目次
- GiNZAとは
- 第4章: 形態素解析
- 30. 形態素解析結果の読み込み
- 31. 動詞
- 32. 動詞の原形
- 33. サ変名詞
- 34. aのb
- 35. 名詞の連接
- 36. 単語の出現頻度
- 37. 頻度上位10語
- 38. ヒストグラム
- 39. zipfの法則
- 参考
GiNZAとは
リクルートのAI研究機関と国立国語研究所が共同で開発した,日本語の自然言語処理ライブラリです。以下 https://www.recruit.co.jp/newsroom/2019/0402_18331.html より抜粋
「GiNZA」の概要
「GiNZA」は、ワンステップでの導入、高速・高精度な解析処理、単語依存構造解析レベルの国際化対応などの特長を備えた日本語自然言語処理オープンソースライブラリです。「GiNZA」は、最先端の機械学習技術を取り入れた自然言語処理ライブラリ「spaCy」(※5)をフレームワークとして利用しており、また、オープンソース形態素解析器「SudachiPy」(※6)を内部に組み込み、トークン化処理に利用しています。「GiNZA日本語UDモデル」にはMegagon Labsと国立国語研究所の共同研究成果が組み込まれています。
「GiNZA」の主な特長
- 高度な自然言語処理をワンステップで導入完了
- 高速・高精度な解析処理と依存構造解析レベルの国際化に対応
- 国立国語研究所との共同研究成果の学習モデルを提供
インストール
特徴としても挙げられているようにGiNZAのインストールはとても簡単で,以下のコマンドを実行するだけ。
pip install "https://github.com/megagonlabs/ginza/releases/download/v1.0.2/ja_ginza_nopn-1.0.2.tgz"
第4章: 形態素解析
夏目漱石の小説『吾輩は猫である』の文章(neko.txt)をMeCabを使って形態素解析し,その結果をneko.txt.mecabというファイルに保存せよ.このファイルを用いて,以下の問に対応するプログラムを実装せよ.
なお,問題37, 38, 39はmatplotlibもしくはGnuplotを用いるとよい.
ここでは,MeCabの代わりにGiNZAを使って形態素解析を行い,その結果をneko.txt.ginzaというファイルに保存します。
GiNZAは内部でspaCyを使用しているので,tokenのインスタンス変数についてはspaCy公式ドキュメントを読めば大体わかります。ただし,pos_detailなどはGiNZAで独自に追加している変数なので,現状GitHubのソースコードを読み解くしかなさそうです。(たぶん)
この部分が一番重要で,逆にこれ以外のプログラムはMeCabと大きく変わりません。
import spacy
nlp = spacy.load('ja_ginza_nopn')
with open('neko.txt') as f1, open('neko.txt.ginza', 'w') as f2:
for line in f1:
for sent in nlp(line.strip()).sents:
for token in sent:
# i:トークン番号, orth_:表層形, lemma_:基本形,
# pos_:品詞(英語), pos_detail:品詞細分類(日本語)
f2.write(f'{token.i}\t{token.orth_}\t{token.lemma_}\t'
f'{token.pos_}\t{token._.pos_detail}\n')
f2.write('EOS\n')
0 一 一 NUM 名詞,数詞,*,*
EOS
0 吾輩 我が輩 PRON 代名詞,*,*,*
1 は は ADP 助詞,係助詞,*,*
2 猫 猫 NOUN 名詞,普通名詞,一般,*
3 で だ AUX 助動詞,*,*,*
4 ある 有る AUX 動詞,非自立可能,*,*
5 。 。 PUNCT 補助記号,句点,*,*
EOS
0 名前 名前 NOUN 名詞,普通名詞,一般,*
1 は は ADP 助詞,係助詞,*,*
...
30. 形態素解析結果の読み込み
形態素解析結果(neko.txt.mecab)を読み込むプログラムを実装せよ.ただし,各形態素は表層形(surface),基本形(base),品詞(pos),品詞細分類1(pos1)をキーとするマッピング型に格納し,1文を形態素(マッピング型)のリストとして表現せよ.第4章の残りの問題では,ここで作ったプログラムを活用せよ.
neko.txt.ginzaを読み込んで,各形態素の情報を取り出します。pos1にはここでいう「小分類」を割り当てています。
def sequence_gen():
''' 情報を一文ずつ取得 '''
with open('neko.txt.ginza') as f:
sequence = []
for line in f:
if line == 'EOS\n':
yield sequence
sequence = []
continue
word_info = line.strip().split('\t')
pos = word_info[4].split(',')
sequence.append({'surface': word_info[1],
'base': word_info[2],
'pos': pos[0],
'pos1': pos[2]})
for sequence in sequence_gen():
print(sequence)
[{'surface': '一', 'base': '一', 'pos': '名詞', 'pos1': '*'}]
[{'surface': '吾輩', 'base': '我が輩', 'pos': '代名詞', 'pos1': '*'}, {'surface': 'は', 'base': 'は', 'pos': '助詞', 'pos1': '*'}, {'surface': '猫', 'base': '猫', 'pos': '名詞', 'pos1': '一般'}, {'surface': 'で', 'base': 'だ', 'pos': '助動詞', 'pos1': '*'}, {'surface': 'ある', 'base': '有る', 'pos': '動詞', 'pos1': '*'}, {'surface': '。', 'base': '。', 'pos': '補助記号', 'pos1': '*'}]
[{'surface': '名前', 'base': '名前', 'pos': '名詞', 'pos1': '一般'}, {'surface': 'は', 'base': 'は', 'pos': '助詞', 'pos1': '*'}, {'surface': 'まだ', 'base': '未だ', 'pos': '副詞', 'pos1': '*'}, {'surface': '無い', 'base': '無い', 'pos': '形容詞', 'pos1': '*'}, {'surface': '。', 'base': '。', 'pos': '補助記号', 'pos1': '*'}]
[{'surface': 'どこ', 'base': '何処', 'pos': '代名詞', 'pos1': '*'}, {'surface': 'で', 'base': 'で', 'pos': '助詞', 'pos1': '*'}, {'surface': '生れ', 'base': '生まれる', 'pos': '動詞', 'pos1': '*'}, {'surface': 'た', 'base': 'た', 'pos': '助動詞', 'pos1': '*'}, {'surface': 'か', 'base': 'か', 'pos': '助詞', 'pos1': '*'}, {'surface': 'と', 'base': 'と', 'pos': '助詞', 'pos1': '*'}, {'surface': 'んと', 'base': 'うんと', 'pos': '感動詞', 'pos1': '*'}, {'surface': '見当', 'base': '見当', 'pos': '名詞', 'pos1': '一般'}, {'surface': 'が', 'base': 'が', 'pos': '助詞', 'pos1': '*'}, {'surface': 'つか', 'base': '付く', 'pos': '動詞', 'pos1': '*'}, {'surface': 'ぬ', 'base': 'ず', 'pos': '助動詞', 'pos1': '*'}, {'surface': '。', 'base': '。', 'pos': '補助記号', 'pos1': '*'}]
[{'surface': '何', 'base': '何', 'pos': '代名詞', 'pos1': '*'}, {'surface': 'で', 'base': 'で', 'pos': '助詞', 'pos1': '*'}, {'surface': 'も', 'base': 'も', 'pos': '助詞', 'pos1': '*'}, {'surface': '薄暗い', 'base': '薄暗い', 'pos': '形容詞', 'pos1': '*'}, {'surface': 'じめじめ', 'base': 'じめじめ', 'pos': '副詞', 'pos1': '*'}, {'surface': 'し', 'base': '為る', 'pos': '動詞', 'pos1': '*'}, {'surface': 'た', 'base': 'た', 'pos': '助動詞', 'pos1': '*'}, {'surface': '所', 'base': '所', 'pos': '名詞', 'pos1': '副詞可能'}, {'surface': 'で', 'base': 'で', 'pos': '助詞', 'pos1': '*'}, {'surface': 'ニャーニャー', 'base': 'にゃあにゃあ', 'pos': '副詞', 'pos1': '*'}, {'surface': '泣い', 'base': '泣く', 'pos': '動詞', 'pos1': '*'}, {'surface': 'て', 'base': 'て', 'pos': '助詞', 'pos1': '*'}, {'surface': 'い', 'base': '居る', 'pos': '動詞', 'pos1': '*'}, {'surface': 'た', 'base': 'た', 'pos': '助動詞', 'pos1': '*'}, {'surface': '事', 'base': '事', 'pos': '名詞', 'pos1': '一般'}, {'surface': 'だけ', 'base': 'だけ', 'pos': '助詞', 'pos1': '*'}, {'surface': 'は', 'base': 'は', 'pos': '助詞', 'pos1': '*'}, {'surface': '記憶', 'base': '記憶', 'pos': '名詞', 'pos1': 'サ変可能'}, {'surface': 'し', 'base': '為る', 'pos': '動詞', 'pos1': '*'}, {'surface': 'て', 'base': 'て', 'pos': '助詞', 'pos1': '*'}, {'surface': 'いる', 'base': '居る', 'pos': '動詞', 'pos1': '*'}, {'surface': '。', 'base': '。', 'pos': '補助記号', 'pos1': '*'}]
...
31. 動詞
動詞の表層形をすべて抽出せよ.
for sequence in sequence_gen():
for word in sequence:
if word['pos'] == '動詞':
print(word['surface'])
ある
生れ
つか
し
泣い
...
32. 動詞の原形
動詞の原形をすべて抽出せよ.
for sequence in sequence_gen():
for word in sequence:
if word['pos'] == '動詞':
print(word['base'])
有る
生まれる
付く
為る
泣く
...
33. サ変名詞
サ変接続の名詞をすべて抽出せよ.
GiNZAの解析結果に「サ変接続」という分類はありませんが,代わりに「サ変可能」という分類がありますので,それを抽出します。
for sequence in sequence_gen():
for word in sequence:
if word['pos'] + word['pos1'] == '名詞サ変可能':
print(word['surface'], word)
記憶 {'surface': '記憶', 'base': '記憶', 'pos': '名詞', 'pos1': 'サ変可能'}
もの {'surface': 'もの', 'base': '物', 'pos': '名詞', 'pos1': 'サ変可能'}
話 {'surface': '話', 'base': '話', 'pos': '名詞', 'pos1': 'サ変可能'}
もの {'surface': 'もの', 'base': '物', 'pos': '名詞', 'pos1': 'サ変可能'}
もの {'surface': 'もの', 'base': '物', 'pos': '名詞', 'pos1': 'サ変可能'}
...
34. 「AのB」
2つの名詞が「の」で連結されている名詞句を抽出せよ.
MeCabでは,"代名詞"は"名詞"の小分類だったのですが,GiNZAの場合,"代名詞"と"名詞"は同列の関係になっています。
import re
pattern = re.compile('N(?:&N)+')
for seq in sequence_gen():
encode_str = ''
for w in seq:
if w['surface'] == 'の':
encode_str += '&'
elif w['pos'] in ('名詞', '代名詞'):
encode_str += 'N'
else:
encode_str += '?'
for m in pattern.finditer(encode_str):
print(''.join(w['surface'] for w in seq[m.start():m.end()]))
彼の掌
掌の上
書生の顔
ものの見
はずの顔
...
35. 名詞の連接
名詞の連接(連続して出現する名詞)を最長一致で抽出せよ.
34同様,MeCabに合わせて代名詞も名詞としています。
import re
pattern = re.compile('NN+')
for seq in sequence_gen():
encode_str = ''.join('N' if w['pos'] in ('名詞', '代名詞') else '?' for w in seq)
for m in pattern.finditer(encode_str):
print(''.join(w['surface'] for w in seq[m.start():m.end()]))
時々我々
時何
見始
時妙
一毛
...
36. 単語の出現頻度
文章中に出現する単語とその出現頻度を求め,出現頻度の高い順に並べよ.
from collections import Counter
counter = Counter(w['surface'] for seq in sequence_gen() for w in seq)
{print(word, num) for word, num in counter.most_common()}
の 9541
。 7486
て 7401
に 7057
、 6773
...
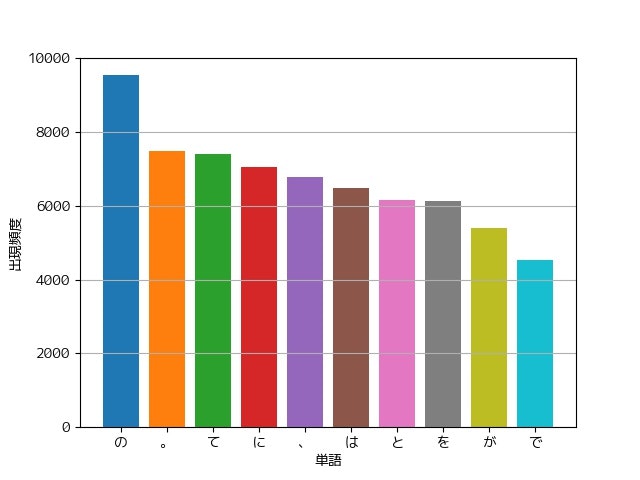
37. 頻度上位10語
出現頻度が高い10語とその出現頻度をグラフ(例えば棒グラフなど)で表示せよ.
from collections import Counter
import matplotlib.pyplot as plt
counter = Counter(w['surface'] for seq in sequence_gen() for w in seq)
for word, num in counter.most_common(10):
plt.bar(word, num)
plt.grid(axis='y')
plt.xlabel('単語')
plt.ylabel('出現頻度')
plt.show()
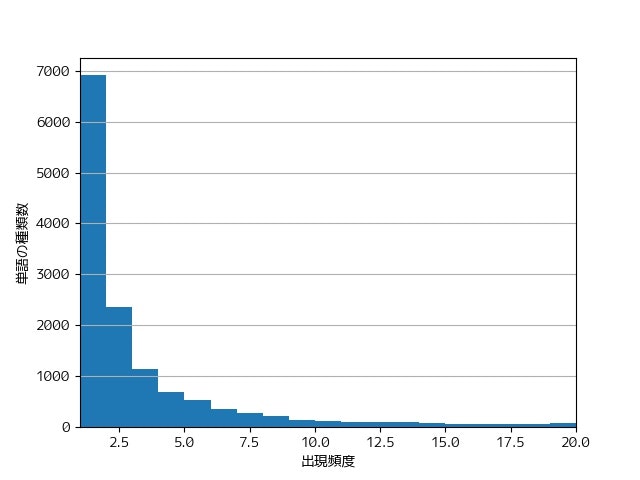
38. ヒストグラム
単語の出現頻度のヒストグラム(横軸に出現頻度,縦軸に出現頻度をとる単語の種類数を棒グラフで表したもの)を描け.
from collections import Counter
import matplotlib.pyplot as plt
counter = Counter(w['surface'] for seq in sequence_gen() for w in seq)
plt.hist([n for w, n in counter.most_common()], bins=19, range=(1, 20))
plt.xlim(xmin=1, xmax=20)
plt.grid(axis='y')
plt.xlabel('出現頻度')
plt.ylabel('単語の種類数')
plt.show()
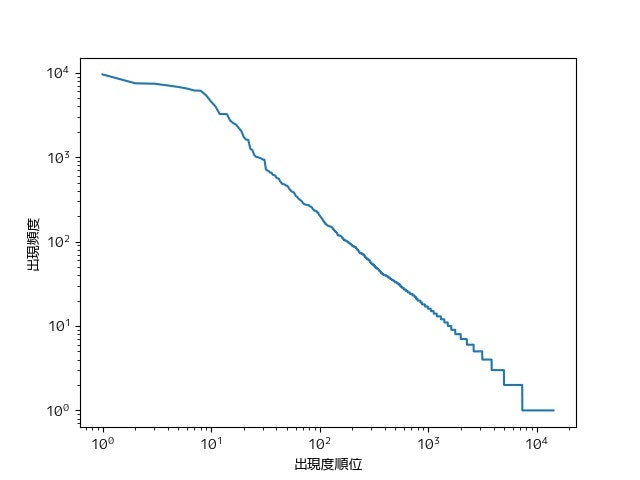
39. Zipfの法則
単語の出現頻度順位を横軸,その出現頻度を縦軸として,両対数グラフをプロットせよ.
from collections import Counter
import matplotlib.pyplot as plt
counter = Counter(w['surface'] for seq in sequence_gen() for w in seq)
counts = [n for w, n in counter.most_common()]
plt.loglog(range(1, len(counts) + 1), counts)
plt.xlabel('出現度順位')
plt.ylabel('出現頻度')
plt.show()
参考
https://megagonlabs.github.io/ginza/
https://www.recruit.co.jp/newsroom/2019/0402_18331.html
https://github.com/megagonlabs/ginza
https://spacy.io/