IT芸人 Advent Calendar 2019 25日目の記事です。
前置き
皆様おはようございます。DE-TEIUです。
今回はIT芸人の記事ということで、ちょっとしたWebアプリを開発しました。
こいつどの記事でも結局やってる事同じとか言うな
成果物
「無限の猿定理」という言葉をご存知でしょうか。
これは、「文字列をランダムに並べ続けると、どんな文字列でもいつかは見つかるはずである」という定理の事です。
猿が適当にキーボードをガチャガチャやっていればいつかは文学作品を書き上げる、というような表現が名前の由来になっているようです。
とはいえ、時間は有限なので、文学作品を書き上げたいからといって本当に完成するまで適当にキーボードを叩くわけにもいきません。
と、いうわけで、誰でも手っ取り早く文学作品を書き上げられるWebアプリを開発しました。
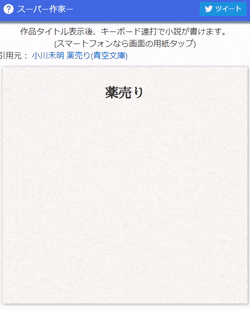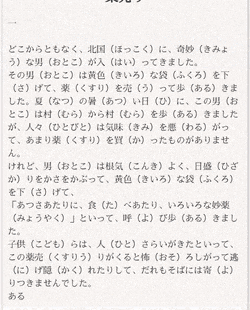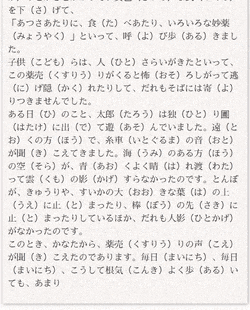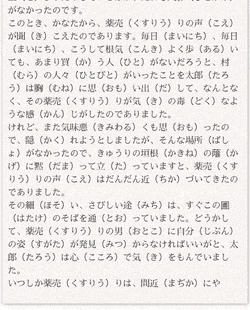
文学史に残る名著が
書けたと思います。
これを使えば自分でキーボードを叩くか、とかげやねこがキーボードの上を歩くだけでも作品が出来上がります。
書いている最中はきっと無我夢中で書いていて内容が頭に入ってこないと思われますので、書き上げてからじっくり読みましょう。
解説
概要
このアプリは、静的サイトを公開するWebサーバーと、青空文庫の著作権切れの作品をランダムに取得するためのAPIサーバーの2つで構成されています。
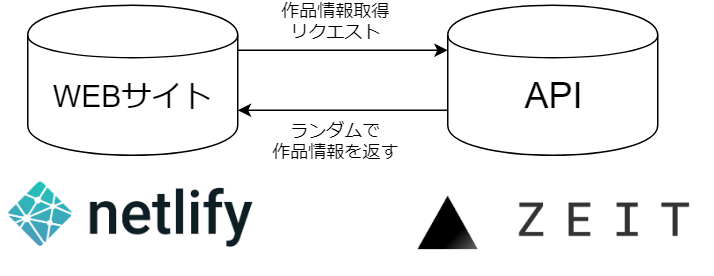
- 静的サイトをnetlifyで公開
- 文学作品情報を取得するためのAPIをNode.jsで実装し、ZEIT Nowで公開
青空文庫について
青空文庫とは、著作権切れ(あるいは公開が許可されている)文学作品が読めるWebサイトです。
今回は、公開中 作家リスト 全てから作品一覧のCSVファイルをダウンロードし、そこから著作権切れの作品の公開URLを抽出し、APIに組み込みました。
解説
以下、実装の解説等です。
青空文庫の作品詳細ページから作品情報を取得
青空文庫の作品の詳細ページ(例えばこちらなど)から、htmlをダウンロードし、そこから作品名、作者名、本文、訳者を抽出します。
この詳細ページは、文字コードがShift-JISになっているため、ダウンロード時にUTF-8にエンコードします。
//文字コード変換にはIconvを使用
import { Iconv } from 'iconv';
const sjis2utf8 = new Iconv('SHIFT_JIS', 'UTF-8//TRANSLIT//IGNORE');
//htmlファイルダウンロードはaxiosで行う
const axios = require("axios");
//ダウンロードしたHTMLをDOMとして加工するため、JSDOMを使用
const jsdom = require("jsdom");
const { JSDOM } = jsdom;
app.get('/getdata', (req, res) => {
const url = "作品URL";
axios.get(url, {
responseType: 'arraybuffer',
//axios実行時にtransformResponseを仕込んでおくと、レスポンスデータを任意の処理で加工して取得できる
transformResponse: [(data) => {
//レスポンスデータの文字コードをShift-JISからUTF-8に変換
return sjis2utf8.convert(data).toString();
}],
}).then(apires => {
const text = apires.data;
const dom = new JSDOM(text);
const document = dom.window.document;
//図書目録の表示を削除
const bibliographicalInformation = document.querySelector(".bibliographical_information");
bibliographicalInformation.parentNode.removeChild(bibliographicalInformation);
//本文を抽出する
//全角文字を除外
//先頭の改行コードを除外
const mainText = format(getTextContent(document, ".main_text"));
//タイトルを抽出
const title = getTextContent(document, ".title");
//作者を抽出
const author = getTextContent(document, ".author");
//訳者を抽出
const translator = getTextContent(document, ".translator");
const result = {
url,
title,
author,
translator,
mainText
};
res.status(200);
res.send(result);
}).catch(err => {
//色々エラー時の処理
res.status(500);
...
...
res.send({});
});
});
/**
* DOM要素を検索し、その中の文字列を抽出
* @param {*} document DOM
* @param {*} condition 検索条件
*/
const getTextContent = (document, condition) => {
const result = document.querySelector(condition);
if (!result) {
return "";
}
return result.textContent;
};
/**
* 文書のフォーマット(空白のトリミング)
* @param {*} text テキスト
*/
const format = (text) => {
if (!text) {
return;
}
const result = text.replace(/ /g, '');
return result.trim();
}
Svelteでフロントエンド実装
今回、フロントエンドのロジックの実装にはSvelteを採用しました。(理由はただ単に使ってみたかっただけです)
Svelteとは、シンプルなJavascriptコンパイラです(フレームワークではありません)。使い方としては、
コンポーネント(~~~.svelte)の中にhtml,css,javascriptを実装し、コンパイルするだけです。このあたりはVueなどの昨今のJSフレームワークに似ています。
しかしながら、Svelteでコンパイルを実行すると、結果はただのhtml,css,javascriptファイルとして出力されます。Svelte固有のロジックなどはほぼ残らないようです。
所感ですが、Vueを更に簡略化したような書き方ができるので、Vueユーザーであればわりとすんなり馴染めるのではないでしょうか。
参考:ReactとVueを改善したSvelteというライブラリーについて
Svelte導入方法
公式ページからの引用です。
$ npx degit sveltejs/template my-svelte-project
$ cd my-svelte-project
$ npm install
$ npm run dev
これだけで、プロジェクトの作成とデバッグ実行までが可能です。
その他、実装方法は公式サイトのTutorialとかExampleを参照してください。
(かなりちゃんとまとまっているので、この記事では細かい文法は省略します。)
まとめ
Svelteは、書き方がシンプルなので今回のような小規模なWebアプリの開発に向いてそうですね。