はじめに
この記事は、音の機械学習を試みました。位置づけは下記のとおりです。
- Urban Sound DatasetsのうちUrbanSound8Kを題材とする。
- TensorFlowのEstimatorの枠組みを使った例をベースにする。
※ 音の分類はあまりやったことのない著者による記事です。
まとめ; この記事の概要
- TensorFlowのEstimatorの枠組みを使った"End-to-end baseline TF Estimator LB0.72"をそのまま使い、UrbanSound8Kに適用して約55%の認識率だった。
- TensorFlowのEstimatorで簡単に書けるわけではなかった。TFでの機械学習を実運用するシステムの枠組みを提供するような位置づけではないか。
- 元は入力ファイルからすべてオンラインで処理する仕組みだったが、それでは音声データ読み込みで処理のボトルネックとなることがわかったため、予め全てのデータの前処理が必要に。
- 別の分類問題のプログラムの入力を変更するだけで 転移 できたのは、ディープラーニング周辺が技術として成熟しかけているのを感じる。
- 学習の高速化のため、ボトルネックのプロファイリングはやはり大事。
今後、下記をトライ予定。
- データセットの分布を見直す。データが均衡していないことはわかっているため。
- データを元の品質のまま処理させる。※今回は48kHz/24bit → 16kHz/16bitに落としたため。
- モデルを最適化する。
データセットUrbanSound8Kについて
UrbanSound8Kは、10クラスからなる音のデータセットです。
- 0 = エアコン
- 1 = 車のクラクション
- 2 = 子供たちの遊ぶ声
- 3 = 犬の鳴き声
- 4 = 工事の音 (drilling)
- 5 = エンジンのアイドリング音
- 6 = 銃声
- 7 = 工事の音 (jackhammer)
- 8 = サイレン
- 9 = ストリート・ミュージック
簡単に登録することで、無料でダウンロードできます。(ありがとうございます!)
ベースにした分類コード "End-to-end baseline TF Estimator LB0.72"
KeggleのTensorFlow Speech Recognition Challengeという機械学習コンペに投稿されているノートで、TensorFlowのEstimatorという枠組みを使ってプログラムされています。
この枠組みに準じた書き方にはなりますが、このEstimatorを試す狙いもあり、"End-to-end baseline TF Estimator LB0.72"をできるだけそのまま使うことを狙いにしてみました。
なお、16kHz/16bitのデータを処理する仕組みになっているため、ここもそのままで試しました。
転移学習の流れ
下記は githubのdaisukelab/ml-urban-sound にすべてまとめてあります。
データの準備
UrbanSound8Kを解凍し、UrbanSound8Kというフォルダがある状態にします。この状態から、下記の準備を行いました。
プログラム書きやすさから、学習/検証データのリストは予め作成することに。
あとでわかった問題ですが、データのフォーマットがまちまちだったり、また主に48kHz/24bitのデータのため読み込みの処理がとても重いことがわかりました。そこでデータは前処理し、16mUrbanSound8Kというフォルダに作成することに。
プログラムの修正
- データの読み込み部分を修正
クラスの内容、フォルダ構成やデータ・ファイル群全て異なりますので、ここを問題に合わせて修正。(クラスID、ファイル名)のtupleリストをtrain、validationそれぞれに用意します。
import os
import re
import pandas as pd
DATADIR = './16mUrbanSound8K'
OUTDIR = './result'
POSSIBLE_LABELS = [str(i) for i in range(10)]
id2name = {i: name for i, name in enumerate(POSSIBLE_LABELS)}
name2id = {name: i for i, name in id2name.items()}
sample_rate = 16000
def load_data():
""" Return 2 lists of tuples:
[(class_id, path), ...] for train
[(class_id, path), ...] for validation
"""
#alldata = pd.read_csv(os.path.join(DATADIR, 'metadata', 'UrbanSound8K.csv'))
traindata = pd.read_csv(os.path.join('.', 'train_list.csv'))
valdata = pd.read_csv(os.path.join('.', 'validation_list.csv'))
trainset = [(int(traindata.classID[k]), os.path.join(DATADIR, 'audio/fold%d/%s' % (traindata.fold[k], traindata.slice_file_name[k])))
for k in range(len(traindata))]
valset = [(int(valdata.classID[k]), os.path.join(DATADIR, 'audio/fold%d/%s' % (valdata.fold[k], valdata.slice_file_name[k])))
for k in range(len(valdata))]
return trainset, valset
trainset, valset = load_data()
print('trainset = %d samples.' % len(trainset))
print('valset = %d samples.' % len(valset))
- data_generator(個々のデータの読み込み)を修正
ファイルを読み込んで、augmentationしている部分で、元の問題特有の部分があったため削除。
import numpy as np
from scipy.io import wavfile
def data_generator(data, params, mode='train'):
def generator():
if mode == 'train':
np.random.shuffle(data)
# Feel free to add any augmentation
for (label_id, fname) in data:
try:
_, wav = wavfile.read(fname)
wav = wav.astype(np.float32) / np.iinfo(np.int16).max
L = 16000 # be aware, some files are shorter than 1 sec!
if len(wav) < L:
continue
if len(wav) > L:
beg = np.random.randint(0, len(wav) - L)
else:
beg = 0
yield dict(
target=np.int32(label_id),
wav=wav[beg: beg + L],
)
except Exception as err:
print('data_generator error', err, label_id, fname)
return generator
実はこのコード散々苦労した結果でした。scipy.io.wavfileは速いが柔軟ではなく、librosaやpydubを使うよう色々と工夫しましたが、信じられないくらい遅かったり、不安定だったりして問題のスポッティングにとても苦労しました。Jupyter Notebookでデバッグしていたことも逆に難しい側面がありました。
STFTなど特徴量の計算は、GPUを使うことで高速化できているようなので、ファイルの読み込みの部分を高速化するために下記の結論となりました。
1. 前処理で音声ファイルのフォーマットを統一する。
2. scipy.io.wavfileで読み込む。
- その他の修正
あったと思いますが、学習全体のコード3_urban_sound_classification_TF_estimator.ipynbを御覧ください。
学習回数だけは、10,000を20,000に変更。こうすることで過学習していることもわかりやすくなりました。
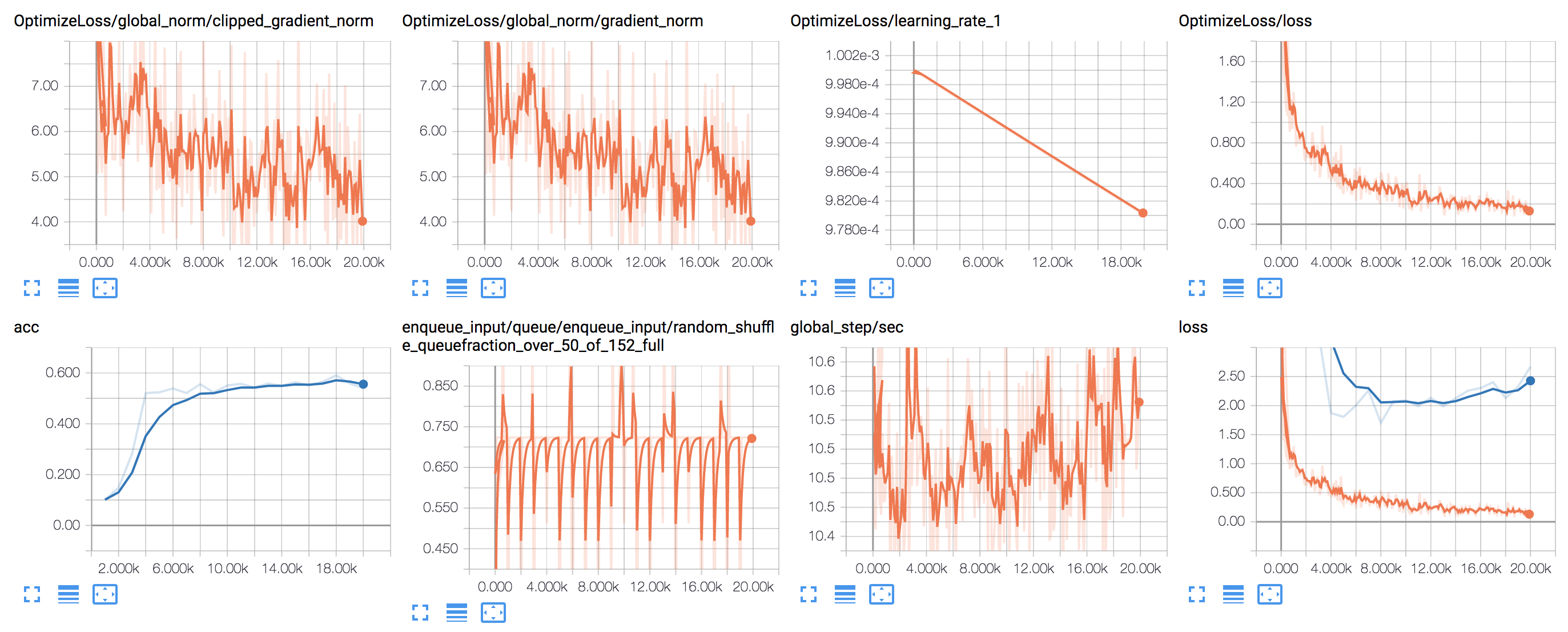
学習結果
認識率は何度か試していると、だいたい55%くらいでした。全くモデルを適応させていないことを考えると、スタート地点としては悪くない状態かと思います。
学習時間はGTX1080を使ってだいたい15分、2枚のGTX1080Ti環境なら10分を切りました。
ログの一例を示します。元々の回数10,000回でおおむね学習できています。別の問題なのにモデルや学習規模が似ているせいかもしれません。その後20,000回に向けてlossのカーブが過学習を示しているようです。