はじめに
こんにちは.NTTドコモ先進技術研究所2年目の田中です.ドコモ先進技術研究所Advent Calendarの発起人で,業務では こんなこと や こんなこと の研究をしています.ただ,この辺の本業に関する技術的な事は大人の事情で簡単には記事にできないので,今回は全く別の(とは言っても機械学習に関する)話題で記事を書きたいと思います.
今回記事するのは,機械学習のセキュリティに関する話です.「機械学習を使ってマルウェア検知をしましょう」とかではなく,「機械学習の」セキュリティです.
弊社も含めた多くの企業で,機械学習を使った多くのサービスが提供されていますが,この機械学習によって作られた classifier や regressor (以下,モデルと呼びます) そのものに,セキュリティ上の問題があるのではないかと指摘されています.今回は,こういったモデルのセキュリティ上の問題について紹介します.
Adversarial Examples
機械学習の研究に携わった事がある人なら一度は聞いたことがあるであろう最も有名な例は,Adversarial Examplesです.Adversarial Examplesとは,「人間が見ると正しく分類できるにも関わらずモデルが誤分類してしまうような入力」のことで,Adversarial Examplesを生成してモデルを騙す攻撃をAdversarial Attackと呼びます(Adversarial Examplesを「攻撃」の意味で使うときもあります).Adversarial Examplesがどれぐらい有名かというと,Twitterでこんなツイートがされるぐらい有名です.
機械学習をやっている人は,「この中でテナガザルはどれでしょうか?」という一見謎の質問に対し,AIになりきって高確率で正答(?)できる
— えるエル (@learn_learning3) 2 Nov 2019
このツイートの意味がわからない人のために解説しておきます.Goodfellow, Shlens, & Szegedy (2014)の研究で,分類器が誤分類してしまうような画像(Adversarial Example)を,元の画像に特定のノイズを乗せることで生成する手法が提案されました.真ん中のパンダはその論文中の例で登場する画像で,Adversarial Examplesの説明をする際に高確率で使われる超有名画像なのです.
「パンダをテナガザルって誤分類するぐらいどうでも良いでしょ」という声が聞こえてきそうですが,Adversarial Examplesは機械学習を実際のサービスに利用する際に非常に重大なインシデントを引き起こします.最も想像しやすい例だと,自動運転での標識の誤認識があげられます.実際,Eykholt, et al. (2018) では現実世界の落書きされた標識に対する誤分類の危険性が指摘され,どのような画像が誤分類されるのかに関して研究されています.
攻撃が提案されれば,当然ながらその対策も研究されます.現状,私が知る限りでAdversarial Atatckに最も有効だと言われている対策は「Adversarial Training」と呼ばれるもので,モデルを学習する際に予め学習データにAdversarial Examplesを混ぜておくという方法です.人間がインフルエンザが悪化しないようにワクチンを事前にうっておくのと似ていますね.
Model Extraction
Model Extractionは,Tramer, et al. (2016) によって提案された,モデルを復元する攻撃です.非常にシンプルな例として,ロジスティック回帰による分類器 $f:\mathbb{R}^d\to[0,1]; \boldsymbol{x}\mapsto \boldsymbol{y}$ を考えてみましょう.シチュエーションとして,$f$にクエリを投げるAPIが公開されていて,攻撃者は$f$がロジスティック回帰モデルであると知っている場合を考えます.
いまロジスティック回帰モデルを考えているので,
$$
f(\boldsymbol{x})=\frac{1}{1+\exp(\boldsymbol{w}^T\boldsymbol{x}+w_0)}
$$
と書けます.ここで,$\boldsymbol{w}$と$w_0$は学習データから決定される(学習される)パラメータです.上式の分母をはらって対数をとると以下のように書けます:
$$
\boldsymbol{w}^T \boldsymbol{x} + w_0 = \log \left( \frac{1-f(\boldsymbol{x})}{f(\boldsymbol{x})}\right).
$$
攻撃者はAPIを使って $(\boldsymbol{x}, f(\boldsymbol{x}))$ を得ることが出来るので,上式において攻撃者にとって未知なのは $\boldsymbol{w}\in \mathbb{R}^d$ と $w_0\in \mathbb{R}$ のみとなります.したがって,$d+1$ 個の線形独立なサンプル $ \boldsymbol{x}_{1},\dots, \boldsymbol{x}_{d+1}$ を攻撃者が準備することで,ロジスティック回帰モデルのパラメータ$ \boldsymbol{w}, w_0$ は復元されてしまいます.
Model Inversion
Model Inversion (Fredrikson, Jha, & Ristenpart (2015)) は,学習データを復元する攻撃です.たとえば,顔画像を分類するモデルに対するModel Inversionでは,モデルの学習に使った顔画像の復元を目的とします.もしこの攻撃が成功してしまうと,プライバシー的な観点で大きな問題となります.しかし,実際のところはModel Inversionはかなり難しいタスクで,Fredrikson, et al. (2015) ではsoftmax関数を使ったneural networkやmultilayer perceptron, stacked denoising autoencoderに対してModel Inversionを実際に行っていますが,復元された画像(下図)を確認すると,あまりうまく復元出来ていないように見えます.

ただし,GANによる画像生成の技術が進歩してきたことによって,Model Inversionをより高精度で実現している研究もあります.たとえば,Kusano, & Sakuma (2018) で提案されているPreImageGANでは,WassersteinGANを用いて鮮明に学習データを復元(厳密には学習データの条件付き生成分布を推定)しています.
Model Inversionやってみた
おなじみのMNISTのデータを使って,Model InversionをPytorchで実装してみました.ベースはKusano, & Sakuma (2018) ですが,実装が公開されていなかったこともあり,かなりゆるふわ実装にしています.また,Model InversionにWasserstein GANではなくDCGANを使っています.
問題設定
今回想定する問題設定の概要を下図に示します.下記の説明を読むときに適宜参照してください.
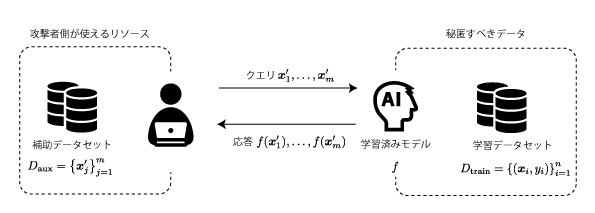
まず,企業等のサービス提供者が自社のデータ $D_{\rm train}=\left\{ (\boldsymbol{x}_i, y_j)\right\}_{i=1}^{n}$ で学習したモデル(classifier)$f$ があり,$f$への入力を投げると予測結果を返すAPIを提供しているとします.サービス提供者は$D_{\rm train}$に関する情報は秘匿したいものであり,$f$ を作成したアルゴリズム等についても非公開にしているとします.
次に,攻撃者が使えるリソースとして補助データセット $D_{\rm aux}=\left\{ \boldsymbol{x}'_j\right\}_{j=1}^{m}$ があります.攻撃者は,このデータセットの $\boldsymbol{x}'_{j}$ をAPIへのクエリとして投げて,その応答 $f(\boldsymbol{x}_j)$ を得ることが出来ます.つまり,攻撃者はAPIを利用することで $D_{\rm aux}=\left\{ (\boldsymbol{x}'_j, f(\boldsymbol{x}'_{j}))\right\}_{j=1}^m$ を攻撃に利用することが出来ます.
これらの条件の下で,攻撃者はConditional DCGANによって学習データの復元を目的として攻撃(Model Inversion)を仕掛けます.
数学的には,学習データの条件付き分布 $\mathcal{F}_{\boldsymbol{X}|Y}(\boldsymbol{x}|Y=y)$ をgenerator $G(\boldsymbol{z})$ で表現することが攻撃者の目的になります.Model Inversionの問題設定ではなく,一般的なconditional DCGANを用いた生成分布を表現することを目的とした場合では,数学的には
\begin{equation}
\widehat{\boldsymbol{\theta}}_G = \mathop{\rm argmin}\limits_{\boldsymbol{\theta}_G} \max_{\boldsymbol{\theta}_D}
\mathbb{E}_{\boldsymbol{X}\sim \mathcal{F}_{\boldsymbol{X}|Y}}\left[ \log D\left( \boldsymbol{X}, y\right) \, |\, Y=y \right]
+ \mathbb{E}_{\boldsymbol{Z}} \left[
\log \left\{ 1 - D\left( G(\boldsymbol{Z}, y), y \right) \right\}
\right]
\end{equation}
をデータから推定します.しかし,これは学習データの生成分布から得られた $(\boldsymbol{x}, y)$があるときに限り可能です.なぜなら,
\mathbb{E}_{\boldsymbol{X}\sim \mathcal{F}_{\boldsymbol{X}|Y}}\left[ \log D\left( \boldsymbol{X}, y\right) \, |\, Y=y \right]
\tag{1}
は学習データの生成分布で期待値をとっているからです.そこで,Model Inversionの問題設定では,攻撃者は式 (1) の代わりに
\begin{equation}
\widehat{\boldsymbol{\theta}}_G = \mathop{\rm argmin}\limits_{\boldsymbol{\theta}_G} \max_{\boldsymbol{\theta}_D}
\mathbb{E}_{\boldsymbol{X}\sim \mathcal{F}'_{\boldsymbol{X}|Y}}\left[ \log D\left( \boldsymbol{X}, f(\boldsymbol{X})\right) \, |\, Y=f\left( \boldsymbol{X}\right)\right]
+ \mathbb{E}_{\boldsymbol{Z}} \left[
\log \left\{ 1 - D\left( G(\boldsymbol{Z}, y), y \right) \right\}
\right]
\end{equation}
を補助データ $D_{\rm aux}=\left\{ (\boldsymbol{x}'_j, f(\boldsymbol{x}'_j))\right\}_{j=1}^{m}$ から推定します.
ここまで述べておいてアレなんですが,実装に関しては $\mathcal{F}_{\boldsymbol{X}|Y}$ と $\mathcal{F}_{\boldsymbol{X}'|Y}$は同一分布の設定となっています.まあ,より現実に近い問題設定での実装をしたい方は下記実装のDatasetの部分を適宜変更していただければ流用できると思います.
実装
Pytorchを使って実装していきます.
まずは,実験に必要なパラメータや,その他諸々の変数などを定義しておきます.
import os
import argparse
import datetime
import numpy as np
import matplotlib.pyplot as plt
import tqdm
import math
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from torchvision.datasets import ImageFolder
from torchvision import transforms
from torchvision.utils import save_image
import torchvision
from tensorboardX import SummaryWriter
import bf_mnist as bfm
if __name__ == "__main__":
"""
parameter and directories
"""
date = datetime.datetime.today().strftime("%Y%m%d%H%M")
""" parsers """
parser = argparse.ArgumentParser()
parser.add_argument(
'--data_dir',
default='../Data/MNIST/'
)
parser.add_argument(
'--model_dir',
default='../Models/model_inversion-MNIST/{0}/'.format(date)
)
parser.add_argument(
'--sample_dir',
default='../Samples/model_inversion-MNIST-{0}/'.format(date)
)
parser.add_argument(
'--log_dir',
default='../Tensorboard/Log-model_inversion-MNIST/{0}/'.format(date)
)
parser.add_argument('--batch_size', default=200, type=int)
parser.add_argument('--dim_initial_vec', default=100, type=int)
parser.add_argument('--epochs_target_model', default=100, type=int)
parser.add_argument('--epochs_gan', default=150, type=int)
parser.add_argument('--ngpu', default=1, type=int)
parser.add_argument('--devicen', default=1, type=int)
parser.add_argument('--training_flag', default=True, type=bool)
parser.add_argument('--train_model_dir')
args = parser.parse_args()
""" directories """
data_dir = args.data_dir
model_dir = args.model_dir
sample_dir = args.sample_dir
log_dir = args.log_dir
for directory in [data_dir, model_dir, sample_dir, log_dir]:
if not os.path.isdir(directory):
os.makedirs(directory)
""" parameters """
batch_size = args.batch_size
dim_initial_vec = args.dim_initial_vec
epochs_target_model = args.epochs_target_model
epochs_gan = args.epochs_gan
ngpu = args.ngpu
devicen = args.devicen
device = torch.device(
"cuda:{0}".format(
devicen) if (torch.cuda.is_available() and ngpu > 0) else "cpu"
)
# device = 'cuda:0'
training_flag = args.training_flag
"""
data loader
"""
""" define dataloader """
trainset = ImageFolder(
data_dir + 'train/',
transform=transforms.Compose([
transforms.Grayscale(num_output_channels=1),
transforms.ToTensor()
])
)
trainloader = torch.utils.data.DataLoader(trainset,
batch_size=batch_size,
shuffle=True,
num_workers=2
)
valset = ImageFolder(
data_dir + 'val/',
transform=transforms.Compose([
transforms.Grayscale(num_output_channels=1),
transforms.ToTensor()
])
)
valloader = torch.utils.data.DataLoader(valset,
batch_size=batch_size,
shuffle=True,
num_workers=2
)
testset = ImageFolder(
data_dir + 'test/',
transform=transforms.Compose([
transforms.Grayscale(num_output_channels=1),
transforms.ToTensor()
])
)
testloader = torch.utils.data.DataLoader(
testset,
batch_size=batch_size,
shuffle=True,
num_workers=2
)
攻撃対象モデル
攻撃対象となる学習データとモデルの部分を実装していきます.ターゲットモデル $f$ とその学習・評価用の関数を定義します.
import numpy as np
import torch
import torch.nn as nn
import tqdm
class TargetModel(nn.Module):
"""
train the classifier
"""
def __init__(self, base_channel=32):
self.base_channel = base_channel
super().__init__()
self.main = nn.Sequential(
nn.Conv2d(
in_channels=1, out_channels=self.base_channel, kernel_size=3
), # (base_cnahhel, 26, 26)
nn.Conv2d(
in_channels=self.base_channel,
out_channels=2*self.base_channel,
kernel_size=3
), # (2 * base_channel, 24, 24)
nn.MaxPool2d(
kernel_size=2, stride=2
), # (2 * base_channel, 12, 12)
nn.Dropout2d(),
bf.FlattenLayer(), # flatten
nn.Linear(
in_features=2*base_channel*12*12, out_features=4*base_channel
),
nn.Dropout2d(),
nn.Linear(in_features=4*base_channel, out_features=10)
)
def forward(self, x):
out = self.main(x)
return out
def train_target_model(
target_model,
train_loader,
eval_loader,
log_dir,
model_dir,
ngpu=1,
epochs_target_model=150,
device='cuda:0',
writer=None):
if (ngpu > 1):
target_model = nn.DataParallel(target_model, list(range(ngpu)))
optimiser_tm = torch.optim.Adam(target_model.parameters())
loss_f = nn.CrossEntropyLoss()
train_losses = []
train_acc = []
val_acc = []
for epoch in range(epochs_target_model):
running_loss = 0.0
target_model.train()
n = 0
n_acc = 0
for i, (x_tensor, y_tensor) in tqdm.tqdm(enumerate(train_loader)):
x_tensor = x_tensor.to(device) # (batch_size, h, w)
y_tensor = y_tensor.to(device) # (batch_size, label)
h_tensor = target_model(x_tensor) # (batch_size, label(predicted))
loss = loss_f(h_tensor, y_tensor)
optimiser_tm.zero_grad()
loss.backward()
optimiser_tm.step()
running_loss = loss.item()
n += len(x_tensor)
_, y_pred = h_tensor.max(1)
n_acc += (y_tensor == y_pred).float().sum().item()
# batch sizeで割って,1エポック分の平均損失を算出
train_losses.append(running_loss / i)
train_acc.append(n_acc / n)
val_acc.append(
eval_target_model(
target_model=target_model,
loader=eval_loader,
device=device
)
)
if writer is not None:
writer.add_scalars(
"Accuracy Loss of Target Model",
{'train': train_acc[-1], 'validation': val_acc[-1]},
epoch
)
""" preserve the taget model """
if (epoch == 0) or (val_acc[-1] > val_acc[-2]):
torch.save(
target_model.state_dict(),
model_dir + 'target-model-{0}.prm'.format(epoch),
pickle_protocol=4
)
def eval_target_model(target_model, loader, device="cuda:0"):
target_model.eval() # invalid the dropout and batchnormalisation
ys = []
ypreds = []
for x_tensor, y_tensor in loader:
x_tensor = x_tensor.to(device)
y_tensor = y_tensor.to(device)
with torch.no_grad():
# predict the class with the miximum of class probability
_, y_pred = target_model(x_tensor).max(1)
ys.append(y_tensor)
ypreds.append(y_pred)
ys = torch.cat(ys) # concat the label of each mini-batch
# tconcat the predicted label of each mini-batch
ypreds = torch.cat(ypreds)
""" evaluation """
acc = (ys == ypreds).float().sum() / len(ys)
return acc.item()
次に,上記で定義したクラスや関数を使ってターゲットモデル $f$ を学習する部分を書きます.
writer = SummaryWriter(log_dir)
if training_flag:
"""
training the target model
"""
target_model = bfm.TargetModel().to(device)
bfm.train_target_model(
target_model=target_model,
train_loader=trainloader,
eval_loader=valloader,
epochs_target_model=epochs_target_model,
log_dir=log_dir,
model_dir=model_dir,
writer=writer,
ngpu=ngpu,
device=device
)
else:
target_model = args.train_model_dir
ここまででターゲットモデルの学習に関する部分は終わりです.
Model Inversion部分
ここからはModel Inversion部分の実装に入ります.今回はModel InversionにConditional DCGANを使いますので,まずはそのGeneratorとDiscriminator部分を書きます.
class Generator(nn.Module):
def __init__(self, input_dim=100, base_channel=32):
self.input_dim = input_dim
self.base_channel = base_channel
super().__init__()
self.block1 = nn.Sequential(
nn.ConvTranspose2d(
in_channels=self.input_dim,
out_channels=self.base_channel, # number of output channel
kernel_size=4,
stride=1,
padding=0,
bias=False), # (base_channel, 4, 4)
nn.BatchNorm2d(num_features=self.base_channel),
nn.ReLU(inplace=True)
)
self.block2 = nn.Sequential(
nn.Linear(in_features=10, out_features=1000),
nn.ReLU(inplace=True)
)
self.concat_block = nn.Sequential(
nn.Linear(
in_features=self.base_channel*4*4 + 1000,
out_features=self.base_channel*4*4
)
)
self.main = nn.Sequential(
nn.ConvTranspose2d(
in_channels=self.base_channel,
out_channels=self.base_channel * 4,
kernel_size=3,
stride=2,
padding=1,
bias=False
), # (base_channel * 4, 7, 7)
nn.BatchNorm2d(num_features=self.base_channel * 4),
nn.ReLU(inplace=True),
nn.ConvTranspose2d(
in_channels=self.base_channel * 4,
out_channels=self.base_channel * 2,
kernel_size=4,
stride=2,
padding=1,
bias=False
), # (base_channel * 2, 14, 14)
nn.BatchNorm2d(num_features=self.base_channel * 2),
nn.ReLU(inplace=True),
nn.ConvTranspose2d(
in_channels=self.base_channel * 2,
out_channels=1,
kernel_size=4,
stride=2,
padding=1,
bias=False
), # (base_channel * 2, 28, 28)
nn.Tanh()
)
def forward(self, x, label_vec):
x = self.block1(x)
x = x.view(x.size(0), -1)
label_vec = label_vec.view(x.size(0), -1)
label_vec = self.block2(label_vec)
x = torch.cat([x, label_vec], dim=1)
x = self.concat_block(x)
x = x.view((x.size(0), self.base_channel, 4, 4))
out = self.main(x)
return out
class Discriminator(nn.Module):
def __init__(self, base_channel=32):
self.base_channel = base_channel
super().__init__()
self.block1 = nn.Sequential(
nn.Conv2d(
in_channels=1,
out_channels=self.base_channel,
kernel_size=4,
stride=2,
padding=1,
bias=False
), # (base_channel, 14, 14)
nn.LeakyReLU(negative_slope=0.2, inplace=True),
)
self.block2 = nn.Sequential(
nn.Linear(in_features=10, out_features=1000),
nn.ReLU(inplace=True)
)
self.concat_block = nn.Sequential(
nn.Linear(in_features=1*32*14*14 + 1000, out_features=1*32*14*14)
)
self.main = nn.Sequential(
nn.Conv2d(
in_channels=self.base_channel,
out_channels=self.base_channel * 2,
kernel_size=4,
stride=2,
padding=1,
bias=False
), # (base_channel, 7, 7)
nn.BatchNorm2d(num_features=self.base_channel * 2),
nn.LeakyReLU(negative_slope=0.2, inplace=True),
nn.Conv2d(
in_channels=self.base_channel * 2,
out_channels=self.base_channel * 4,
kernel_size=4,
stride=2,
padding=1,
bias=False
), # (base_channel * 2, 3, 3)
nn.BatchNorm2d(num_features=self.base_channel * 4),
nn.LeakyReLU(negative_slope=0.2, inplace=True),
nn.Conv2d(
in_channels=self.base_channel * 4,
out_channels=1,
kernel_size=4,
stride=2,
padding=1,
bias=False
) # (base_channel * 8, 1, 1)
)
def forward(self, x, label_vec):
x = self.block1(x)
x = x.view(x.size(0), -1)
label_vec = label_vec.view(x.size(0), -1)
label_vec = self.block2(label_vec)
x = torch.cat([x, label_vec], dim=1)
x = self.concat_block(x)
x = x.view(x.size(0), self.base_channel, 14, 14)
out = self.main(x)
return out.squeeze()
次に,Conditional DCGANの学習用関数の部分です.
def train_model_inversion(
g, d, target_model, opt_g, opt_d, loss_f, loader, device, nz=100):
"""
For the training DCGAN
args:
g: generator
d: discriminator
target_model: trained target model (attacked)
opt_g: optimisation method of discriminator
opt_d: optimisation method of discriminator
loss_f: loss function
loader: data loader defined by pytorch's DataLoader
nz: dimension of the hidden feature vector
"""
# liset for watching the objective function of generator and discriminater
log_loss_g = []
log_loss_d = []
cnt_iter = 1
batch_size = loader.batch_size
ones = torch.ones(batch_size).to(device)
zeros = torch.zeros(batch_size).to(device)
g.train()
d.train()
for real_img, _ in tqdm.tqdm(loader):
"""
train the discriminator: maximise log(D(x)) + log(1-D(G(z)))
"""
batch_len = len(real_img)
real_img = real_img.to(device) # to GPU device
""" train the discriminator """
''' for real image '''
with torch.no_grad():
real_label = target_model(real_img).max(1)[1]
real_label_vec = bf.onehot_encode(real_label, device=device)
real_out = d(real_img, real_label_vec)
if cnt_iter < 50:
loss_d_real = loss_f(
real_out, torch.rand(batch_len, device=device)
)
else:
loss_d_real = loss_f(real_out, ones[: batch_len])
''' for fake image '''
z = torch.randn(batch_len, nz, 1, 1).to(device)
with torch.no_grad():
# predict the class with the miximum of class probability
target_label = target_model(real_img).max(1)[1]
label_vector = bf.onehot_encode(target_label, device=device)
fake_img = g(z, label_vector)
with torch.no_grad():
fake_label = target_model(fake_img).max(1)[1]
fake_label_vec = bf.onehot_encode(fake_label, device=device)
fake_out = d(fake_img, fake_label_vec)
loss_d_fake = loss_f(fake_out, zeros[: batch_len])
""" sum of loss: real and fake """
loss_d = loss_d_real + loss_d_fake
log_loss_d.append(loss_d.item())
""" update the parameters """
if cnt_iter % 2 == 0:
opt_g.zero_grad()
opt_d.zero_grad()
loss_d.backward()
opt_d.step()
""" train the generator """
with torch.no_grad():
# predict the class with the miximum of class probability
target_label = target_model(real_img).max(1)[1]
z = torch.randn(batch_len, nz, 1, 1).to(device)
label_vector = bf.onehot_encode(target_label, device=device)
fake_img = g(z, label_vector)
with torch.no_grad():
fake_label = target_model(fake_img).max(1)[1]
fake_label_vec = bf.onehot_encode(fake_label, device=device)
out = d(fake_img, fake_label_vec).view(-1)
loss_g = loss_f(out, ones[: batch_len])
log_loss_g.append(loss_g.item())
""" update gradient """
opt_d.zero_grad()
opt_g.zero_grad()
loss_g.backward()
opt_g.step()
# update iteration counter
cnt_iter += 1
log_loss_g = torch.tensor(log_loss_g)
log_loss_d = torch.tensor(log_loss_d)
return torch.mean(log_loss_g), torch.mean(log_loss_d)
def model_inversion(
g, d, target_model, model_dir, sample_dir, testloader, dim_initial_vec, epochs_gan=300, device='cuda:0', ngpu=1, writer=True):
"""
train the GAN
"""
""" Define networks """
if (device.type == 'cuda') and (ngpu > 1):
g = nn.DataParallel(g, list(range(ngpu)))
d = Discriminator().to(device)
# optimiser for discriminator
opt_d = torch.optim.Adam(d.parameters(), lr=0.0004, betas=(0.0, 0.9))
# optimiser for generator
opt_g = torch.optim.Adam(g.parameters(), lr=0.0001, betas=(0.5, 0.9))
# loss function
loss_f = nn.BCEWithLogitsLoss(reduction='mean')
""" for visualise the results """
z = torch.randn([10, 100, 1, 1], device=device)
label_vecs = torch.tensor(
np.diag(np.ones(10)), dtype=torch.float32, device=device
)
for epoch in range(epochs_gan):
loss_g, loss_d = train_model_inversion(
target_model=target_model,
g=g,
d=d,
opt_g=opt_g,
opt_d=opt_d,
loss_f=loss_f,
loader=testloader,
device=device,
nz=dim_initial_vec
)
""" preserve the log for tensorboard """
if writer is not None:
writer.add_scalars(
'LogLoss',
{'generator': loss_g,
'discriminator': loss_d},
epoch
)
"""
preserve the results
"""
with torch.no_grad():
results = g(z, label_vecs)
results = results.detach().cpu().numpy().reshape(10, 28, 28)
for i in range(10):
plt.subplot(2, 5, i+1)
plt.imshow(bf.min_max(results[i, :, :]), 'gray')
plt.savefig(sample_dir + "{:03d}.jpg".format(epoch))
if epoch % 10 == 0:
torch.save(
g.state_dict(),
model_dir + "g_{:03d}.prm".format(epoch),
pickle_protocol=4
)
torch.save(
d.state_dict(),
model_dir + "d_{:03d}.prm".format(epoch),
pickle_protocol=4
)
最後に,実際に学習する部分を書きます.
"""
model iversion
"""
g = bfm.Generator(input_dim=dim_initial_vec).to(device)
if (device.type == 'cuda') and (ngpu > 1):
g = nn.DataParallel(g, list(range(ngpu)))
d = bfm.Discriminator().to(device)
bfm.model_inversion(
g=g,
d=d,
target_model=target_model,
model_dir=model_dir,
sample_dir=sample_dir,
testloader=testloader,
dim_initial_vec=dim_initial_vec,
epochs_gan=epochs_gan,
writer=writer,
device=device
)
結果
Conditional DCGANによるModel Inversionを150エポック回したときの結果が下図になります.正直なところ,ほとんどConditionの制御が出来てないですね.Model InversionではAPIを介して獲得した $f(\boldsymbol{x})$ をGeneratorとDiscriminatorに入力するcondition部分に利用しますが,そこがあまり「正しいラベル」を出せていないのでしょうね.

まとめ
今回の記事では,機械学習で構築したモデルそのものに対する攻撃をいくつか紹介し,その中の1つであるModel Inversionを実際に試してみました.その結果,あまり正確に学習データを復元することは出来ませんでしたが,ぼんやりと学習データらしきものが生成されました.また,今後さらにGANの技術が進歩していくことが予想されるため,Model Inversion自体の性能も上がっていくかもしれませんね.
最後にヒトコト
どうしても声を大にしていっておきたい事があります.それは,「セキュリティ上のリスクがあるからAIは危険だ!使うのをやめるべきだ!」とはならないで欲しいという事です.
確かに,機械学習で構築したモデルには,今回紹介したようなセキュリティ上のリスクがあることが指摘されてはいます.その一方で,機械学習を利用したサービスは,人々の生活を助け,社会をより便利にしていく事は確かです.このような技術革新の流れを止めてはいけないと私は考えています.ですから,「リスクがあるものを使うのはやめるべきだ!」ではなく,「リスクを出来るだけ抑えたサービスを提供するにはどうすればよいのか?」という考え方をして頂きたいと思っています.
また,私も企業研究者として「えーあい」の社会実装に向けて,この「どうすればよいのか?」という課題のSolutionとなるような技術の研究開発に取り組んでいかなければならないと思っています.
最後にカッコイイ感じのポエムも書いたことですし,これぐらいで締めたいと思います.
ここまで御覧いただき,ありがとうございました!
参考文献
Goodfellow, I. J., Shlens, J., & Szegedy, C. (2014). Explaining and harnessing adversarial examples. arXiv preprint arXiv:1412.6572.
Eykholt, K., Evtimov, I., Fernandes, E., Li, B., Rahmati, A., Xiao, C., ... & Song, D. (2018). Robust physical-world attacks on deep learning visual classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 1625-1634).
Fredrikson, M., Jha, S., & Ristenpart, T. (2015, October). Model inversion attacks that exploit confidence information and basic countermeasures. In Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security (pp. 1322-1333). ACM.
Tramèr, F., Zhang, F., Juels, A., Reiter, M. K., & Ristenpart, T. (2016). Stealing machine learning models via prediction apis. In 25th USENIX Security Symposium (USENIX Security 16) (pp. 601-618).
Kusano, K., Sakuma, J. (2018). Classifier-to-Generator Attack: Estimation of Training Data Distribution from Classifier. https://openreview.net/forum?id=SJOl4DlCZ