はじめまして。
devと申します。
Qiitaへの投稿は初めてです。
この投稿がどなたかの役に立てばと思い、記事を作成しています。
今回はOCRを利用した数字判別アプリについてご紹介します。
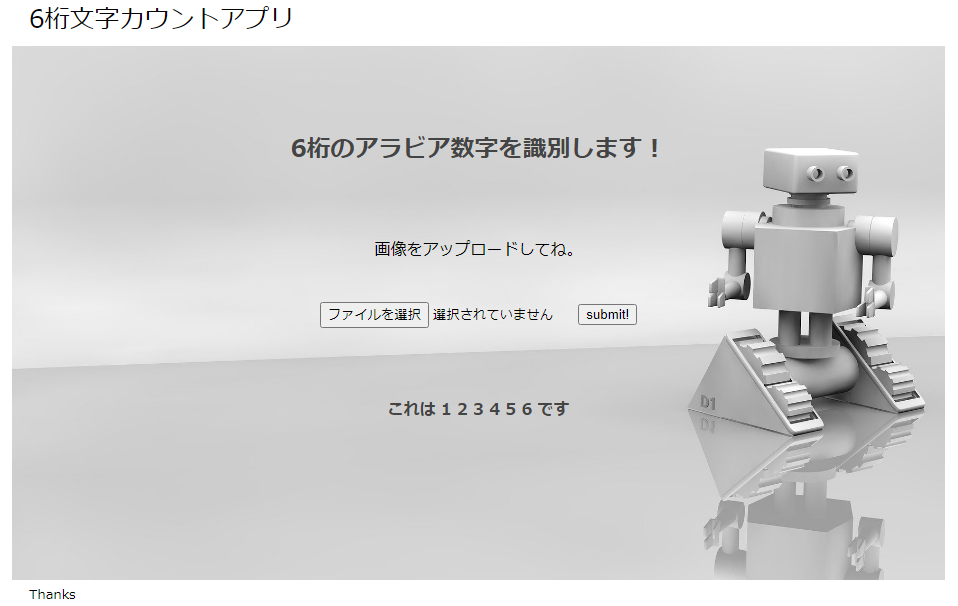
アプリについて
ごく単純ですが、入力された画像をOCR(Google cloud vision api)で判別し、答えを返すWebアプリです。作成理由
車のスピードメーターみたいなアナログなメーターを読み取れたら便利ですよね。 サービスとしては既に提供されているようだけど、「自分も少し近いことしてみたいなぁ」と思ったのが発端。でもメーターの読み取りって難易度高そう。初めてのアプリなので、「まずはアナログな走行距離数字を読み取ってみよう!」という訳で数字の識別にチャレンジです。
基本機能
6桁数字の画像を選んでポチれば、読み取った数字をWeb画面に返します。例えばこんな画像を読み取れます。
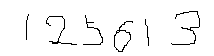

作って感じたのは「Google cloud vision api」を使えばこんな簡単に高精度のアプリができるんだ!ってことですね。
簡単ながら、精度もGOOD(le)!
しかも、数字だけでなく文字も判定できちゃいます。
だからこんなのもOK


でも何に使えるの?
お遊びアプリなので、このままでは「何にも使えません」 笑発展形としては「書類NOの通し番号読み取り」や「伝票読み取り」にも使えるかと思います。
別に「Google cloud vision api」を使わずとも「Tesseract」や、その他フリーソフトでもOCR機能は実現できますね。
実装環境
html css Flask選択肢
数字を読み取るために、以下の2つを検討しました。 ・mnistの学習データ ・OCRmnistデータセットを使って学習させる
mnistの場合、学習させるのは比較的容易です。 ただし桁数を表現するために、1桁目、2桁目といった物体検出が必要。学習データは以下のような方法で保存できます。
■[参考]
from keras.datasets import mnist
from keras.models import Sequential, load_model
from keras.layers.core import Dense, Activation, Flatten
from keras.layers import Conv2D, MaxPooling2D, Dropout, Reshape
from keras.utils import np_utils
import numpy as np
(X_train, y_train),(X_test, y_test) = mnist.load_data()
X_train = np.array(X_train)/255
X_test = np.array(X_test)/255
y_train = np_utils.to_categorical(y_train)
y_test = np_utils.to_categorical(y_test)
model = Sequential()
model.add(Reshape((28,28,1),input_shape=(28,28)))
model.add(Conv2D(32,(3,3)))
model.add(Activation("relu"))
model.add(Conv2D(32,(3,3)))
model.add(Activation("relu"))
model.add(MaxPooling2D((2,2)))
model.add(Dropout(0.5))
model.add(Conv2D(16,(3,3)))
model.add(Activation("relu"))
model.add(MaxPooling2D((2,2)))
model.add(Dropout(0.5))
model.add(Flatten())
model.add(Dense(784))
model.add(Activation("relu"))
model.add(Dropout(0.5))
model.add(Dense(10))
model.add(Activation("softmax"))
model.compile(loss="categorical_crossentropy", optimizer="sgd", metrics=["accuracy"])
hist = model.fit(X_train, y_train, batch_size=200,
verbose=1, epochs=1, validation_split=0.1)
score = model.evaluate(X_test, y_test, verbose=1)
print('Test loss:', score[0])
print("test accuracy:", score[1])
model.save("C:/test/mnist_main.h5")
OCRを使って判別させる
何よりも手っ取り早いのがOCR。 GoogleのAPIを使うので精度も高く、作りこむ必要がありません。 桁数も気にせず読み取ってくれます。用途次第では十分利用できますね!
※「Google cloud vision api」実装はこちらを参考にさせていただきました。
精度
精度を確認するために1000文字の数字を確認しました。 ■条件
画像サイズ:1,024x768
フォント:游ゴシック
文字サイズ:16x23pixel(WH)
文字間:5pixel
行間:11pix3l
■結果
精度:100%
※文字サイズを半分にしても100%でした。
高い精度を出すことができたので、次は同条件でフォントを変えてみました。
■結果
mspゴシック:100%
msp明朝:100%
fugaz one:100%
ink free:99.9%
np b:99.6%
どれも高い精度ですが、「np b」フォントは他に比べて精度が落ちました。
なぜでしょうか?

原因は「1」の形です。
「|(パイプ)」や「I(アイ)」と認識されている箇所がありました。
■その他1
ink freeは下記のような手書き風文字ですが、精度は99.9%と高かったことから、標準的なフォントには対応しているのかもしれません。

■その他2
下記のような文字間、行間を1pixelにした文字も別途試してみましたが、結果は100%。
※文字サイズ:12x14pixel(WH)

うん。十分使えますね!
精度に関してはWeb上にたくさん情報がありますので、いろいろ探してみましょう。
<参考にさせていただいた記事>
(https://qiita.com/saken649/items/4bfd215bf943c36a52ab "画像による文字識別の違い")
(https://qiita.com/se_fy/items/963b295bbd13101c044b "画像サイズによるスループット")
Google Cloud Vision APIについて
設定自体はとても簡単。 APIkeyを取得すれば利用できます。 ※請求に関する設定は有効にしないとエラーを返し、利用できないのでご注意ください。料金自体もかなり安いようです。
月1,000回(ユニット)までは無料。
以降は1,000ユニット毎に1.5$。回数レンジに応じて料金がかわります。
お小遣い程度で運用できそうですね。
ですが、念のた利用料のアラート設定は有効にしておきましょう。
(事故防止)