概要
Elasticsearchではベクトル検索がサポートされていますが、ベクトル検索を実装するにあたっては基本的に全てのデータがRAM(オフヒープメモリ)に載っていることが期待されています。これまではベクトルデータを保存しているインデックスで必要としているメモリ量がどれだけなのかを知る方法がなかったのですが、v9.1からベクトルデータに関するメトリクスが取得できるようになりました。
この記事では、これらのメトリクスの取得方法とその意味について紹介します。また、Flat, HNSW, Int8 HNSW, BBQ HNSWの4種類のインデックスオプションでベクトルを保存した場合のメトリクスを比較し、各インデックスオプションがRAMに与える影響についても検証します。
理論的な値
Elasticsearchのベクトルデータはオフヒープメモリに格納されます。オフヒープとは、JVMのヒープメモリの外部にあるネイティブのメモリ領域のことです。オフヒープメモリを使用することで、Elasticsearch/Luceneは大量のベクトルデータを効率的に扱うことができるようになっています。しかし、JVMのヒープメモリとは別に管理されるため、通常のJVMメモリ使用量のメトリクスには含まれません。したがって、オフヒープメモリの使用量を別の方法で取得する必要があります。
Elasticsearchでは、ベクトルデータを保存する際にいくつかのインデックスオプションが提供されています。これらのオプションは、ベクトルデータの保存方法と検索性能に影響を与えます。以下を参照すると、各インデックスオプションごとに、ベクトルデータに必要な理論的なメモリ使用量を確認できます。
表にまとめると以下のようになります。
| element_type | 量子化 | メモリ使用量の理論値 |
|---|---|---|
| float | なし | num_vectors * num_dimensions * 4 |
| float | int8 | num_vectors * (num_dimensions + 4) |
| float | int4 | num_vectors * (num_dimensions / 2 + 4) |
| float | bbq | num_vectors * (num_dimensions / 8 + 14) |
| byte | なし | num_vectors * num_dimensions |
| bit | なし | num_vectors * (num_dimensions / 8) |
メモリ上のデータのレイアウトを図示すると以下のようになります。
量子化前のベクトルデータ

Int8量子化したベクトルデータ

BBQで量子化したベクトルデータ
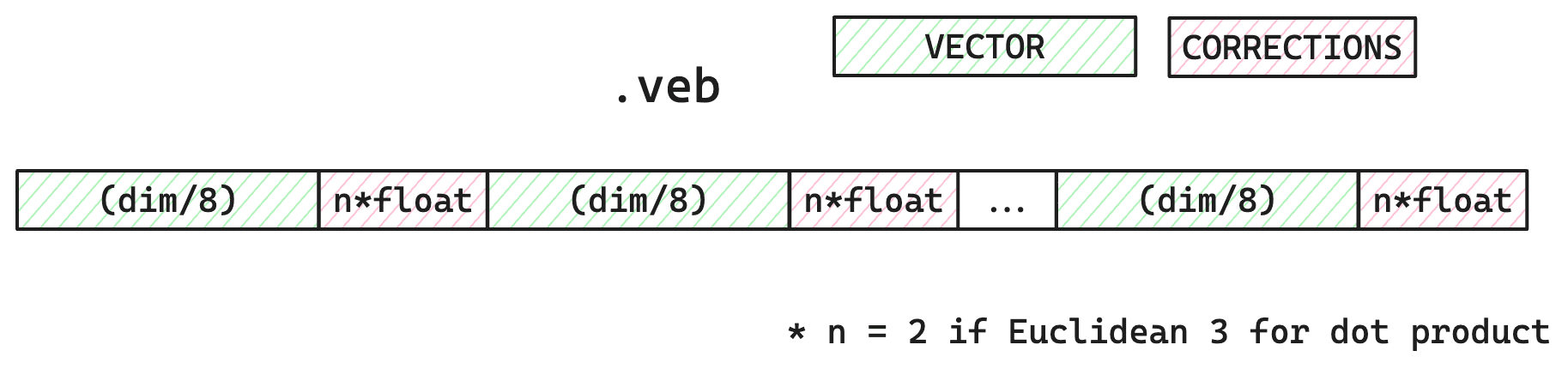
また、これとは別にHNSWを利用する場合には、HNSWグラフのためのメモリが追加で必要になります。HNSWグラフのメモリ使用量の理論値は以下の通りです。
num_vectors * 4 * HNSW.m
ここで、HNSW.mはHNSWアルゴリズムのパラメータで、デフォルト値は16です。
これから新規にベクトルデータを保存するインデックスを作成する際には、これらの理論値を参考に、インデックスに保存されているベクトルデータが実際にどれだけのオフヒープメモリを必要とするかを見積もることができます。
Off heapメモリ使用量の取得
では、実際に運用しているElasticsearchのインデックスで使用されているベクトルデータのオフヒープメモリ使用量はどのように取得できるのでしょうか。
Elasticsearchのv9.1から、Get index statistics APIでこのベクトルのメモリーに関するメトリクスが取得できるようになりました。以下のように、filter_pathパラメータを使用して、ベクトル関連のメトリクスのみを抽出できます。
GET my_vector_index/_stats?filter_path=*.primaries.dense_vector
このAPIを使用すると、以下のようなベクトル関連のメトリクスが取得できます。
{
"_all": {
"primaries": {
"dense_vector": {
"value_count": 764,
"off_heap": {
"total_size_bytes": 1229092,
"total_vec_size_bytes": 1173504,
"total_veq_size_bytes": 0,
"total_veb_size_bytes": 47368,
"total_vex_size_bytes": 8220
}
}
}
}
}
それぞれの要素の意味は以下の表の通りです。
| メトリクス名 | 説明 |
|---|---|
| value_count | インデックス内のベクトルの総数 |
| total_size_bytes | オフヒープメモリで使用されているベクトルデータの総サイズ |
| total_vec_size_bytes | 非量子化ベクトルデータのサイズ |
| total_veq_size_bytes | 量子化ベクトルデータ(int4またはint8)のサイズ。veqのqはquantizationの略。 |
| total_veb_size_bytes | バイナリ量子化ベクトルデータ(bbq)のサイズ。vebのbはbinaryの略。 |
| total_vex_size_bytes | HNSWグラフのサイズ |
上記の例はbbq量子化ベクトルを使用しているため、total_veq_size_bytesが0になっています。int4やint8を使用している場合は、total_veb_size_bytesが0になり、total_veq_size_bytesにサイズが表示されます。
これらのうち、どの項目がRAMに収まるべきかをまとめると以下のようになります。
| Index type | RAMに収まるべき項目 |
|---|---|
| flat | vec |
| hnsw | vec, vex |
| int8_hnsw | veq, vex |
| bbq_hnsw | veb, vex |
ただし、この値は実際のデータ件数や設定を元にした理論値であることに注意してください。保存されているベクトルの総量から計算するとこれだけのメモリが必要になる、という意味です。例えば他のプロセスによってRAGがすでに消費されていたりすることもあるため、OSレベルでベクトルデータが実際にどれだけのメモリを使用しているかを正確に把握する方法はありません。
とはいえElasticsearchとしては、このベクトルデータ(total_size_bytes)が全てRAM上に展開されている状態で検索を行うことを前提としています。このメトリクスを参考に、Elasticsearchが必要としているリソースを把握することができます。
検証
実際にElasticsearchにデータを投入し、上記のメトリクスが理論値とどの程度一致するかを検証しました。
検証結果
Flat, HNSW, Int8 HNSW, BBQ HNSWの4種類のインデックスオプションで、64次元ベクトルを100件登録した場合のメトリクスを比較しました。結果は以下の通りです。
| Index type | value_count | total_size_bytes | vec | veq | veb | vex |
|---|---|---|---|---|---|---|
| flat | 100 | 25,600 | 25,600 | 0 | 0 | 0 |
| hnsw | 100 | 26,780 | 25,600 | 0 | 0 | 1,180 |
| int8_hnsw | 100 | 33,601 | 25,600 | 6,800 | 0 | 1,201 |
| bbq_hnsw | 100 | 28,982 | 25,600 | 0 | 2,200 | 1,182 |
ここで、メモリー上に収まるべき項目は太字にしてあります。単位はバイトです。
各インデックスオプションごとに、理論値と実際のメトリクスを比較すると以下のようになります。
- ベクトルデータ(vec)の値は全て25,600で、理論値 (num_vectors * num_dimensions * 4 = 100 * 64 * 4) と完全に一致しています。
- HNSWグラフ(vex)の値は理論値 (num_vectors * 4 * HNSW.m = 100 * 4 * 16 = 6400) よりかなり小さい値になっています。これはベクトル件数が少ないために、HNSWグラフの接続数が少なく抑えられたためかもしれません。実際の運用の際には、適切なサイズでの検証を行うことをお勧めします。また、この値は作成されるグラフの構造に依存しているため、登録されるベクトルの値によって変動するようです。
- Int8量子化(veq)の値は理論値 (num_vectors * (num_dimensions + 4) = 100 * (64 + 4) = 6800) と完全に一致しています。
- BBQ量子化(veb)の値も理論値 (num_vectors * (num_dimensions / 8 + 14) = 100 * (64 / 8 + 14) = 2200) と完全に一致しています。
確認用コード
上記の結果は以下のコードで確認しました。環境変数か.evnファイルにES_URLとES_API_KEYを設定して実行すると上記のような表が表示されます。
# Test the vector quantizations
import os
from elasticsearch import Elasticsearch
from dotenv import load_dotenv
import numpy as np
from tqdm import tqdm
# Load environment variables from .env file (ES_URL and ES_API_KEY)
load_dotenv()
TEST_SPECS = [
# Format: (index_name, index_options.type)
("vec_float_flat", "flat"),
("vec_float_hnsw", "hnsw"),
("vec_int8_hnsw", "int8_hnsw"),
("vec_bbq_hnsw", "bbq_hnsw"),
]
NUM_VECTORS = 100
DIM = 64
M = 32
EF_CONSTRUCTION = 100
BULK_BATCH_SIZE = 500 # Number of documents per bulk request
"""
Create index with given name and type.
"""
def create_index(es, index_name, index_type):
# Delete index if it exists
if es.indices.exists(index=index_name):
es.indices.delete(index=index_name)
body = {
"mappings": {
"properties": {
"vector": {
"type": "dense_vector",
"dims": DIM,
"similarity": "cosine",
"element_type": "float",
"index_options": {
"type": index_type
}
}
}
}
}
if index_type == "hnsw" or index_type == "int8_hnsw" or index_type == "bbq_hnsw":
body["mappings"]["properties"]["vector"]["index_options"].update({
"m": M,
"ef_construction": EF_CONSTRUCTION
})
es.indices.create(index=index_name, body=body)
print(f"Created index: {index_name} with type: {index_type}")
"""
Ingest sample vectors into the given index.
"""
def ingest_vector(es, index_name, vectors):
total_vectors = len(vectors)
num_batches = (total_vectors + BULK_BATCH_SIZE - 1) // BULK_BATCH_SIZE
print(f"Ingesting {total_vectors} vectors into {index_name}")
# Process vectors in batches with progress bar
with tqdm(total=total_vectors, desc=f"Bulk indexing to {index_name}", unit="docs") as pbar:
for batch_num in range(num_batches):
start_idx = batch_num * BULK_BATCH_SIZE
end_idx = min(start_idx + BULK_BATCH_SIZE, total_vectors)
bulk_body = []
for i in range(start_idx, end_idx):
bulk_body.append({"index": {"_index": index_name, "_id": str(i)}})
bulk_body.append({"vector": vectors[i]})
es.bulk(body=bulk_body)
pbar.update(end_idx - start_idx)
# Refresh index to make documents searchable
es.indices.refresh(index=index_name)
# Flush to disk
es.indices.flush(index=index_name)
# Force merge to combine all segments into 1
es.indices.forcemerge(index=index_name, max_num_segments=1)
print(f"Completed ingestion of {total_vectors} vectors into {index_name}")
"""
Check the off-heap metrics for the given index.
Print the results as markdown table.
"""
def test_vector_quantizations(es):
print("## Parameters\n")
print(f"- Number of vectors: {NUM_VECTORS}")
print(f"- Dimensions: {DIM}")
print(f"- HNSW M: {M}")
print(f"- HNSW ef_construction: {EF_CONSTRUCTION}")
print("\n## Off-heap Memory Usage\n")
print("| Index type | value_count | total_size_bytes | vec | veq | veb | vex |")
print("|------------|-------------|------------------|-------------|-------------|-------------|-------------|")
def get_formatted_off_heap_size(off_heap, key):
size = off_heap.get(key, 0)
return f"{size:,}"
for index_name, index_type in TEST_SPECS:
# Get index stats with dense_vector metrics
stats = es.indices.stats(index=index_name)
# Extract dense_vector information
dense_vector = stats['indices'][index_name]['primaries'].get('dense_vector', {})
off_heap = dense_vector.get('off_heap', {})
# Get off-heap memory breakdown
vec_fmt = get_formatted_off_heap_size(off_heap, 'total_vec_size_bytes')
veq_fmt = get_formatted_off_heap_size(off_heap, 'total_veq_size_bytes')
veb_fmt = get_formatted_off_heap_size(off_heap, 'total_veb_size_bytes')
vex_fmt = get_formatted_off_heap_size(off_heap, 'total_vex_size_bytes')
total_fmt = get_formatted_off_heap_size(off_heap, 'total_size_bytes')
# Get document count
count = dense_vector.get('value_count', 0)
count_fmt = f"{count:,}"
print(f"| {index_type:10} | {count_fmt:>11} | {total_fmt:>16} | {vec_fmt:>11} | {veq_fmt:>11} | {veb_fmt:>11} | {vex_fmt:>11} |")
if __name__ == "__main__":
es_url = os.getenv("ES_URL", "http://localhost:9200")
es_api_key = os.getenv("ES_API_KEY")
# Connect to Elasticsearch
if es_api_key:
es = Elasticsearch(es_url, api_key=es_api_key)
else:
es = Elasticsearch(es_url)
# Generate vectors once for all tests
print(f"Generating {NUM_VECTORS} random vectors with {DIM} dimensions...")
vectors = [np.random.rand(DIM).tolist() for _ in range(NUM_VECTORS)]
for index_name, index_type in TEST_SPECS:
create_index(es, index_name, index_type)
ingest_vector(es, index_name, vectors)
test_vector_quantizations(es)
まとめ
Elasticsearchのベクトルデータに関するオフヒープメモリ使用量のメトリクスは、v9.1からGet index statistics APIで取得できるようになりました。これらのメトリクスを使用することで、インデックスに保存されているベクトルデータが実際にどれだけのオフヒープメモリを必要とするかを把握できます。各インデックスオプションごとの理論値と実際のメトリクスを比較した結果、ほとんどの場合で理論値と一致することが確認されました。これらの情報を活用して、Elasticsearchのベクトル検索機能を効果的に運用してください。