はじめに
こんにちは、NTTドコモ サービスイノベーション部の春山です。
本記事は、NTTドコモR&D Advent Calendar 2021の19日目の記事です。
普段の業務では、サッカー、野球などのスポーツAIの開発・運用に携わっております。
さらに、趣味はサッカー観戦、ということで普段から頭の中はサッカーのことでいっぱいです。
今回はタイトルにもある通り、簡単なデータ分析でサッカー欧州5大リーグの優勝チームを予測してみます。
完全に私欲を満たすための記事ですが、お付き合いいただけたらと思います。

サッカーについて
今回分析対象となる欧州5大リーグとは、下表の国(左列)に属するサッカーリーグ(右列)のことを指します。
| 国 | リーグ名 |
|---|---|
| イングランド | English Premier League |
| スペイン | Spain Primera Division |
| イタリア | Italian Serie A |
| ドイツ | German 1. Bundesliga |
| フランス | French Ligue 1 |
この欧州5大リーグはサッカーのレベルが世界トップであり、優秀な選手が世界各国から集まってきます。
スタジアムやサポーターの規模も尋常ではなく、大きな経済効果も生み出しているリーグです。
誰もが知っている(であろう)メッシ選手やクリスティアーノ・ロナウド選手も欧州5大リーグでプレーしています。
今回は、データ分析手法の基本である回帰モデルを使って、リーグの優勝チーム(順位)を予測してみたいと思います。
データセット
分析対象となるデータはKaggleに公開されているFIFA 22 complete player datasetです。
今回はコンペで戦うわけでは無いのですが、コンペで戦う際にはこちらのページ(Kaggleに登録したら次にやること ~これだけやれば十分闘える!Titanicの先へ行く入門 10 Kernel~)が大変参考になります。
FIFA 22 complete player datasetには、世界中のリーグの2014-2015シーズンから2021-2022シーズンに所属した選手のデータが格納されています。
players_15.csv
players_16.csv
players_17.csv
players_18.csv
players_19.csv
players_20.csv
players_21.csv
players_22.csv
まずはデータの中を下記コードで覗いてみます。
一番最近の2021-2022シーズンのデータにあたるplayers_22.csvを見てみます。
import pandas as pd
seasons = ["15","16","17","18","19","20","21","22"]
# データフレームを読み込み
for season in seasons:
exec("df_{} = pd.read_csv('./players_{}.csv')".format(season, season))
# データフレームのサイズを表示
print(df_22.shape)
# データフレームの1行目を表示
print(df_22.iloc[0])
出力結果↓↓
100%|██████████████████████████████████████████████████████████████████████| 8/8 [00:03<00:00, 2.59it/s]
(19239, 107)
sofifa_id 158023
player_url https://sofifa.com/player/158023/lionel-messi/...
short_name L. Messi
long_name Lionel Andrés Messi Cuccittini
player_positions RW, ST, CF ★
overall 93 ★
potential 93 ★
value_eur 78000000 ★
wage_eur 320000
age 34 ★
dob 1987-06-24
height_cm 170 ★
weight_kg 72 ★
club_name Paris Saint-Germain ★
league_name French Ligue 1 ★
league_level 1.0
club_position RW
club_jersey_number 30.0
club_loaned_from NaN
club_joined 2021-08-10 ★
club_contract_valid_until 2023.0
nationality Argentina
nation_position RW
nation_jersey_number 10.0
preferred_foot Left
weak_foot 4 ★
skill_moves 4 ★
international_reputation 5 ★
work_rate Medium/Low
body_type Unique
real_face Yes
release_clause_eur 144300000.0
player_tags #Dribbler, #Distance Shooter, #FK Specialist, ...
player_traits Finesse Shot, Long Shot Taker (AI), Playmaker ...
pace 85.0 ★
shooting 92.0 ★
passing 91.0 ★
dribbling 95.0 ★
defending 34.0 ★
physic 65.0 ★
attacking_crossing 85 ★
attacking_finishing 95 ★
attacking_heading_accuracy 70 ★
attacking_short_passing 91 ★
attacking_volleys 88 ★
skill_dribbling 96 ★
skill_curve 93 ★
skill_fk_accuracy 94 ★
skill_long_passing 91 ★
skill_ball_control 96 ★
movement_acceleration 91 ★
movement_sprint_speed 80 ★
movement_agility 91 ★
movement_reactions 94 ★
movement_balance 95 ★
power_shot_power 86 ★
power_jumping 68 ★
power_stamina 72 ★
power_strength 69 ★
power_long_shots 94 ★
mentality_aggression 44 ★
mentality_interceptions 40 ★
mentality_positioning 93 ★
mentality_vision 95 ★
mentality_penalties 75 ★
mentality_composure 96 ★
defending_marking_awareness 20 ★
defending_standing_tackle 35 ★
defending_sliding_tackle 24 ★
goalkeeping_diving 6 ★
goalkeeping_handling 11 ★
goalkeeping_kicking 15 ★
goalkeeping_positioning 14 ★
goalkeeping_reflexes 8 ★
goalkeeping_speed NaN ★
ls 89+3 ★
st 89+3 ★
rs 89+3 ★
lw 92 ★
lf 93 ★
cf 93 ★
rf 93 ★
rw 92 ★
lam 93 ★
cam 93 ★
ram 93 ★
lm 91+2 ★
lcm 87+3 ★
cm 87+3 ★
rcm 87+3 ★
rm 91+2 ★
lwb 66+3 ★
ldm 64+3 ★
cdm 64+3 ★
rdm 64+3 ★
rwb 66+3 ★
lb 61+3 ★
lcb 50+3 ★
cb 50+3 ★
rcb 50+3 ★
rb 61+3 ★
gk 19+3 ★
player_face_url https://cdn.sofifa.com/players/158/023/22_120.png
club_logo_url https://cdn.sofifa.com/teams/73/60.png
club_flag_url https://cdn.sofifa.com/flags/fr.png
nation_logo_url https://cdn.sofifa.com/teams/1369/60.png
nation_flag_url https://cdn.sofifa.com/flags/ar.png
Name: 0, dtype: object
出力結果から分かるように、players_22.csvには19239人分の選手に対する107項目のデータが格納されています。short_name(名前)、player_face_url(顔画像のURL)、などの選手のプロフィールに関する情報、shooting、skill_dribblingなどの選手の能力に関する情報が格納されていました。
今回は、この中からデータ分析に使えそうなデータをいくつか抽出します。
具体的に書き出すと長くなるので、上で★マークになっている項目をそのままもしくは加工して利用します。
全選手Top5
overallは選手の総合能力値を表します。2014-2015シーズンから2021-2022シーズンの全選手Top5を見てみましょう。
| 2014-2015 | 2015-2016 | 2016-2017 | 2017-2018 | 2018-2019 | 2019-2020 | 2020-2021 | 2021-2022 | |
|---|---|---|---|---|---|---|---|---|
| 1位 | L. Messi | L. Messi | Cristiano Ronaldo | Cristiano Ronaldo | Cristiano Ronaldo | L. Messi | L. Messi | L. Messi |
| 2位 | Cristiano Ronaldo | Cristiano Ronaldo | L. Messi | L. Messi | L. Messi | Cristiano Ronaldo | Cristiano Ronaldo | R. Lewandowski |
| 3位 | A. Robben | A. Robben | M. Neuer | M. Neuer | Neymar | Neymar Jr | R. Lewandowski | Cristiano Ronaldo |
| 4位 | Z. Ibrahimović | M. Neuer | L. Suárez | L. Suárez | Sergio Ramos | E. Hazard | Neymar | Neymar |
| 5位 | M. Neuer | L. Suárez | Neymar | Neymar | L. Suárez | K. De Bruyne | K. De Bruyne | K. De Bruyne |
これを見ると、メッシ選手とクリスティアーノ・ロナウド選手がずっとTop3に入っています。
彼らが近年のサッカー界を引っ張ってきたことが一目瞭然でした。

日本人選手Top5
次に2014-2015シーズンから2021-2022シーズンの日本人選手Top5を見てみましょう。
| 2014-2015 | 2015-2016 | 2016-2017 | 2017-2018 | 2018-2019 | 2019-2020 | 2020-2021 | 2021-2022 | |
|---|---|---|---|---|---|---|---|---|
| 1位 | S. Kagawa | S. Kagawa | S. Kagawa | S. Kagawa | S. Kagawa | M. Hasebe | T. Inui | D. Kamada |
| 2位 | K. Honda | S. Okazaki | K. Honda | T. Inui | T. Inui | T. Inui | H. Sakai | W. Endo |
| 3位 | S. Okazaki | K. Honda | H. Kiyotake | K. Honda | K. Honda | S. Nakajima | T. Minamino | M. Hasebe |
| 4位 | Y. Nagatomo | A. Uchida | T. Usami | M. Hasebe | H. Sakai | S. Kagawa | S. Nakajima | S. Nakajima |
| 5位 | H. Hosogai | H. Kiyotake | S. Okazaki | Y. Ōsako | M. Hasebe | H. Sakai | M. Hasebe | J. Ito |
これを見ると、香川真司選手が日本代表を引っ張っていたことがわかります。
ここ2,3年で世代交代が起きているように思えます。リヴァプールに所属する南野選手やヘンクに所属する伊東純也がランクインしてきています。

各項目の相関係数
続いては、各項目の相関係数を見てみます。総合能力値であるoverallとの相関係数が高いものを見てみます。これを見ることでどの能力値が選手の完成度に寄与しているかわかります。
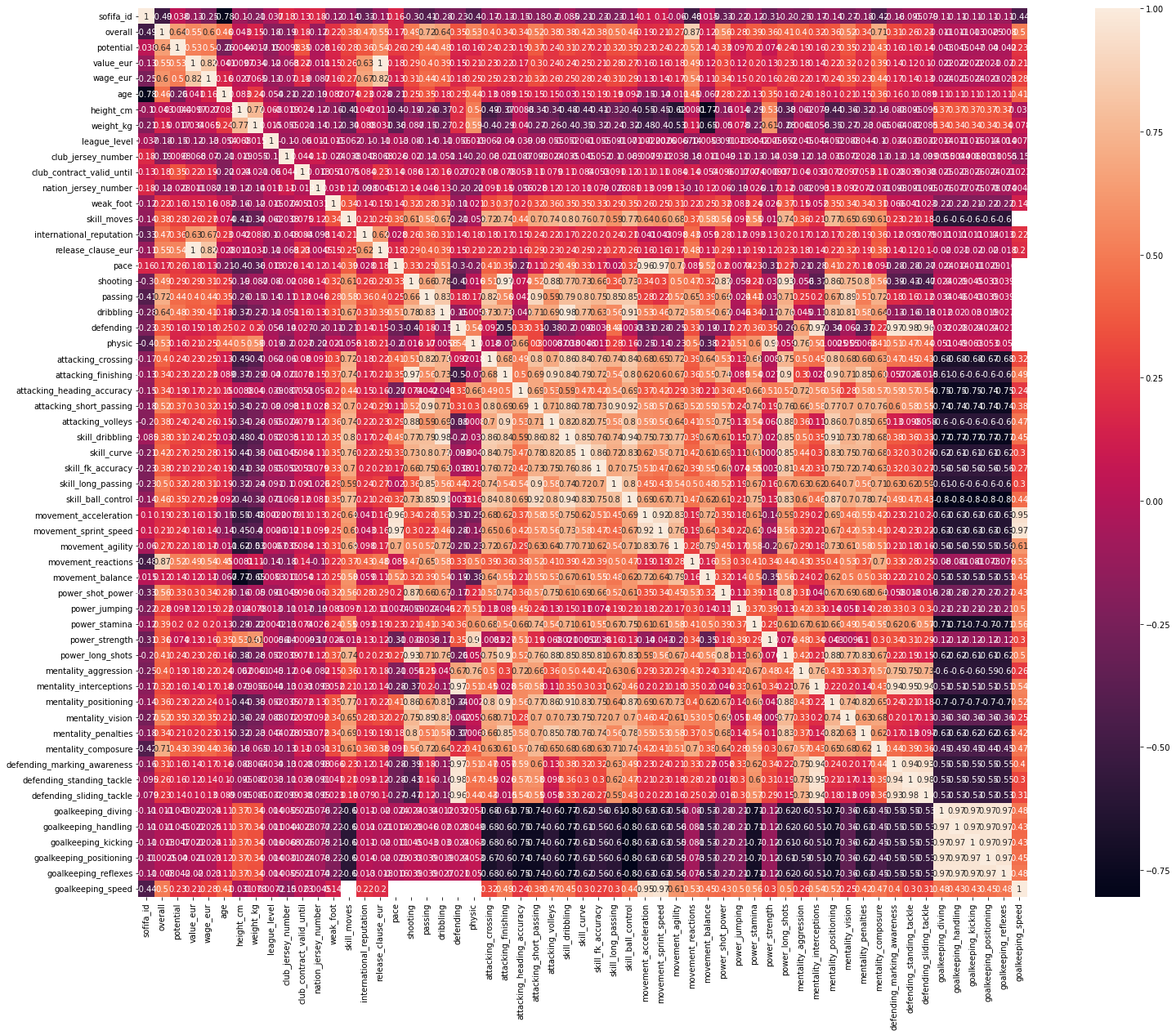
overallとの相関係数が高いのは、movements_reactions、passing、menatrity_composureあたりでした。各項目の詳細については非公表でしたが、ボールへのリアクション速度やパス精度、精神面の落ち着きと予想され、それらが重要だということがわかりました。
体格やパワーよりもプレーの正確性が重要なのは、恵まれた体格ではなくても一流選手になれる証拠で、僕もまだ夢を諦めずに頑張ろうと思わされました。
欧州5大リーグの優勝チーム(順位)予測
それでは、本題の欧州5大リーグの優勝チーム(順位)予測をしていきます。
正解データとなる順位に関しては、ダウンロード可能なデータとして公開されていなかったため、自分でcsvファイルを作成しました(これがかなり大変でした…)。
本当は全リーグの順位予測をしたかったのですが、この作業が思った以上に大変だったため欧州5大リーグに絞ってデータ分析を行っていきます。
具体的には、columnの1つであるleague_nameを以下のコードで{English Premier League、Spain Primera Division、Italian Serie A、German 1. Bundesliga、French Ligue 1}に限定します。
データ前処理
まずは、欠損データを補完するために、NaNデータをそのcolumn(特徴量)の平均値で埋めます。
leagues = ["Spain Primera Division", "English Premier League", "Italian Serie A", "German 1. Bundesliga", "French Ligue 1"]
# NaNデータを平均値で補完
for season in seasons:
exec("df_{} = df_{}.fillna(df_{}.mean())".format(season, season, season))
次に、各特徴量に含まれるstr型のデータを計算可能なint型に変換します。
1つ目は、player_positionsです。
この特徴量には、DFやFWなど、その選手が対応可能なポジションがstr型として格納されています。
今回は、その値をその選手が対応可能なポジション数としてint型に変換します。
# player_positionを対応可能なポジション数に変換する
for season in seasons:
exec("Num = len(df_{})".format(season))
for i in range(Num):
exec("df_{}.iloc[i, 0] = len(df_{}.iloc[i, 0].split(','))".format(season, season))
2つ目は、club_joinedです。
この特徴量には、その選手がクラブに加入した日にちがstr型として格納されています。
今回は、その値を選手がクラブに加入してから経った日数としてint型に変換します。
# club_joinedをクラブに加入してから経った日数に変換する
for season in seasons:
exec("Num = len(df_{})".format(season))
for i in range(Num):
exec("df_{}.iloc[i, 7] = (datetime.strptime('20{}-07-01', '%Y-%m-%d') - datetime.strptime(df_{}.iloc[i, 7], '%Y-%m-%d')).days".format(season, season, season))
さらに、この後行う分析のために、df_{シーズン年度}_{リーグ名}となるようにデータフレームを分解します。
各データフレームにはそのシーズン年度のそのリーグの選手データが格納されます。
# シーズン、リーグごとにデータフレームを作成
for season in seasons:
for league in leagues:
exec("df_{}_{} = df_{}[df_{}['league_name']=='{}']".format(season, league.split(" ")[0], season, season, league))
説明のために詳細な処理は省いているところもありますが、ここまでで前処理は終了です。
選手ごとの情報からチームごとの情報への変換
今回の目的はチームの順位を予測することなので、レコード単位は選手ではなくチームとなります。
そのため、そのチームに所属する選手全員の値を1レコードに集約する必要があります。
今回は難しいことは考えず、選手たちの各特徴量の値を平均することにします。
また、リーグ内の順位予測ということなのでリーグによってばらつきが出ないようにリーグごとに正規化処理を行います。
本来であればリーグごとの特性を考慮できればよいのですが、今回は手を付けずに考えます。
レコード単位をチームにする処理と正規化処理は以下のコードで行いました。
# 正規化の関数定義
from sklearn import preprocessing
for season in seasons:
for league in leagues:
exec("df_{}_{}_str = df_{}_{}[['club_name', 'league_name']]".format(season, league.split(" ")[0], season, league.split(" ")[0]))
exec("df_{}_{}_str = df_{}_{}_str.reset_index()".format(season, league.split(" ")[0], season, league.split(" ")[0]))
exec("df_{}_{}_str['index'] = df_{}_{}_str.index".format(season, league.split(" ")[0], season, league.split(" ")[0]))
exec("df_{}_{}_str.set_index('index',inplace=True)".format(season, league.split(" ")[0]))
exec("df_{}_{}_int= df_{}_{}.drop(['club_name', 'league_name'], axis=1)".format(season, league.split(" ")[0], season, league.split(" ")[0]))
exec("df_{}_{}_int = df_{}_{}_int.reset_index()".format(season, league.split(" ")[0], season, league.split(" ")[0]))
exec("df_{}_{}_int['index'] = df_{}_{}_int.index".format(season, league.split(" ")[0], season, league.split(" ")[0]))
exec("df_{}_{}_int.set_index('index',inplace=True)".format(season, league.split(" ")[0]))
exec("df_{}_{}_scaled = seikika(df_{}_{}_int, 'index', df_{}_{}_int.columns.values)".format(season, league.split(" ")[0], season, league.split(" ")[0], season, league.split(" ")[0]))
exec("df_{}_{}_scaled = pd.merge(df_{}_{}_str, df_{}_{}_scaled, on='index')".format(season, league.split(" ")[0], season, league.split(" ")[0], season, league.split(" ")[0]))
## チームごとに平均を出す
for season in seasons:
for league in leagues:
exec("uniques = df_{}_{}_scaled['club_name'].unique()".format(season, league.split(" ")[0]))
exec("df_{}_{}_scaled_columns = df_{}_{}_scaled.drop(columns=['club_name', 'league_name'])".format(season, league.split(" ")[0], season, league.split(" ")[0]))
exec("columns = df_{}_{}_scaled_columns.columns.values".format(season, league.split(" ")[0]))
exec("df_{}_{}_scaled_mean = pd.DataFrame(index=uniques, columns=columns)".format(season, league.split(" ")[0]))
for unique in uniques:
for column in columns:
exec("tmp_club = df_{}_{}_scaled[df_{}_{}_scaled['club_name'] == '{}'].mean()".format(season, league.split(" ")[0], season, league.split(" ")[0], unique))
exec("tmp_league = df_{}_{}_scaled[df_{}_{}_scaled['league_name'] == '{}'].mean()".format(season, league.split(" ")[0], season, league.split(" ")[0], league))
exec("df_{}_{}_scaled_mean.at['{}', '{}'] = tmp_club['{}']".format(season, league.split(" ")[0], unique, column, column))
exec("df_{}_{}_scaled_mean.at['{}', 'club_name'] = '{}'".format(season, league.split(" ")[0], unique, unique))
exec("df_{}_{}_scaled_mean.at['{}', 'league_name'] = '{}'".format(season, league.split(" ")[0], unique, league))
さらに、最初に作成した欧州5大リーグの順位データ(大変だったやつ)を新しいcolumn ["rank"]としてデータフレームに追加します。
以上の処理で、df_{シーズン年度}_{リーグ名}_mean_scaledに各シーズンの各リーグ、それが選手ごとに平均化されて、さらに正規化されたデータが格納されます。
予測モデル(回帰)の作成
順位を正解データとして回帰モデルを学習することで順位の予測モデルを作成していきます。
まずは、下記コードで学習データとテストデータに分割します。
2014-2015シーズンから2018-2019シーズンを学習データにし、2019-2020シーズンと2020-2021シーズンをテストデータにします。
2021-2022シーズンは絶賛オンシーズンなので評価には用いません(用いることができません)。
## 学習データとテストデータに分ける(今回は2015~2019を学習、2020~2021をテスト)
df_train = pd.DataFrame(index=[], columns=columns)
df_test = pd.DataFrame(index=[], columns=columns)
for season in tqdm(seasons):
for league in leagues:
if season in ("15", "16", "17", "18", "19"):
exec("df_train = pd.concat([df_train_scaled, df_{}_{}_scaled_mean])".format(season, league.split(" ")[0]))
elif season in ("20", "21"):
exec("df_test = pd.concat([df_test_scaled, df_{}_{}_scaled_mean])".format(season, league.split(" ")[0]))
続いて、学習データを目的変数と説明変数に分けます。
ここで、["club_name"]と["league_name"]は今までチーム名やリーグ名を振り分けるために使っていたstr型の値であるため学習には用いません。
ですので、目的変数を作成する際に["rank"]と一緒に省いておきます。
# 目的変数と説明変数に分ける
data_train_X = df_train.drop(['club_name', 'league_name', 'rank'], axis=1)
data_test_X = df_test.drop(['club_name', 'league_name', 'rank'], axis=1)
data_train_y = df_train['rank']
data_test_y = df_test['rank']
ようやく、モデルの学習です。
今回は基本的な回帰モデルとしてRandomForestRegressor、GradientBoostingRegressor、LGBMRegressor、SVRで検証を行えるようなコードを書いています。
from sklearn.ensemble import RandomForestRegressor
from sklearn.ensemble import GradientBoostingRegressor
from lightgbm import LGBMRegressor
from sklearn.svm import SVR
from sklearn.metrics import mean_squared_error
# モデル定義
model_name = "RandomForestRegressor"
# model_name = GradientBoostingRegressor
# model_name = LGBMRegressor
# model_name = SVR
exec("model = {}()".format(model_name))
# 学習
if model_name == "LGBMRegressor":
model.fit(data_train_scaled_X.values, data_train_y.values, eval_metric='rmse')
else:
model.fit(data_train_scaled_X, data_train_y)
# 回帰
pred_y = model.predict(data_test_scaled_X)
# 評価
rmse = np.sqrt(mean_squared_error(data_test_y, pred_y))
print("RMSE : %.3f" % rmse)
モデル評価
今回はRMSEを評価指標としていますが、4つのモデルでの評価結果は以下となりました。
| | RandomForestRegressor | GradientBoostingRegressor | LGBMRegressor | SVR |
|:-------------|:-----------------|:------------------|:-----------------|:------------------|:-----------------|
|RMSE|3.583|3.755|3.800|3.640|
そもそもいい数値ではないのですが、1番精度が高いのはRandomForestRegressorとなりました。
学習したRandomForestRegressorモデルにテストデータを適用した結果を散布図をプロットしてみます。
import matplotlib.pyplot as plt
import seaborn as sns
import japanize_matplotlib
# 散布図を描画(真値 vs 予測値)
plt.plot(data_test_y, data_test_y, color = 'red', label = 'x=y')
plt.scatter(data_test_y, pred_y)
plt.xlabel('正解順位')
plt.ylabel('予測順位')
plt.title('散布図')
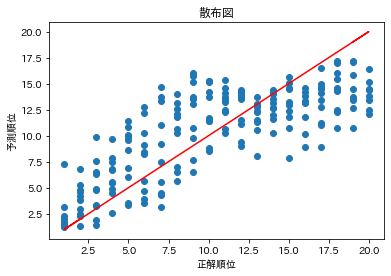
横軸に正解順位、縦軸に予測順位としています。
この散布図からは、順位の傾向は大方掴めているように伺えます。
特徴量の重要度算出
学習モデル(model)がどの特徴量を重要としているかの定量化を可能とするmodel.feture_importances_を可視化します。
# 説明変数の重要度をデータフレーム化
fea_rf_imp = pd.DataFrame({'imp': model.feature_importances_, 'col': data_train_X.columns})
fea_rf_imp = fea_rf_imp.sort_values(by='imp', ascending=False)
# 重要度を可視化
plt.figure(figsize=(20, 12))
sns.barplot('imp','col',data=fea_rf_imp,orient='h')
plt.title('Feature Importance',fontsize=28)
plt.ylabel('Features',fontsize=10)
plt.xlabel('Importance',fontsize=10)

上の結果から上位5位の特徴量を以下にまとめました。説明は非公開のため、あくまで予測になります。
| 項目名 | 説明 | |
|---|---|---|
| 1位 | value_eur | 市場価値 |
| 2位 | potential | 選手の潜在能力 |
| 3位 | international_reputation | 母国のFIFAランク |
| 4位 | dribbling | ドリブルスキル |
| 5位 | skill_moves | スキルレベル |
上の結果からは、重要度はvalue_eurが圧倒的に高いということがわかりました。
value_eurは選手の市場価値を表します。なんとも残酷なことに、お金がかなり重要いうということがわかってしまいました。
2番目に重要なのはpotentialでした。これは、FIFAが選手の潜在能力を評価した値です。妥当な結果だと考えられます。
3番目に重要なのはinternational_reputationでした。これは母国のFIFAランクです。
おそらくFIFAランクの高い国から選手を集めているチームは順位が高くなっているのでしょう。これも妥当な結果だと考えられます。
4番目に重要なのはdribblingでした。リーグで良い順位でフィニッシュするにはゴールを決めなくてはなりません。
そのゴールのためにはドリブルが必要不可欠です。English Premier Leagueに所属する選手でdribblingが高い選手は、ジョルダン・サンチョ、ベルナルド・シウバ、サディオ・マネなどトップチームのドリブラーでした。
5番目に重要なのはskill_movesでした。これは、シザースフェイントやルーレット、エラシコといったテクニックが必要なスキルレベルを表す数字です。Spain Primera Divisionに所属する選手でskill_movesが最大値を示す選手は、マルセロ、コウチーニョ、ジョアンフェリックスなどテクニシャンばかりでした。やはりこのようなテクニシャンが多いチームは局面を打開できますし、個人技での得点も増えるためリーグでの高順位が保たれているのかもしれません。
2021-2022シーズン 優勝チーム予測
絶賛オンシーズン中の2021-2022シーズンの優勝チーム予測をしてみます。
学習データを2014-2015シーズン~2020-2021シーズンとして、テストデータを2021-2022シーズンとします。
1位~5位と予測されたチームは以下のようになりました。
| | Spain Primera Division | English Premier League | Italian Serie A | German 1. Bundesliga | French Ligue 1 |
|:-------------|:-------------|:-----------------|:------------------|:-----------------|:------------------|:-----------------|
| 1位 | Real Madrid CF | Manchester City | Juventus | FC Bayern München | Paris Saint-Germain |
| 2位 | FC Barcelona | Manchester United | Inter | Borussia Dortmund | AS Monaco |
| 3位 | Atlético de Madrid | Liverpool | AC Milan | RB Leipzig | Olympique Lyonnais |
| 4位 | Real Sociedad | Chelsea | Napoli | VfL Wolfsburg | LOSC Lille |
| 5位 | Sevilla FC | Tottenham Hotspur | Atalanta | Bayer 04 Leverkusen | Stade Rennais FC |
以上のように予測できました。現在(12/06時点)でのリーグ1位チームはItalian Serie A以外で的中しています!
もちろん5位~最下位までの予測も行っていますので、シーズン終了の5月末予測結果がどの程度正しかったかを確認したいと思います。
まとめ
今回は、簡単なデータ分析でサッカー欧州5大リーグの優勝チーム(順位)を予測してみました。
リーグで上位の成績を残すためにはお金が一番大切という現実もデータ分析からわかりました。
ただ、予測精度がそこまで高くないことからも、番狂わせが起こっていることも伺えます。
これがサッカー観戦の醍醐味でもあるため、本当は予測精度は低い方が良いのかもしれません。
ですが今後は、リーグごとの特性を考慮したり、特徴選択を詳細に行ったりして、より性能の高い予測モデルを作成していきたいと思います。
参考文献
・Kaggleに登録したら次にやること ~これだけやれば十分闘える!Titanicの先へ行く入門 10 Kernel~
※本記事内の画像はFlickerから「All creative commons」のものを拝借いたしました。