の画像のように「mysql>」の後に以下のコマンドを入力し、実行してください。
CREATE DATABASE studydb CHARACTER SET utf8;
利用するデータベースを選択する
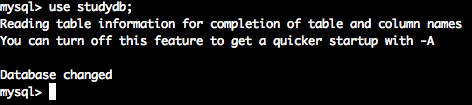
SQLをどのデータベースを利用するか設定するため
以下のコマンドを実行します。
use studydb;
CREATE TABLE
学習用に使うテーブルを作成していきましょう。
| id | name | sex | birth_day |
|---|---|---|---|
| 1 | tarou | male | 1992-11-30 |
| 2 | hanako | female | 1993-01-14 |
今回学習するために利用するテーブルは上記のように作りたいため
以下のコマンドでテーブルを作成しましょう。
カラム型については、説明を割愛します。
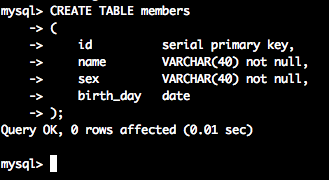
画像をよく見比べながら実行してみてください
CREATE TABLE members
(
id serial primary key,
name VARCHAR(40) not null,
sex VARCHAR(40) not null,
birth_day date
);
とりあえず準備はここまでです。
テーブルの一覧を確認する。
show tables;
無事にmembersテーブルが表示されたでしょうか?
今の段階で、作ったばかりのテーブルにはレコードがありません。
ここから実際に操作を見ていきましょう。
基本操作
INSERT文
INSERT はテーブルにレコードを追加するSQL文です。
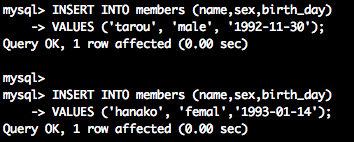
以下のコマンドを実行し、Query OKと返ってくることを確認してください。
INSERT INTO members (name,sex,birth_day)
VALUES ('tarou', 'male', '1992-11-30');
INSERT INTO members (name,sex,birth_day)
VALUES ('hanako', 'femal','1993-01-14');
SELECT文
レコードを作成したので、今度は検索してみましょう。
SELECT文は一番使う頻度が多く、かつ検索方法もたくさんあるのですが、ここでは基本中の基本だけ。
全件全列を参照する
SELECT * FROM members; -- 全件検索
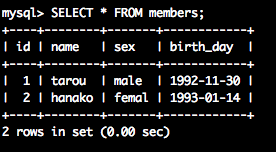
無事に以下のようなテーブルのレコードが参照できましたか?
id | name | sex | birth_day
----+-------+-------+------------
1 | tarou | male | 1992-11-30
2 | hanako | female | 1993-01-14
全件 name列だけを参照する
全ての列は要らない時はカラム名で絞込をしましょう。
SELECT name FROM members; -- 全件検索(名前だけ見たい)
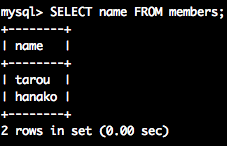
以下の結果が得られましたか?
| name |
|---|
| tarou |
| hanako |
全件 特定の条件に一致するデータだけを参照する
別の章で絞込については、もう少し掘り下げたいと思いますが、単純な絞込条件だけ、ここでは見てみましょう。
SELECT * FROM members WHERE name = 'tarou'; -- 名前が"tarou"のレコードを検索
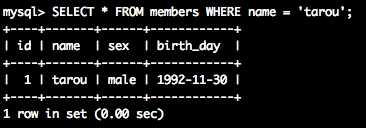
nameが「tarou」のデータだけ得られましたか?
id | name | sex | birth_day
----+-------+------+------------
1 | tarou | male | 1992-11-30
UPDATE文
ここからはUPDATE文でデータを更新してみましょう。
全件特定のカラムを更新
--membersのレコードのnameをすべて'jirou'に更新する
UPDATE members SET name = 'jirou';
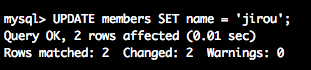
では無事に更新されているかを確認してみましょう。
SELECT * from members;--更新されているか確認
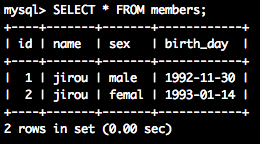
無事にデータが更新されていますね。
id | name | sex | birth_day
----+------+-------+------------
1 | jirou | male | 1992-11-30
2 | jirou | femal | 1993-01-14
絞込条件に該当するデータの特定のカラムを更新
--membersのレコードでidが1のレコードのname,birth_dayを更新
UPDATE members SET name = 'saburo', birth_day = '2015-03-11' WHERE id = 1;

さて更新されているでしょうか?
SELECT * from members;--更新されているか確認
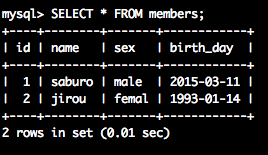
以下の様に更新されているのが確認出来ていれば成功です。
id | name | sex | birth_day
----+--------+-------+------------
1 | saburo | male | 2015-03-11
2 | jirou | femal | 1993-01-14
DELETE文
特定条件に該当するデータを削除
--idが1のレコードを削除する
DELETE FROM members WHERE id = 1;

SELECT * from members;--削除されているか確認
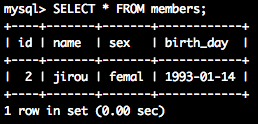
だいぶ、この流れに慣れてきたころですね?
id | name | sex | birth_day
----+------+-------+------------
2 | jirou | femal | 1993-01-14
全件データを削除
--membersのレコード全てを削除する
DELETE FROM members;

無事に全件削除されているでしょうか?
SELECT * from members;--削除されているか確認

id | name | sex | birth_day
----+------+-----+-----------
SQLの4大命令は以上です。
基本操作になるので、習得出来るまで反復練習をしましょう。
小話1 CRUD図(表)
システム開発をしていて、ドキュメントを作っている会社だと、属人化を未然に防いだり、影響調査のコスト圧縮のために、CRUD図という図を作成したりします。
このCRUD図とは、SQLの4大命令に即した形で「Create」、「Read」、「Update」、「Delete」の操作がどのテーブルに対して行われているかを画面(機能やユースケース)ごとに記載する資料です。
| 省略形(意味) | SQL | 説明 |
|---|---|---|
| C(Create) | INSERT | データを作成する。 |
| R(Read) | SELECT | データを参照する。 |
| U(Update) | UPDATE | データを更新する。 |
| D(Delete) | DELETE | データを削除する。 |
自社で開発している際には、あると便利という表ですね。
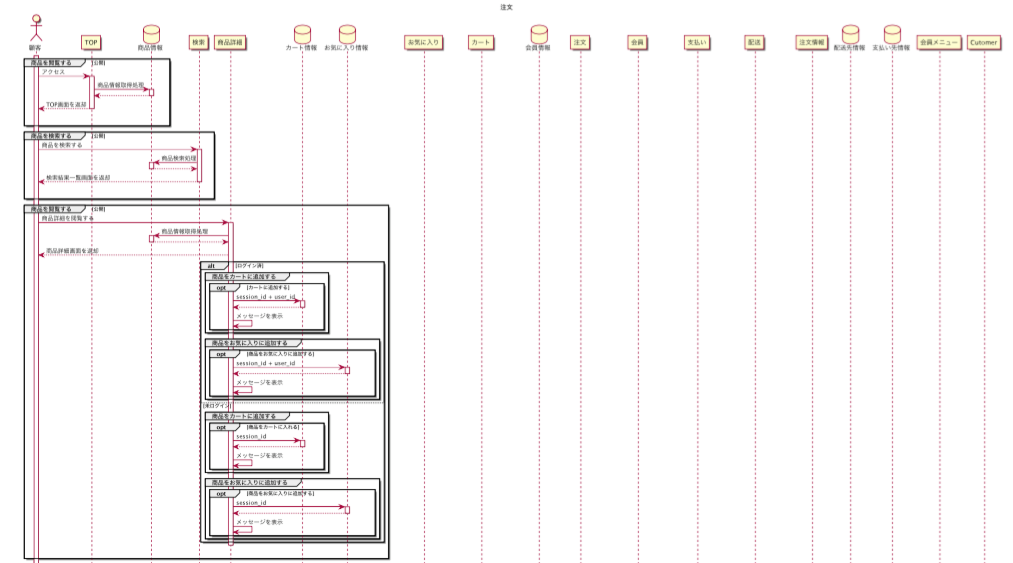
先日テモナで行った開発合宿でUMLをがっつり勉強してきましたが、その際に説明として照会したCRUD図を掲載しておきます。
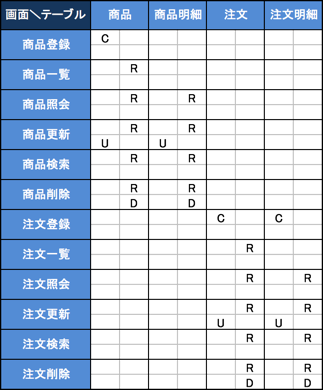
上記の例では、画面とテーブルで表現していますが、どの画面において、どのテーブルに対してデータ操作を行うかが一覧で分かって便利ですよね。
小話2 ACID
RMDBS(リレーショナルデータベースシステム)を理解するために、もう一つ照会したいお話があります。
データを守るための基本的なルール "ACID"
システム開発において、データベースをそれ単体で使うということは、あまり考えにくいですね。通常他のシステム(たとえばWebアプリケーションなど)と連携して使用することが多いです。データベースには顧客情報などの重要な情報が保存されています。
ではそんなとき、みなさんがデータベースに期待する、性能/機能とはなんでしょう。
もしかしたら...
突発的なサーバーダウンが発生するかもしれません。
ハードが壊れて、そもそもサーバーを起動することすらできなくなるかも。
Aさんがあるデータを更新しているときに、Bさんも同一データを更新しているかもしれません。
どんなことが起きたとしても、大切なデータは守りたいです。
結局、「データを守る」ことがみんなが共通に期待する性能ではないでしょうか。
そして、「データを守る」ために"ACID"というルールがあります
ACID
以下の特徴の頭文字をつなげてACIDと言います
- 原子性 (ATOMICITY)
- 一貫性 (CONSISTENCY)
- 独立性 (ISOLATION)
- 永続性 (DURABILITY)
言葉は難しいので、はじめはそうなんだと聞き流しておきましょう。
トランザクション
標準SQL規格にもある「データ制御言語」の1つにトランザクションというものがあります。
「処理のまとまり」としてのトランザクション
トランザクションを説明するときに、よく例に出されるのが銀行口座の例です。
Aさんの口座から、Bさんの口座に100万円を振り込む処理を例に考えてみましょう。
これを実現するには、下記のような2つのステップが必要になります。
STEP1 => Aさんの口座から100万円を引く
STEP2 => Bさんの口座に100万円を足す
別にSTEP2=>STEP1の順で処理してもいいと思いますが、少なくとも、
STEP1とSTEP2は両方とも実行完了するか、両方とも実行完了されない という条件が満たされていないと、口座間の計算があわなくて大変です。Aさん口座から100万円引いたのにも関わらず、その時点でサーバーダウンして、Bさんの口座に100万円が振り込まれなかったら...考えるだけで恐ろしいです。
この STEP1とSTEP2は両方とも実行完了するか、両方とも実行完了されない という性質を **原子性 (ATOMICITY)**といいます。
ではこのSTEP1とSTEP2はセットで実行したいということ(トランザクション)を、RDBMSはどうやって認識するのでしょうか。
これはデータベースを使う人が明示的に指定してあげる必要があります。データベースが勝手に判断して、ここからここまでがトランザクションだ!と判断することはありません。今回の預金口座の例では、下記のような感じになります。
CREATE TABLE bank_accounts
(
id serial primary key,
name VARCHAR(40) not null,
balance bigint
);
INSERT INTO bank_accounts (name,balance)
VALUES ('A', 1000);
INSERT INTO bank_accounts (name,balance)
VALUES ('B', 900);
SELECT * FROM bank_accounts;-- 確認
id | name | balance
----+------+---------
1 | A | 1000
2 | B | 900
(2 rows)
--トランザクションはクライアントが明示的に宣言する必要がある
BEGIN; --トランザクションの開始宣言
UPDATE bank_accounts SET balance = ( balance - 100) WHERE name = 'A'; --STEP1
UPDATE bank_accounts SET balance = ( balance + 100) WHERE name = 'B'; --STEP2
COMMIT; --トランザクションの終了宣言
SELECT * FROM bank_accounts;-- 確認
id | name | balance
----+------+---------
1 | A | 900
2 | B | 1000
(2 rows)
「データの復旧の単位」としてのトランザクション
トランザクションには、なにかしら障害が発生した際の「データの復旧の単位」としての一面もあります。
RDBMSは、障害発生前に終了しているトランザクションの結果は保証する。言い換えれば、障害発生時にトランザクションが終了していないものに関しては、保存してくれません。
この 障害発生前に終了しているトランザクションの結果は保証する という性質を
永続性 (DURABILITY) といいます
トランザクションと同時実行
データベースを一人で使えればいいのですが、複数のユーザーが同時並行でデータベースにアクセスするのが通常です。
同一データを、AさんBさん二人が更新しようとしているとき、どのようにしたらデータの整合性を保証できるでしょうか。
AさんとBさんがお互いを気遣い合って、相手方が終わってから処理をかけるジェントルマンならいいのですが...
そんなこと普段意識していませんよね?この辺は、RDBMSが裏で働いていて、うまい具合に複数処理をスケジューリングして、整合性を保証してくれています。
この性質を 独立性 (ISOLATION) といいます
ひとつひとつのトランザクションは、その他の処理からは独立しているよってことですね。
最後の 一貫性 (CONSISTENCY) というのはレコードへのnot null, default =,primary_key などの制約に関して、トランザクションの前後で整合性をとるよって意味です。
RMDBSとしては、多くがこんな特徴があるよと覚えておいてください。
【新人教育 資料】SQLへの道 〜DB編〜で照会している、DBの種類全てが対応しているわけではないのでご注意ください。
あとがき
今回はどうだったでしょうか?しっかり反復学習してくださいね。
さて話変わりますが、2/13,2/14で横須賀市の太っ腹な施策(無料で開発合宿)を利用して開発合宿に行ってきました。駅から送迎着きで、ホテルはツインベットを1人締めして泊まれ、お昼にはお弁当まで頂けるとなんとも言えない豪華な開発合宿でした。

※上記の写真は前回の鎌倉合宿を日経新聞社様に取材頂いた時のキャッチ画像です
大変有意義な時間を過ごせたのですが、普段野性味を帯びて開発合宿(きゅうりかじったり、すいかかじったり、釣りをしたり)を行っている僕達からすると綺麗に整いすぎて、甘やかされすぎたダメ男になりそうな感じでもありました。
綺麗にかっちりと、自由に野性味感じる合宿を順番に行きたいなと思う今日このごろです。
以下はUMLでのモデリングの成果の一部です。表現手法はだいぶ学習出来てきていると思うのですが、ロジカル・シンキングのような情報整理能力が低いので、両方コンテンツを作っていこうと思います
次回は【新人教育 資料】第5章 SQLへの道 〜絞込編〜をお送りする予定です。