はじめに
Elasticsearchには機械学習の機能の一つとして異常検知(Anomaly Detection)が実装されています。ウィザードが用意されていて一見シンプルに使えるようでいて、細かいことを考え出すと色々と調べ直さないといけないことも多いので、この記事ではあらためて基本を押さえていきたいと思います。とはいえAnomaly Detectionの全てについて一つの記事で説明することは現実的ではありません。この記事では基本的で重要なコンセプトについて概略を説明します。
したがってこの記事は初めてElasticsearchのAnomaly Detectionを使ってみるという人のための入門記事というより、一度使ってみた後にその仕組みをよりよく理解するためのものです。異常検知(Anomaly Detection)についてはこれまでにも以下のような記事がありますので、そちらも参考にしてください。
またElasticsearchの機械学習の機能を網羅的に理解するという点においては、以下の書籍が最も適していると思われます。英語ですが深く理解したい方は一読することをお勧めします。
異常検知 Anomaly Detection とはどういう機能か
Elasticsearchにおける異常検知(Anomaly Detection)とは、時系列データに対し、自分のデータの過去の振る舞いを学習して、新しく投入されたデータが「いつもと違う」かどうかを0から100の数値(Severity)で評価する仕組みです。Severityが高いほど、学習されている通常の値から乖離して異常度合いが高いことを示します。
具体的なユースケースとしては、例えば以下のようなものが考えられるでしょう。
- Webサーバーへのアクセス数が急増・急減したことを検知する
- DBサーバーのCPU負荷が急増・急減したことを検知する
- 滅多に発生しない種類のログが出力されたことを検知する
- 特定のサーバーが他に比べて多くのIPアドレスに対してアクセスを行っていることを検知する(セキュリティ的に疑わしい振る舞いを検知)
このように、Anamaly Detectionを利用すると平常時と比較し不自然な挙動を自動的に見つけることができます。
Anomaly Detectionを利用する大きな利点は、ユーザーが事前に閾値などを設定する必要がないことです。固定の閾値を使うような旧来からよくあるアラートの仕組みは、わかりやすく、多くの場合適切に動作することが期待できます。しかし例えば本来アクセスが増えるはずの時間帯に想定通り増えない、あるいはその逆のように、ピーク以外で閾値に到達しない状態でも通常状態から逸脱したというようなことを検知するのは困難でしょう。そのような場面ではAnomaly Detectionが威力を発揮し、具体的な数値を指定しなくても異常を検知することを可能にします。
逆に以下のようなケースには適していないことにも注意が必要です。
- 時間軸に沿ったはっきりしたパターンが存在しない
- 突発的に発生する事象を事前に検知しようとしている
Anomaly Detectionが対象としているのは、「いつもと違う」事象が発生したときに、それを自動的に検知することです。「いつも」とはつまりそれ自身の過去の振る舞いのことです。この枠組みから外れる動作を期待する場合は、Anomaly Detection以外の仕組みの導入の検討が必要になります。またAnomaly Detectionは発生した事象に対してそれが異常かどうかを判定する仕組みです。したがって「異常」が発生することを予測することはできません。(できるとするとそれは定義上予測可能な通常の振る舞いであって、「異常」ではありません。)
では具体的にElasticsearchでのAnomaly Detectionの動作イメージを見てみましょう。
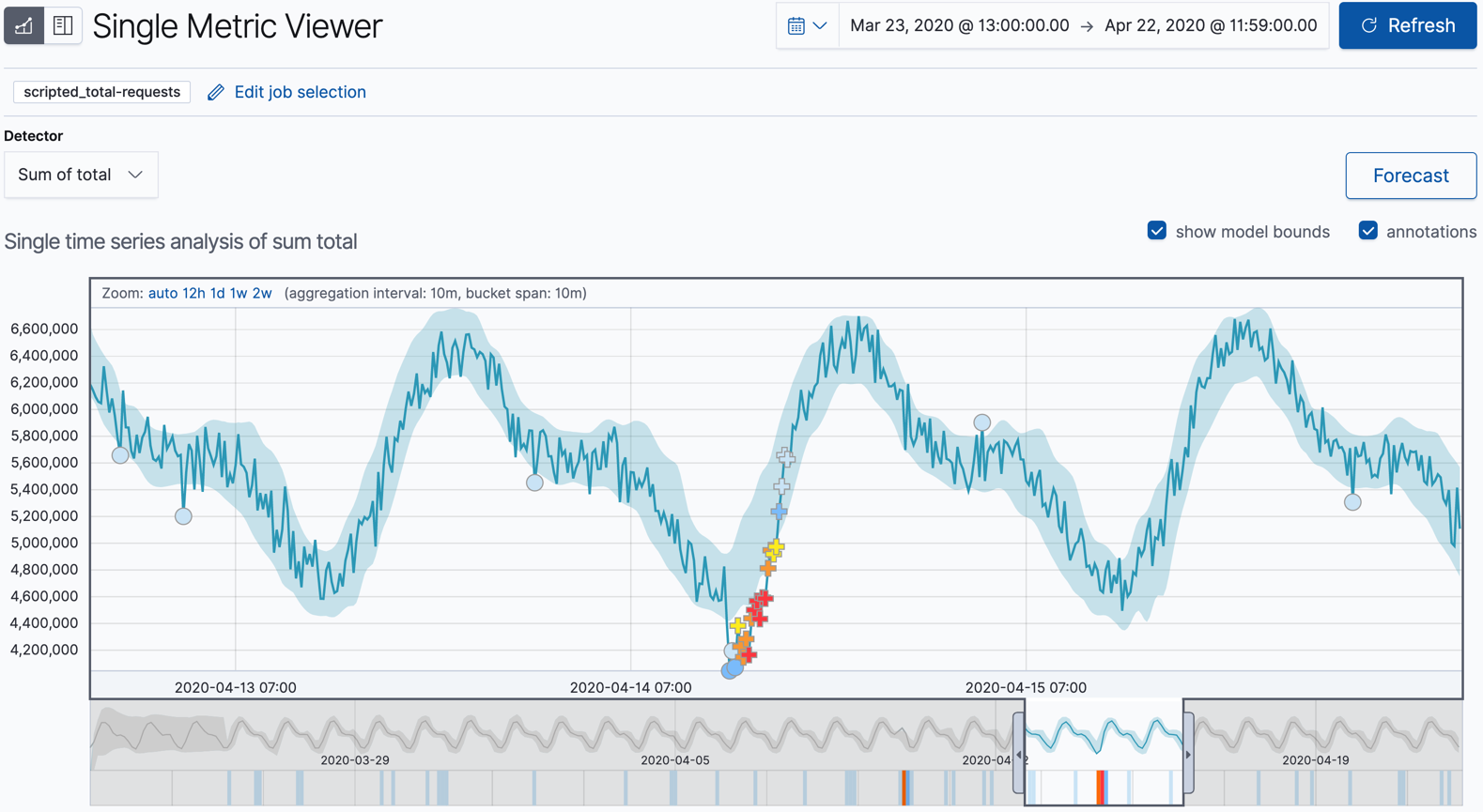
上はElasticの公式サイトから持ってきた図ですが、これを見るとおおよそ以下のことがわかると思います。
- Elasticに投入されているデータの実測値が青の実線で表示されている
- 過去の系列から予測される、「通常」のデータ範囲が薄い青のバンドで表示されている
- 適切に日毎に繰り返されるパターンを学習している
- 実績(実線)がバンドから外れている場合は「異常」としてマークされている
また、特にスコアが高く赤く表示されている箇所は、マーカーが「+」マークになっていることに注目してください。このようにシングルメトリックビューワーでマーカーが「+」マークになっているものは、「Multi bucket anomalies」と呼ばれるものです。これは一点のバケットのみに注目してそれが青いバンドから外れているかという判定をしているだけでなく、直近の系列での変化が想定外であるような場合に高い異常スコアが算出されたものです。そのため一部青いバンドの中にも「+」のマーカーが存在することに注目してください。Multi bucket anomaliesについては以下の記事が詳しく説明しています。
アーキテクチャー
ElasticsearchのAnomaly Detectionはどのような仕組みで動いているのでしょうか。まずは大枠のアーキテクチャーについて概観を掴んでおきましょう。
Anomaly DetectionはMLノード上で動作します。ElasticsearchはJavaで実装されていますが、このAnomaly Detectionのジョブ(autodetect)はC++で実装されており、Javaの外部プロセスになっています。
データの流れをざっくりまとめると以下のようになっています。
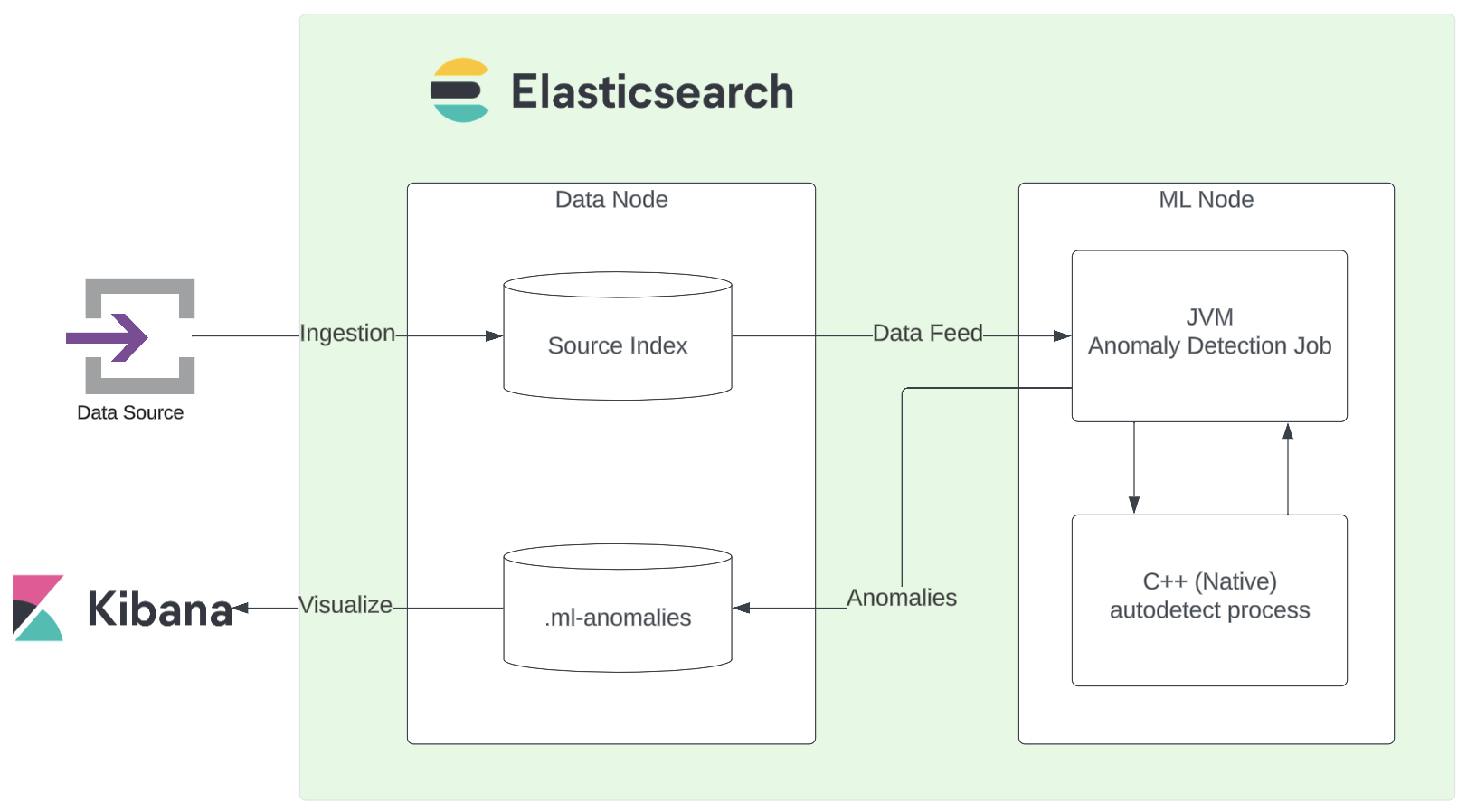
まずデータソースとなるデバイスでElastic AgentやBeatsなどのデータシッパーエージェントが、ログやメトリクスなど時系列データをElasticsearchに送信します。Elasticsearchは受け取ったデータをインデックス(ここではSource Indexとします)に保存します。この処理はリアルタイムで随時行われています。
この流れとは非同期に、MLノードは一定間隔(Frequency)でAnomaly Detectionに必要なデータをData Feedとして取得します。そしてBucket Spanの間隔で新しいバケットに溜まったデータに対して分析を行います。過去の系列との比較をし、異常を検知した場合はそれをAnomalyとして.ml-anomalies-*というインデックスに保存します。Kibanaのシングルメトリックビューワーなどで表示されているグラフや異常値スコアの情報は、この.ml-anomalies-*がデータソースとなっているわけです。
時間の取り扱い
Anomaly Detectionは時系列データに特化した分析処理です。そのため時間情報をどのように取り扱っているかについては正確に理解しておく必要があります。
Anomaly Detectionで最も重要と言ってよい要素は「Bucket Span」です。集計する時間間隔を「15m」のように設定します。Elasticsearchは入力されたデータをこの間隔で集計し、その集計結果がそれ以前の系列から妥当な値なのかどうかを評価しています。この設定とチューニングについては以下の記事が詳しく説明しています。
Bucket Spanを短くとると、素早く異常を検知することが可能になりますが、たとえばアクセス回数の分析をしている場合に短い期間でたまたまアクセスが多かった場合などでは結果がノイジーになります。Elasticとしては15分から1時間程度が通常の推奨値としています。
Bucket Spanの設定値はモデルの学習に決定的な影響を与えます。そのためジョブを作成した後には変更することはできませんので注意してください。
Data feedがデータをMLノードに送るのは、実際の時刻からquery_delayで設定した時間経過した後であることも注意が必要です。データソースから送信されたデータが検索可能になるまでには様々な理由で一定の遅れが生じる可能性があります。そのことを考慮し、query_delayには適切な値を設定する必要があります。詳しくはこちらの公式ドキュメントを参照してください。
フォーラムの回答に、Machine Learning本の著者から図解で解説があるのを見つけました。
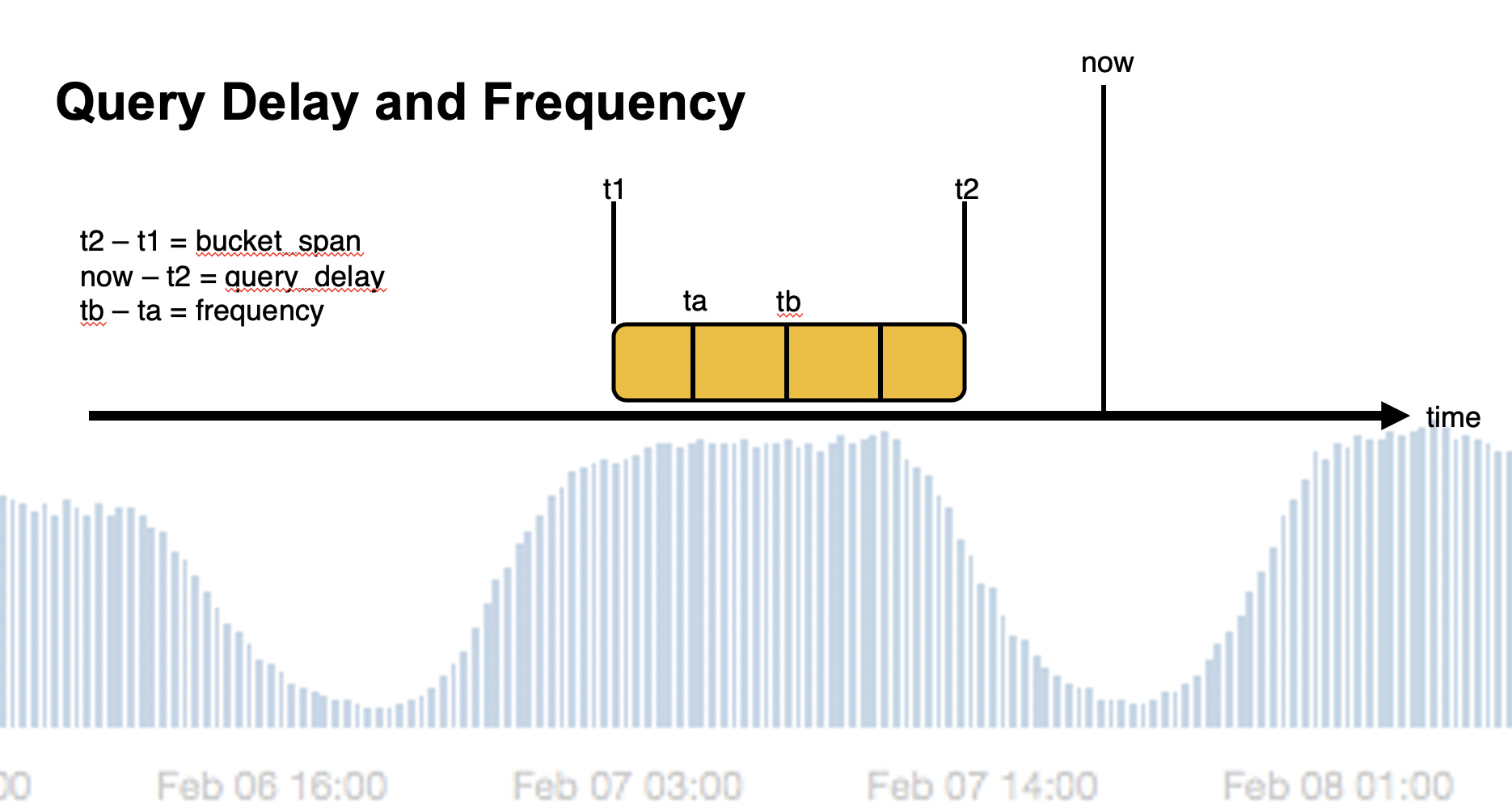
ここでnowが現在時刻=分析の始まる時刻、t1が対象のバケットの開始時刻、t2がバケットの終了時刻になります。
またFrequencyをBucket spanより短くとることで、細かい単位でバケット中のデータを取り込み、中間(interim)の結果を表示させることができます。このinterimの結果はどんな集計でも使えるわけではありません。例えばバケット期間の合計(sum)を集計している場合、バケットの中間時点で想定の半分の集計結果が出ている時、それが異常と判定されても困りますね。逆にmaxのような集計の場合は中間地でも意味があるため、短いfrequencyを設定することによって異常値をいち早く見つけることが可能になります。
もう一つ重要な点は、ジョブがバケット対してスコアリングを行った後、そのバケットに対して付与する時刻です。上記の図で示されるt1-t2のバケットの時刻はtimestampとしてt1の時刻を持ちます。したがって仮に以下のような条件の場合:
- now : 10:32
- query_delay: 1min
- t1: 10:15
- t2: 10:30
画面上に表示される最終のバケットのtimestampは10:15になります。
アラート
Anomaly DetectionによってElasticsearchが自動的に異常を検知しても、それにユーザーが気づかなければ意味がありません。Elasticsearchがユーザーに対して通知を送る仕組みとしては、以下の二つがあります。
これら以外の選択肢として、以下も考えられます。
- Elasticの外部から
.ml-anomalies-*インデックスを監視する
AlertはKibana上に実装された通知機能で、現在はこちらが推奨になっています。特にAnomaly Detectionを利用している場合は、適切な条件を簡単に作成することができるので、要件に合ったアラートを設定できるのであればこちらを使うべきでしょう。以下の公式ページで設定方法は確認してください。
一方Watcherは古くからElasticsearch上に実装された通知機能です。ElaticとしてはAlertの方に通知の機能は寄せていく方針のため、いつまでサポートが続くかわかりませんので、可能であればAlertを使いましょう。ただし、外部APIを組み合わせたりPainless Scriptで自前の処理を施してから通知を行うような複雑な設定は現在でもAlertだけでは実現できません。どうしても必要な場合はWatcherも選択肢に入るでしょう。
三つ目の外部から監視する方法はここでは解説できませんが、場合によってはWatcherより柔軟で良い選択肢になるかもしれませんので、環境的に選択できる場合は検討の余地があります。
一つ目のKiabna Alertを利用する場合は、適切な条件設定をKibanaの方で自動的にしてくれます。しかしWatcherや外部からの管理を実装しようとする場合、以下の点に気をつけましょう。
- 監視するべきインデックスは
.ml-anomalies-* -
job_idフィールドで絞り込みを行う - 監視するべき時間は、現時刻から(bucket_span x 2)前までの時間
- (繰り返しになりますが)対象のバケットが持つ時刻は、そのバケットの開始時刻(t1)
- 中間の結果を除外する場合はis_interim:falseで絞り込む
おわりに
この記事ではElasticsearchの機械学習における異常検知(Anomaly Detection)について、改めて基本的かつ重要な点について説明しました。とはいえまだジョブの作成方法などにすら触れていませんので、今後いくつかの回に分けてAnomaly Detectionがどのように動いているのか、どのような設定が可能なのかについて紹介したいと思います。