はじめに
この記事は、ドコモアドベントカレンダー15日目の記事になります。
POI検索エンジンの開発に携わっています。
今回は、Solrを使ったPOI横断検索の基本の仕組みについて書きます。
概要
- POIってなに・活用事例
- 検索エンジン・Solrってなに
- どうやって検索しているの
- 精度を上げる工夫
今回のテーマは、"検索をする"という行為の裏側で、どのようなシステムが動いているか、
専門外の方でもなんとなくイメージすることができるということです。
というのも、私自身が最初に「検索エンジンの開発」に取り掛かる時に、正直全くイメージがつかず、
検索エンジンの構成や技術的な情報が理解しづらかったからです。
検索、って・・・検索窓に知りたいことを入力すれば、魔法のように自分の求める答えが出てくるんじゃない?
なんて思っており、どのようなロジックで検索されているか全く知りませんでした。

Solrの詳しい使い方や細かい検索テクニック等は、検索すれば手に入ると思いますし、
詳しい方にとっては周知の事実も多いかもしれませんが、お付き合いいただけますと幸いです。
本文
POIってなに
「POI検索エンジン」って言われて、
あ〜POIを検索するためのエンジンね、だいたい把握した!なんてピンとくる方はどれくらいいらっしゃるのでしょうか。
ネットワーク系の専門職の方には、は?POI?相互接続点?なんて言われることもたまにありますが、
ここでいうPOIとは、Point of Interface (相互接続点)ではなく、 **Point of Interest(施設情報)**のことです。
"POI"は「誰かが便利、あるいは興味のある所と思った特定の場所」を定義としています。
例えば、観光スポット・ショッピングモール・コンビニエンスストアなどはPOIに当てはまりますが、
個人宅の住所等はPOIには当てはまりません。
つまり、POI検索エンジンというのは、ユーザが知りたい施設情報を検索すると、
合致する適切な施設情報を検索し、返答するものです。
ドコモが提供するいくつかの商用サービス内でも、POI検索エンジンは利用されています。
検索エンジン・Solr ってなに
ドコモ内のPOI検索を利用したサービスの裏側では、Apache Solr(以下、Solr)と呼ばれる全文検索エンジンサーバが利用されています。
Solrは、Lucene というJavaライブラリをベースにしたオープンソースの検索エンジンであり、世界中の開発者によって活発に機能拡張が行われています。(最新ver:7.5.0 2018/11現在)
全文検索
全文検索は、指定したキーワード(クエリ)が、データベースのどこに含まれるか、横断的に中身を全て検索する方法です。
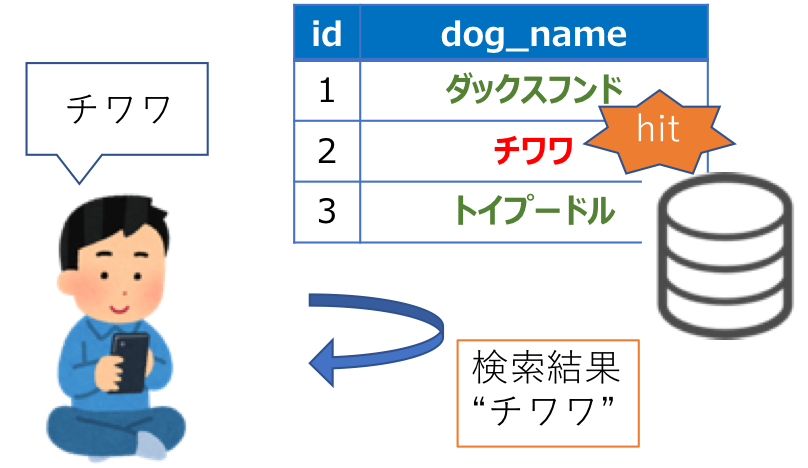
例えば、データベースとして、犬の名前の入ったリストを持っていたとします。
このリストからユーザが「チワワ」という文字列を検索すると、リスト内を全文検索して、一致する文字列があった場合はその検索結果を返します。
全文検索には、主に「順次検索方式」と「転置インデックス方式」の2種類があります。
詳細な説明は省略しますが、Solrでは転置インデックス方式という索引検索のような方式が取られています。
どうやって検索しているの
それでは、実際にSolrを使ったPOI検索がどのように行われているか、イメージを追っていきましょう。
さきほどの例に則ると、POI名称のリストを全部見ていき、合致する名称を返す挙動となります。
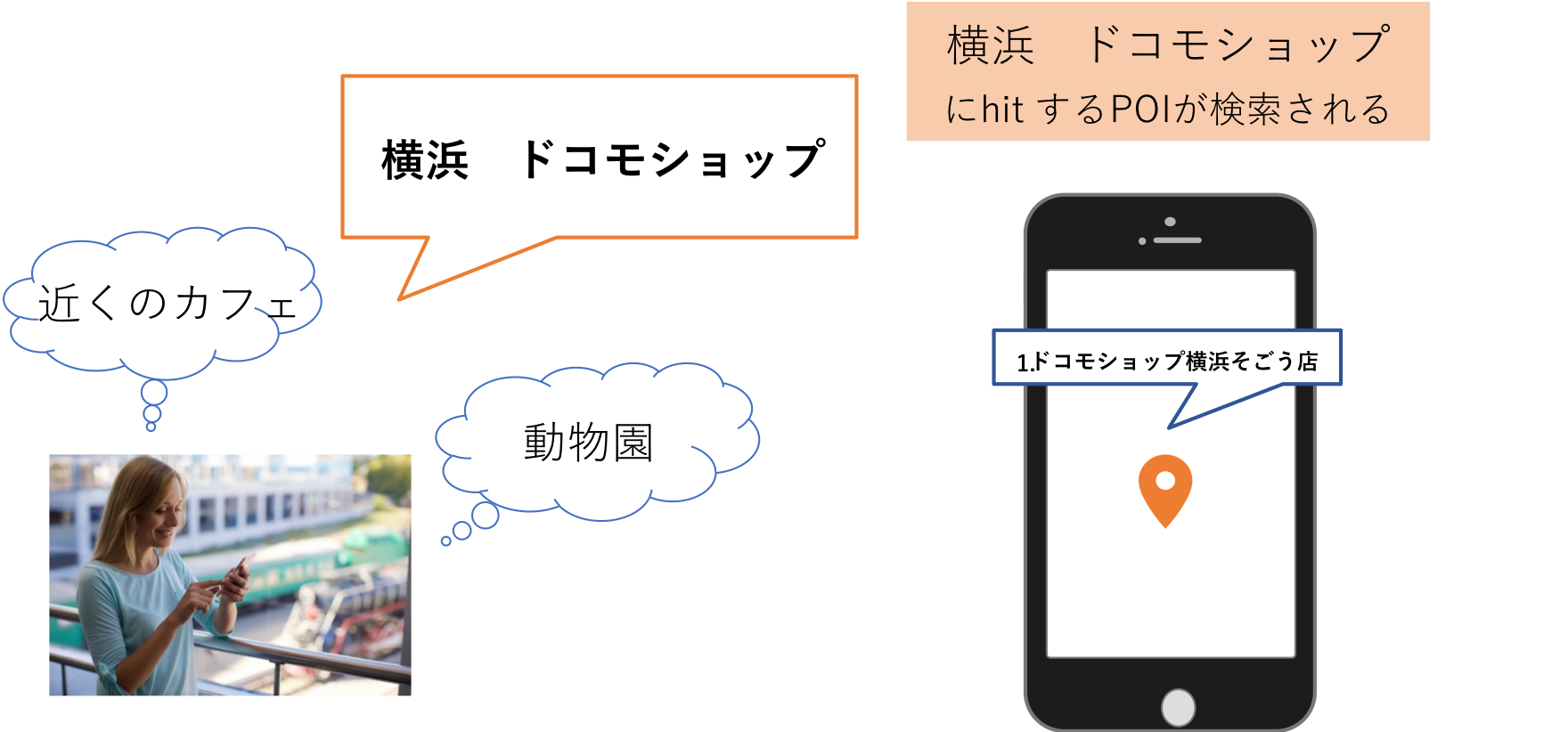
ユーザがPOI検索を行うシーンを考えてみましょう。
前提として、次のようなPOIのデータをエンジン側で持っていたとします。
| id | POI_name |
|---|---|
| 1 | A電機 みなとみらい店 |
| 2 | Bカメラ 港北店 |
| 3 | C電機店 横須賀店 |
ユーザ「あ〜、ふとん乾燥機が欲しいなぁ。週末に横浜に行くから、家電量販店に寄ろうかな。」
上図のPOIは全て横浜にある家電量販店ですので、よい結果としては、全てのPOIが検索結果として返されることが想定されます。
ユーザ「よし、『横浜 家電量販店』で検索だ」
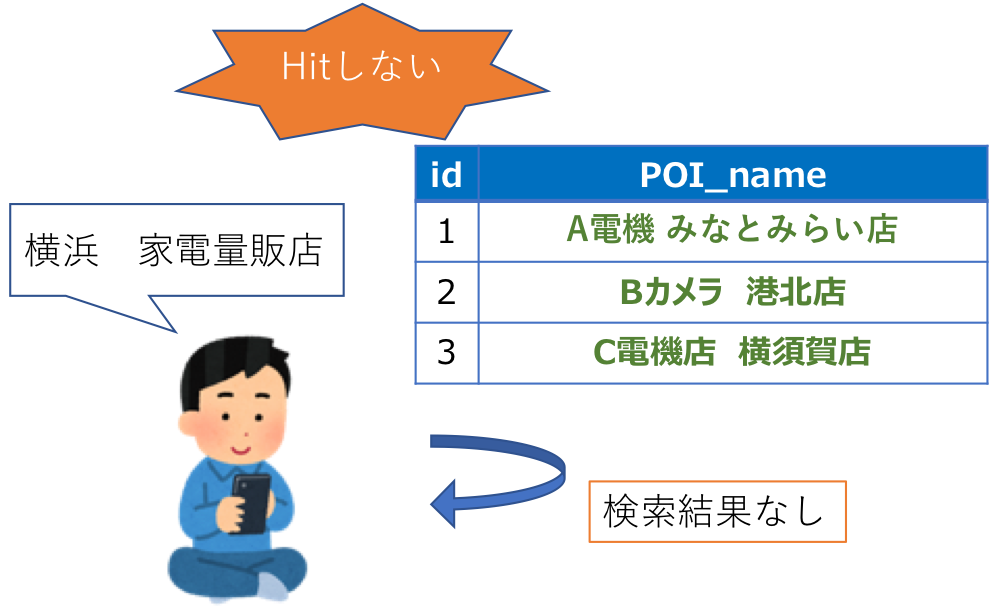
ユーザ「検索結果なし・・・」
このようにPOI検索では、施設名称の情報だけでは文字列が一致せず、うまく検索できないこともあります。
しかし、POI情報として施設名称だけでなく、住所(横浜)やカテゴリ名(電気量販店)などの属性情報も持っていれば、例に挙げたPOIは検索可能です。
ですので、実際のPOI検索では、いくつもの属性情報を横断的に検索しています。(以下、横断検索と呼ぶ)
では、別の検索例を使って、もう少し複雑な横断検索がどのように行われるか説明します。
横断検索には、edismax(全フィールド内で最も高いスコアを採用)というSolrの機能を利用しています。
次のような検索対象データを持っていた場合を考えます。poi_nameやカテゴリ等の属性情報を、以下、
フィールドと呼びます。
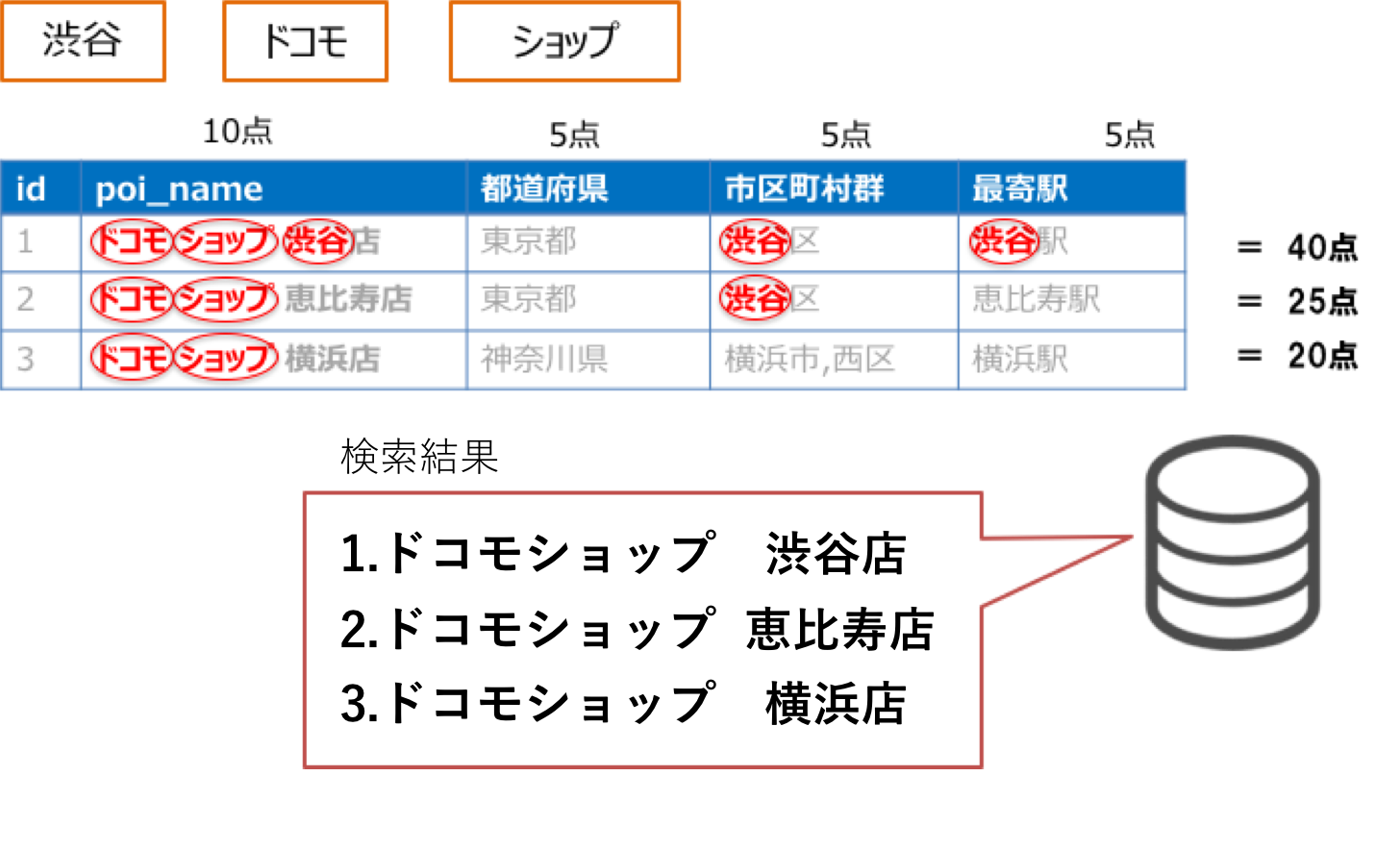
| id | poi_name | 都道府県 | 市区町村群 | 最寄駅 | カテゴリ |
|---|---|---|---|---|---|
| 1 | ドコモショップ 渋谷店 | 東京都 | 渋谷区 | 渋谷駅 | ケータイ販売店 |
| 2 | ドコモショップ 恵比寿店 | 東京都 | 渋谷区 | 恵比寿駅 | ケータイ販売店 |
| 3 | ドコモショップ 横浜店 | 神奈川県 | 横浜市,西区 | 横浜駅 | ケータイ販売店 |
ユーザ「あ、携帯の充電が切れたからショップに行きたいな。『渋谷のドコモショップ』と。」

『渋谷のドコモショップ』という検索語は、内部で形態素解析され、"渋谷" "ドコモ" "ショップ"という3つの検索語に分割されます。("の"は、接続語なので検索語から外してあります。)
それぞれのフィールドには、入力された文字列と合致するとX点を付ける、というスコア情報が事前に付与されていて、検索語が当たった数だけスコアを足すとします。
そのスコアの高い順に返答すると、以下のような検索結果となります。
ユーザ「渋谷にあるドコモが分かったぞ!恵比寿にもあるなら、帰り道に寄ってみよう」
このように、名称と文字列が一致しなくても、他の属性情報を使ってPOIを検索することもできます。
今回は簡略化して書きましたが、実際には20以上のフィールドを横断検索しており、
各フィールドに付けるスコアは、機械学習を用いたパラメータチューニングにより決定しています。
精度を上げる工夫
ユーザが求める情報がきちんと上位で返されることが、検索エンジンの精度がいい、ということです。
どんなに曖昧な検索でも、ユーザが
**そうそう!これが知りたかった! **
という情報が検索できるよう、様々な工夫を行なっています。
その中で、今回1つお伝えしたいのが人気度情報を利用した検索です。
例えば、あるユーザが
「『清水寺』に行きたいな〜」
と思ったとします。
この時、「清水寺」で多くのユーザがイメージするのは、おそらく**(京都にある)清水寺**だと思います。
前述のように、文字列の一致情報を使って「清水寺」を検索するとどのような結果が返るでしょうか。

ユーザ「千葉にも清水寺あるんだ・・・京都のが知りたいんだけどな」
このように、文字列の一致情報で検索を行なっていると、同名施設があったときにそれをどのような順番で返すのかが重要になって来ます。
しかし、人間にとっては雰囲気でわかることでも、エンジンには、同じように文字列一致しているPOIの中でどれが重要かなんて分かりません。
ここで利用するのが「施設人気度」情報です。これはPOIに前もって付与してあり、人気の施設ほど高いスコアがつくため、上位で検索されます。
「人気度」は、「その施設の周辺に人がたくさんいたら人気だろう」と「その施設についてSNSでよく発信されていたら人気だろう」という二つの観点から算出しています。
では、先ほどの『清水寺』POIに、施設人気度情報が付与されていたらどうなるでしょうか。

ユーザ「わ〜い、京都の清水寺の情報が分かった!」
めでたし、めでたし。
おわりに
これから検索エンジンに触れようと思っている方、検索の仕組みを全くご存知なかった方、
それぞれが今後、検索するときに「お、裏で色んなロジックが動いとるんやなぁ」と
少しでも興味を持っていただけることを願って、おわりにさせていただきます。
お読みいただき、ありがとうございました。
参考書籍
- 打田智子,大須賀稔,大杉直也,西潟一生,西本順平,平賀一昭(2017)『[改訂第3版]Apache Solr入門』 技術評論社.