はじめに
この記事は、NTTドコモ 先進技術研究所 Advent Calendar 2019の7日目です。
NTTドコモの久保田です。業務では、ドコモのFinTechサービスに使われる技術の研究開発をしています。研究開発といいつつも、ビジネス部門と密に連携しながら、世の中への価値提供を日々考えています。
業務内容に関しては、まだ出せない部分もあるので、
今回は、オープンデータを活用しながら機械学習系の一分野である推薦システムについて書きたいと思います(一応今回の実装も記載しています)。
概要
NLPと推薦システムという2つの分野は、似たような手法を使われることが多い分野です。
例えば、LDA(latent Dirichlet allocation)などのトピックモデルなどは両分野で提案されています。
NLPにおけるトピックは、政治的な内容などの文章で題材にしている話題であり、推薦システムにおけるトピックはECサイトでのユーザの購入背景やアイテム間の関係性が該当します。
NLPの技術をもとに推薦システムに活かそうという試みは、Word2Vecで提案されているSkip-gram with negative sapmplingというアーキテクチャを応用したItem2Vecがあります。
この記事では、EMNLP2017で提案されたSCDV(Sparse Composite Document Vectors using soft clustering over distributional representations)を推薦システムに応用してみたという内容になります。
SCDVは単語ベクトルを足し合わせて平均することで、文書ベクトルを作成する手法です。
各単語が属するトピックをGMMでソフトクラスタリングして求め、Word2Vecで構築した単語ベクトルをトピックを考慮したベクトル空間に変換することで、精度を向上しようとしています。この手法のアイディアとしては、単語は意味が一意に定まるわけではないという仮定のもと、ソフトクラスタリングで多義性を表現しようとしています。
SCDVの詳細については、詳細を解説している人におまかせして、
この記事では、Item2Vecを踏襲し、SCDVにおける単語をアイテム、文書をユーザと見立てて推薦システムに適用できるのかという検証をします。
アイテムに関しても、ユーザによって同じアイテムでも利用シーンが異なることがあるので、精度が向上するのでは!?と考えています。
実務での適用例
実務では、以下のような推薦シナリオがあるのではないかと思います。
「このアイテムを買った人はこのアイテムを買っています」という場面での推薦
アイテム間の関連性に基づいて、すでにユーザが購入しているアイテムに関連するアイテムを推薦する状況ですね。
足し上げる前のトピックを考慮したアイテムベクトルを活用することで、よりアイテム間の類似度を高められるのではという期待感があります。
ユーザの趣味嗜好に基づきアイテムを推薦
ユーザとアイテムの関連性に基づいて、推薦する状況です。
ユーザとアイテムの関連性を表現する潜在因子の特定をすることがポイントになります。
SCDVでユーザベクトルを求め、アイテムとの類似度を求めることができます。アイテムベクトルとユーザベクトルとの類似度に基づいて推薦することで、ユーザとアイテムの関連性を考慮した推薦ができることが期待できます。
今回は、1つめに関してItem2Vecと比較して検証してみたいと思います。
実験設定
データ
groupelensが提供しているMovieLens 20M Datasetを利用します。
MovieLensは映画のレビューサイトで、ミネソタ大学が研究目的で運用しているサイトで取得できるデータセットで公開されています。
パラメータ設定
Item2Vecのパラメータは以下のように設定します。
- 周辺アイテム:ユーザがレビューした映画のうち、各ユーザの平均レビューより高い評価の全てのアイテム
- アーキテクチャ:Skip-Gram with negative sampling
- アイテムベクトルサイズ:300
- negative samplingサイズ:5
- SCDVでトピックを考慮するために利用しているGMMで想定するクラスタ数:10
実装は後段で示します。
映画ジャンルのクラス定義
映画に関する情報は、以下の図のようなデータがあります。ジャンル情報に関しては、20ジャンル(ジャンル無しも含む)の複数が映画に付与されています。
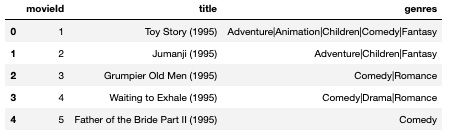
今回、映画のクラス定義については、以下のように定義することにします。
まず、20のジャンルを20次元のOneHotベクトルで表現し、主成分分析をして第一主成分を取得します。取得した第一主成分を5つのビンに分割し、Label Encodingしたものを映画が属するクラスとして定義します。
結果
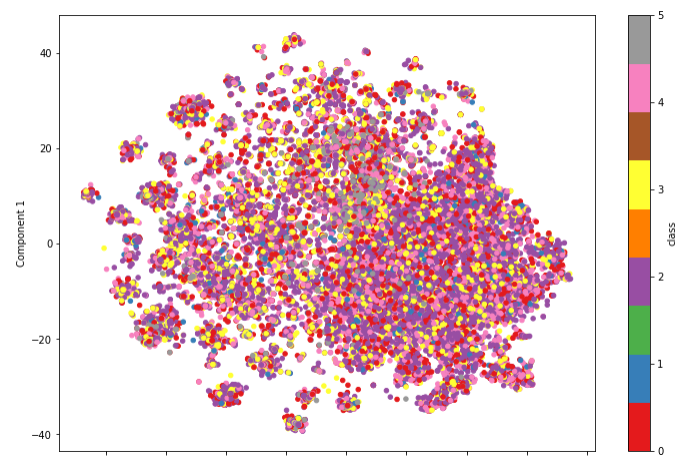
Item2Vecで獲得したアイテムベクトルをt-SNEで可視化した図になります。
SCDVで提案されていたトピックを考慮したアイテムベクトルをt-SNEで可視化した図が以下の図です。
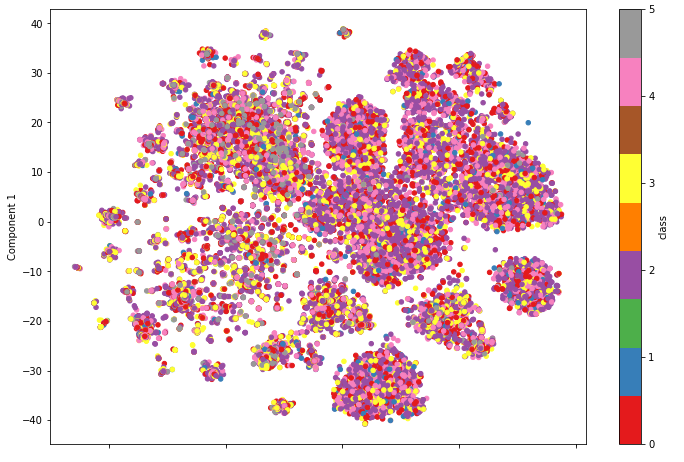
うーん、SCDVで提案されているトピックを考慮したItem2Vecの方が比較的にアイテムの集合ができているように見えますが、クラスのラベル付けがいまいちなのか入り乱れてますね。
クラスタリングの定量評価を行うために、Pseudo Fという尺度を導入します。
Pseudo Fは以下の式で表現できます。
\text{Pseudo F} = \frac{(T-P_{k})/(k-1)}{P_{k}/(n-k)}
$ k $はクラスタの数、$ n $は全サンプル数、$ T $は全データの距離二乗和、$ P_{k}$はクラスタ内距離二乗和です。この指標は、クラスタの凝縮性と離散性を考慮した指標であり、値が大きいほどクラスごとにきれいに分離できているという解釈になります。
| Item2Vec | トピックを考慮したItem2Vec | |
|---|---|---|
| class0 | 28441 | 28526 |
| class1 | 168725 | 172851 |
| class2 | 10487 | 11009 |
| class3 | 33827 | 34211 |
| class4 | 26895 | 25730 |
class4以外は値が大きくなっており、全体的にクラスがきれいに分離しているといえそうです。
この結果から、プレーンなItem2VecよりもSCDVでトピックを考慮したほうが推薦システムの精度向上に寄与するかもしれないということがわかりました。
おわりに
今回は、SCDVで提案されていたトピックを考慮した単語ベクトルを応用して、推薦システムを考えてみました。実際に、ユーザに推薦して評価するところまではいけませんでした。方針としては、今回求めたトピックを考慮したアイテムベクトルを中間層として再利用してモデルを学習して、周辺アイテムから対象となるアイテムを予測することで推薦するという感じかなと思います。
(参考)実装
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import os
import sys
import seaborn as sns
import gc
from sklearn.model_selection import train_test_split
import pickle
from tqdm import tqdm_notebook as tqdm
import time
import itertools
from MulticoreTSNE import MulticoreTSNE as TSNE
from sklearn.mixture import GaussianMixture
import smart_open
import gensim
from gensim.models import word2vec
from gensim.test.utils import common_texts, get_tmpfile
from gensim.models import Word2Vec
from gensim.models.callbacks import CallbackAny2Vec
from sklearn.decomposition import PCA
import warnings
warnings.filterwarnings('ignore')
%matplotlib inline
def reduce_mem_usage(df, verbose=True):
numerics = ['int16', 'int32', 'int64', 'float16', 'float32', 'float64']
start_mem = df.memory_usage().sum() / 1024**2
for col in df.columns:
col_type = df[col].dtypes
if col_type in numerics:
c_min = df[col].min()
c_max = df[col].max()
if str(col_type)[:3] == 'int':
if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:
df[col] = df[col].astype(np.int8)
elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:
df[col] = df[col].astype(np.int16)
elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max:
df[col] = df[col].astype(np.int32)
elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max:
df[col] = df[col].astype(np.int64)
else:
if c_min > np.finfo(np.float16).min and c_max < np.finfo(np.float16).max:
df[col] = df[col].astype(np.float16)
elif c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max:
df[col] = df[col].astype(np.float32)
else:
df[col] = df[col].astype(np.float64)
end_mem = df.memory_usage().sum() / 1024**2
print('Memory usage after optimization is: {:.2f} MB'.format(end_mem))
print('Decreased by {:.1f}%'.format(100 * (start_mem - end_mem) / start_mem))
return df
DATA_DIR = 'ml-20m/'
def get_ratings_count(ratings_df):
ratings_count = pd.DataFrame(ratings_df['rating'].value_counts()).reset_index()
ratings_count.columns = ['ratings', 'count']
ratings_count.sort_values('ratings', inplace=True)
return ratings_count
def get_user_count(ratings_df):
user_count = ratings_df[['userId', 'rating']].groupby('userId').count().reset_index()
user_count.columns = ['userId', 'count']
return user_count
def get_average_ratings_by_user(ratings_df):
df = pd.DataFrame(ratings_df.groupby('userId')['rating'].agg(np.average)).reset_index()
df.columns = ['userId', 'average_rating']
return df
ratings = pd.read_csv(DATA_DIR + 'ratings.csv')
ratings = reduce_mem_usage(ratings)
display(ratings.head())
if not os.path.isfile(DATA_DIR + 'word_counts.pkl'):
word_counts = ratings.groupby('userId')['movieId'].count().to_dict()
with open(DATA_DIR + 'word_counts.pkl', 'wb') as f:
pickle.dump(word_counts, f)
ratings_train, ratings_test = train_test_split(ratings, test_size=0.2, shuffle=True, random_state=42)
del ratings; gc.collect()
ratings_count = get_ratings_count(ratings_train)
user_count = get_user_count(ratings_train)
average_rating_by_user = get_average_ratings_by_user(ratings_train)
ratings_train = pd.merge(ratings_train, average_rating_by_user, on='userId', how='left')
del ratings_count, user_count, average_rating_by_user; gc.collect()
with open(DATA_DIR + 'ratings_train.pkl', 'wb') as f:
pickle.dump(ratings_train, f)
ratings_count = get_ratings_count(ratings_test)
user_count = get_user_count(ratings_test)
average_rating_by_user = get_average_ratings_by_user(ratings_test)
ratings_test = pd.merge(ratings_test, average_rating_by_user, on='userId', how='left')
del ratings_count, user_count, average_rating_by_user; gc.collect()
with open(DATA_DIR + 'ratings_test.pkl', 'wb') as f:
pickle.dump(ratings_test, f)
del ratings_test; gc.collect()
ratings = ratings_train.copy(deep=True)
del ratings_train; gc.collect()
item_buskets = {}
for user_id in tqdm(ratings['userId'].unique()):
user_ratings = ratings[ratings['userId'] == user_id]
movie_list = user_ratings['movieId'].sort_values().astype('str').values
item_buskets[user_id] = ' '. join(movie_list)
with open(DATA_DIR + 'item_buskets.pkl', 'wb') as f:
pickle.dump(item_buskets, f)
del f, user_id;gc.collect()
with open(DATA_DIR + 'item_buskets.txt', 'w') as f:
f.write('\n'.join(item_buskets.values()))
vocabulary = ratings['movieId'].unique()
vocab_size = len(vocabulary)
sentences = word2vec.LineSentence(DATA_DIR + 'item_buskets.txt')
model = word2vec.Word2Vec(sentences, sg=1, size=300, window=vocab_size, hs=0, min_count=1, negative=5, seed=42, iter=3, workers=16)
with open('item2vec_model.pkl', 'wb') as f:
pickle.dump(model, f)
with open('item2vec_model.pkl', 'rb') as f:
item2vec_model = pickle.load(f)
def cluster_GMM(num_clusters, word_vectors):
start = time.time()
clf = GaussianMixture(n_components=num_clusters,
covariance_type="tied", init_params='kmeans', max_iter=50, random_state=0)
clf.fit(word_vectors)
idx = clf.predict(word_vectors)
print ("Clustering Done...", time.time()-start, "seconds")
idx_proba = clf.predict_proba(word_vectors)
return (idx, idx_proba)
def get_probability_word_vectors(word2vec_model, featurenames, word_centroid_map, num_clusters, word_idf_dict):
prob_wordvecs = {}
for word in word_centroid_map:
prob_wordvecs[word] = np.zeros(num_clusters * num_features, dtype=np.float32)
for index in range(0, num_clusters):
try:
prob_wordvecs[word][index*num_features:(index+1)*num_features] = word2vec_model[word] * word_centroid_prob_map[word][index] * word_idf_dict[word]
except:
continue
return prob_wordvecs
def create_cluster_vector_and_gwbowv(prob_wordvecs, wordlist, word_centroid_map, word_centroid_prob_map, dimension, word_idf_dict, featurenames, num_centroids, train=False):
bag_of_centroids = np.zeros( num_centroids * dimension, dtype="float32" )
global min_no
global max_no
for word in wordlist:
try:
temp = word_centroid_map[word]
except:
continue
bag_of_centroids += prob_wordvecs[word]
norm = np.sqrt(np.einsum('...i,...i', bag_of_centroids, bag_of_centroids))
if(norm!=0):
bag_of_centroids /= norm
if train:
min_no += min(bag_of_centroids)
max_no += max(bag_of_centroids)
return bag_of_centroids
def save_word2vec_format(fname, vocab, vector_size, binary=True):
"""Store the input-hidden weight matrix in the same format used by the original
C word2vec-tool, for compatibility.
Parameters
----------
fname : str
The file path used to save the vectors in.
vocab : dict
The vocabulary of words.
vector_size : int
The number of dimensions of word vectors.
binary : bool, optional
If True, the data wil be saved in binary word2vec format, else it will be saved in plain text.
"""
total_vec = len(vocab)
with smart_open.open(fname, 'wb') as fout:
print(total_vec, vector_size)
fout.write(gensim.utils.to_utf8("%s %s\n" % (total_vec, vector_size)))
for word, row in tqdm(vocab.items()):
if binary:
row = row.astype(np.float32)
fout.write(gensim.utils.to_utf8(word) + b" " + row.tostring())
else:
fout.write(gensim.utils.to_utf8("%s %s\n" % (word, ' '.join(repr(val) for val in row))))
with open('item2vec_model.pkl', 'rb') as f:
model = pickle.load(f)
num_features = 300
num_workers = 16
num_clusters = 10
word_vectors = model.wv.syn0
idx, idx_proba = cluster_GMM(num_clusters, word_vectors)
word_centroid_map = dict(zip(model.wv.index2word, idx))
word_centroid_prob_map = dict(zip(model.wv.index2word, idx_proba))
with open(DATA_DIR + 'ratings_train.pkl', 'rb') as f:
ratings = pickle.load(f)
user_num = ratings['userId'].nunique()
movie_count = ratings[['userId', 'movieId']].groupby('movieId').count().reset_index()
movie_count.columns = ['movieId', 'count']
movie_count['idf'] = np.log(user_num / movie_count['count']) + 1
featurenames = movie_count['movieId'].values
idf = movie_count['idf'].values
word_idf_dict = {}
for pair in zip(featurenames, idf):
word_idf_dict[str(pair[0])] = pair[1]
prob_wordvecs = get_probability_word_vectors(model, featurenames, word_centroid_map, num_clusters, word_idf_dict)
del word_vectors, idx, idx_proba, word_centroid_map, user_num, movie_count, featurenames, idf, word_idf_dict
gc.collect()
save_word2vec_format(binary=True, fname=DATA_DIR + 'prob_wordvecs.bin', vocab=prob_wordvecs, vector_size=3000)
prob_model = gensim.models.KeyedVectors.load_word2vec_format(DATA_DIR + 'prob_wordvecs.bin', binary=True)
tsne = TSNE(n_components=2, n_jobs=-1, random_state=42, verbose=2)
reduced = tsne.fit_transform(model[model.wv.vocab])
reduced_df = pd.DataFrame(reduced).rename(columns={0: 'Component 0', 1: 'Component 1'})
with open(DATA_DIR + 'reduced_df_wv.pkl', 'wb') as f:
pickle.dump(reduced_df, f)
del reduced_df; gc.collect()
tsne = TSNE(n_components=2, n_jobs=-1, random_state=42, verbose=2)
reduced = tsne.fit_transform(prob_model[prob_model.wv.vocab])
prob_reduced_df = pd.DataFrame(reduced).rename(columns={0: 'Component 0', 1: 'Component 1'})
with open(DATA_DIR + 'reduced_df_prob_wv.pkl', 'wb') as f:
pickle.dump(prob_reduced_df, f )
with open(DATA_DIR + 'reduced_df_wv.pkl', 'rb') as f:
reduced_df = pickle.load(f)
with open(DATA_DIR + 'reduced_df_prob_wv.pkl', 'rb') as f:
prob_reduced_df = pickle.load(f)
movies = pd.read_csv(DATA_DIR + 'movies.csv')
movies.head()
genres_list = movies['genres'].str.split('|')
genres_cat = list(set(itertools.chain.from_iterable(genres_list.values)))
indices_list = [[genres_cat.index(n) for n in genres] for genres in genres_list]
one_hot = np.zeros((movies.shape[0], len(genres_cat)))
for i, indices in tqdm(enumerate(indices_list)):
one_hot[i, :][indices] = 1
movies['movieId'] = movies['movieId'].astype(str)
pca = PCA()
pca.fit(one_hot)
transformed = pca.fit_transform(one_hot)
first_component = transformed[:, 0]
movies['first_component'] = first_component
model_vocab = list(model.wv.vocab.keys())
model_first_component = movies[movies['movieId'].isin(model_vocab)]['first_component']
print(len(reduced_df))
reduced_df['class'] = model_first_component
reduced_df['class'] = pd.cut(reduced_df['class'], 5).astype(str).astype('category').cat.codes
reduced_df_for_plot = reduced_df
reduced_df_for_plot.plot.scatter(x='Component 0', y='Component 1', c='class', cmap='Set1', figsize=(12, 8))
plt.savefig(DATA_DIR+'word2vec_tsne.png')
plt.show()
x_mean, y_mean = np.mean(reduced_df.iloc[:, 0].values), np.mean(reduced_df.iloc[:, 1])
for k in range(5):
class_df = reduced_df[reduced_df['class'] == k]
T = np.sum((reduced_df.iloc[:, 0].values - x_mean)**2 + (reduced_df.iloc[:, 1].values - y_mean)**2)
W_k = np.sum((class_df.iloc[:, 0].values - x_mean)**2 + (class_df.iloc[:, 1].values - y_mean)**2)
model_pseudo_F = (T - W_k) / ((5-1)*(W_k / (len(reduced_df) - k)))
print('class{} Pseudo F: {}'.format(k, model_pseudo_F))
prob_model_vocab = list(prob_model.wv.vocab.keys())
prob_model_first_component = movies[movies['movieId'].isin(prob_model_vocab)]['first_component']
prob_reduced_df['class'] = prob_model_first_component
prob_reduced_df['class'] = pd.cut(prob_reduced_df['class'], 5).astype(str).astype('category').cat.codes
prob_reduced_df_for_plot = prob_reduced_df
prob_reduced_df_for_plot.plot.scatter(x='Component 0', y='Component 1', c='class', cmap='Set1', figsize=(12, 8))
plt.savefig(DATA_DIR + 'prob_word2vec_tsne.png')
plt.show()
x_mean, y_mean = np.mean(prob_reduced_df.iloc[:, 0].values), np.mean(prob_reduced_df.iloc[:, 1])
for k in range(5):
class_df = prob_reduced_df[prob_reduced_df['class'] == k]
T = np.sum((prob_reduced_df.iloc[:, 0].values - x_mean)**2 + (prob_reduced_df.iloc[:, 1].values - y_mean)**2)
W_k = np.sum((class_df.iloc[:, 0].values - x_mean)**2 + (class_df.iloc[:, 1].values - y_mean)**2)
model_pseudo_F = (T - W_k) / ((5-1)*(W_k / (len(prob_reduced_df) - k)))
print('class{} Pseudo F: {}'.format(k, model_pseudo_F))
参考文献
- Barkan, Oren, and Noam Koenigstein. "Item2vec: neural item embedding for collaborative filtering." 2016 IEEE 26th International Workshop on Machine Learning for Signal Processing (MLSP). IEEE, 2016.
- Mekala, Dheeraj, et al. "SCDV: Sparse Composite Document Vectors using soft clustering over distributional representations." arXiv preprint arXiv:1612.06778 (2016).
- 文書ベクトルをお手軽に高い精度で作れるSCDVって実際どうなのか日本語コーパスで実験した(EMNLP2017)
- Word2Vec のニューラルネットワーク学習過程を理解する