はじめに
イベント等のアイデア出しをするSlackチャンネルがあるのですが、
投稿されたメッセージを組み合わせて新たなアイデアを創造したいなあ。というわけで。
slackに投稿されたメッセージを用いて、キーワード抽出・分析をしたい計画
以下の段階で完成させようと思います。
一:まずは投稿メッセージを取得しよう
二:キーワード抽出をしよう
三:分析・可視化しよう
API,エクスポート機能を使わない理由は、ワークスペース管理者へ連絡をするのが億劫だからです。
一:まずは投稿メッセージを取得しよう
完成したもの
↓をコピペしてプログラムを実行すると
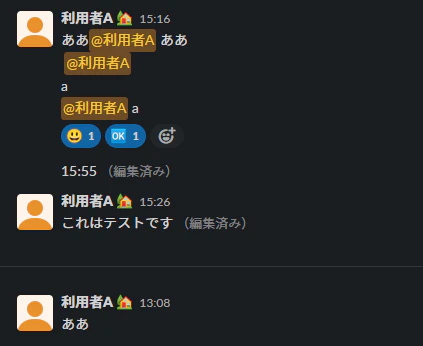
こうなります。
{
"value": {
"poster": {
"value": {
"name": "利用者A",
"status": ":庭付き家:"
}
},
"post": {
"value": {
"time": "15:16",
"massage": "ああ @利用者A ああ @利用者Aa @利用者A a"
}
},
"reply": {
"value": {
"count": 0
}
},
"reaction_array": [
{
"value": {
"name": ":スマイリー:",
"count": 1
}
},
{
"value": {
"name": ":okマーク:",
"count": 1
}
}
]
}
}
{
"value": {
"poster": {
"value": {
"name": "利用者A",
"status": ":庭付き家:"
}
},
"post": {
"value": {
"time": "15:26",
"massage": "これはテストです (編集済み) "
}
},
"reply": {
"value": {
"count": 0
}
},
"reaction_array": []
}
}
{
"value": {
"poster": {
"value": {
"name": "利用者A",
"status": ":庭付き家:"
}
},
"post": {
"value": {
"time": "13:08",
"massage": "ああ"
}
},
"reply": {
"value": {
"count": 0
}
},
"reaction_array": []
}
}
実装
基本的にはslackアプリケーションにて全体コピーAlt+A → Ctrl+Cをした結果を見て、
調整しただけです。
例えばこのような投稿をコピペすると以下のような文字列でした
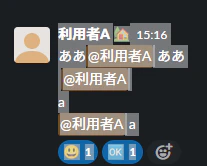
利用者A
:庭付き家: 15:16
ああ
@利用者A
ああ
@利用者A
a
@利用者A
a
:スマイリー:
1
:okマーク:
1
改善点はたくさんあります。
- 出力JSON構造自体の最適化(poster内のvalueっていうやつが邪魔だなあと思っています)
- メッセージ内に3つ以上連続する改行があった場合への対処
- 十分なパターンでのテストを行っていないので、想定していない投稿の構造
etc...
が、メッセージ内容の抽出は実装できた気がするので良いです。
初めてpythonを書いた気がします。
ファイルの構造
プログラム全文
import json
from array import array
import re
# json encorder
class MyEncoder(json.JSONEncoder):
def default(self, o):
if isinstance(o, FullyJson):
return {'value': o.__dict__}
if isinstance(o, Poster):
return {'value': o.__dict__}
if isinstance(o, Post):
return {'value': o.__dict__}
if isinstance(o, Reaction):
return {'value': o.__dict__}
if isinstance(o, Reply):
return {'value': o.__dict__}
return json.JSONEncoder.default(self, o)
# define fully json object
class FullyJson:
# constructor
def __init__(self, poster_name:str, poster_status:str, post_time:str, post_massage:str, reaction_arrray:array, reply_count:int):
self.poster: Poster = Poster(poster_name, poster_status)
self.post: Post = Post(post_time, post_massage)
self.reply: Reply = Reply(reply_count)
self.reaction_array = reaction_array
# define composition of json object
class Poster:
# constructor
def __init__(self, name:str, status:str):
if type(name) is not str or type(status) is not str:
raise TypeError('Error occured at Poster constructor')
self.name = name
self.status = status
class Post:
# constructor
def __init__(self, time:str, massage:str):
if type(time) is not str or type(massage) is not str:
raise TypeError('Error occured at Post constructor')
self.time = time
self.massage = massage
def getMsg(self):
print(self.massage)
class Reaction:
# constructor
def __init__(self, name:str, count:int):
if type(name) is not str or type(count) is not int:
raise TypeError('Error occured at Reaction constructor')
self.name = name
self.count = count
class Reply:
# constructor
def __init__(self, count:int):
if type(count) is not int:
raise TypeError('Error occured at Reply constructor')
self.count = count
# is the number decimal
def isascnum(s):
return True if s.isdecimal() and s.isascii() else False
# main method start
print("slack_text_to_json/main method is starting...")
# get text data
fully_data:str = open('./src/tmp.txt', 'r', encoding="utf-8").read()
# Leading Row Molding
fully_data = '\n\n\n' + fully_data
fully_data = re.sub("^\n+", "\n", fully_data)
# Remove excessive blank lines of all rows(3 or more blanks remove)
someblanks_removed_data_tmp=re.sub('\n\n\n+', '\n=====\n', fully_data)
someblanks_removed_data=re.sub('\n+', '\n', someblanks_removed_data_tmp)
# Forming to JSON format
MAX_MENTION_LENGTH = 20
LINE_OF_POSTER_NAME:int = 1
LINE_OF_POSTER_STATUS_AND_TIME:int = 2
LINE_OF_BEGINNING_MASSAGE_:int = 3
#Break down it into posts.
posting_data:array=[]
contain_non_posting_data:array = someblanks_removed_data.split('=====')
for data_may_be_posting in contain_non_posting_data:
each_lines_of_post:str = data_may_be_posting.split('\n')
# contain mm:ss on the line
contain_time:bool = re.search('[0-9]{2}:[0-9]{2}',each_lines_of_post[LINE_OF_POSTER_STATUS_AND_TIME]) is not None
if(contain_time):
posting_data.append(data_may_be_posting)
ret_arr:array = []
for a_post in posting_data:
# define roop meta data
roop_count:int = 0
be_skip:bool = False # this flg user to skip non-post data like '~が参加しました'
reaction_flg:bool = False # this flg use to get the next line reaction_count
#define class member
reaction_array:array = []
reaction:Reaction = ("",0)
poster_name:str = ''
poster_status:str = ''
post_time:str = ''
post_massage:str = ''
reaction_name:str = ''
reaction_count:int = 0
reply_count:int = 0
for line in a_post.split('\n'):
if(roop_count == 0): # cuz blank line
pass
elif(roop_count == LINE_OF_POSTER_NAME):
poster_name = line
elif(roop_count == LINE_OF_POSTER_STATUS_AND_TIME):
if(line[0] == ':'):
poster_status = line.split()[0]
post_time = line.split()[1]
else:
post_time = line.split()[0]
else:
if(len(line) < 1): # cuz blank line
pass
#if the line is only :something: then the line is reaction-line
elif(line[0] == ':' and line[-1:] == ':' and line.count(':') < 3):
reaction_name = line
reaction_flg = True
elif(reaction_flg):
reaction_flg = False
if(isascnum(line)):
reaction_count = int(line)
reaction_array.append(Reaction(reaction_name,reaction_count))
else:
if(line[0]=='@' and len(line) < MAX_MENTION_LENGTH):
post_massage += ' '+line
elif(' に追加されました。' in line or 'チャンネルのトピックを設定しました: ' in line or ' に参加しました。' in line):
be_skip = True
else:
post_massage += line
roop_count += 1
if(be_skip):
pass
elif(len(post_massage) == 0):
pass
else:
# encoded data store in array for return
fully_json:FullyJson = FullyJson(poster_name, poster_status, post_time, post_massage, reaction_array, reply_count)
ret_arr.append(fully_json)
js = json.dumps(fully_json, cls=MyEncoder, ensure_ascii=False)
print(js)
print("...slack_text_to_json/main method is ending")
二:キーワード抽出をしよう
キーワード抽出には下記2通りを試しました。
=>YAKE!
=>pke (python keyphrase extraction)
結論から言うと、pkeの方が相応しいワードを抽出できました。
YAKE! について
YAKE!のアルゴリズムは、以下を大きく評価するようです
- 文頭に近い位置にある
- 何度も表示する
- 共起する単語が少ない
- 複数の文章に出現する
pke.MultipartieRank について
MultipartieRankでは、複数のトピックが存在することが前提で、
- トピック達から、重要なトピックを選ぶ
- 選ばれたトピックから先頭に近いフレーズ候補を抽出する。(出現回数を基に抽出するものもある)
要は、大事な話の最初の方にある単語は大事。
と認識しました。
自然言語処理の入門にも立っていない私は、"フレーズ","トピック"などの定義がイマイチぴんと来なかったので、名言は避けます。
[Keyphrase Extraction],[Graph base ~]などで検索してみてください。
キーワード抽出の前処理
日本語は英文と違い、空白やカンマ等で単語を分割しないので、
キーワード分析するために、単語ごと分割する必要があります。
=>MeCabを使いました。
こんな感じに分かち書きしてくれます
日本語は英文と違い、空白やカンマ...
↓
日本_語_は_英文_と_違い_、_空白_や_カンマ...
完成したもの
使用した文章
前回まで使用していたデータは、文章自体に意味が含まれていなかったので、対象とする文章を変更しました。
(公開して良いチャットデータを探し中)。。。
YAKE!
プログラム
kw_extractor = KeywordExtractor(lan="ja", n=3, top=10)
keywords = kw_extractor.extract_keywords(JSONのmassage.value)
print(keywords)
出力
(公開して良いチャットデータを探し中)
pke
プログラム
import pke
import separatingWords
extractor = pke.unsupervised.MultipartiteRank()
separated_words_massage_array = separatingWords.separete()
for separated_words_massage in separated_words_massage_array:
extractor.load_document(input=separated_words_massage, language='ja', normalization=None)
extractor.candidate_selection(pos={'NOUN', 'PROPN', 'ADJ', 'NUM'})
extractor.candidate_weighting(threshold=0.74, method='average', alpha=1.1)
print(extractor.get_n_best(3))
出力
(公開して良いチャットデータを探し中)
考察
今回のキーワード抽出で、精度が低かったのは、以下3つの要因があるのではないかと考えます。
・ 短文はキーワード抽出の難易度が高い
短文の場合、各単語の出現回数が1回ずつというケースが頻出します。
文章ごとの関連や、各単語の出現回数、繋がりを基に重要さを決定するアルゴリズムでは、正しいキーワード抽出が出ないのではないか。
加えて、日本語の短文では句読点を打たなくても容易に文が成り立つので、機械的にはどこまでが文なのか判別がつかないのではないか。
・ 主語が先頭に出ない文の解析は難しい
英語も日本語も重要な単語が必ずしも先頭に来るわけではない。
特に日本語で、重要な単語が文頭に出ていない文は、分かち書きをしたところで、英語をベースとしたキーワード抽出処理では高い精度は出せないのではないか。
例
日:skype, discordと同様に、VRでの会話は今後の標準になるだろう。
英:Like skype and discord, VR conversations will become the standard for the future.
または
日:VRでの会話は、skype,discordと同様に、今後の標準になるだろう。
英:Conversations in VR will be the standard for the future, just like skype,discord.
どの文もキーワードは"VR", "会話"であってほしい。
上側の文について、英語ではLike(たぶん前置詞)が文頭に来るが、日本語ではskype(名詞)が文頭に来るため、skype(名詞)が主語だと認識されても仕方ないのかもしれない。
・ 日本語は必ずしも主語が明記されるわけではない。
英語は構造上、主語が明記される。
しかし日本語では主語が明記されない場合がある。
(参考:主題優勢言語_wikipedia)
例
日:私はケンジ君と遊んだ。サッカーとバスケットボールをした。
英:I played with Kenji. We played soccer and basketball.