こんにちは!株式会社DearOneの申(シン)です。バックエンドとインフラを中心に、幅広く担当しています。
今回のテーマは、RunPodを活用したコーディングエージェントの構築です。
ローカルLLMでコーディングエージェントを動かしたい。でも自宅のiMac M4(32GB)だとLLMとClineを同時に使うとVRAMが足りず、コンテキストウィンドウを大きく取れないのですぐ詰まってしまいます。
じゃあクラウドGPUならどうだろう?ということで、RunPodでOSSのコーディング特化LLMを試してみました。
RunPod vs AWS:GPU料金と使い勝手の比較
GPU クラウドサービスはいくつかありますが、RunPodを選んだ理由はシンプルです。
- 秒単位課金で無駄がない
- データ転送料が無料(AWSだとEgressに課金される)
- A40が$0.40/hr前後で使える
- セットアップが簡単(Docker テンプレートで即起動)
AWSのGPUインスタンス(g5.xlargeなど)と比べると3〜5倍安いです。個人の実験用途ならRunPodが最適だと感じました。
GLM-4.7-Flashとは:性能とライセンスの整理
今回選んだのは、Zhipu AIが公開した GLM-4.7-Flash です。MoE(Mixture of Experts)アーキテクチャで、総パラメータ数は30Bですが実際にアクティベートされるのは3Bだけ。つまり軽いです。
選定理由:
- コーディングエージェント向けに最適化されている
- MITライセンスで商用利用可
- 198Kトークンの長いコンテキストウィンドウ
- SWE-bench: 73.8%、Q4_K_Mで19GB程度に収まる
ローカルの14Bモデルで16Kコンテキストに苦戦していた身としては、「30Bクラスの性能を3Bの計算コストで」というのは魅力的でした。
GPU選定:A40・4090・A5000・4000のVRAM・コスト比較
GLM-4.7-FlashのQ4_K_M量子化版は約19GB。VRAMに余裕を持たせたかったので、いくつか比較しました。
| GPU | VRAM | 価格 | 判定 |
|---|---|---|---|
| RTX 4000 Ada | 20GB | $0.20/hr | ギリギリすぎる。OOMリスクあり |
| RTX A5000 | 24GB | $0.20/hr | 動くが余裕が少ない |
| RTX 4090 | 24GB | $0.50/hr | 動く。ただしSpotは中断リスクあり |
| A40 | 48GB | $0.40/hr | 余裕あり。128Kコンテキストも可能 |
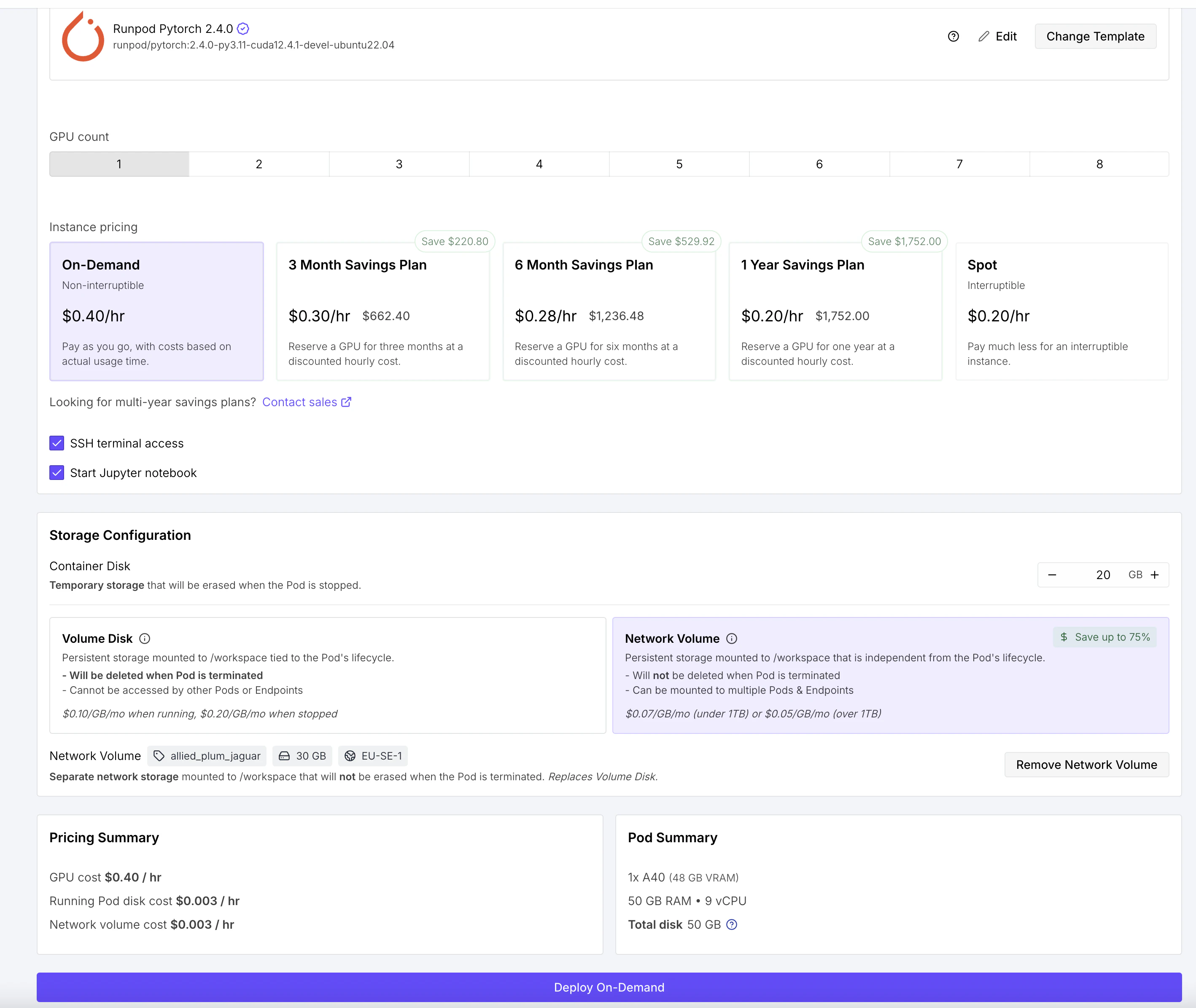
実際にA40で動かしたところ、モデルロード後のVRAM使用量は約25GBでした。残り21GBはKVキャッシュ(コンテキスト)に使えます。128Kトークンに設定しても31GB程度で収まり、まだ14GBの余裕がありました。
最初はSpotインスタンス(RTX 4090)で始めましたが、モデルダウンロード中にインスタンスが回収されてしまいました。実験中はOn-Demandの方が安心です。
セットアップ手順
RunPodでOllamaを動かす手順は意外とシンプルでした。
1. Pod作成
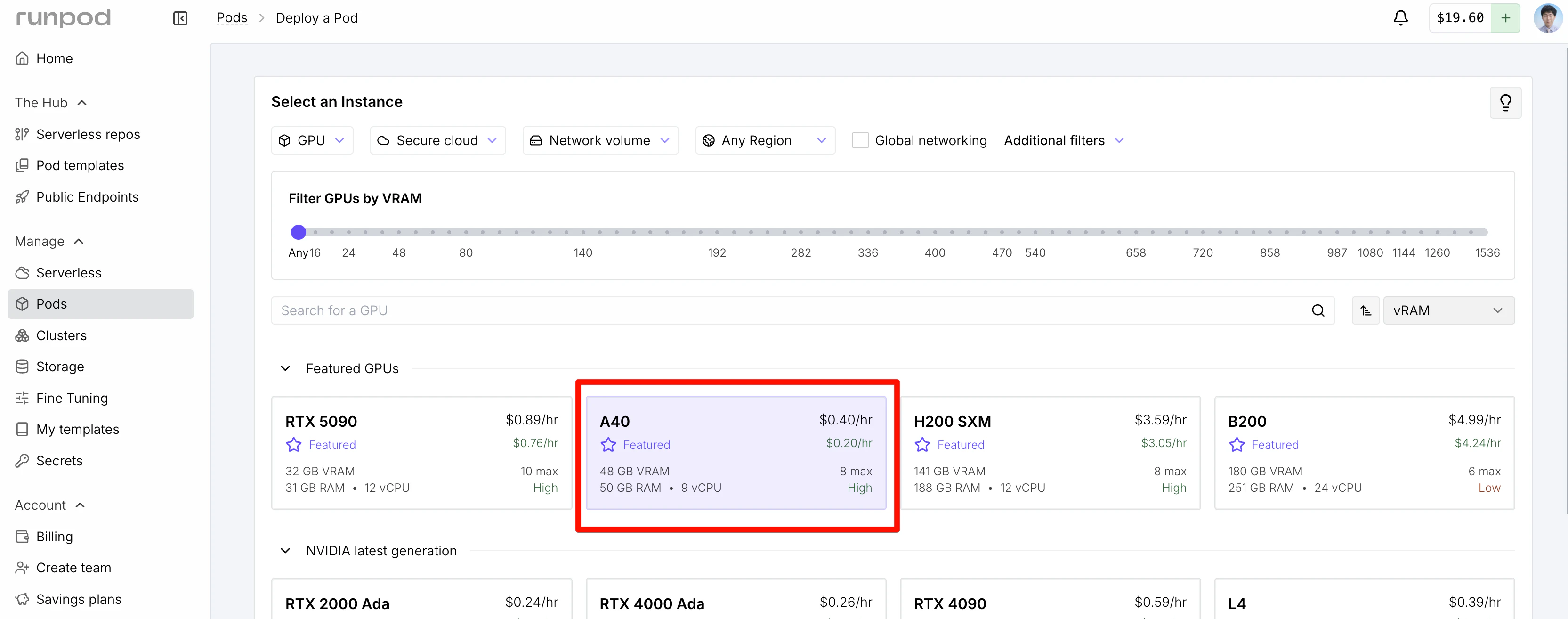
RunPod Consoleで以下の設定でPodを作成:
- テンプレート: RunPod Pytorch 2.4
- GPU: A40(Secure Cloud)
- HTTP Port: 11434を追加(Ollama API用)
-
環境変数:
OLLAMA_HOST=0.0.0.0(Pod設定画面で追加)
2. Ollamaインストール
Pod起動後、Web Terminalから:
apt update && apt install -y lshw zstd
(curl -fsSL https://ollama.com/install.sh | sh && ollama serve > ollama.log 2>&1) &
ollama pull glm-4.7-flash
OLLAMA_HOST はPod作成時に環境変数として設定済みなので、コマンドで指定する必要はありません。zstd はOllamaのモデル展開に必要ですが、Pytorchテンプレートには入っていません。先にインストールしておかないとpull時にエラーになります。
3. 接続方法:RunPod Proxy URL
最初はSSHトンネルを試しましたが、RunPodのSSHリレー(ssh.runpod.io)はポートフォワーディングには対応していませんでした。
結局、RunPodの Proxy URL 方式が一番簡単でした。HTTPポートを公開しておけば、以下のようなURLで外部からアクセスできます:
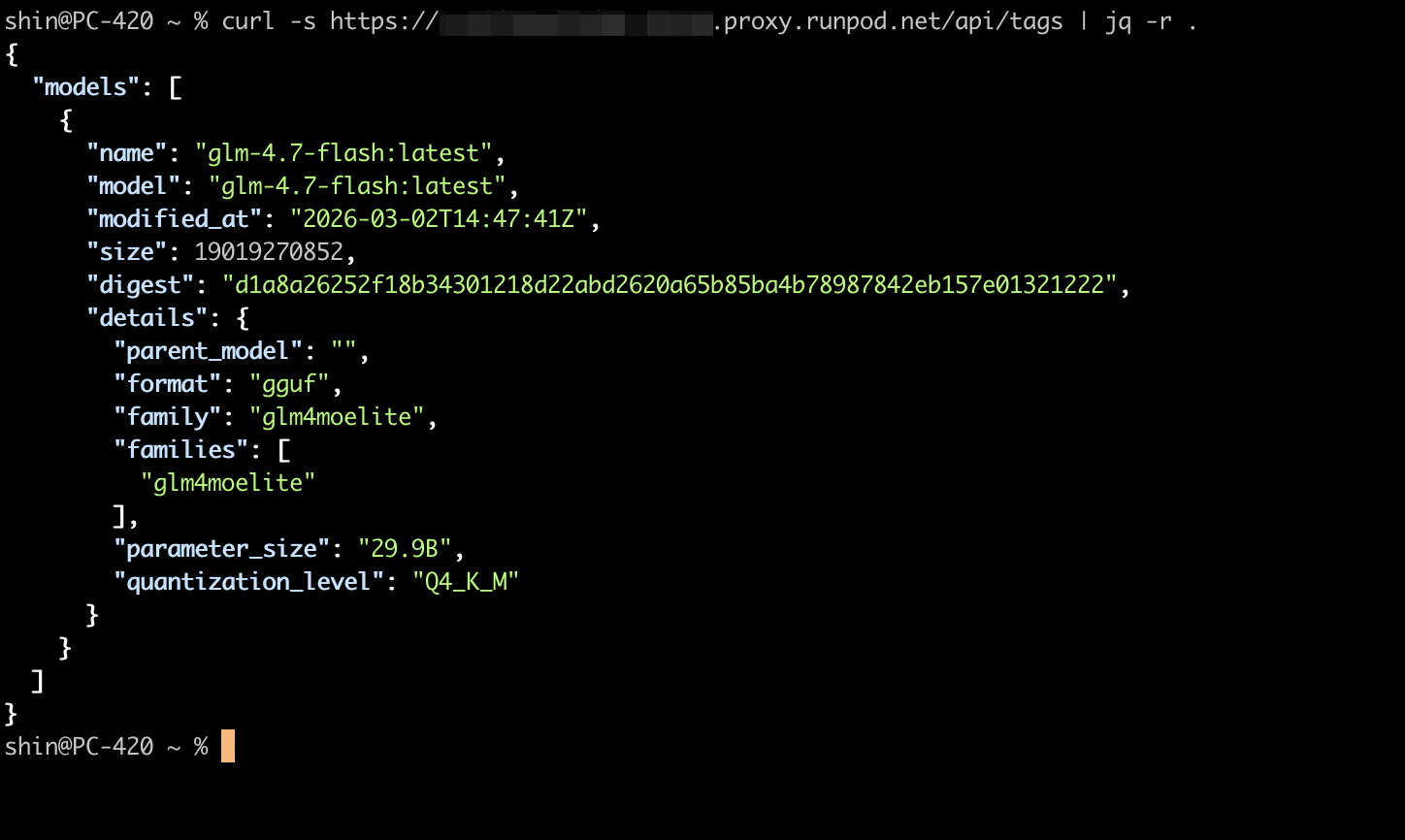
https://{POD_ID}-11434.proxy.runpod.net
ローカルマシンからの疎通確認:
curl https://{POD_ID}-11434.proxy.runpod.net/api/tags
モデル一覧が返ってくれば成功です。
Clineの設定
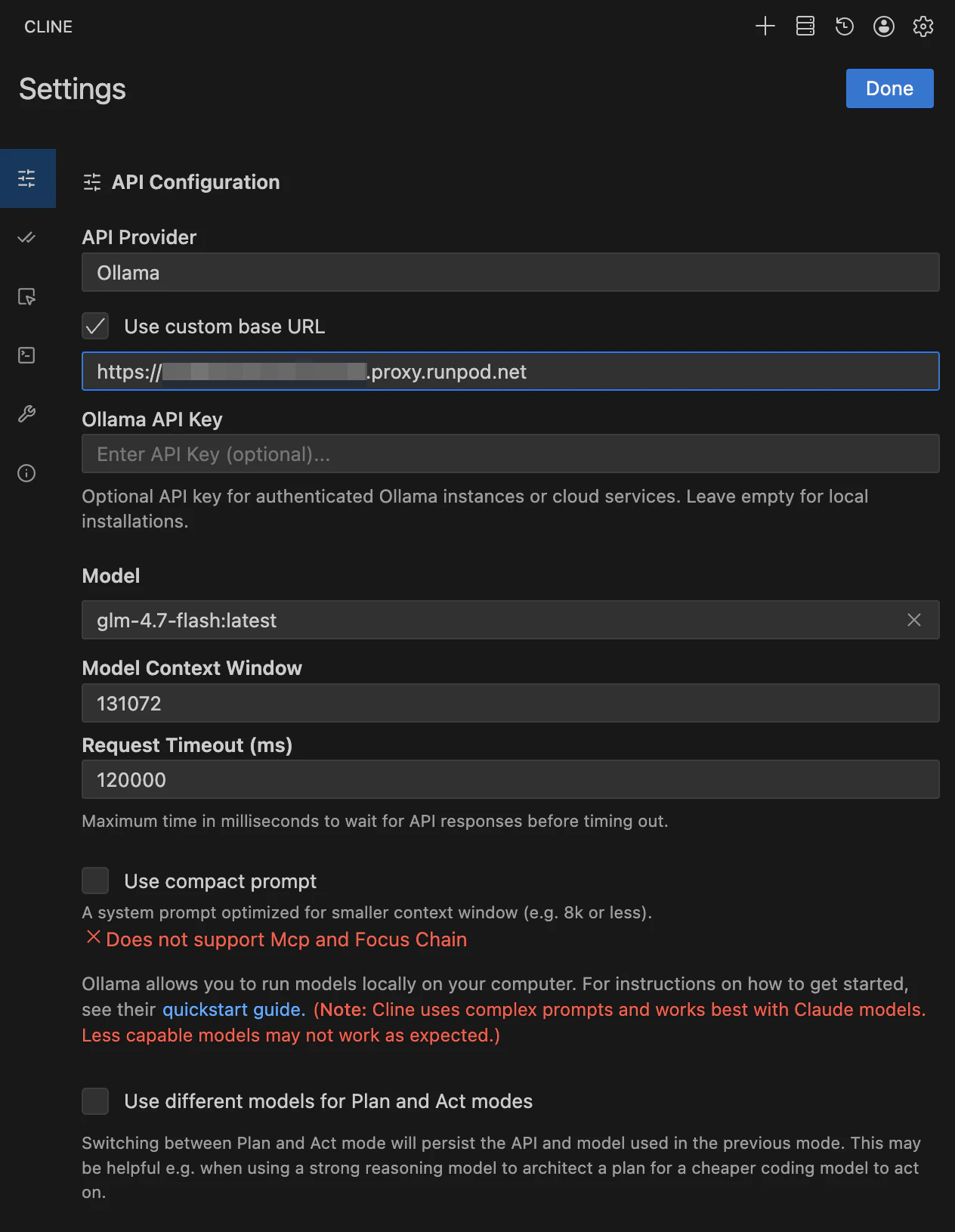
VS CodeのCline拡張で以下を設定:
- API Provider: Ollama
-
Base URL:
https://{POD_ID}-11434.proxy.runpod.net -
Model:
glm-4.7-flash - Context Window: 128K(A40なら余裕)
- Request Timeout: 120000ms(ネットワーク経由なので長めに)
Compact Promptは好みによりますが、MCP連携が不要ならオンにした方がコンテキストを節約できます。
OpenCodeの設定
ターミナルベースのコーディングエージェント OpenCode からも接続できます。~/.config/opencode/opencode.json の provider に以下を追加:
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"runpod-ollama": {
"npm": "@ai-sdk/openai-compatible",
"name": "RunPod Ollama",
"options": {
"baseURL": "https://{POD_ID}-11434.proxy.runpod.net/v1"
},
"models": {
"glm-4.7-flash": {
"name": "GLM-4.7-Flash"
}
}
}
}
}
既存の設定(mcp など)がある場合は、provider キーを追加するだけで、他の設定はそのまま維持されます。OllamaはOpenAI互換APIを提供しているので、baseURL の末尾に /v1 を付けるだけで接続できます。
Network Volumeでモデルを永続化する
ここまでの手順だと、Podを停止するたびにモデルが消えてしまいます。毎回19GBのダウンロードからやり直すのは非常に時間がかかるので、RunPodの Network Volume を使えば、モデルデータをPodのライフサイクルから切り離して永続化できます。
Network Volumeの作成
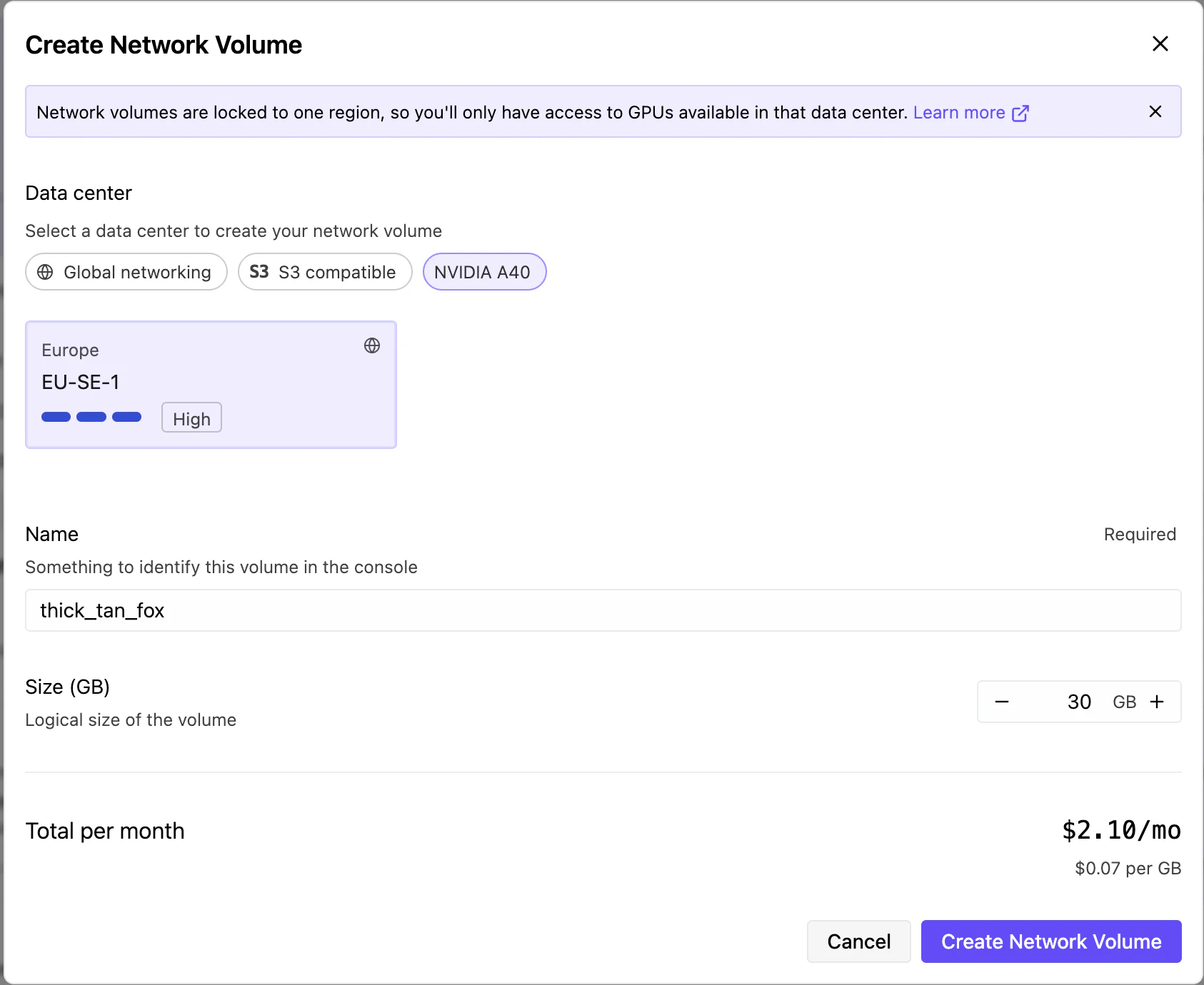
RunPod Consoleの「Storage」から新しいNetwork Volumeを作成します:
- リージョン: Podと同じリージョンを選ぶ(違うと接続できない)
- サイズ: 30GB以上(GLM-4.7-Flashは19GBだが、他のモデルも試すなら余裕を持たせる)
PodにNetwork Volumeをアタッチ
Pod作成時(または既存Podの設定変更で)Network Volumeを指定します。マウントポイントはデフォルトで /workspace になります。
Ollamaのモデル保存先をNetwork Volumeに向けるため、環境変数を追加します:
OLLAMA_MODELS=/workspace/ollama-models
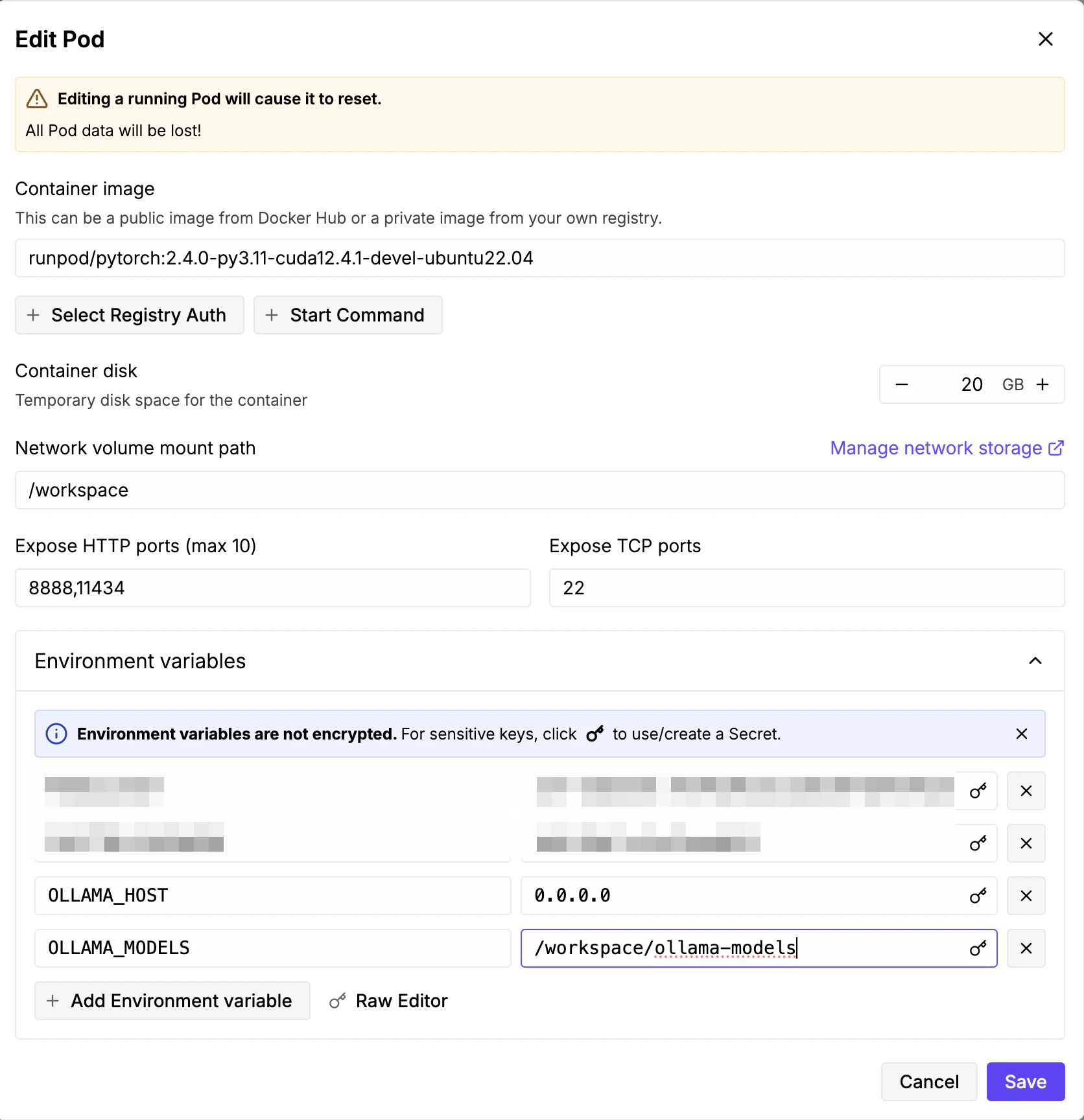
初回だけpull、以降は即起動
# 初回のみ
apt update && apt install -y lshw zstd
(curl -fsSL https://ollama.com/install.sh | sh && ollama serve > ollama.log 2>&1) &
ollama pull glm-4.7-flash # /workspace/ollama-models に保存される
# 2回目以降(Podを再起動しても)
apt update && apt install -y lshw zstd
(curl -fsSL https://ollama.com/install.sh | sh && ollama serve > ollama.log 2>&1) &
# ollama pull 不要。モデルはNetwork Volumeに残っている
Network Volumeの料金は$0.07/GB/月。30GBなら月$2.10です。Podを止めている間もモデルを保持してくれるので、使いたいときにすぐ起動できます。
実測レポート:VRAM・速度・品質の評価
コスト感
A40 On-Demandで$0.40/hr。2時間の実験で$0.80程度。モデルダウンロードの待ち時間も含めて$1以下で収まりました。Claude APIで同じ量のコーディング作業をしたら、もっとかかっていたかもしれません。
VRAM使用量の推移
| 設定 | VRAM使用量 | 残り |
|---|---|---|
| モデルロード直後 | 25GB | 21GB |
| コンテキスト 64K | 25GB | 21GB |
| コンテキスト 128K | 32GB | 14GB |
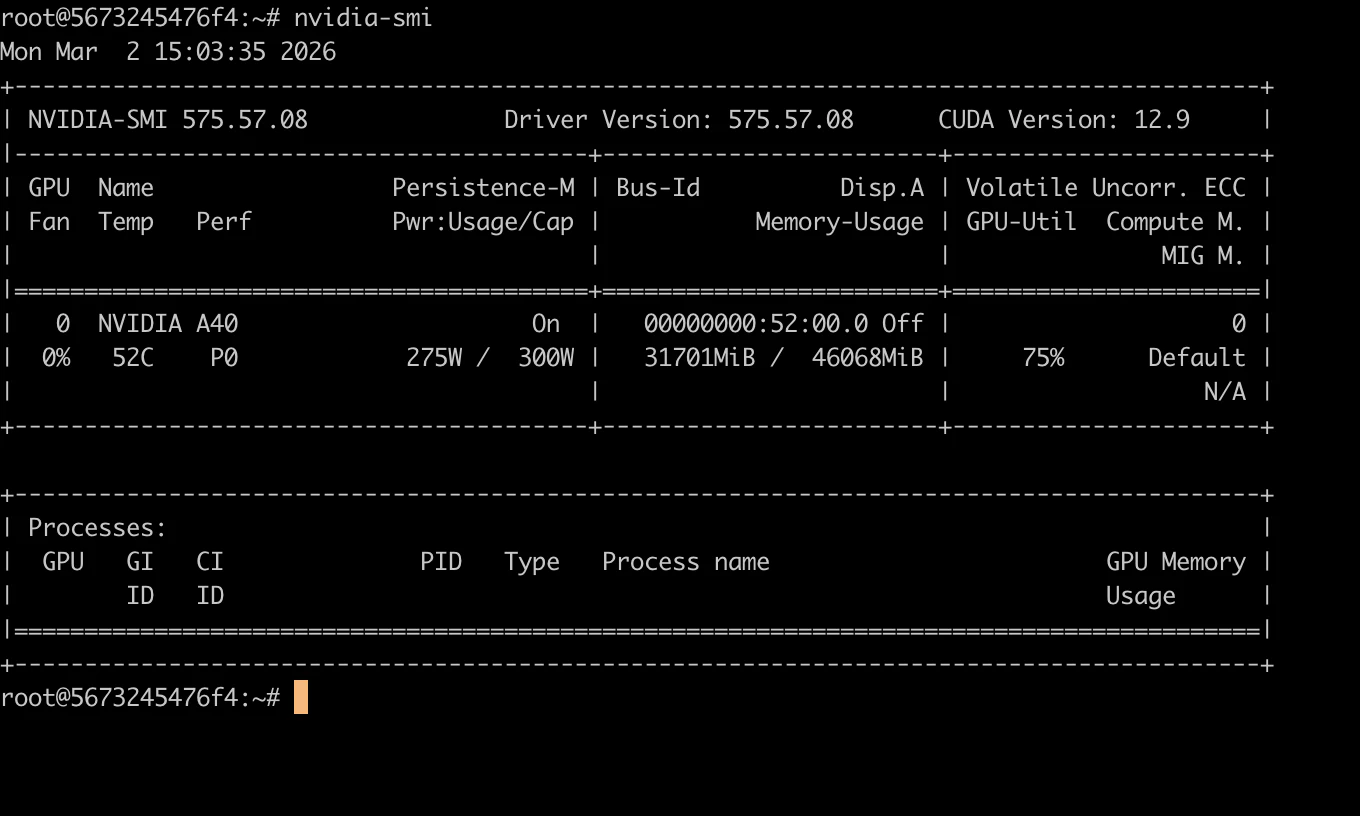
A40の48GBに対して十分な余裕があります。ローカルのM4 32GBでは到底実現できないスペックです。
ハマりポイント
- Spotインスタンスは注意: 安いが5秒前の通知で中断される。モデルダウンロード中に飛ぶと最初からやり直し
- zstdの事前インストール: Ollamaが依存しているが、多くのDockerテンプレートに含まれていない
- SSHトンネル非対応: RunPodのSSHリレーはポートフォワーディングをサポートしていない。Proxy URL方式を使うこと
- Pod再起動でモデル消失: Network Volumeなしの場合、Podを停止すると中身がリセットされる。Network Volumeの設定を忘れずに
Container Start Commandで完全自動化
ここまでの手順だと、Pod起動後に毎回手動でOllamaをインストール・起動する必要がありました。RunPodの Container Start Command を使えば、この手順を自動化できます。
Network Volume + Container Start Commandの構成:
-
Network Volume:
/workspaceにマウント(モデル永続化) -
環境変数:
OLLAMA_HOST=0.0.0.0、OLLAMA_MODELS=/workspace/ollama-models - Container Start Command:
bash -c 'apt update && apt install -y lshw zstd && curl -fsSL https://ollama.com/install.sh | sh && ollama serve'
注意点として、ollama serve はフォアグラウンドで実行する必要があります。& でバックグラウンドに回すとプロセスが終了してコンテナごと停止してしまいます。
こうすればPodをStop→Startするだけで:
- Container Start CommandでOllamaが自動インストール・起動
- Network Volume上のモデルがそのまま使える(再ダウンロード不要)
- 手動操作なしでProxy URLからすぐアクセス可能
Network Volumeのコストは$0.07/GB/月。30GBなら月$2.10程度です。Podは使わないときにStopしておけばGPU課金はゼロ。「必要なときにStart → 自動でLLM起動 → 使い終わったらStop」というワークフローが実現できます。
まとめ
| 項目 | 内容 |
|---|---|
| モデル | GLM-4.7-Flash (MoE 30B/3B, Q4_K_M, 19GB) |
| GPU | NVIDIA A40 48GB |
| コスト | ~$0.40/hr + Network Volume $2.10/月 |
| コンテキスト | 128Kトークン |
| 接続方法 | RunPod Proxy URL → Cline (VS Code) |
ローカルMacの16Kコンテキストで苦しんでいたのが、RunPod + A40なら128Kで余裕を持って動きます。Network Volume + Container Start Commandを使えば、Podの起動だけでLLMが自動で立ち上がります。OSSモデルでコーディングエージェントを試したい人には、RunPodは手軽で安価な選択肢だと思います。
ただし、Claude等の商用モデルと比べると品質差はまだあります。複雑なリファクタリングや大規模なコードベースの理解は、商用モデルに軍配が上がります。「ちょっと試してみたい」「コストを抑えて回数を回したい」という用途には、RunPodは最適だと感じました。