本記事はNTTドコモSI部アドベントカレンダー20日目の記事です。
はじめに
こんにちは。NTTドコモ2年目の矢吹です。
業務ではストリーミング処理基盤の開発やネットワークの分析などに取り組んでいます。
先日、AWSが毎年ラスベガスで開催しているre:Invent 2019というイベントに参加してきました。
そこで参加した**「Experience the real-world ML lifecycle with Amazon SageMaker」**
というMLシステムの構築についてのワークショップ(メインはSageMakerを利用したモデル作成, デプロイ)の内容について書きます。
ワークショップの内容
セッション概要
In this workshop, you get hands-on experience taking custom machine learning (ML) solutions from prototype to production.
You use Amazon SageMaker to build, train, and deploy ML models for a real-world Amazon Robotics use case.
You learn about the human-robot interactions that happen hundreds of times every second to power the Amazon fulfillment network.
You craft your own ML models based on millions of anonymized data points, and you deploy your models to serve warehouses across the globe with regional endpoints that scale automatically.
ざっくり言うと、
Amazon Robotics(ロボットを用いてほとんどの作業が自動化されている物流拠点) での実例を基に
AWSサービスを組み合わせたMLシステムの構築が体験できるような内容でした。
(メインはSageMakerを利用したモデルの構築とデプロイ)
ワークショップの資料はここからダウンロードできます。
スピーカー
- Mike Calder - Software Engineer , AWS
- Rick Nayar - Senior Solutions Architect , Amazon Web Services
対象とする課題
Amazon Robotics の物流センターでは、ル○バのようなロボットが商品が格納された棚を載せて縦横無尽に走り回っています。
全ての作業がル○バによって自動化されているかと言うとそうではなく、ル○バと人間のインタラクションが必要な作業も存在します。
今回のモデリングの対象は、
ロボットが運んできた棚の中から特定の商品の数量を調整するという作業の中で、
「商品のサイズや配置されている場所などの情報から、作業完了までにどのくらい時間がかかるのかを推定する」
というものです。
全体のワークフローとアーキテクチャ
今回の課題のワークフローは以下のような内容です。

モデル作成に有用そうな特徴量を考える (Feature Selection)
→ その特徴量(とターゲット変数)を収集する仕組みを作る (Sample Collection)
→ モデルの学習 (Model Training)
→ ライブ推論 (Live Inference)
→ モデルの自動アップデート (Automated Retraining)
という流れですね。
ワークショップでは、 Sample Correction (Lab 1) と Model Training (Lab 2), Live Inference (Lab 3)を実際に手を動かして体験しました。
構築するシステムのアーキテクチャは以下のようになります。
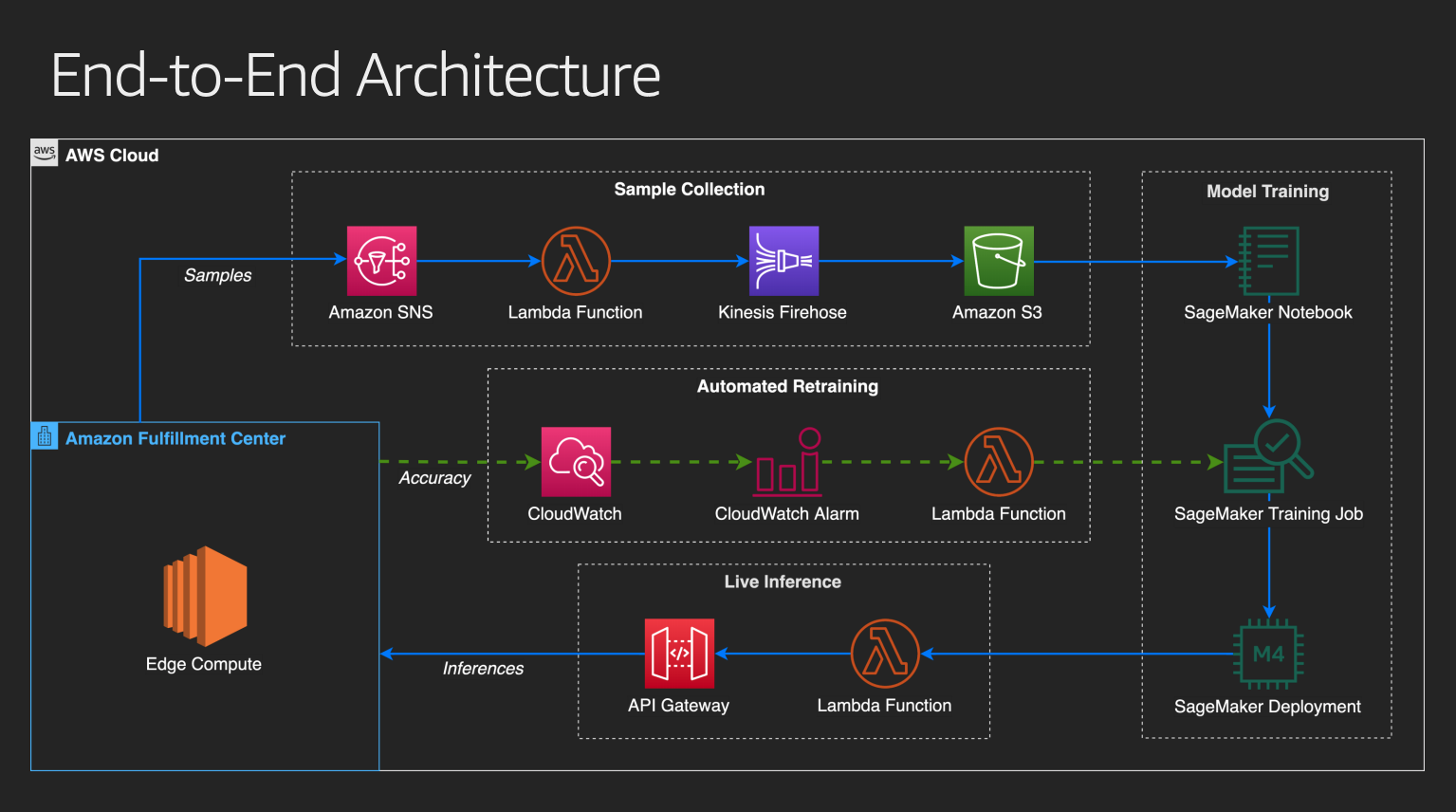
Sample Collection (Lab 1)
特徴量とターゲット変数(ここでは商品除去までの時間)を収集するシステムを構築します。Edge Compute からデータを送信するところはAWS側で用意されていたので、送信されたデータをSNSやFirehorseを使用してS3に保存するところまで行います。
Model Training (Lab 2)
SageMakerを利用してモデルの作成とデプロイを行います。S3に格納したデータを読み込み、組み込み関数 (Linear Regression, k-NN, XGBoostなど) でモデルを構築します。モデルを決定したら推論用のインスタンスにデプロイします。
Live Inference (Lab 3)
SageMakerエンドポイントにリクエストをルーティングするためのライブ推論APIを作成します。まず、SageMakerエンドポイントを呼び出すためのLamdbaを実装し、API Gatewayを使用してデータを受信した後Lamdbaにルーティングするような外部APIを設定します。
Automated Retraining
Edge Computeでカスタムメトリクス(予測値と実測値との差)を計算し、CloudWatchで監視します。閾値が一定以上を超えたらAlarmを飛ばしてLamdbaを起動し、SageMakerに対してモデルの再学習のジョブを発行します。今回のワークショップでは、扱いませんでした。
急にKaggleみたいなのが始まった
Model Training (Lab 2) が始まったときに講師の方からアナウンスがありました。
「今からみなさんにはそれぞれモデルを構築してもらってその精度を競ってもらいます。1位の方には景品としてAmazon Roboticsのリュックをプレゼントします。」
どうやら、各自でモデルを作成し、Edge Computeから送られてくるデータをリアルタイムで推論し、その精度を競うという内容のようです。30分間推論を続けて終了時に一番誤差が小さかった人が景品を貰えます。(30分間の平均ではなく、終了時の瞬間に1位だった人が対象)
これまでワークショップにはいくつか参加しましたが、コンペ形式のものはなかったので、ワクワクします。(そして、リュックも普通に欲しい)
とは言っても、時間配分の都合上15分くらいしか使えなかったので、XGBoostを使用してサクッとモデルを作成することにしました。
XGBoostは特徴量のスケーリングや欠損値補完などの前処理を行わなくても良い精度が出るのでおすすめです。また、SageMakerの組み込みアルゴリズムにも入っています。アルゴリズムの詳細は以下の記事がわかりやすいです。
Kaggle Masterが勾配ブースティングを解説する - Qiita
XGBoost論文を丁寧に解説する(1) - Qiita
パラメータ職人としての経験を頼りにパラメータを設定してモデルを作成し、デプロイします。デプロイした後すぐにリーダボードに自分の名前が表示されます。

**いきなり1位になってしまいました。しかも断トツです。**しかし、ライブ推論での勝負のため刻一刻と数値は変化します。データを推論し続けて30分後の時点で1位のユーザーが景品をもらえるということなので、油断はできません。

モデル作成が終わったユーザーが増えてきて何度か1位を明け渡すこともありましが、比較的安定して1位をキープしています。
あくまで予想ですが、単発的に順位が上がる人は訓練データに対して過適合していて、訓練データと似たパターンのデータが来たときだけ、かなり良いスコアが出たのだと思います。それに対して、自分は学習時にsubsampleパラメータも使用していたため、過適合を防げたのではないかと思われます。(テストデータに対してはsubsampleを使用しない方が良い結果が出ましたが、そちらは選択しませんでした)
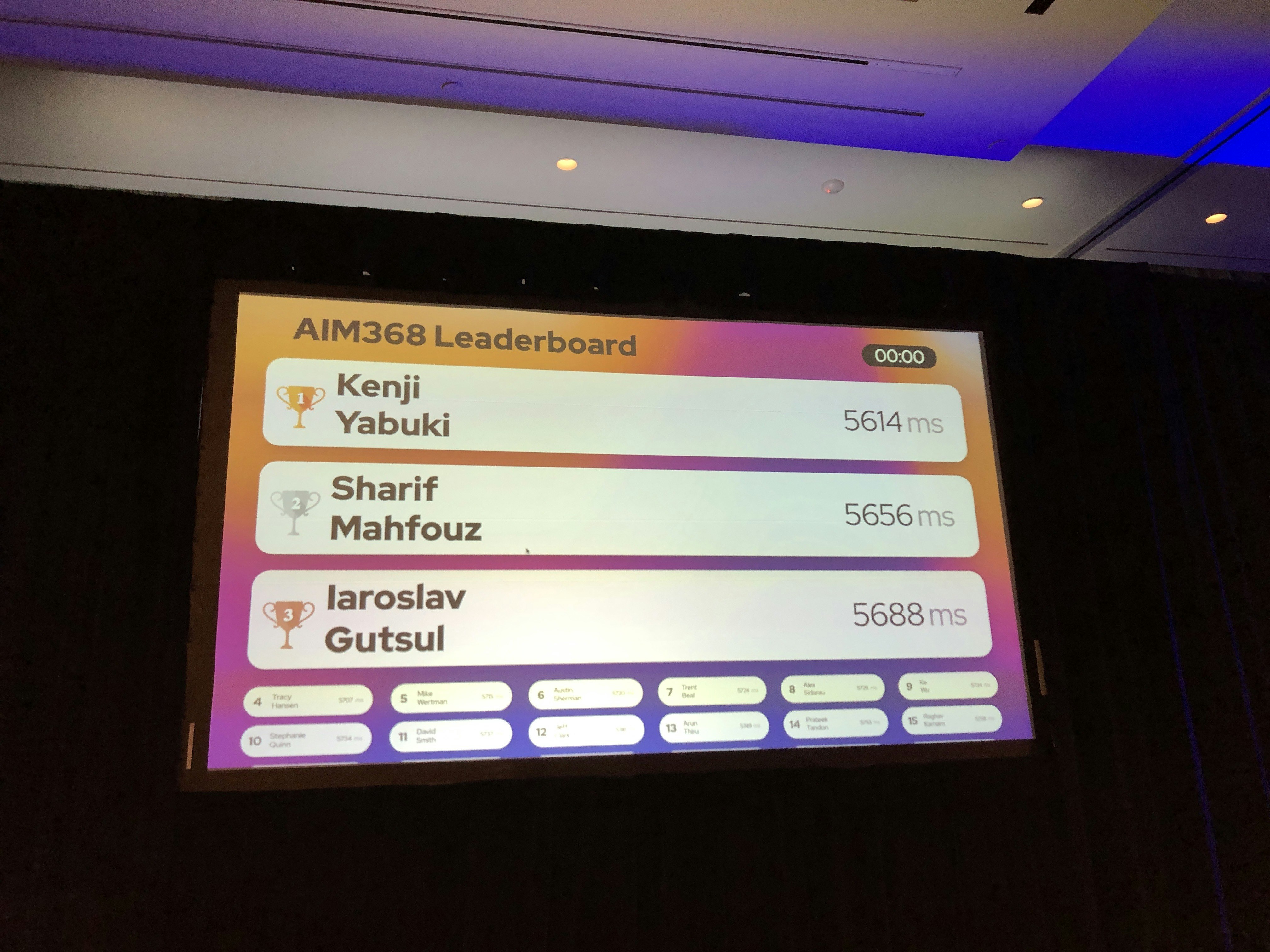
ラスト10秒のとこで2位に後退して焦りましたが、終了直前に抜き返し、無事1位でフィニッシュしました。
おわりに
ということで、無事に1位を獲得し景品のリュックをゲットすることができました。世界から猛者が集うワークショップで優勝できたので、実質世界1位になったと言えるでしょう。(←絶対違う)

re:Invent では様々なセッションが開催され、AWSの各サービスについて学べますが、通常のセッションよりもワークショップに参加して手を動かした方がより理解が深まると感じました。強制的に色々なサービスを触れることができる良い機会になりますね。また、ワークショップに参加するとグッズ (今年の目玉はdeepComposer用のキーボード)をもらえることが多いのでおすすめです。
最後までお読みいただきありがとうございます。
街中でこのリュックを背負ってる人を見かけたら多分僕なので声をかけてください。(普段から使うのかよ)
それでは皆さん、良い年末を!