目的
分析コンペの効率化のための、可視化ツールのいろいろまとめ。
少しずつ、増やしていく!
目次
1.相関マップ
2.混同行列(Confusion Matrix)
3.LightGBMの特徴量重要度
1.相関マップ
pandasデータフレームの各列の相関をヒートマップ表示。
各特徴量の相関、モデルのアンサンブル用の予測結果の相関に使用する。
参考
-
コード
fig ,ax = plt.subplots(1,1,figsize=(12,12))
sns.heatmap(df.corr(), annot=True, fmt='.7f', ax=ax)
df.corr()
2.混同行列(Confusion Matrix)
参考
-
コード
import numpy as np
import pandas as pd
from scipy import signal
from sklearn.metrics import confusion_matrix, f1_score, plot_confusion_matrix
# Thanks to https://www.kaggle.com/marcovasquez/basic-nlp-with-tensorflow-and-wordcloud
def plot_cm(y_true, y_pred, title="", figsize=(14,14):
y_pred = y_pred.astype(int)
cm = confusion_matrix(y_true, y_pred, labels=np.unique(y_true))
cm_sum = np.sum(cm, axis=1, keepdims=True)
cm_perc = cm / cm_sum.astype(float) * 100
annot = np.empty_like(cm).astype(str)
nrows, ncols = cm.shape
for i in range(nrows):
for j in range(ncols):
c = cm[i, j]
p = cm_perc[i, j]
if i == j:
s = cm_sum[i]
annot[i, j] = '%.1f%%\n%d/%d' % (p, c, s)
elif c == 0:
annot[i, j] = ''
else:
annot[i, j] = '%.1f%%\n%d' % (p, c)
cm = pd.DataFrame(cm, index=np.unique(y_true), columns=np.unique(y_true))
cm.index.name = 'Actual'
cm.columns.name = 'Predicted'
fig, ax = plt.subplots(figsize=figsize)
plt.title(title)
sns.heatmap(cm, cmap='viridis', annot=annot, fmt='', ax=ax)
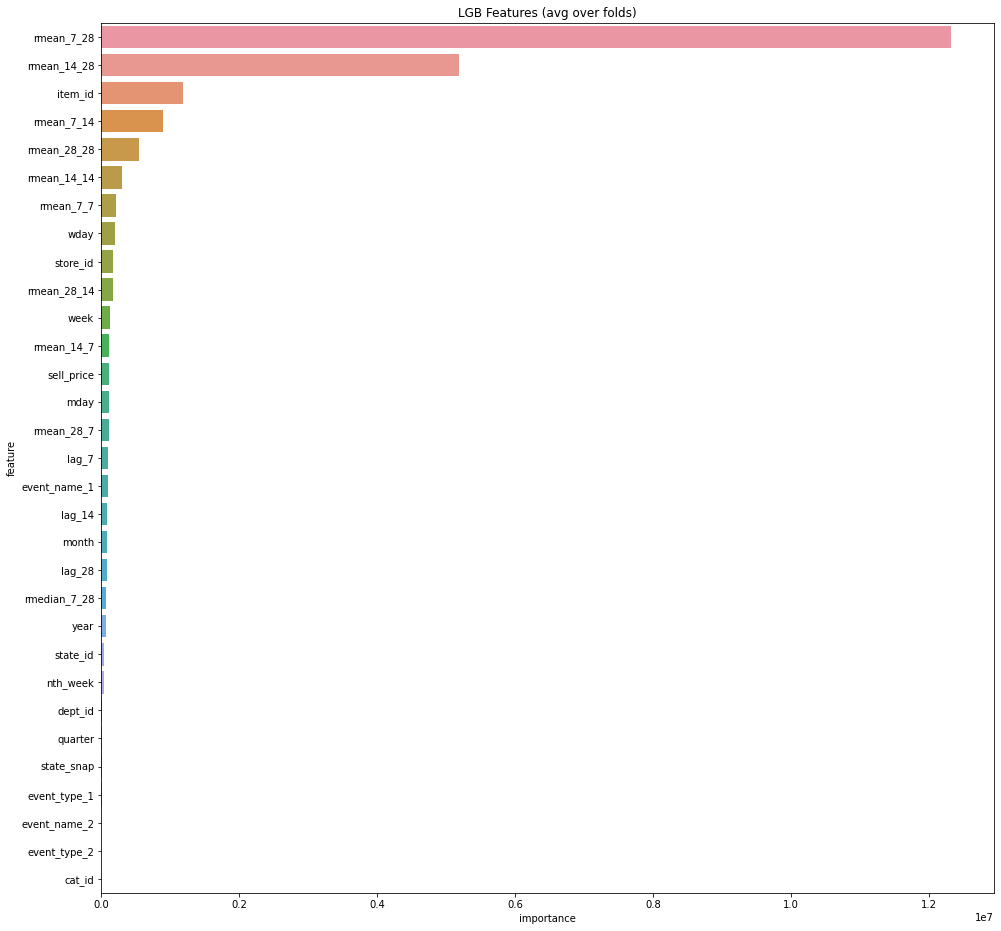
3.LightGBMの特徴量重要度
LightGBMの学習結果の特徴量重要度の可視化
入力はLightgbmのリスト
コード
def display_feature_importance(models):
fi = pd.DataFrame(columns=['importance','feature'])
for i, m in enumerate(models):
df_t = pd.DataFrame(columns=['importance','feature'])
df_t['importance'] = m.feature_importance(importance_type='gain')
df_t['feature'] = m.feature_name()
fi = pd.concat([fi, df_t], axis=0)
fi = fi.groupby('feature').sum()
best_features = fi.sort_values(by='importance', ascending=False).reset_index()
plt.figure(figsize=(16, 16));
sns.barplot(x="importance", y="feature", data=best_features);
plt.title('LGB Features (avg over folds)');
print('worst:\n',best_features['feature'][-20:].values)
Sampleコード(疑似)
### 学習
m_lgb = lgb.train(params, train_data, valid_sets = [valid_data],
verbose_eval=100,early_stopping_rounds=200)
### 特徴量の重要度の表示
display_feature_importance([m_lgb])
表示例
表示は、kaggleの「M5 Forecasting - Accuracy」コンペの特徴量の重要度。
ちなみに結果は、395/5,558の銅メダル