ライブラリのimport
まずは、以下のライブラリをimportします。
import torch
import torch.utils.data
import torch.nn as nn
import numpy as np
import random
import torch.nn.functional as F
from model_for_bert import LinearModel # 有料
from data_cleaning import data_cleaning # 無料
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from bert_sequence_vectorizer_ver2 import BertSequenceVectorizer # 有料
from earlystopping import EarlyStopping # 無料
import pickle
SEEDの固定
SEEDを固定します。
SEED = 20201215
random.seed(SEED)
np.random.seed(SEED)
torch.manual_seed(SEED)
torch.cuda.manual_seed_all(SEED)
Deep Learningのハイパーパラメータを設定
Deep Learningを行うにあたり、ハイパーパラメータを設定します。
# ハイパーパラメータ
LEARNING_RATE = 0.0001
BATCH_SIZE = 10
PATIENCE = 5
EPOCHS = 10
データをロード
データをロードします。
# 訓練データをロード
with open('data.pkl', mode='rb') as f:
data = pickle.load(f)
with open('label.pkl', mode='rb') as f:
label = pickle.load(f)
データの前処理
データを前処理します。
data = data_cleaning(data)

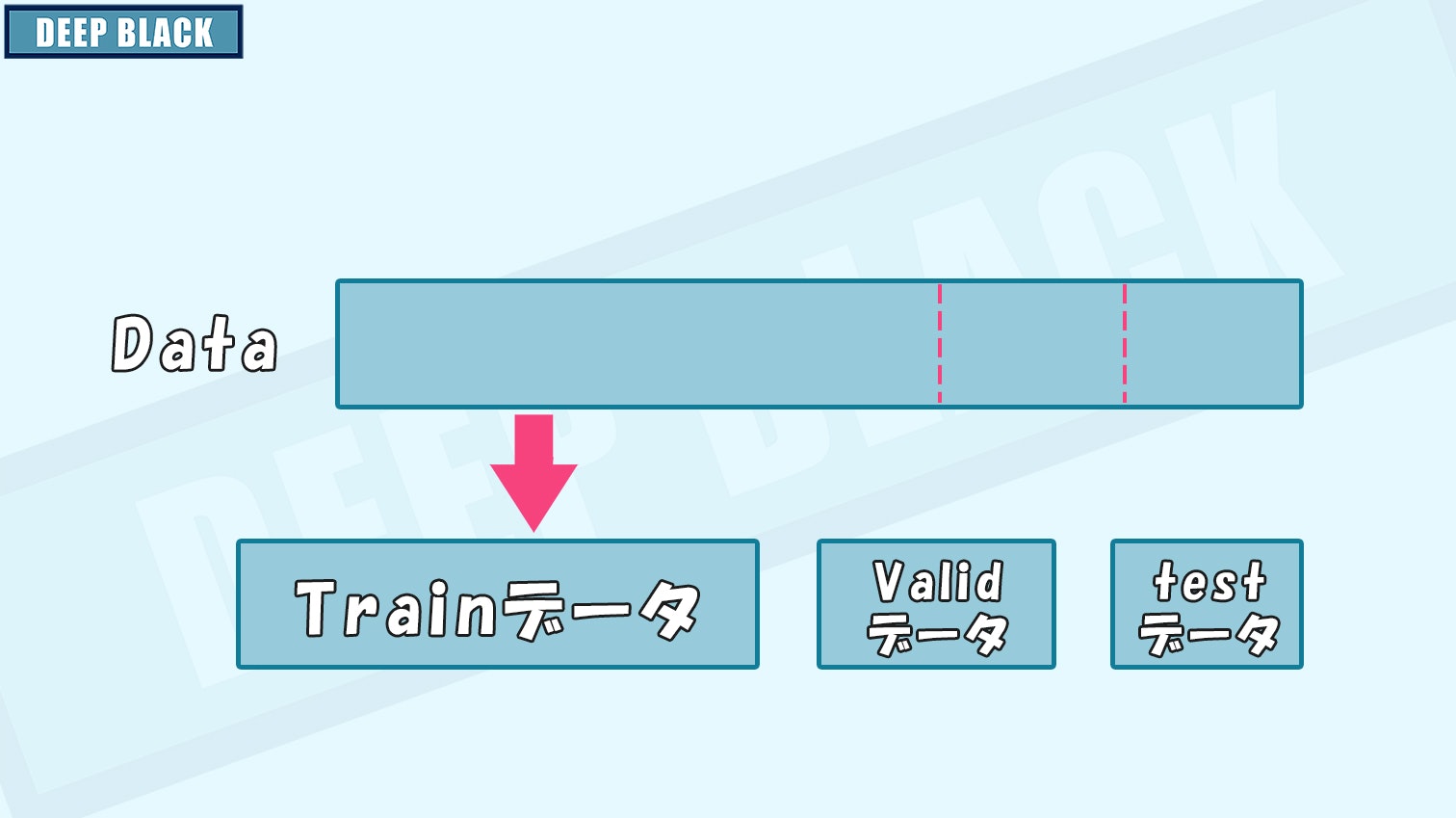
訓練・検証・テストデータに分ける
scikit-learnのtrain_test_splitを用いて、データを訓練・検証・テストデータに分けます。
X, test_data, y, test_label = train_test_split(
data, label, test_size=0.2, random_state=42)
train_data, valid_data, train_label, valid_label = train_test_split(
X, y, test_size=0.2, random_state=42)
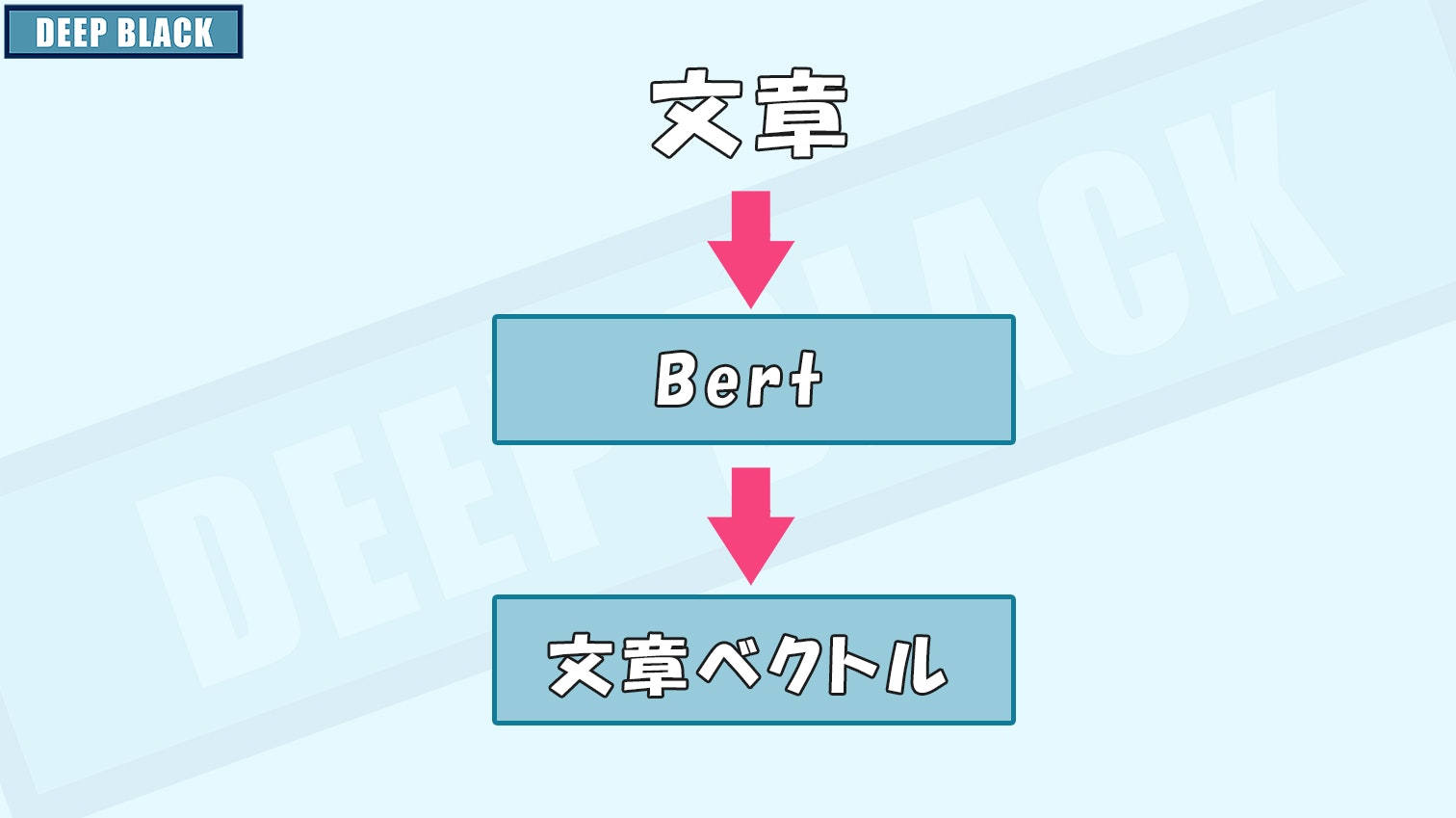
BERTで文章をベクトル化
BertSequenceVectorizerを用いて、文章をベクトル化します。
BSV = BertSequenceVectorizer() # BERTでベクトル化
print("文章ベクトル化開始")
print("訓練")
train_lst = list()
for i in range(0, len(train_data)):
train_lst += [BSV.vectorize(train_data[i], 512)]
print("検証")
valid_lst = list()
for i in range(0, len(valid_data)):
valid_lst += [BSV.vectorize(valid_data[i], 512)]
print("テスト")
test_lst = list()
for i in range(0, len(test_data)):
test_lst += [BSV.vectorize(test_data[i], 512)]
train_arr = np.array(train_lst)
valid_arr = np.array(valid_lst)
test_arr = np.array(test_lst)
print("文章ベクトル化終了")
Datasetの定義
PytorchのDatasetを定義します。
class MyDataSet(torch.utils.data.Dataset):
def __init__(self, data, label):
self.data = data
self.label = label
self.length = len(data)
def __len__(self):
return self.length
def __getitem__(self, index):
data = self.data[index]
label = self.label[index]
return data, label
DataLoaderの定義
PytorchのDataLoaderを定義します。
trainset = MyDataSet(train_arr, train_label)
trainloader = torch.utils.data.DataLoader(
trainset, batch_size=BATCH_SIZE, shuffle=True)
validset = MyDataSet(valid_arr, valid_label)
validloader = torch.utils.data.DataLoader(
validset, batch_size=10, shuffle=True)
ネットワークの定義
BERTで文章をベクトル化した後、クラス分けを行うモデルを定義します。
model = LinearModel() # ネットワーク
損失関数、最適化手法、Early Stoppingの設定
損失関数、最適化手法、Early Stoppingを設定します。
criterion = nn.NLLLoss()
optimizer = torch.optim.AdamW(model.parameters(), lr=0.0001)
earlystopping = EarlyStopping(patience=PATIENCE, verbose=True)
ネットワークの学習
ネットワークの学習を行います。
for epoch in range(EPOCHS):
print(epoch)
train_loss = 0
train_acc = 0
total = 0
model.train()
# cnt = 0
for data in trainloader:
optimizer.zero_grad()
output = model(data[0])
predicted = torch.argmax(output, axis=1)
target = data[1]
loss = criterion(output, target)
train_loss += loss.item()
train_acc += (predicted == target).sum().item()
total += data[1].size(0)
loss.backward()
optimizer.step()
train_loss = train_loss / total
train_acc = train_acc / total
print(f"{train_loss}")
print("訓練データでの精度は、"+str(train_acc*100)+"%です。")
model.eval()
vali_total = 0
vali_loss = 0
vali_acc = 0
for data in validloader:
with torch.no_grad():
out = model.forward(data[0])
predicted = torch.argmax(out, axis=1)
target = data[1]
loss = criterion(out, data[1])
vali_loss += loss.item()
vali_acc += (predicted == target).sum().item()
vali_total += data[1].size(0)
vali_loss = vali_loss / vali_total
vali_acc = vali_acc / vali_total
print("検証データでの精度は、"+str(vali_acc*100)+"%です。")
earlystopping(vali_loss, model)
if earlystopping.early_stop:
print("Early stopping")
break
テストデータで精度を算出
テストデータで作成された、モデルの精度を算出します。
model.load_state_dict(torch.load("model.pth"))
model.eval()
testset = MyDataSet(test_arr, test_label)
testloader = torch.utils.data.DataLoader(
testset, batch_size=1, shuffle=False)
res_lst = list()
for data in testloader:
res = model(data[0])
if torch.cuda.is_available():
res = res.cpu()
res_lst.append(np.argmax(np.exp(res.detach().numpy())))
print(accuracy_score(test_label, res_lst))
Code
import torch
import torch.utils.data
import torch.nn as nn
import numpy as np
import random
import torch.nn.functional as F
from model_for_bert import LinearModel
from data_cleaning import data_cleaning
from sklearn.model_selection import train_test_split
from bert_sequence_vectorizer_ver2 import BertSequenceVectorizer
from earlystopping import EarlyStopping
import pickle
# ハイパーパラメータ
LEARNING_RATE = 0.0001
BATCH_SIZE = 10
PATIENCE = 5
EPOCHS = 10
SEED = 20201215
random.seed(SEED)
np.random.seed(SEED)
torch.manual_seed(SEED)
torch.cuda.manual_seed_all(SEED)
# 訓練データをロード
with open('data.pkl', mode='rb') as f:
data = pickle.load(f)
with open('label.pkl', mode='rb') as f:
label = pickle.load(f)
# data = data[:50]
# label = label[:50]
print(len(data))
data = data_cleaning(data)
X, test_data, y, test_label = train_test_split(
data, label, test_size=0.2, random_state=42)
train_data, valid_data, train_label, valid_label = train_test_split(
X, y, test_size=0.2, random_state=42)
BSV = BertSequenceVectorizer() # BERTでベクトル化
print("文章ベクトル化開始")
print("訓練")
train_lst = list()
for i in range(0, len(train_data)):
train_lst += [BSV.vectorize(train_data[i], 768)]
print("検証")
valid_lst = list()
for i in range(0, len(valid_data)):
valid_lst += [BSV.vectorize(valid_data[i], 768)]
print("テスト")
test_lst = list()
for i in range(0, len(test_data)):
test_lst += [BSV.vectorize(test_data[i], 768)]
train_arr = np.array(train_lst)
valid_arr = np.array(valid_lst)
test_arr = np.array(test_lst)
print("文章ベクトル化終了")
class MyDataSet(torch.utils.data.Dataset):
def __init__(self, data, label):
self.data = data
self.label = label
self.length = len(data)
def __len__(self):
return self.length
def __getitem__(self, index):
data = self.data[index]
label = self.label[index]
return data, label
trainset = MyDataSet(train_arr, train_label)
trainloader = torch.utils.data.DataLoader(
trainset, batch_size=BATCH_SIZE, shuffle=True)
validset = MyDataSet(valid_arr, valid_label)
validloader = torch.utils.data.DataLoader(
validset, batch_size=10, shuffle=True)
model = LinearModel() # ネットワーク
criterion = nn.NLLLoss()
optimizer = torch.optim.AdamW(model.parameters(), lr=0.0001)
earlystopping = EarlyStopping(patience=PATIENCE, verbose=True)
print("学習開始")
for epoch in range(EPOCHS):
print(epoch)
train_loss = 0
train_acc = 0
total = 0
model.train()
# cnt = 0
for data in trainloader:
optimizer.zero_grad()
output = model(data[0])
predicted = torch.argmax(output, axis=1)
target = data[1]
loss = criterion(output, target)
train_loss += loss.item()
train_acc += (predicted == target).sum().item()
total += data[1].size(0)
loss.backward()
optimizer.step()
train_loss = train_loss / total
train_acc = train_acc / total
print(f"{train_loss}")
print("訓練データでの精度は、"+str(train_acc*100)+"%です。")
model.eval()
vali_total = 0
vali_loss = 0
vali_acc = 0
for data in validloader:
with torch.no_grad():
out = model.forward(data[0])
predicted = torch.argmax(out, axis=1)
target = data[1]
loss = criterion(out, data[1])
vali_loss += loss.item()
vali_acc += (predicted == target).sum().item()
vali_total += data[1].size(0)
vali_loss = vali_loss / vali_total
vali_acc = vali_acc / vali_total
print("検証データでの精度は、"+str(vali_acc*100)+"%です。")
earlystopping(vali_loss, model)
if earlystopping.early_stop:
print("Early stopping")
break
model.load_state_dict(torch.load("model.pth"))
model.eval()
testset = MyDataSet(test_arr, test_label)
testloader = torch.utils.data.DataLoader(
testset, batch_size=1, shuffle=False)
res_lst = list()
for data in testloader:
res = model(data[0])
if torch.cuda.is_available():
res = res.cpu()
res_lst.append(np.argmax(np.exp(res.detach().numpy())))
from sklearn.metrics import accuracy_score
print(accuracy_score(test_label, res_lst))
以上でBERTで行うテキスト分類を終わりにいたします。
BERTのモデルまた分類モデルに興味がある方は、以下のリンクからご購入お願いします。
https://zenn.dev/deepblackinc/books/ad568c611643c6
仕事、ご相談は
mailto:deepblack.inc@gmail.com
までお願いいたします。