業務で機械学習のETL処理を行う必要があったので,2019年12月に発表されたNetflix内製ツールのMetaflowを試しに使ってみました.色々と知見が得られたので,詳細な概要記事を書こうと思います.
はじめに
MetaflowはNetflixがデータサイエンティストの生産性を高めるために作成した内製のワークフローツールです.
バージョン管理やデータウェアハウスなどのインフラについてはあまり考えずにモデルやビジネスロジックの構築に集中できるようにすることを目的に作られたそうです.検証段階からMetaflowで開発することで商用への移行が楽になります.
これまでNetflixでは,約2年前からこの内製ツールを使用してきたらしいのですが,2019年12月にOSS化されました.米国一の高所得エンジニア達が生産性を高めるために使っていたツールなので気になりますよね.
本記事では,公式ドキュメントに記載されている内容をかいつまんで詳細に解説しました.
本記事を読むだけでざっくりと使えるようになることが目標です.
インストール
pip install metaflow
Metaflowのライブラリ管理機能はcondaが必要なので,conda環境推奨です.
基本的な概念(Flow, Run, Step)
Flow
定義された一連のワークフローをFlowと呼びます.(そのままですね.)
Run
Flowの各実行のことをRunと呼びます.各Runはバージョン管理されており,各Runにおけるメタデータは自動的に保存されます.デバッグや実行結果の確認を行う際は対象のRunを指定してそのメタデータにアクセスします.
Step
Flowを定義する処理のブロックをStepと呼びます.処理全体を意味のあるブロックに分割し,Stepとして記述しましょう.Step内のインスタンス変数はメタデータと共に保存されます.通常,デバッグの際などに確認するのはStep内のデータとなります.
サンプルコードによる解説
例えば,下記のような機械学習パイプラインを作成するとします.
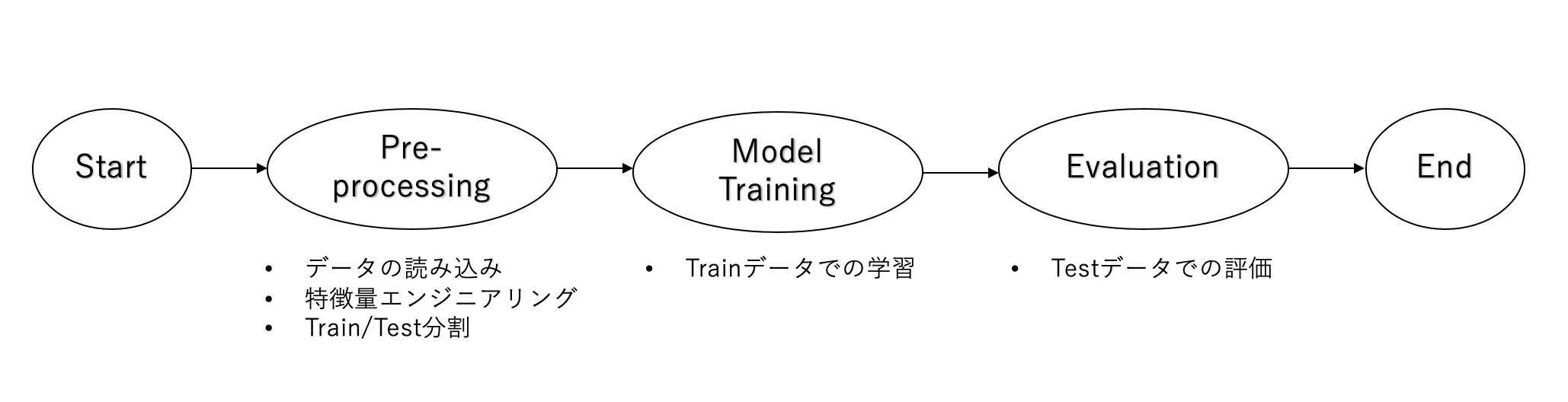
これを実現するコードの大枠は下記のようになります.
from metaflow import FlowSpec, step
class SampleFlow(FlowSpec):
@step
def start(self):
self.next(self.preprocessing)
@step
def preprocessing(self):
# 処理内容を記述
self.next(self.model_training)
@step
def model_training(self):
# 処理内容を記述
self.next(self.evaluation)
@step
def evaluation(self):
# 処理内容を記述
self.next(self.end)
@step
def end(self):
pass
if __name__ == "__main__":
SampleFlow()
- 記述したいワークフローをFlowSpecを継承したクラス内に記述していきます.
- それぞれの処理は
@step以下に記述します. - FlowにはstartとendのStepが必要です.
- 各Stepの終わりにself.next()で次の処理を指定します.
簡単ですね.それでは,実際に処理内容を記述したものを以下に記します.
有名なTitanicデータを用いてモデルを作成し,TestデータのAccuracyとモデルのパラメータを表示します.
from metaflow import FlowSpec, step
import numpy as np
import pandas as pd
import xgboost as xgb
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
class TitanicClassification(FlowSpec):
@step
def start(self):
self.next(self.preprocessing)
@step
def preprocessing(self):
# Titanicデータの読み込み
data = pd.read_csv('data/train.csv')
# LabelEncodingや欠損値の補完などの前処理
data['Sex'].replace(['male','female'], [0, 1], inplace=True)
data['Embarked'].fillna(('S'), inplace=True)
data['Embarked'] = data['Embarked'].map( {'S': 0, 'C': 1, 'Q': 2} ).astype(int)
data['Fare'].fillna(np.mean(data['Fare']), inplace=True)
data['Age'].fillna(np.mean(data['Age']), inplace=True)
# 必要なさそうなカラムの削除
delete_columns = ['Name', 'PassengerId', 'SibSp', 'Parch', 'Ticket', 'Cabin']
data.drop(delete_columns, axis=1, inplace=True)
# train,test分割
self.X_train, self.X_validation, self.y_train, self.y_validation = \
train_test_split(data.drop('Survived', axis = 1), data['Survived'], train_size=0.8, random_state=0)
self.next(self.model_training)
@step
def model_training(self):
# max_depth, n_estimators, subsampleについてはパラメータで指定した値を設定
self.params = {"objective":"binary:logistic",'learning_rate': 0.1, \
'max_depth': 6, 'n_estimators': 100, "subsample": 0.8}
self.model = xgb.XGBClassifier(**self.params)
self.model.fit(self.X_train, self.y_train)
self.next(self.evaluation)
@step
def evaluation(self):
self.y_pred = self.model.predict(self.X_validation)
self.accuracy = accuracy_score(self.y_validation, self.y_pred)
print('Accuracy : %f' % self.accuracy)
print('Parameter : %s' % self.params)
self.next(self.end)
@step
def end(self):
pass
if __name__ == "__main__":
TitanicClassification()
実行コマンド (Show, Run, Resume)
次に作成したFlowを実行するために実行コマンドについて説明します.
Flowが記述されたファイルを実行する際,ファイル名の後にshow, run, resumeのいずれかを指定して実行します.
python ファイル名 [show|run|resume]
Show
DAG (Stepの推移)を表示します.結構,見づらいですね... DAGはGUIで見たいところですが現在その機能はありません.
$ python titanic_classification.py show
Metaflow 2.0.3 executing TitanicClassification for user:kenji_yabuki
Step start
?
=> preprocessing
Step preprocessing
?
=> model_training
Step model_training
?
=> evaluation
Step evaluation
?
=> end
Step end
?
Run
Flowを最初から順に実行します.
$ python titanic_classification.py run
Metaflow 2.0.3 executing TitanicClassification for user:kenji_yabuki
Validating your flow...
The graph looks good!
Running pylint...
Pylint is happy!
2020-03-12 08:41:10.142 Workflow starting (run-id 1583970070135480):
2020-03-12 08:41:10.151 [1583970070135480/start/1 (pid 55394)] Task is starting.
2020-03-12 08:41:11.821 [1583970070135480/start/1 (pid 55394)] Task finished successfully.
2020-03-12 08:41:11.829 [1583970070135480/preprocessing/2 (pid 55399)] Task is starting.
2020-03-12 08:41:13.704 [1583970070135480/preprocessing/2 (pid 55399)] Task finished successfully.
2020-03-12 08:41:13.710 [1583970070135480/model_training/3 (pid 55404)] Task is starting.
2020-03-12 08:41:15.411 [1583970070135480/model_training/3 (pid 55404)] Task finished successfully.
2020-03-12 08:41:15.422 [1583970070135480/evaluation/4 (pid 55409)] Task is starting.
2020-03-12 08:41:17.473 [1583970070135480/evaluation/4 (pid 55409)] Accuracy : 0.837989
2020-03-12 08:41:17.723 [1583970070135480/evaluation/4 (pid 55409)] Parameter : {'objective': 'binary:logistic', 'learning_rate': 0.1, 'max_depth': 6, 'n_estimators': 100, 'subsample': 0.8}
2020-03-12 08:41:17.726 [1583970070135480/evaluation/4 (pid 55409)] Task finished successfully.
2020-03-12 08:41:17.736 [1583970070135480/end/5 (pid 55414)] Task is starting.
2020-03-12 08:41:19.783 [1583970070135480/end/5 (pid 55414)] Task finished successfully.
2020-03-12 08:41:19.784 Done!
Resume
過去のRunの任意のStepから処理を再開します.このとき,再開するStep以前までの実行結果は過去の実行結果を再利用するため,素早く処理を再開できます.(=再開するStepまでの処理はきちんと実行されていなければなりません)
RunやStepを指定しなければ,直近のRunの処理が失敗したところから再開されます.処理が途中でこけたときのデバッグや途中のStepでコードやパラメータを修正した際などに使用することが多いです.詳細な使い方はこちらをご確認ください.
先ほどの例でn_estimateorsを100 -> 50 に修正し,Model Trainingから再開した結果がこちらです.
$ python titanic_classification.py resume model_training
Metaflow 2.0.3 executing TitanicClassification for user:kenji_yabuki
Validating your flow...
The graph looks good!
Running pylint...
Pylint is happy!
2020-03-12 08:50:08.663 Gathering required information to resume run (this may take a bit of time)...
2020-03-12 08:50:08.672 Workflow starting (run-id 1583970608661883):
2020-03-12 08:50:08.675 [1583970608661883/start/1] Cloning results of a previously run task 1583970070135480/start/1
2020-03-12 08:50:10.587 [1583970608661883/preprocessing/2] Cloning results of a previously run task 1583970070135480/preprocessing/2
2020-03-12 08:50:12.258 [1583970608661883/model_training/3 (pid 55569)] Task is starting.
2020-03-12 08:50:14.027 [1583970608661883/model_training/3 (pid 55569)] Task finished successfully.
2020-03-12 08:50:14.033 [1583970608661883/evaluation/4 (pid 55574)] Task is starting.
2020-03-12 08:50:15.622 [1583970608661883/evaluation/4 (pid 55574)] Accuracy : 0.865922
2020-03-12 08:50:15.842 [1583970608661883/evaluation/4 (pid 55574)] Parameter : {'objective': 'binary:logistic', 'learning_rate': 0.1, 'max_depth': 6, 'n_estimators': 50, 'subsample': 0.8}
2020-03-12 08:50:15.845 [1583970608661883/evaluation/4 (pid 55574)] Task finished successfully.
2020-03-12 08:50:15.855 [1583970608661883/end/5 (pid 55579)] Task is starting.
2020-03-12 08:50:17.582 [1583970608661883/end/5 (pid 55579)] Task finished successfully.
2020-03-12 08:50:17.583 Done!
preprocessingまでは結果がcloneされ,Model Trainingから処理が再開し,Accuracy, Parameterが書き換わっていることが分かります.
3種類の構文 (Linear, Branch, Foreach)
Metaflowの処理では,①Linear ②Branch ③Foreach の3種類の構文が使えます.
①Linear
順番にStepをつなげていくだけの処理をLinearと呼びます.先ほどの例はLinearですね.
②Branch
次のStepを指定する際に,self.next()で複数のStepを指定すると処理が分岐し,並列処理が行われます.分岐を行った際は必ずJoin Stepが必要です.Join Stepでは,inputs引数を与えることで,分岐した各Stepの変数を受け取ります.(また,inputs引数の有無でJoin Stepかどうか判定されます)
下図は先ほどの例でモデルを学習する際に,XGBoostとRandomForestをそれぞれ並列でモデルを作成し,一番精度の良いモデルの結果を表示する例です.
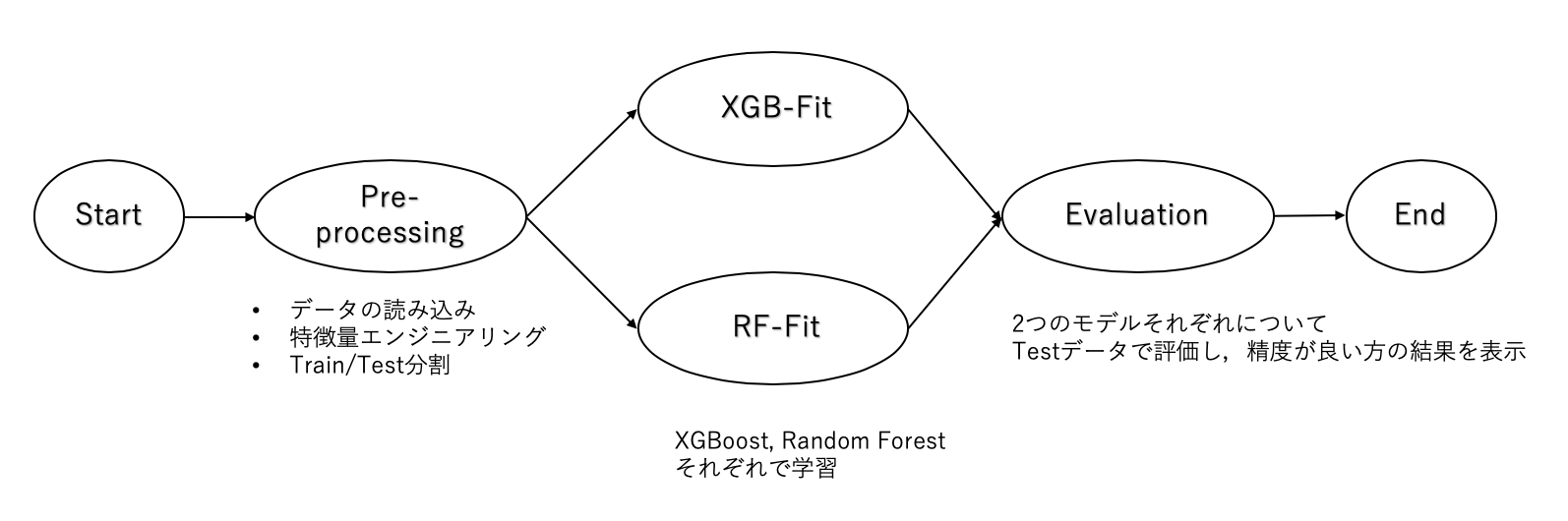
from metaflow import FlowSpec, step
import os
import numpy as np
import pandas as pd
import xgboost as xgb
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.ensemble import RandomForestClassifier
class ModelSelection(FlowSpec):
@step
def start(self):
self.next(self.feature_engineering)
@step
def feature_engineering(self):
# 省略
self.next(self.xgb_fit, self.rf_fit)
@step
def xgb_fit(self):
self.model = xgb.XGBClassifier(random_state=0)
self.model.fit(self.X_train, self.y_train)
self.y_pred = self.model.predict(self.X_validation)
self.score = accuracy_score(self.y_validation, self.y_pred)
self.next(self.evaluate_model)
@step
def rf_fit(self):
self.model = RandomForestClassifier(random_state=0)
self.model.fit(self.X_train, self.y_train)
self.y_pred = self.model.predict(self.X_validation)
self.score = accuracy_score(self.y_validation, self.y_pred)
self.next(self.evaluation)
@step
def evaluation(self, inputs):
self.best = max((i.score, i.model) for i in inputs)
print('Accuracy : %f' % self.best[0])
print('Best Model : %s' % self.best[1])
self.next(self.end)
@step
def end(self):
pass
if __name__ == "__main__":
ModelSelection()
$ python model_selection.py run
Metaflow 2.0.3 executing ModelSelection for user:kenji_yabuki
Validating your flow...
The graph looks good!
Running pylint...
Pylint is happy!
2020-03-12 09:44:29.393 Workflow starting (run-id 1583973869387632):
~~省略~~
2020-03-12 09:44:35.999 [1583973869387632/evaluation/5 (pid 55734)] Task is starting.
2020-03-12 09:44:37.865 [1583973869387632/evaluation/5 (pid 55734)] Accuracy : 0.854749
2020-03-12 09:44:38.020 [1583973869387632/evaluation/5 (pid 55734)] Best Model : RandomForestClassifier(bootstrap=True, ccp_alpha=0.0, class_weight=None,
2020-03-12 09:44:38.020 [1583973869387632/evaluation/5 (pid 55734)] criterion='gini', max_depth=None, max_features='auto',
2020-03-12 09:44:38.020 [1583973869387632/evaluation/5 (pid 55734)] max_leaf_nodes=None, max_samples=None,
2020-03-12 09:44:38.020 [1583973869387632/evaluation/5 (pid 55734)] min_impurity_decrease=0.0, min_impurity_split=None,
2020-03-12 09:44:38.020 [1583973869387632/evaluation/5 (pid 55734)] min_samples_leaf=1, min_samples_split=2,
2020-03-12 09:44:38.020 [1583973869387632/evaluation/5 (pid 55734)] min_weight_fraction_leaf=0.0, n_estimators=100,
2020-03-12 09:44:38.020 [1583973869387632/evaluation/5 (pid 55734)] n_jobs=None, oob_score=False, random_state=0, verbose=0,
2020-03-12 09:44:38.020 [1583973869387632/evaluation/5 (pid 55734)] warm_start=False)
2020-03-12 09:44:38.023 [1583973869387632/evaluation/5 (pid 55734)] Task finished successfully.
2020-03-12 09:44:38.034 [1583973869387632/end/6 (pid 55739)] Task is starting.
2020-03-12 09:44:40.339 [1583973869387632/end/6 (pid 55739)] Task finished successfully.
2020-03-12 09:44:40.339 Done!
③Foreach
Branchでは,各分岐を手動で定義しましたが,分岐を入力によって動的に変えたい場合はForeachを使います.
使い方は,分岐先のStepを指定する際にforeach=分岐対象のパラメータのList (or Tupple)を与えるだけです.Join StepについてはBranchと同様です.
先ほどのtitanic_classification.py でmax_depth, n_estimators, subsampleのパラメータでGrid Searchを行い,一番精度の高いパラメータの結果を表示する例を示します.
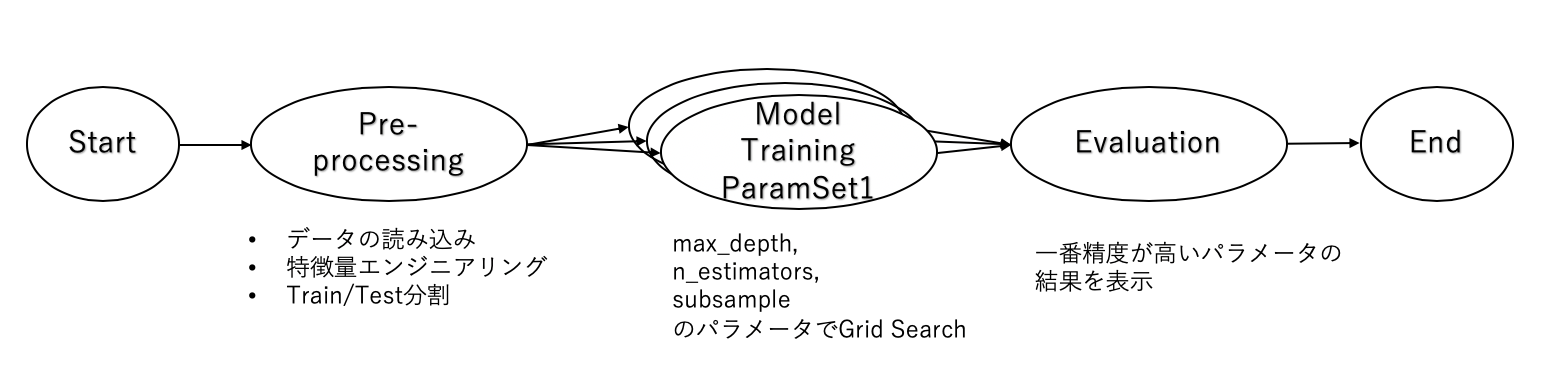
from metaflow import FlowSpec, step
import os
import itertools
import numpy as np
import pandas as pd
import xgboost as xgb
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
class GridSearchXGB(FlowSpec):
@step
def start(self):
self.next(self.feature_engineering)
@step
def feature_engineering(self):
# 省略
self.next(self.param_setting)
@step
def param_setting(self):
max_depth_params = [2,4,6]
n_est_params = [50,100,150]
subsample_params = [0.4,0.6,0.8]
self.target_params = list(itertools.product(max_depth_params, n_est_params, subsample_params))
self.next(self.train_model, foreach='target_params')
@step
def train_model(self):
self.params = {"objective":"binary:logistic",'learning_rate': 0.1, \
'max_depth': self.input[0], 'n_estimators': self.input[1], "subsample": self.input[2]}
self.model = xgb.XGBClassifier(**self.params)
self.model.fit(self.X_train, self.y_train)
self.y_pred = self.model.predict(self.X_validation)
self.score = accuracy_score(self.y_validation, self.y_pred)
self.next(self.evaluation)
@step
def evaluation(self, inputs):
best_index = np.argmax([i.score for i in inputs])
self.best_accuracy = inputs[best_index].score
self.best_params = inputs[best_index].params
print('Accuracy : %f' % self.best_accuracy)
print('max_depth : %s' % self.best_params['max_depth'])
print('n_estimators : %s' % self.best_params['n_estimators'])
print('subsample : %s' % self.best_params['subsample'])
self.next(self.end)
@step
def end(self):
pass
if __name__ == "__main__":
GridSearchXGB()
$ python grid_search_xgb.py run
Metaflow 2.0.3 executing GridSearchXGB for user:kenji_yabuki
Validating your flow...
The graph looks good!
Running pylint...
Pylint is happy!
2020-03-12 09:46:19.875 Workflow starting (run-id 1583973979869090):
2020-03-12 09:46:19.880 [1583973979869090/start/1 (pid 55789)] Task is starting.
2020-03-12 09:46:21.776 [1583973979869090/start/1 (pid 55789)] Task finished successfully.
2020-03-12 09:46:21.785 [1583973979869090/feature_engineering/2 (pid 55794)] Task is starting.
2020-03-12 09:46:23.972 [1583973979869090/feature_engineering/2 (pid 55794)] Task finished successfully.
2020-03-12 09:46:23.987 [1583973979869090/param_setting/3 (pid 55799)] Task is starting.
2020-03-12 09:46:25.942 [1583973979869090/param_setting/3 (pid 55799)] Foreach yields 27 child steps.
2020-03-12 09:46:25.942 [1583973979869090/param_setting/3 (pid 55799)] Task finished successfully.
2020-03-12 09:46:25.954 [1583973979869090/train_model/4 (pid 55804)] Task is starting.
2020-03-12 09:46:25.970 [1583973979869090/train_model/5 (pid 55805)] Task is starting.
~~省略~~
2020-03-12 09:46:48.751 [1583973979869090/evaluation/31 (pid 55939)] Task is starting.
2020-03-12 09:46:50.788 [1583973979869090/evaluation/31 (pid 55939)] Accuracy : 0.871508
2020-03-12 09:46:50.932 [1583973979869090/evaluation/31 (pid 55939)] max_depth : 4
2020-03-12 09:46:50.932 [1583973979869090/evaluation/31 (pid 55939)] n_estimators : 100
2020-03-12 09:46:50.932 [1583973979869090/evaluation/31 (pid 55939)] subsample : 0.6
2020-03-12 09:46:50.935 [1583973979869090/evaluation/31 (pid 55939)] Task finished successfully.
2020-03-12 09:46:50.943 [1583973979869090/end/32 (pid 55944)] Task is starting.
2020-03-12 09:46:52.685 [1583973979869090/end/32 (pid 55944)] Task finished successfully.
2020-03-12 09:46:52.686 Done!
3種類のパラメータで3つずつの値を試しているので,27個の分岐が発生していることが分かります.
Metaflowの特徴的な機能
Metaflowの特徴的な機能をいくつかPick upして説明します.
バージョン管理とメタデータの自動保存
Flowが実行される度に各Runはバージョン管理されます.保存されるデータはRunそのものについてのメタデータ(実行時刻や実行環境のバージョンなど)や各Stepのメタデータ, インスタンス変数などがあります.
※ インスタンス変数 (e.g. self.x)は保存されますが,通常の変数(e.g. x)は保存されません.
あるRunのデータを確認したい場合はIPythonなどを利用して簡単に確認できます.
例えば,先ほどのBranchの例で2つのモデルの精度を比較しRandom Forestの方が良い結果となりましたが,確認のためXGBoostのAccuracyを以下のようにして調べます.
$ ipython
Python 3.6.9 |Anaconda, Inc.| (default, Jul 30 2019, 13:42:17)
Type 'copyright', 'credits' or 'license' for more information
IPython 7.10.2 -- An enhanced Interactive Python. Type '?' for help.
In [1]: from metaflow import Flow, Run, Step
In [2]: run = Flow('ModelSelection').latest_run # ModelSelection Flowの直近のRunを取得
In [3]: list(run) # RunのStep一覧を確認
Out[3]:
[Step('ModelSelection/1583973869387632/end'),
Step('ModelSelection/1583973869387632/evaluation'),
Step('ModelSelection/1583973869387632/xgb_fit'),
Step('ModelSelection/1583973869387632/rf_fit'),
Step('ModelSelection/1583973869387632/feature_engineering'),
Step('ModelSelection/1583973869387632/start')]
In [4]: Step('ModelSelection/1583973869387632/xgb_fit').task.data # xgb_fitで参照できるデータ一覧
Out[4]: <MetaflowData: model, name, y_train, score, y_validation, X_train, y_pred, X_validation>
In [5]: Step('ModelSelection/1583973869387632/xgb_fit').task.data.score # XGBoostモデルのAccuracy
Out[5]: 0.8435754189944135
耐障害性のための機能
ワークフローツールとして,安定して処理を継続するために,インフラの障害や予期せぬデータが来た際の対策などがあると便利です.Metaflowでは,一過性の障害をRetryで対処したり,予期せぬ処理のループを継続させないためにTimeoutを設ける,などをデコレータを用いて簡単に実現できます.これらのデコレータの使い方は後に紹介します.
詳細についてはこちらをご参照ください.
Cloud(AWS)との連携
MetaflowはAWSと密に連携して開発されました.現在はAWSとの連携機能として,S3へのデータアクセス(メタデータの保存など)やAWS Batchを使用した処理があります.大規模な入力データを保存するとなるとS3との連携は嬉しいですね.また,AWS Batchを使用して,重たい処理だけAWS Batchで処理し,その他の処理はローカルで行うといったことも可能です.各Stepでリソースの制御も簡単にできるのでCloudとの連携がしやすいです.
また,GithubのIssuesやPull requestsを見てると,GCPとの連携機能の開発も進められていそうです.
各種デコレータ
Metaflowには,ワークフローに使える便利なデコレータがいくつか用意されています.
使用する場合は各 各Stepの@Stepの前にこれから説明するデコレータを付け足してください.
@resources
resourcesデコレータは各StepでのメモリやCPU, GPUなどのリソースの割り当てを行うことができます.
例えば,memory:6GB, CPU:1 を割り当てる場合,下記のようになります.
@resources(memory=60000, cpu=1)
@batch
AWS Batchで処理したいStepにはbatchデコレータを使います.
@batch(memory=60000, cpu=1)
@retry
一時的な障害などで処理が中断したときに,中断したStepの最初から再開するようにする場合はretryデコレータを用います.
デフォルトでは,2分間隔で3回までretryを行います.
retry回数と間隔を変更したい場合は下記のように引数を渡します.(retry回数と間隔の最大値はそれぞれ4回と20分です)
@retry(times=4, minutes_between_retries=20)
基本的にクラウド上でMetaflowを使う場合は全てのStepでリトライを使用することが望ましいですが,全てのStepに@retryを追加するのは手間です.実行時に--with retryオプションを与えることで全てのStepにリトライ機能が追加されます.
@catch
デフォルトでは,MetaflowはどこかのStepでエラーが起こると全体のフローが中止されます.しかし,catchデコレータを使うことで,そのStepで処理が失敗したとしても,後続のStepへと処理が続きます.
もちろん,エラーが起きたまま処理が進むので,後続のStepで何らかのエラーハンドリングを記述する必要があります.
exceptionをmetadataとして保存するには,下記のようにvar引数を与える必要があります.
@catch(var=hoge)
また,retryと併用することで,上限までリトライしても成功しなかったときにcatchを行うことできます.
@timeout
予期せぬループにはまったり,処理に時間がかかり過ぎる際に処理を中断するにはtimeoutを用います.
下記は5分30秒経過したらタイムアウトを行う例です.引数には,seconds, minutes, hoursを指定できます.
@timeout(minutes=5, seconds=30)
また,catchと併用することで,timeout後の処理を継続させることができます.
@conda
異なる環境での実行や再現性を担保する上で,ライブラリ管理は重要です.Metaflowでは,@condaデコレータを使うことで,各Step毎に使用するライブラリとバージョンを指定できます.なので,Step毎に同じライブラリでも違うバージョンを指定することが可能です.
例
@conda(libraries={'numpy':'1.16.3'})
@step
def foo(self):
...
@conda(libraries={'numpy':'1.15.4'})
@step
def bar(self):
...
@condaデコレータを使用する場合は,実行時に--environment=condaオプションが必要です.
また,@conda_baseデコレータを使用することで,Flow全体で使用するベースのライブラリとPythonを指定できます.
@conda_base(libraries={'numpy':'1.15.4'}, python='3.6.5')
class Hoge(FlowSpec):
...
所感
使ってみての感想ですが,とにかく手軽に処理を記述でき,様々なデコレータを駆使して簡単にインフラ周りの課題に対処できるのが良いと感じました.GUIでの操作ができない,DAG schedulerの機能がないなど他のリッチなワークフローツールに比べると機能が少ない点もありますが,シンプルで使いやすいので個人的には良いんじゃないかと思います.また,AWSとの連携が強力なので,AWS環境で運用している会社であれば開発段階からMetaflowを用いて進めることで本番移行が容易にできそうです.
逆に,それ以外の環境であったりInternet Reachability がない場合は,スケーリングやcondaでのライブラリ管理の恩恵を受けづらい(あるいは,受けれない)のであまりメリットがないかもしれません.
また,条件分岐付きのDAGを定義できるとさらに良いなと思いました.例えば,ある条件のときに後方のStepまでSkipするということが今のところできません.(他のツールは出来るんですかね?)ここが改善されるとさらに使い勝手が良くなると感じました.
終わりに
Metaflowについて詳細な概要を書きました.
OSS版のMetaflowでは,R言語のサポートや大規模データのインメモリ処理など,公開されていない機能もあるそうですが,要望が多ければこれらの機能も公開するみたいです.皆さんも使ってみてどんどん要望を上げていきましょう!