はじめに
今回はマルチモーダルエンベディングについてのメモ書きです。いつもと違って自分自身忘れないようにという意味合いが強いので、自分用のざっくり説明になります。
ことの発端
最近、生成AIを使って色々試していることがあるのですが、その中で画像やらテキストやらを何でもベクトル化するマルチモーダルエンベディングという技術があることを知りました。で、最初はマルチモーダルといっても画像をテキストに直してそれをベクトル化してるんじゃないの?と勝手に思い込んでいたのですが、どうやらそうではないらしいです。そもそもテキスト化していたらマルチモーダルとは言えないんで気づけよという話ですが。。。
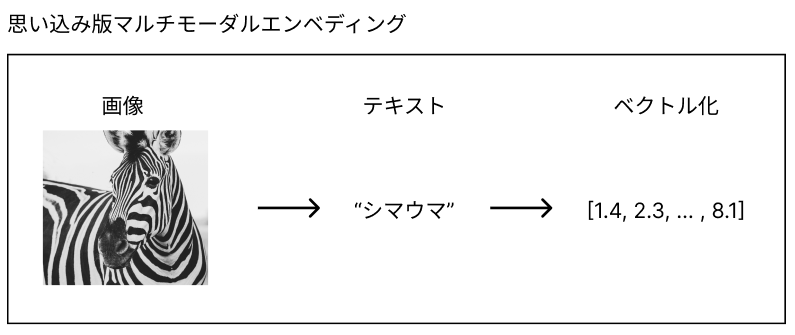
これをきっかけにマルチモーダルエンベディング(画像とテキストのエンベディング)について調べたのでそのメモ書きとなります。
CLIP
CLIPは画像とテキストをベクトル化(エンベディング)できる機械学習モデルです。まさにマルチモーダルエンベディングですね。
CLIPは、「WebImageText」とよばれるデータセットで学習されています。「WebImageText」はインターネット上にある膨大なデータを利用して作成された4億組の画像とテキストのペアです。画像のタイトルや説明がファイル名になっているものを収集しているので、画像とテキストのペアが得られるようです。
学習方法は下記の通りです。
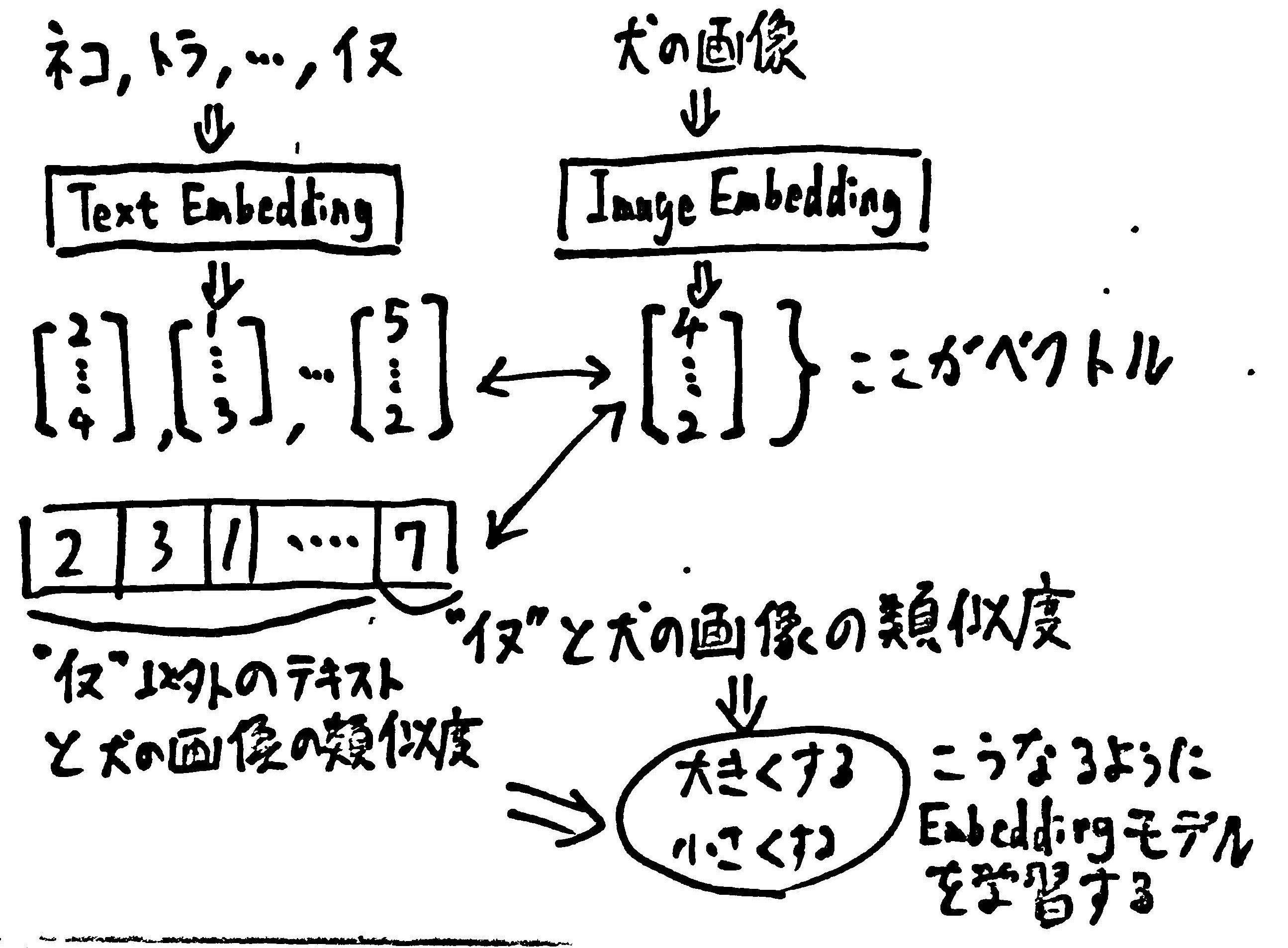
- 画像を1枚与える
- 画像を示すテキストを10パターン用意する(正解は1つ、残りは不正解)
- 画像とテキストをそれぞれベクトル化して、各組み合わせで類似度を計算する
- 正解を確認する
- 正解のペアについては類似度が高くなるように、それ以外は類似度が低くなるようにモデルを学習する
これを繰り返すことで、最終的にモデルは画像とテキストを意味ごとにベクトル化できるようになります。図で示した通り直接画像をベクトル化しており、画像⇒テキストではありません。これがマルチモーダルたる理由です。
プロンプトエンジニアリングについて
最近、生成AIで流行りの「プロンプトエンジニアリング」ですがCLIPでも既に「プロンプトエンジニアリング」がありました。CLIPは画像分類などにも応用できるのですが、その際に与えるテキストを変えることで分類精度が向上する、という性質があります。この、精度向上のためにテキストを変えることを「プロンプトエンジニアリング」とよんでいたのです。
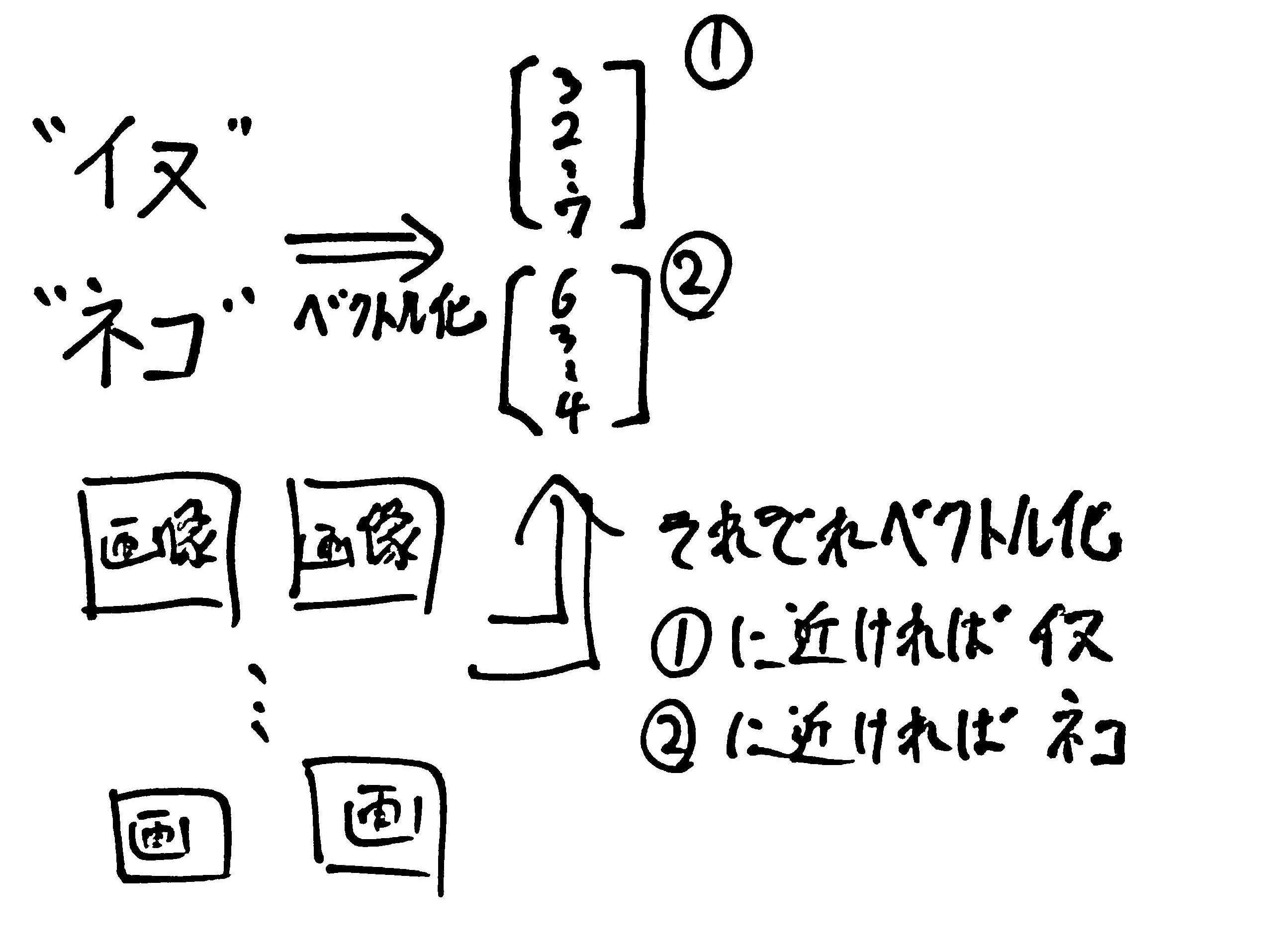
上の図でいうと"イヌ"、"ネコ"をそれぞれ"イヌの画像"、"ネコの画像"などの文字に変えると精度が上がる、ということです。
さいごに
マルチモーダルエンベディングはちゃんと画像、テキストをそのままベクトル化してるんですね。調べてみてスッキリしました。
ブログ↓
https://mochinochikimchi.com
自作アプリLP↓
https://mochinochikimchi.com/applications/mealmotion/index.html