はじめに
こんにちは。
NTTドコモサービスイノベーション部1年目社員の尾﨑です。
この記事は、NTTドコモ R&D Advent Calendar 2020 14日目の記事です。
通常業務では、位置情報を活用したレコメンド基盤の開発を担当しています。
先日、自然言語処理コーパスについて知らべていたら、LREC 2020に通っている含意関係認識(後記述)の日本語コーパスが公開されていたため
早速BERTにて含意関係認識タスクを行ってみました。
本記事はこんな人向け
-
含意関係認識ってなに?
-
手軽にBERTで文書分類タスクやってみたい
含意関係認識とは?
含意関係認識(Recognizing Textual Entailment)とは、与えられた2つの文の間に含意関係が成り立つかどうかを判別することを言います。含意関係とは、例えば下記例文のように、文1として「この部屋はオーシャンビューで景色が綺麗。」という文が成り立つとき、「この部屋から海が見える。」という文も成り立つような関係を言います。要するに仮説(Hypothesis)とする文(ここでは文1)が成り立つとき、前提(Premise)とする文(ここでは文2)が成り立つかどうかを判別するタスクになります。
| Hypothesis: この部屋はオーシャンビューで景色が綺麗。 |
|---|
| Premise: この部屋から海が見える。 |
| 含意有無:あり |
含意関係認識は機械翻訳や質問応答をはじめとする自然言語処理研究に広く必要とされる技術要素でもあり、様々な手法で解かれていますが、本記事ではBERTを使った手法を紹介します。
モデル(BERT)概要
本記事ではBERTを用いて含意関係認識を行います。下記モデル画像はBERTの元論文から引用
Sentense1(Hypothesis)とSentense2(Premise)の文の分割された単語をInputとし、含意関係が成り立つか否かの2値分類タスクとして実装します。
Sentense1とSentense2の2文としてモデルにInputするため、Sentense1の文頭に [CLS], 2文間に[SEP]のを挟んで、境目を認識できるようにしています。
最終的なOutputはSoftmax関数後の各クラス0~1.0の範囲で算出られる値で、確率的解釈が可能になります。
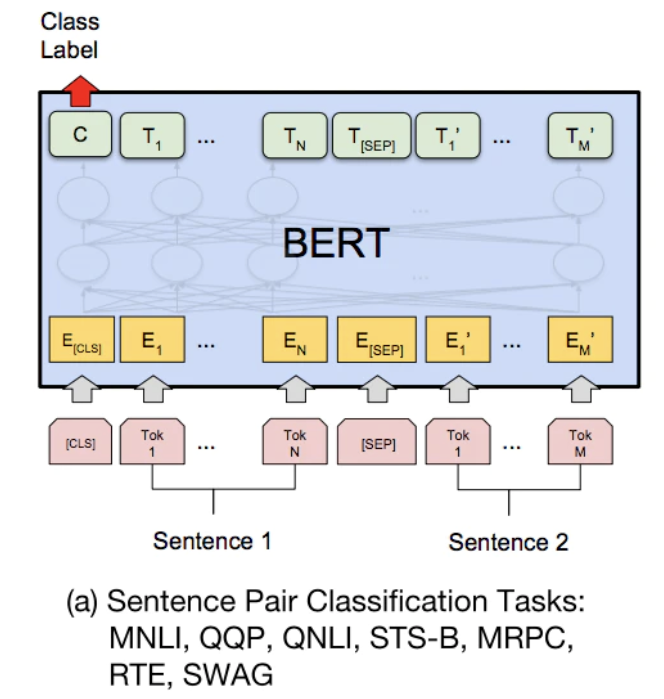
実際にこちらのモデルを使用して、含意関係認識タスクを解いてみましょう。
準備
パッケージ
BERTの実装はtransformersのパッケージに頼ります。
transformersは自然言語処理向けのモデルが多数含まれたパッケージなので便利です。
今回はtransformersのパッケージ内にあるBERTを使用して実装を行います。
あとは付属で必要な幾つかのパッケージをインストールして下さい。
pip install transformers
pip install tensorflow
pip install scikit-learn
pip install pandas
pip install fugashi
pip install mecab-python3
pip install ipadic
データ
本記事では株式会社リクルートが提供する"Japanese Realistic Textual Entailment Corpus" (https://github.com/megagonlabs/jrte-corpus)を利用しました。
※このコーパスのライセンスはCC-BY-NC-SA 4.0なので商用利用は不可です
含意関係認識タスクの英語コーパスは多く世の中に出回っていあますが、今回使用する日本語コーパスはあまり見ません。また、じゃらんクチコミデータから作成されているため、現実で使用する自然言語により近い文書となっています。
上記の様になかなか珍しいデータですので、実際にデータを見てみましょう!
データ例 rte.lrec2020_sem_long.tsv
| id | Hypothesis | Premise | 含意有無 |
|---|---|---|---|
| 0 | 従業員さんの対応もよくお部屋もきれいでした。 | お部屋はキレイでした! | 1 |
| 1 | 居酒屋、コンビニはタクシーでないと行けません。 | コンビニは徒歩圏内です。 | 0 |
| 2 | 部屋数もとても多い。 | 外国人も多い。 | 0 |
| 3 | 前にローソンができてました。 | コンビニが近かったです。 | 1 |
| 4 | ちょっと気になったのは、浴槽にゴミ浮いてたのが残念。 | 景色良かったです。 | 0 |
| 5 | 外観の綺麗な良い所でした。 | 高級ホテルでした。 | 0 |
| 6 | 値段が安く温泉なので,またの機会があったら宿泊したい。 | リーズナブルな料金でまた利用したいと思います | 1 |
| 7 | 一日中本当にリフレッシュ、リラックスできました! | とてもゆっくりくつろげました! | 1 |
データはHypothesis, Premise, 含意有無のラベルからなってます。
含意有無のラベルは0が含意なし、1が含意ありを表しています。
id:0のペアーはHypothesisとPremiseの単語の被覆が多いので、機械学習ベースでも比較的に容易に解けそうな問題だと思いました。
一方、id:3のペアーは「コンビニ」が「ローソン」を包含していてかつ「前」と「近かった」も文脈的に類似する単語であると認識することが求められます。このような場合、「コンビニ」が「ローソン」の上位語になる事前知識が必要ですが、今回使用するBERTでは単語間の上位語、下位語を認識するような機構は持ち合わせていないため、id:3のような問題は解くのは難しそうです。
また、レビューなので主語が抜けている文がほとんどでした。(人は主語を補完、単語同士の包含認識等を行い含意関係認識を行っていると思うと改めて人の凄さに気づかされました。)
含意関係認識に使用できるデータはいくつかありますが、本記事ではrte.lrec2020_sem_long.tsvを使用います。
データ例を見てお気づきの方もいるかもしれませんが、含意関係認識タスクは単語の被覆率などの表層的な素性で容易に解けてしまうことがあります。(データ作成時に問題あり)
そのような表面的な含意関係ではなく、本来あるべき含意関係認識(id:3のような)を行いたかったため、単語の被覆率が少ないrte.lrec2020_sem_long.tsvでの学習・評価を行います。
rte.lrec2020_sem_long.tsvのデータ数はそれぞれ
- train:10,299
- dev:2,918
- test:1,490
です。
実装
パッケージセクションでも書きましたが、BERTの実装はtransformersのパッケージに頼ります。
googleが提供する公式での実装をしたい方はこちらを参考にどうぞ
ファイル構成
├── data
│ └── jrte_corpus
│ └── rte.lrec2020_sem_long.tsv
├── models/
├── models.py
├── preprocessing.py
├── train.py
├── utils.py
└── evaluate.py
日本語事前学習モデル
BERTのtokenizerに日本語事前学習モデルとし東北大学の乾研究室が作成したbert-base-japanese-whole-word-maskingを使用します。bert-base-japanese-whole-word-maskingは
- Mecabで分かち書き
- WordPieceでSubwordに分割
- whole word maskingを適用
にて学習した日本語事前学習モデルです。
学習
モデル部分の記述はtransformersのパッケージを使用しているため簡潔に書くことができます。
下記がモデルのコード
import tensorflow as tf
from transformers import BertConfig, TFBertForSequenceClassification
def build_model(pretrained_model_name_or_path, num_labels):
config = BertConfig.from_pretrained(
pretrained_model_name_or_path,
num_labels=num_labels
)
model = TFBertForSequenceClassification.from_pretrained(
pretrained_model_name_or_path,
config=config
)
model.layers[-1].activation = tf.keras.activations.softmax
return model
学習部分のスクリプトはこちらの記事を参考にさせていただきました。
from sklearn.model_selection import train_test_split
from tensorflow.keras.callbacks import EarlyStopping
from transformers import BertJapaneseTokenizer
from models import build_model
from preprocessing import convert_examples_to_features, Vocab
from utils import load_dataset, evaluate
def main():
# Set hyper-parameters.
batch_size = 32
epochs = 100
model_path = 'models/'
pretrained_model_name_or_path = 'cl-tohoku/bert-base-japanese-whole-word-masking'
maxlen = 100
# Data loading.
x, y = load_dataset('./data/jrte_corpus/rte.lrec2020_sem_long.tsv')
tokenizer = BertJapaneseTokenizer.from_pretrained(pretrained_model_name_or_path)
# Pre-processing.
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=42)
target_vocab = Vocab().fit(y_train)
features_train, labels_train = convert_examples_to_features(
x_train,
y_train,
target_vocab,
max_seq_length=maxlen,
tokenizer=tokenizer
)
features_test, labels_test = convert_examples_to_features(
x_test,
y_test,
target_vocab,
max_seq_length=maxlen,
tokenizer=tokenizer
)
# Build model.
model = build_model(pretrained_model_name_or_path, target_vocab.size)
model.compile(optimizer='sgd', loss='sparse_categorical_crossentropy')
# Preparing callbacks.
callbacks = [
EarlyStopping(patience=3),
]
# Train the model.
model.fit(x=features_train,
y=labels_train,
batch_size=batch_size,
epochs=epochs,
validation_split=0.1,
callbacks=callbacks)
model.save_pretrained(model_path)
if __name__ == '__main__':
main()
評価
accuracyは0.8368でなかなか高い精度ですが、詳しい誤分類をサンプルしてみていきましょう。
| 含意ラベル | precision | recall | f1-score |
|---|---|---|---|
| 0 | 0.8153 | 0.7774 | 0.7959 |
| 1 | 0.8506 | 0.8780 | 0.8641 |
結果サンプル
True Positiveの例
| Hypothesis | Premise | Predict | True |
|---|---|---|---|
| ホテルまで駅からの送迎バスも在ります! | 送迎もあるので便利です。 | 1 | 1 |
| 部屋も清潔でベッドも充分な広さでした。 | 部屋も清潔で広々としていました。 | 1 | 1 |
| 全体的に多少古いのでしょうがEV,部屋等汚れていました。 | 古いですね。 | 1 | 1 |
| 朝食はあまり期待しないほうがいいかもしれません。 | 朝食はおすすめできません。 | 1 | 1 |
True Positiveの傾向から単語の被覆によって含意関係を認識しているように見えます。
単語が被覆しているペアーは含意関係を認識するのは容易に感じられました。
False Positiveの例
| Hypothesis | Premise | Predict | True |
|---|---|---|---|
| さらにお風呂も気持ちよく良かった。 | お風呂も広く良かった。 | 1 | 0 |
| 角部屋で景色は最高。 | 最上階で景色も最高。 | 1 | 0 |
| 軽く部屋の説明をうけ、エレベーターまで案内をしてくれました。 | 部屋まで案内される。 | 1 | 0 |
| ただ風呂からそこそこ歩きますので寒いです。 | 風呂は寒いです。 | 1 | 0 |
False Positiveでは単語の被覆につられて誤認識が多くみられました。
Hypothesis:「ただ風呂からそこそこ歩きますので寒いです。」Premise:「 風呂は寒いです。」に関しては人でも含意関係を認識するの難しいですよね。Hypothesisの「寒い」は省略されている「道中は」に主語となりますが、Premiseの「 寒い」の主語は「風呂は」ですのでこの問題を解くには係り受け解析や単語の上位語、下位語等の事前知識が必要になりそうです。
「角部屋で景色は最高。」と「 最上階で景色も最高。」も同様ですね
最後に
BERTも用いた含意関係認識について紹介しました。
含意関係認識タスクではBERT様な強力なsequenceモデルでも課題は多い様に感じられました。
また、単語の上位語、下位語等の事前知識理解や係り受け解析等の複数のNLP技術が組み合わさり、人が行う含意関係認識に近づくことができると改めて思いました。
含意関係認識の精度が上がれば、機械翻訳や質問応答をはじめとする自然言語処理研究に広く必要とされる技術要素であると個人的には期待している分野です。
参考文献
- Yuta Hayashibe. Japanese Realistic Textual Entailment Corpus. Proceedings of The 12th Language Resources and Evaluation Conference, pp.6829-6836. 2020. (LREC 2020) [PDF] [bib]
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, Devlin, J. et al. (2018)
- https://github.com/cl-tohoku/bert-japanese
- https://hironsan.hatenablog.com/entry/textual-entailment-recognition-in-japanese