自分がよく使っているPower Queryのuse caseをまとめてみました。まだ覚えたてなので、いろいろつたない点もありますが、お気づきの点がございましたらご指摘ください。
Mの特徴
とりあえず、Mの特徴をざっくりまとめます。
- 大文字小文字を区別する
- データ型の扱いが厳密
- インデックスが0から始まる
- すべての式は同時に評価される
最後の点はちょっとわかりにくいですが、要は上から順番に実行されるのではなく、表計算ソフトのように依存関係に従って処理されるということです。
データ型
こちらもざっくり。詳しくはMSのreferenceを見るのが一番良いです。
リスト
リストというのは値の集合で0から始まるインデックスがついています。リストを作るには以下のように{}で各要素を並べるだけです。あらかじめ決まっているリストは直接書いてしまったほうが早いこともあります。
{1, 2, true, "abc", 3.1}
リストは順番のある値の集合なので、0から始まるインデックスを後ろにつけて取り出せます。
{1, 2, true, "abc", 3.1}{4} #3.1が返る
複数取り出す場合は、List.Rangeを使います。{0..10}というのは、0から10までの11個のリストです。これでインデックス0から5の一つ前までを取り出します。
List.Range({0..10}, 0, 5)
結果
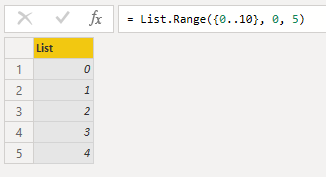
結果に表示されるインデックスは1から始まるので、関数内のインデックスと違うことに注意してください。例えばList.Range({0..10}, 0, 5){1}は2番目の要素1が返ってきます。
テーブル
テーブルは#table()関数で作成できます。ほかの例はMicrosoftのサイトを見たほうがいいでしょう。
# table(
{"Name", "Sex"},
{
{"Mike","M"},
{"Anne","F"}
}
)
関数
関数の定義は以下のように書けます。
(x as number) as number =>
let
Ret = if x < 2
then x
else Fib(x - 1) + Fib(x - 2)
in
Ret
こちらはよくあるフィボナッチ数を計算する関数ですが、見てわかるように再帰も可能です。このクエリーにFibという名前を付けてセーブするとクエリー内のFibでこの関数自身を呼び出します。
以下は20200401などの8桁の文字列を日付型に変換する関数で、うまく変換できなかったらそのままの文字列を返します。
(x as text) =>
let
usrYear = Number.From(Text.Middle(x, 0, 4)),
usrMonth = Number.From(Text.Middle(x, 4, 2)),
usrDay = Text.Middle(x, 6, 2),
isDD = Value.Is(Value.FromText(usrDay), type number),
usrDate = if isDD
then Date.From(#date(usrYear, usrMonth, Number.From(usrDay)))
else x
in
usrDate
エディターを閉じてこのクエリーを選択すると、自分でパラメーターを入れて結果を確認することもできます。
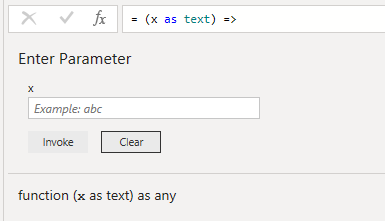
この関数はほかのクエリーでも使えるので、クエリー内でよく使う関数は、ユーザー関数にしておくと便利です。
外部に保存されたクエリーを使用する
これはググって見つけた方法なのですが、これらのコードをテキストファイルに保存してそれを呼び出すことも可能です。適当なテキストエディタでクエリー部分を書いて保存すると、以下のクエリーで同じように実行できます。いろいろなファイルで共通の関数を使用したい場合には便利です。
let
Source = Text.FromBinary(File.Contents("C:\temp\func.m")),
EvaluatedExpression = Expression.Evaluate(Source, #shared)
in
EvaluatedExpression
#sharedというパラメーターはないと動きません。謎です。
再帰関数はそのままではうまく実行できませんので、ちょっと工夫が必要になります。
let
Fib = (x as number) as number =>
let
Ret = if x < 2
then x
else @Fib(x - 1) + @Fib(x - 2)
in
Ret
in
Fib
このようにletをネストして、Fib関数の定義自体を埋め込んでしまえばファイルとして取り込んでも使えるようになります。普段からこのように書いたほうが、クエリー名に影響されずコピペできるのでいいかもしれません。再帰で呼ぶ場合は頭に@をつけるルールがあるらしいのですが、つけなくても動きました。
一つのファイルに複数の関数をまとめる
複数のユーザー関数をカンマで区切って並べ、それぞれをレコードとして返します。SumProductはググって見つけた関数です。
let
Fib = (x as number) as number =>
if x < 2 then x else @Fib(x - 1) + @Fib(x - 2),
Multiply = (x, y) => (x * y),
SumProduct = (L1 as list, L2 as list) as number =>
let
Result = List.Accumulate(List.Positions(L1),
0,
(state, current) => state + L1{current} * L2{current})
in
Result,
Ret = [
Fib = Fib,
Multiply = Multiply,
SumProduct = SumProduct
]
in
Ret
これはそれぞれの関数名をキーに関数を値として持つレコードを返すので、myfuncsなどのクエリーでこのテキストファイルを読み込んでおくと、
myfuncs[SumProduct]({1..10}, {2..11})
などとして、引数を()でつけて呼び出すことができます。
PythonのDataFrameをテーブルとして利用する。
Pythonを使用する設定をしておけば、PandasのDataFrameを読み込むことができます。クエリーのソースでPythonを選択するとエディターが開くので、ここにコードを書くのですが、ここではコードを適当なテキストエディタやIDEで作成し別のファイルとして保存してみます。例えば、
import pandas as pd
from sklearn.datasets import load_boston
boston_dataset = load_boston()
boston = pd.DataFrame(boston_dataset.data, columns=boston_dataset.feature_names)
というファイルを作成し、クエリーエディタで以下のように書きます。
let
Source = Python.Execute(Text.FromBinary(File.Contents("c:\temp\bostondf.py"))),
Ret = Source{[Name="boston"]}[Value]
in
Ret
そうすると、データフレームがテーブルになります。
一つのコードで複数のデータフレームを定義したい場合は単にDFを列挙します。
import pandas as pd
from sklearn.datasets import load_boston
boston_dataset = load_boston()
boston = pd.DataFrame(boston_dataset.data, columns=boston_dataset.feature_names)
boston_01 = boston[:100]
boston_02 = boston[100:200]
boston_03 = boston[200:300]
boston_04 = boston[300:400]
boston_05 = boston[400:500]
boston_06 = boston[500:600]
クエリーは以下のように書くと、それぞれのDFとテーブルからなるテーブルが返されます。
Python.Execute(Text.FromBinary(File.Contents("c:\temp\bostondf.py")))
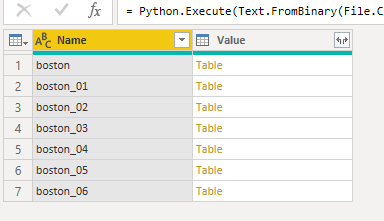
このコードを読み込んだクエリーをLoadPythonDFsなど適当な名前で保存し、新しいクエリーを以下のように作成すると、PythonのDF名を引数にDFを持ってこれる関数が作成できます。
(tName) => LoadPythonDFs{[Name=tName]}[Value]
pythonを呼び出すのは非常に時間がかかりますが、一度データを取り込んでしまえば、Power BIの動作は軽いです(多分)。pythonコードを編集するたびにpermissionを聞かれるのがちょっと面倒です。
ファイル名のフィールドが作成されないとき
データソースにフォルダーを指定して、複数のファイルをまとめて取り込むとき、Source.Nameのフィールドが作成されなくて、どのファイルのデータかわからないことがあります。うまくいくこともあるのですが、私の環境ではなぜかしょっちゅうミスります。これバグだと思うんですが。
そんなとき、クエリーをみて、こうなっている部分を見つけてください。

間に1行追加して、続く行を以下のように修正します。

これでめでたくSource.Nameの項目が追加されます。
フィールドをまとめて削除
不要なフィールドを削除するとき、何を消すか大体決まっていることが多いです。こんなテーブルを作っていらないフィールドをベタ打ちしておきます。
let
UnecessaryFields = #table(
{"DataName", "ListofFields"},
{
{"Report1",
{"いらないフィールド1", "いらないフィールド2", "いらないフィールド3"}
},
{"Report2",
{"いらないフィールド1", "いらないフィールド2", "いらないフィールド3"}
}
}
)
in
UnecessaryFields
そして、クエリーにこんな風に書くと、指定したフィールドをまとめて削除できます。
Remove_Fields = Table.RemoveColumns(
"前のテーブル", Table.SelectRows(UnecessaryFields, each [DataName] = "Report1"
){0}[ListofFields])
乱数
Number.RandomBetween(a, b)でaからbまでの乱数を取得することができますが、そのままコラムに追加すると、全部同じ数字になってしまうことがあります。(ならないこともある。謎)この場合、こうやって、最初の引数になにか数字のコラムを足し引きすると、レコード毎に違う乱数を計算してくれます。
let
ListN = #table({"i"}, List.Transform({1..10}, each {_})),
#"Added Custom" = Table.Buffer(Table.AddColumn(ListN, "rnd",
each Number.RandomBetween(0 + [i] - [i], 100)))
in
#"Added Custom"
two-way Lookup
例えば、以下のように2つのテーブルがあります。

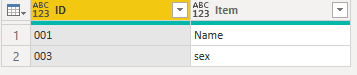
1つめのテーブルを仮にPeopleとして保存しておきます。2つ目のテーブルの項目を1つ目のテーブルから持ってくるには(例えば、ID=001のNameを知りたい)、2つ目のテーブルにカスタム列を追加し、以下のように記述します。
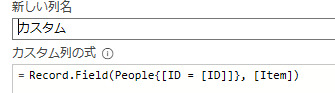
こうして、リレーションを貼るのと同様のことができます。ただマスターテーブルのキーが複数ある場合エラーになってしまいますので、予めマスターのIDをuniqueにする必要があります。同様のことはクエリのマージでもっと簡単に実現可能です。
これを利用して、データのある特定の値に対して、HTMLカラーコードを関連づけ、レポートの条件付き書式で、値によって背景色等を変えることができます。利用しなくてもできますが。
リンク集
最後に、参考にしたリンクなど。
Microsoft公式M数式言語リファレンス
Power Query M Primer Introduction
M or DAX
Basics of M