HARファイル(JSON)を加工して分かりやすくしたい
その汎用性から言語や場面を問わずJSON形式のデータが飛び交うようになり、結果としてJSON形式を扱うことが可能なライブラリも多種多様なものが開発/公開されています。
先日Selenium Wireに関する記事を投稿しましたが、Selenium Wireの処理結果としての通信情報もJSON形式のHAR(HTTPアーカイブ)ファイルとして取得できます。
中身はHTTP(S)通信なので、その基本的な構造はリクエストとレスポンスのセットが複数個並んでいる単純なものではあるのですが、通信ログはそのままだと不要な情報も多く、一見すると圧倒されがちです。
HARの汎用的なビューアもあるとはいえ都度ビューアで内容を確認するよりも、自分の望む情報が分かっている場合は直接HARファイルを操作した方が効率的な場合もあることから、今回はAWS Lambda上でHARファイルを基にした解析っぽいことをしたいと思います。
なお、対象とするHARファイルや環境など、前回の記事を(一部)基にしています。
注意事項
- HARファイルには通信内容が記録されているため、IDやパスワード、セッション情報などの機密にすべき情報が含まれることがあります。
HARファイルの取り扱いにはご注意ください(HARファイルを他者へ開示しない、開示の必要がある場合は機密情報を削除するなど)。
この記事のゴール
前回の記事ではHARファイルの出力までで終わっていたため、本記事ではHARファイルを処理するための次の2つのAWS Lambda関数を作成します。
- HARファイルからURLを抽出する
→先ずは単純にHARファイルをJSONとして扱い、HARファイル内からURLを取得し一覧化します。
→「ZIP形式のLambda関数」で実装します。 - HARファイルからSeabornを使ってグラフを作成する
→HARファイルの内容をPandasに読み込み、Seabornを使ってグラフを作成します。
→「コンテナ形式のLambda関数」で実装します。
それでは順番に作成していきたいと思いますが、基本的にはそれぞれ独立したものですのでご興味のあるものを参照ください。
1. HARファイルからURLを抽出する
HARファイルにはアクセスする対象のURLが含まれており、これを抽出して一覧化します。
1-0. 前提
- AWS Lambdaコンソール(以下、コンソール)から作成します。
- Lambda関数はS3からHARファイルの読み込み&処理結果のファイル書き込みを行うため、バケットおよび処理対象とするHARファイルを事前にご用意ください。
- Selenium Wireにて出力したHARファイルを対象に検証しています。
1-1. Lmabda関数の作成
コンソールから、「関数の作成」ボタンを押下して「関数の作成」画面を表示します。
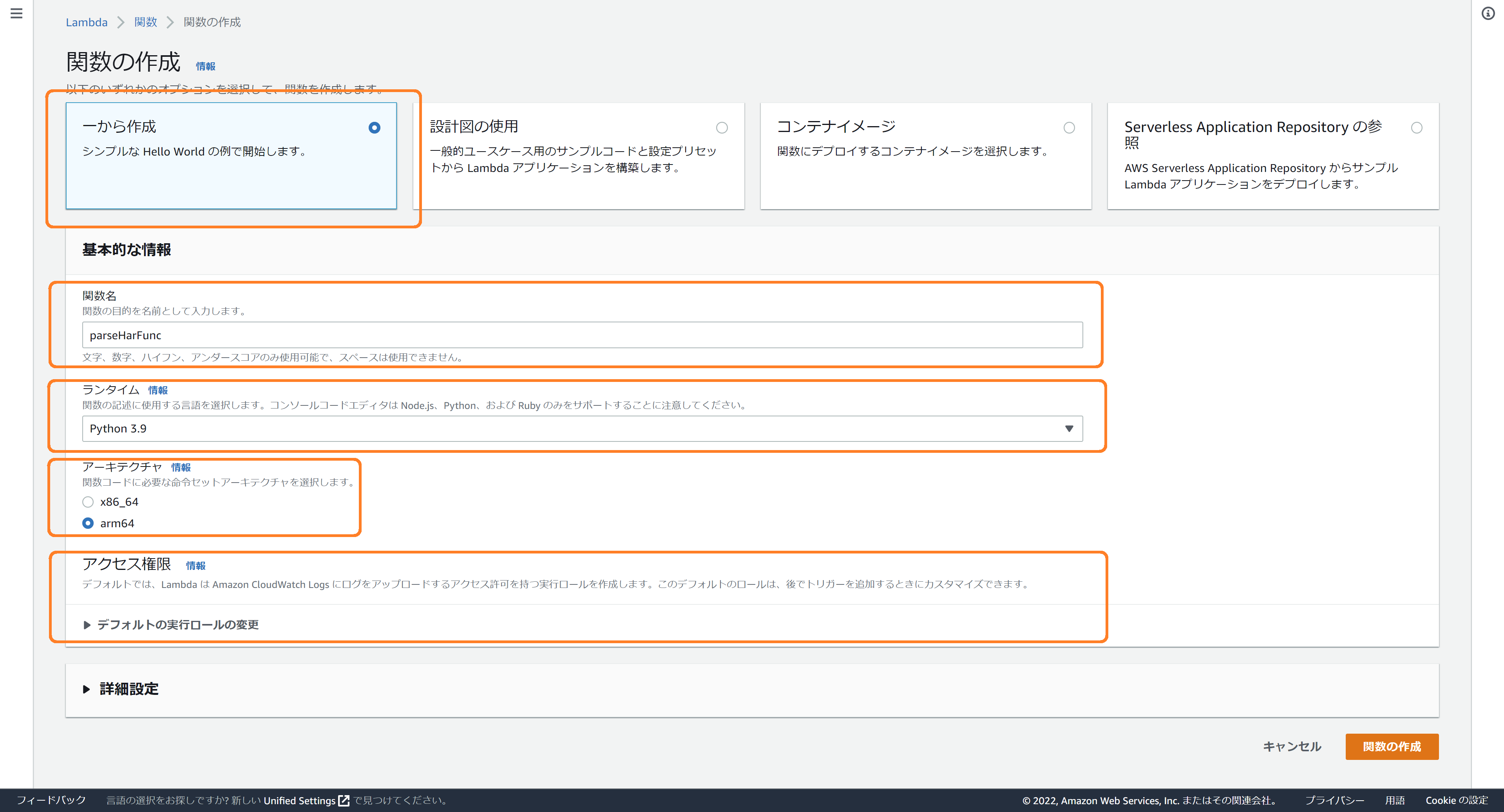
以下のように設定します。
- 「一から作成」を選択
- 「関数名」に任意の名称を入力(例:parseHarFunc)
- 「ランタイム」として、「Python 3.9」を選択
- 「アーキテクチャ」として、「arm64」を選択
(「x86_64」を選択いただいても問題ありませんが、コスト的に「arm64」を選択しています) - 「アクセス権限」として、基本的なLambdaアクセス権限に加え、S3へのアクセス権を付与してください。
入力完了後、「関数の作成」ボタンを押下し、Lambda関数の作成完了を待ちます。
1-2. Lambda関数のコード入力
Lambda関数の作成が完了したら、コンソール上でコードを入力します。
ポイントは次のとおりです。
- HARファイルが格納されている、また、処理結果を保存するバケット名を、BUCKET_NAMEに設定します。
- HARファイル名は本Lambda関数をコールする際のイベントJSONにセットしたものを使用します。
入力するコードは以下のとおりです。
import json
import boto3
from datetime import datetime
s3 = boto3.resource('s3')
# HARファイルを格納するバケット名を設定します
BUCKET_NAME = "************"
def lambda_handler(event, context):
targetHar = event['target_har']
# S3から読み込み
bucket = s3.Bucket(BUCKET_NAME)
obj = bucket.Object(targetHar)
response = obj.get()
body = response['Body'].read()
har = json.loads(body)
entries = har['log']['entries']
urls = set(map(lambda x: x['request']['url'], entries))
# URL単位に何か処理をしたい場合はここに記述
# for url in urls:
# TODO:
# print(url)
# S3へURLリストを保存
urlsName = "sw_" + datetime.now().strftime('%Y-%m-%d-%H-%M-%S') + "_urls.txt"
obj = s3.Object(BUCKET_NAME,urlsName)
obj.put( Body="\r\n".join(urls) )
return {
"statusCode": 200,
"body": {"urls": urlsName}
}
下図はコードを入力後のイメージです。
1-3. テスト
コードの入力が完了したら、続いてテストします。
テストを行う前に、次の事項について問題がないかを確認します。
- S3バケットを用意
- 処理対象のHARファイルを用意したバケットに格納
- 入力したコードのBUCKET_NAMEに用意したバケット名を入力
- Lambda関数にS3へのアクセス権を付与している
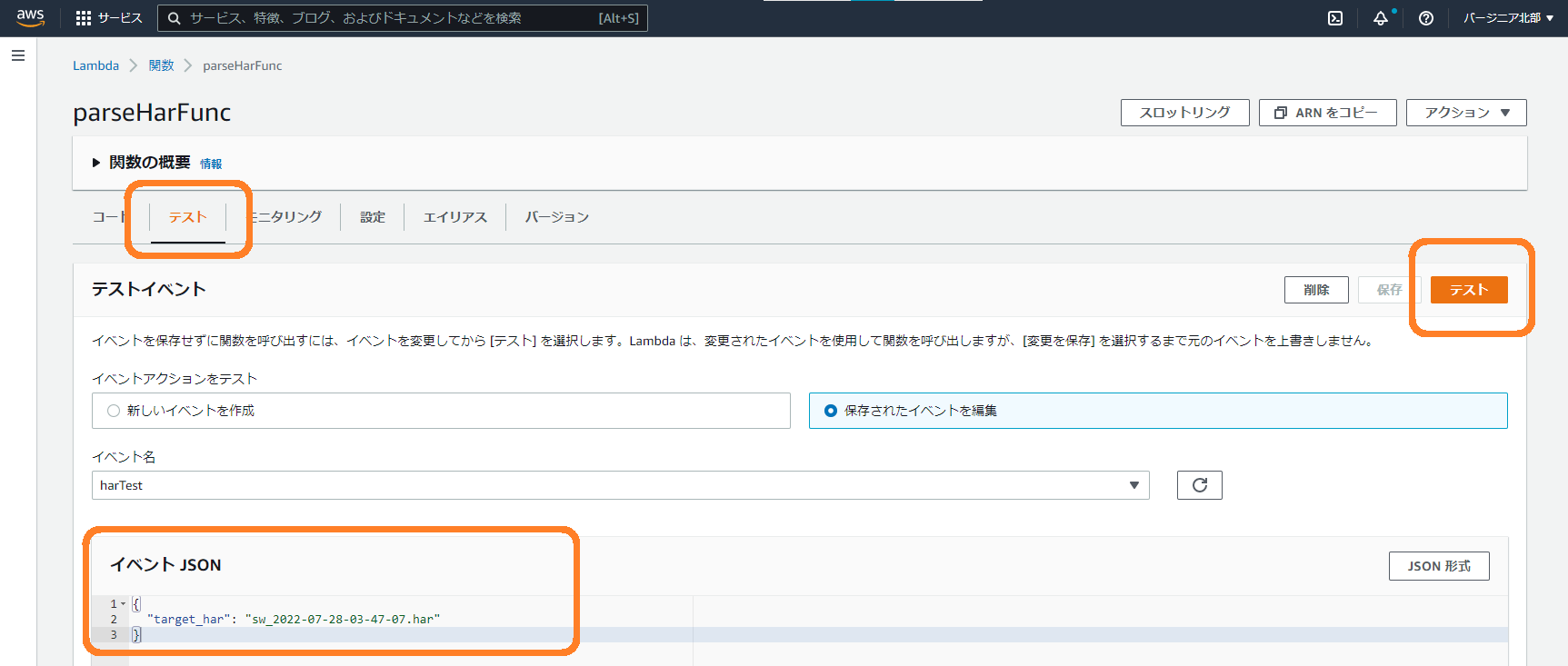
問題がない場合、テストの設定としてイベントJSONを入力します。
イベントJSONのtarget_harの値には、バケットに格納している処理対象のHARファイル名を指定してください。
{
"target_har": "sw_2022-07-28-03-47-07.har"
}
イベントJSONを入力したら「テスト」ボタンを押下します。
テストが問題なく実施できた場合、処理結果としてバケットにHARファイル内のURL一覧を示すファイルが作成されます。
2. HARファイルからSeabornを使ってグラフを作成する
HARファイルにはアクセスした際のレスポンスに要した時間が含まれています。
この情報を基にグラフを作成します。
2-0. 前提
- Cloud9から作成します。
- Lambda関数はS3からHARファイルの読み込み&処理結果のファイル書き込みを行うため、バケットおよび処理対象とするHARファイルを事前にご用意ください。
- Selenium Wireにて出力したHARファイルを対象に検証しています。
- 基本的な進め方は以前の記事と同じになるため、差分となるコードの部分だけ記載します。
2-1. 作成するグラフ
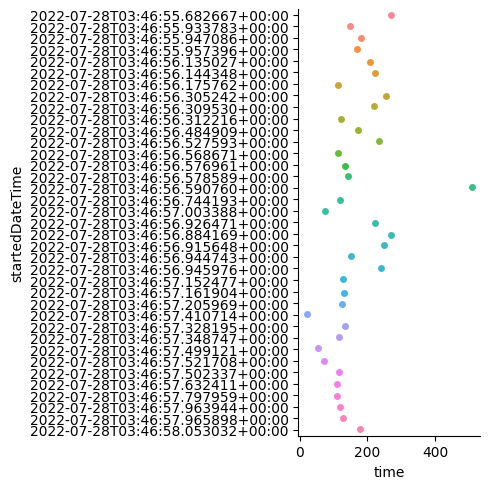
各リクエストのリクエストからレスポンスまでの時間をプロットした、下図のようなグラフを作成します。
2-2. コード
コンテナ形式のLambdaを作成します。
手順については以下の記事を参照していただければと思います。
Dockerfile、app.pyのコードを以下に記載します。
Dockerfile
FROM public.ecr.aws/lambda/python:3.9
RUN pip install --upgrade pip
RUN pip install pandas
RUN pip install seaborn
COPY app.py ./
CMD [ "app.handler" ]
app.py
import json
import pandas as pd
import seaborn as sns
import boto3
from datetime import datetime
s3 = boto3.resource('s3')
# HARファイルが格納されているバケット名を設定します
BUCKET_NAME = "YOUR BUCKET NAME"
def handler(event, context):
har = event['target_har']
# S3からHARファイルを読み込み
bucket = s3.Bucket(BUCKET_NAME)
obj = bucket.Object(har)
body = obj.get()['Body'].read()
harJson = json.loads(body)
df = pd.DataFrame(harJson['log']['entries'])
# グラフ描画
pg = sns.catplot(x="time", y="startedDateTime", data=df, kind="strip")
# グラフをtmpに保存
imageName = "graph_" + datetime.now().strftime("%Y-%m-%d-%H-%M-%S") + ".png"
pg.savefig("/tmp/" + imageName)
# S3へグラフを保存
data = open("/tmp/" + imageName, 'rb')
bucket.put_object(Key=imageName, Body=data)
return {
"statusCode": 200,
"body": {"imageName": imageName}
}
以上です。