はじめに
前回投稿では、2次元データ分布状態をカーネル密度推定に基づきコンターにより図化したが、コンター線を引く高さについては、特に確率的な意味は考えず、確率密度関数の高さに応じて定めていた。
カーネル密度分布のコンターについては、「Seabornを使えば、2次元データ分布のコンターがかけるよ」というような記事はしばしば見かけるが、その線にどういう意味があるのかということを解説したものは見たことがない。また、お客さんにコンターを見せれば、「その線の工学的意味は?」と聞かれるのは目に見えている。そのため、今回は、前回から少し発展させ、コンター線を確率値に基づいて引くことを試みた。
自分なりの理解でやっているため、間違いなどもあるかもしれませんが、その場合はご指摘願えればと思います。
やりかた
以下にカーネル密度推定からコンターを引く部分のコードを示す。カーネル密度推定では、データの分布に基づき、確率密度関数が出力される(下記コード6行目の変数f)。
01: xx,yy = np.mgrid[xmin:xmax:0.01,ymin:ymax:0.01]
02: positions = np.vstack([xx.ravel(),yy.ravel()])
03: value = np.vstack([x,y])
04: #kernel = gaussian_kde(value, bw_method='scott')
05: kernel = gaussian_kde(value, bw_method=0.1)
06: f = np.reshape(kernel(positions).T, xx.shape)
07: ll=fprop(f)
08: f=f/np.max(f)
09: plt.contourf(xx,yy,f,cmap=cm.Purples,levels=ll)
10: plt.contour(xx,yy,f,colors='#000080',linewidths=0.7,levels=ll)
ここで、上記コード7行目の関数fpropを導入して、コンター線を引く高さのリストllを算出している。関数fpropを以下に示す。scipyの線形内挿を使うので、scipy.interpolateをインポートしておく。
01: def fprop(f):
02: ff=np.ravel(f)
03: fmax=np.max(ff)
04: fsum=np.sum(ff)
05: asx=np.array([0.001,0.01,0.05,0.10,0.30,0.50,0.70,0.90,0.99])
06: asy=np.zeros(len(asx),dtype=np.float64)
07: for i,sx in enumerate(asx):
08: ii=np.where(sx<=ff/fmax); asy[i]=np.sum(ff[ii])/fsum
09: fip = interpolate.interp1d(asy, asx)
10: pr=np.array([0.99,0.90,0.70,0.50,0.30,0.10]) # probability
11: ch = fip(pr) # conter height corresponding to probability
12: con_h = ch.tolist()+[1.0] # np.array to list for plotting
13: print('fmax=',fmax) # peak value of probability density function
14: print('fsum=',fsum) # total sum of probability density function
15: print('pr=',pr) # specified probability
16: print('ch=',ch) # height of contour line corresponding to the specified probability
17: return con_h
上記関数fpropは、指定した2次元座標(xx,yy)(作図用コードの1行目)に相当する座標で与えられている確率密度関数値fから、与えられた確率値に応じた、コンターを引くべき高さ(出力値リスト:con_h)を指定するものである。
やっていることは以下の通り。
- 2行目:引数として引き込んだ2次元配列
fを処理用に1次元配列に変換。 - 3行目:確率密度関数のピーク値を算出(
fmax)。 - 4行目:確率密度関数の値の総和を算出(
fsum)。このプログラムの場合、プログラム内で出力される値は、fsum=9999.9999...であるが、確率値を計算するメッシュを0.01刻みで与えている(作図用コード1行目)ので、確率密度関数の積分値は9999.9999 x 0.01 x 0.01 = 0.9999でほぼ1となり、理屈通りである。 - 5行目:コンターを引く高さを仮の値として指定。
- 6〜8行目:仮定したコンター高さ以下の領域にある確率を算出。
- 9〜11行目:与えられた非超過確率(配列
pr)に相当するコンター高さ(配列ch)を線形内挿で推定。したがってコンターを引く高さと確率の関係はもちろん概略値である。 - 12行目:作図用にコンター高さの最大値を加えておく。
結果として、このプログラムでは、確率的に、99%、90%、70%、50%、30%、10%の値がその範囲内にあるコンター線を引くことができる。
作図例 (bw_method=0.1)
データ数が少ない場合、かなり複雑な形状となるが、外形線(99%ライン)はデータの分布と概ね一致しており、想定通りの図となっている。余談であるが、これが動けば、天気予報の雲かアメダスのデータみたいである。
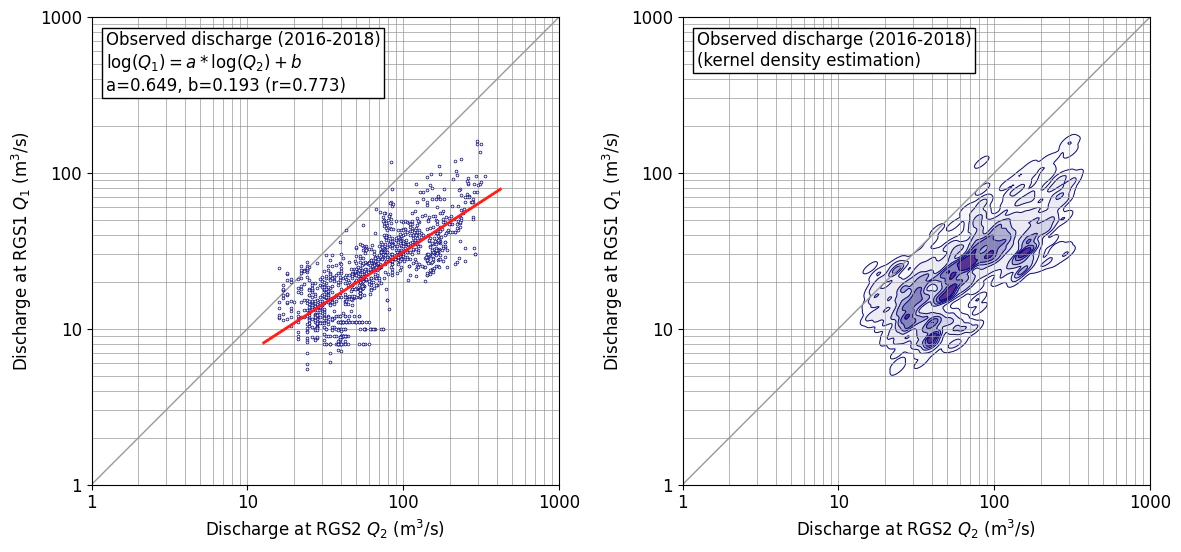
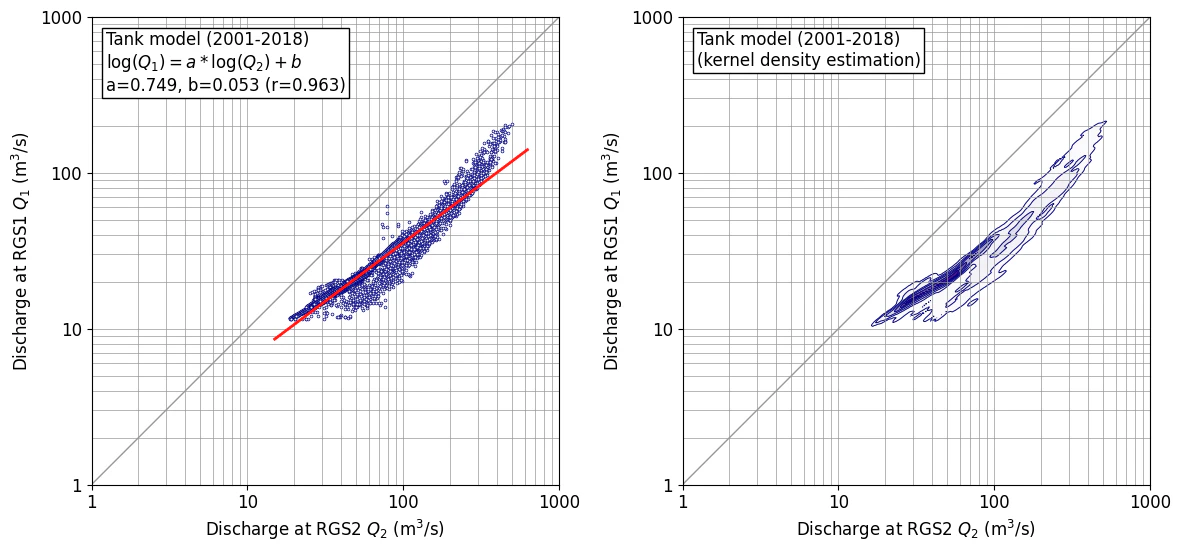
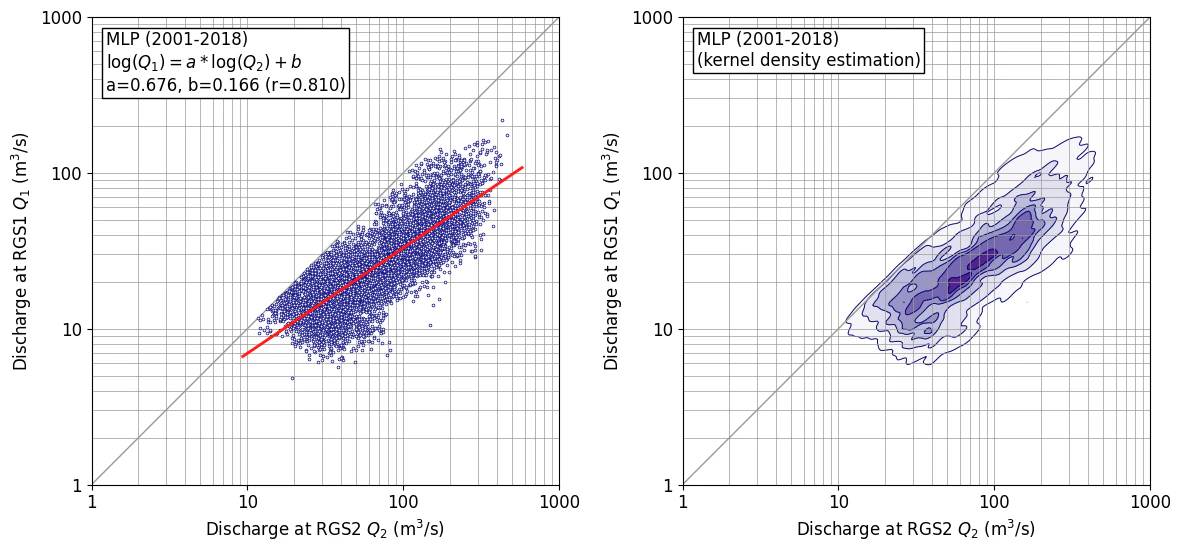
プログラム
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.cm as cm
from scipy.stats import gaussian_kde
from scipy import interpolate
def fprop(f):
ff=np.ravel(f)
fmax=np.max(ff)
fsum=np.sum(ff)
asx=np.array([0.001,0.01,0.05,0.10,0.30,0.50,0.70,0.90,0.99])
asy=np.zeros(len(asx),dtype=np.float64)
for i,sx in enumerate(asx):
ii=np.where(sx<=ff/fmax); asy[i]=np.sum(ff[ii])/fsum
fip = interpolate.interp1d(asy, asx)
pr=np.array([0.99,0.90,0.70,0.50,0.30,0.10]) # probability
ch = fip(pr) # conter height corresponding to probability
con_h = ch.tolist()+[1.0] # np.array to list for plotting
print('fmax=',fmax) # peak value of probability density function
print('fsum=',fsum) # total sum of probability density function
print('pr=',pr) # specified probability
print('ch=',ch) # height of contour line corresponding to the specified probability
return con_h
def sreq(x,y):
# y=a*x+b
res=np.polyfit(x, y, 1)
a=res[0]
b=res[1]
coef = np.corrcoef(x, y)
r=coef[0,1]
return a,b,r
def inp_obs():
fnameR='df_rgs1_tank_inp.csv'
df1_obs=pd.read_csv(fnameR, header=0, index_col=0) # read excel data
df1_obs.index = pd.to_datetime(df1_obs.index, format='%Y/%m/%d')
df1_obs=df1_obs['2016/01/01':'2018/12/31']
#
fnameR='df_rgs2_tank_inp.csv'
df2_obs=pd.read_csv(fnameR, header=0, index_col=0) # read excel data
df2_obs.index = pd.to_datetime(df2_obs.index, format='%Y/%m/%d')
df2_obs=df2_obs['2016/01/01':'2018/12/31']
#
return df1_obs,df2_obs
def inp_tank():
fnameR='df_rgs1_tank_result.csv'
df1_tank=pd.read_csv(fnameR, header=0, index_col=0) # read excel data
df1_tank.index = pd.to_datetime(df1_tank.index, format='%Y/%m/%d')
df1_tank=df1_tank['2001/01/01':'2018/12/31']
#
fnameR='df_rgs2_tank_result.csv'
df2_tank=pd.read_csv(fnameR, header=0, index_col=0) # read excel data
df2_tank.index = pd.to_datetime(df2_tank.index, format='%Y/%m/%d')
df2_tank=df2_tank['2001/01/01':'2018/12/31']
#
return df1_tank,df2_tank
def inp_mlp():
fnameR='df_rgs1_mlp_result.csv'
df1_mlp=pd.read_csv(fnameR, header=0, index_col=0) # read excel data
df1_mlp.index = pd.to_datetime(df1_mlp.index, format='%Y/%m/%d')
df1_mlp=df1_mlp['2001/01/01':'2018/12/31']
#
fnameR='df_rgs2_mlp_result.csv'
df2_mlp=pd.read_csv(fnameR, header=0, index_col=0) # read excel data
df2_mlp.index = pd.to_datetime(df2_mlp.index, format='%Y/%m/%d')
df2_mlp=df2_mlp['2001/01/01':'2018/12/31']
#
return df1_mlp,df2_mlp
def drawfig(x,y,sstr,fnameF):
fsz=12
xmin=0; xmax=3
ymin=0; ymax=3
plt.figure(figsize=(12,6),facecolor='w')
plt.rcParams['font.size']=fsz
plt.rcParams['font.family']='sans-serif'
#
for iii in [1,2]:
nplt=120+iii
plt.subplot(nplt)
plt.xlim([xmin,xmax])
plt.ylim([ymin,ymax])
plt.xlabel('Discharge at RGS2 $Q_2$ (m$^3$/s)')
plt.ylabel('Discharge at RGS1 $Q_1$ (m$^3$/s)')
plt.gca().set_aspect('equal',adjustable='box')
plt.xticks([0,1,2,3], [1,10,100,1000])
plt.yticks([0,1,2,3], [1,10,100,1000])
bb=np.array([1,2,3,4,5,6,7,8,9,10,20,30,40,50,60,70,80,90,100,200,300,400,500,600,700,800,900,1000])
bl=np.log10(bb)
for a0 in bl:
plt.plot([xmin,xmax],[a0,a0],'-',color='#999999',lw=0.5)
plt.plot([a0,a0],[ymin,ymax],'-',color='#999999',lw=0.5)
plt.plot([xmin,xmax],[ymin,ymax],'-',color='#999999',lw=1)
#
if iii==1:
plt.plot(x,y,'o',ms=2,color='#000080',markerfacecolor='#ffffff',markeredgewidth=0.5)
a,b,r=sreq(x,y)
x1=np.min(x)-0.1; y1=a*x1+b
x2=np.max(x)+0.1; y2=a*x2+b
plt.plot([x1,x2],[y1,y2],'-',color='#ff0000',lw=2)
tstr=sstr+'\n$\log(Q_1)=a * \log(Q_2) + b$'
tstr=tstr+'\na={0:.3f}, b={1:.3f} (r={2:.3f})'.format(a,b,r)
#
if iii==2:
tstr=sstr+'\n(kernel density estimation)'
xx,yy = np.mgrid[xmin:xmax:0.01,ymin:ymax:0.01]
positions = np.vstack([xx.ravel(),yy.ravel()])
value = np.vstack([x,y])
#kernel = gaussian_kde(value, bw_method='scott')
kernel = gaussian_kde(value, bw_method=0.1)
f = np.reshape(kernel(positions).T, xx.shape)
ll=fprop(f)
f=f/np.max(f)
plt.contourf(xx,yy,f,cmap=cm.Purples,levels=ll)
plt.contour(xx,yy,f,colors='#000080',linewidths=0.7,levels=ll)
xs=xmin+0.03*(xmax-xmin)
ys=ymin+0.97*(ymax-ymin)
plt.text(xs, ys, tstr, ha='left', va='top', rotation=0, size=fsz,
bbox=dict(boxstyle='square,pad=0.2', fc='#ffffff', ec='#000000', lw=1))
#
plt.tight_layout()
plt.savefig(fnameF, dpi=100, bbox_inches="tight", pad_inches=0.1)
plt.show()
def main():
df1_obs, df2_obs =inp_obs()
df1_tank,df2_tank=inp_tank()
df1_mlp ,df2_mlp =inp_mlp()
fnameF='fig_cor_obs.png'
sstr='Observed discharge (2016-2018)'
xx=df2_obs['Q'].values
yy=df1_obs['Q'].values
xx=np.log10(xx)
yy=np.log10(yy)
drawfig(xx,yy,sstr,fnameF)
fnameF='fig_cor_tank.png'
sstr='Tank model (2001-2018)'
xx=df2_tank['Q_pred'].values
yy=df1_tank['Q_pred'].values
xx=np.log10(xx)
yy=np.log10(yy)
drawfig(xx,yy,sstr,fnameF)
fnameF='fig_cor_mlp.png'
sstr='MLP (2001-2018)'
xx=df2_mlp['Q_pred'].values
yy=df1_mlp['Q_pred'].values
xx=np.log10(xx)
yy=np.log10(yy)
drawfig(xx,yy,sstr,fnameF)
# ==============
# Execution
# ==============
if __name__ == '__main__': main()
以上