Neo4jをインストールしたもののなかなか触ることができていなかったので、夏前?に1日触ってみた備忘録。
Cypherについては、公式で丁寧に解説されているので、そちらを参考にしてください。
https://neo4j.com/docs/cypher-manual/current/インストール関連
前に備忘録としてまとめたので、そちらを参照
グラフDB初心者 Neo4jインストールからサンプル実行まで
Neo4j ブラウザコマンド備忘録
ブラウザに表示された画面でコマンドが実行できます。

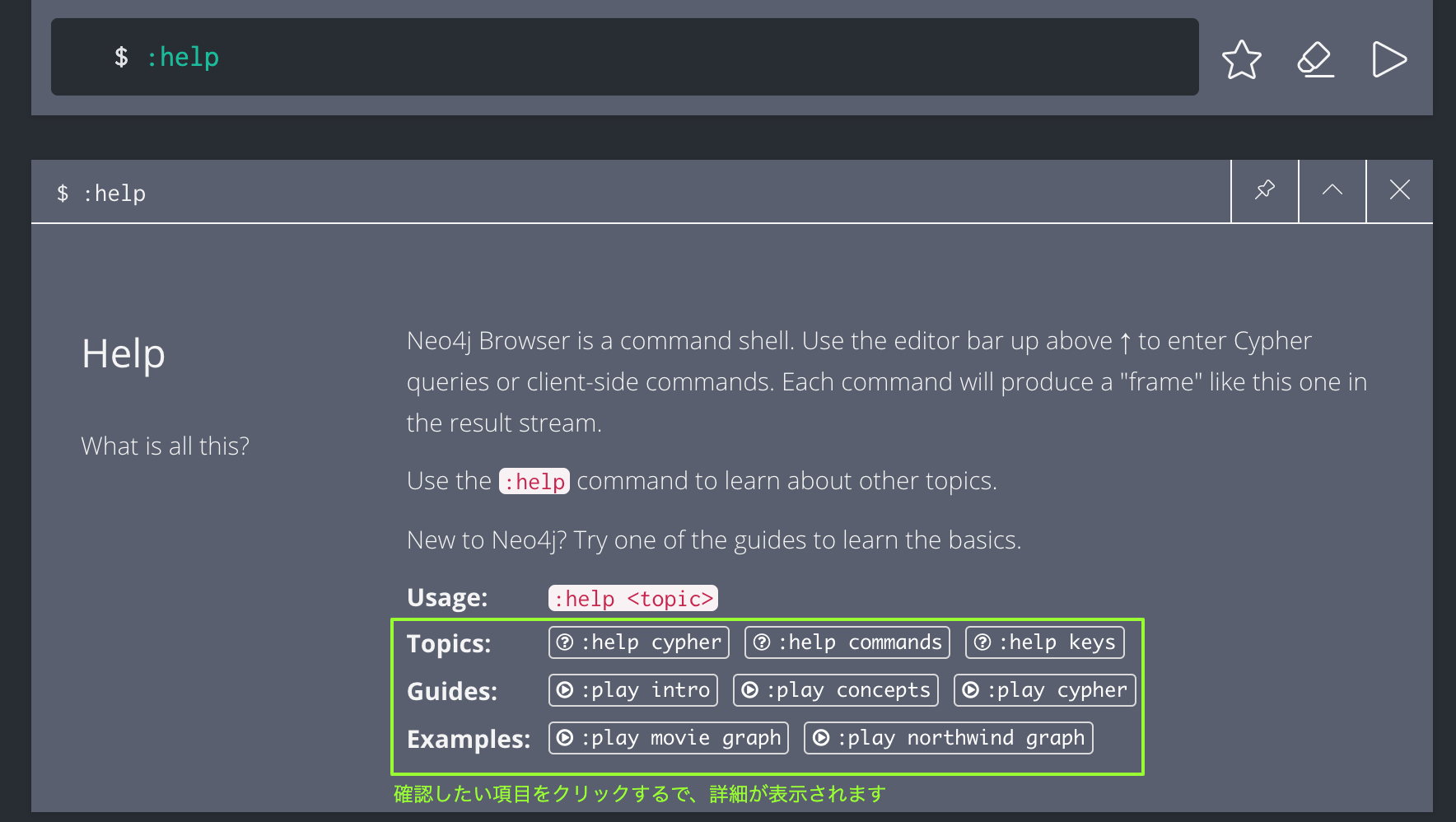
■HELPを表示
HELPコマンドから、コマンドやクエリ、チュートリアルなどを参照することができます。
自分は初心者として、Exampleのチュートリアルを触って、クエリのイメージを掴むのはおすすめです。
:help
■cypherを確認
GraphoDBを操作するクエリを確認することができます。
:help cypher
■画面をクリアする
:clear
詳しくはこちらが参考になります
Neo4j Webインターフェースを使い倒す
Neo4j データ型
- 数値
integerおよびFloat - 文字列
''もしくは""で記載する - 真偽値
- List型
Neo4j cypherクエリ備忘録
node
作成関連
CREATE
■シンプルにINSERT
label(ラベル) :person
property(属性) :中田
CREATE(:person{name:'中田'})
もちろん、SQLのように見やすく改行しても実行できます!
Neo4j公式の構文記載方法はこちらを参照してください。
Cypher 構文推奨記載方法
CREATE (
:person{
name:'田中'
}
)
■一度に複数のnodeをINSERT
CREATE (
:person{
name:'森田'
}
)
,(
:person{
name:'田森'
}
)
■複数のpropertyをINSERT
複数のnodeをINSERTする場合でも、propertyを統一する必要はありません。
CREATE (
:person{
name:'村田'
,age:25
,from:'Kyoto'
}
)
,(
:person{
name:'田村'
,age:40
,job:'engineer'
,hobby:['fishing','reading','cooking']
}
)
■やってみての注意点
・データの重複はあり
例えばCREATE(:person{name:'中田'})を複数回実行すれば、中田さんが複数node表示されます。
制約関連
制約をしようすれば、データの重複も除外することができます。
CONSTRAINT
■ユニーク制約の作成
Lable"Person"のProperty"name"にユニーク制約をつけることで名前が重複する人の登録を防ぐことが可能です。
CREATE CONSTRAINT ON (p:person) ASSERT p.name IS UNIQUE
ユニークを制約を作成すると、作成したPropertyに対してIndexが作成されます。
以下のクエリで確認できます。
CALL db.indexes
■(ユニーク)制約の削除
制約の削除はCREATEをDROPに変更することで実行が行えます。
また、上記で補足したIndexは削除されないため、別で削除が必要になります。
DROP CONSTRAINT ON (p:person) ASSERT p.name IS UNIQUE
■制約の確認
CALL db.constraints
他にも"Label"、"Index"などの設定がCALLを使用することで確認できます。
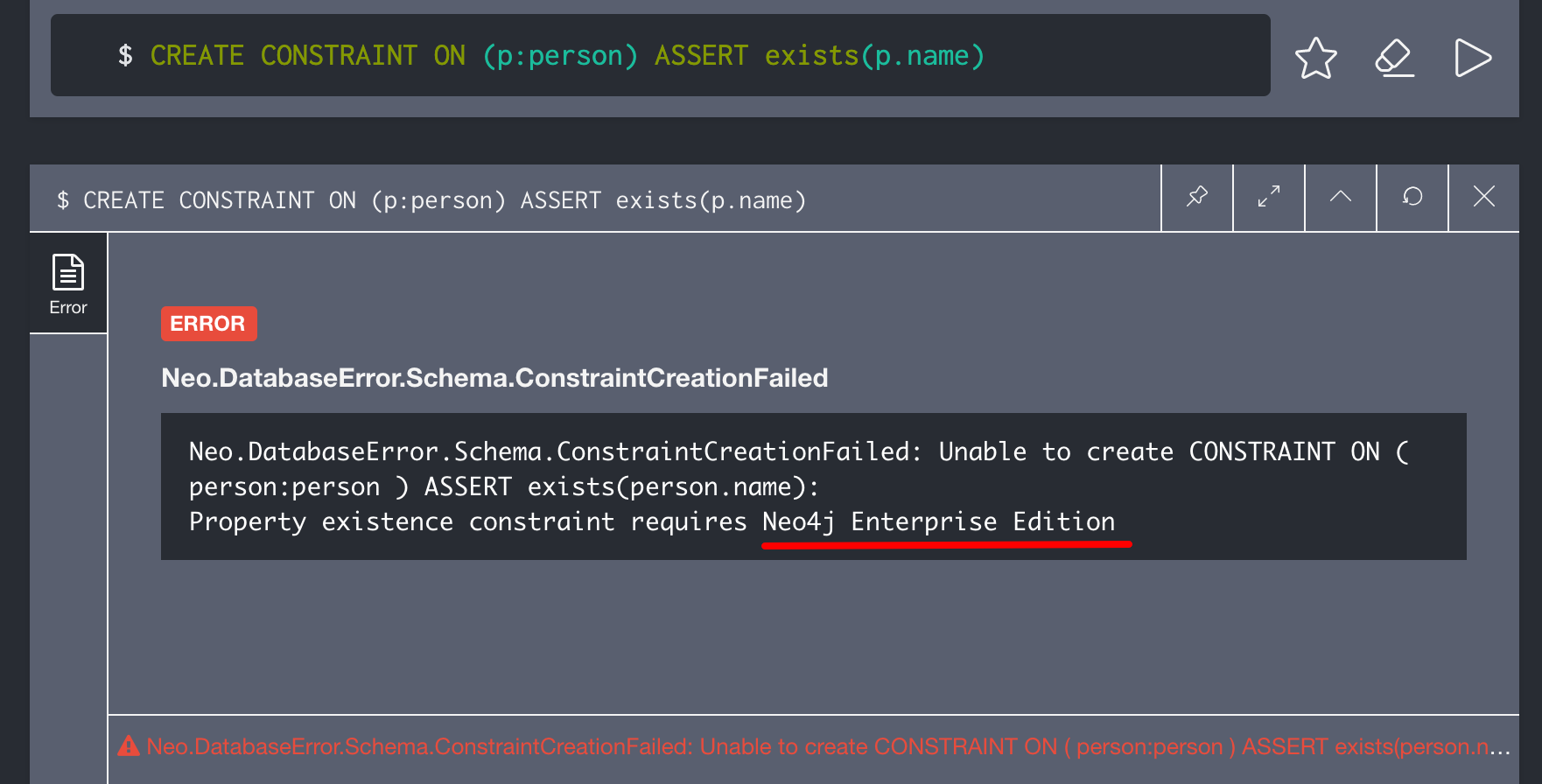
Enterprise Editionのみで設定できる制約
■Propertyの制約
Propertyで必ず登録が必要なものには、制約を付与できます。
例えば、Label"person"では、Property"name"の登録を必須にすることで、名前は常にわかる状態とすることができます。
ただし、Enterprise Editionのみ実行可能でした。。。
CREATE CONSTRAINT ON (p:person) ASSERT exists(p.name)
■Node Keyの制約
CREATE CONSTRAINT ON (p:Person) ASSERT (p.name, p.age) IS NODE KEY
INDEX関連
INDEX
■1つのPropertyにINDEXを作成する
CREATE INDEX ON :person(name)
■複数のPropertyにINDEXを作成する
CREATE INDEX ON :person(name, age)
■INDEXの確認
CALL db.indexes
■INDEXの削除
CREATEをDROPに変更するのみ
DROP INDEX ON :person(name, age)
検索関連
MATCH, RETURN
MATCHはSQLでのFROMに相当
RETURNはSQLでのSELECTに相当
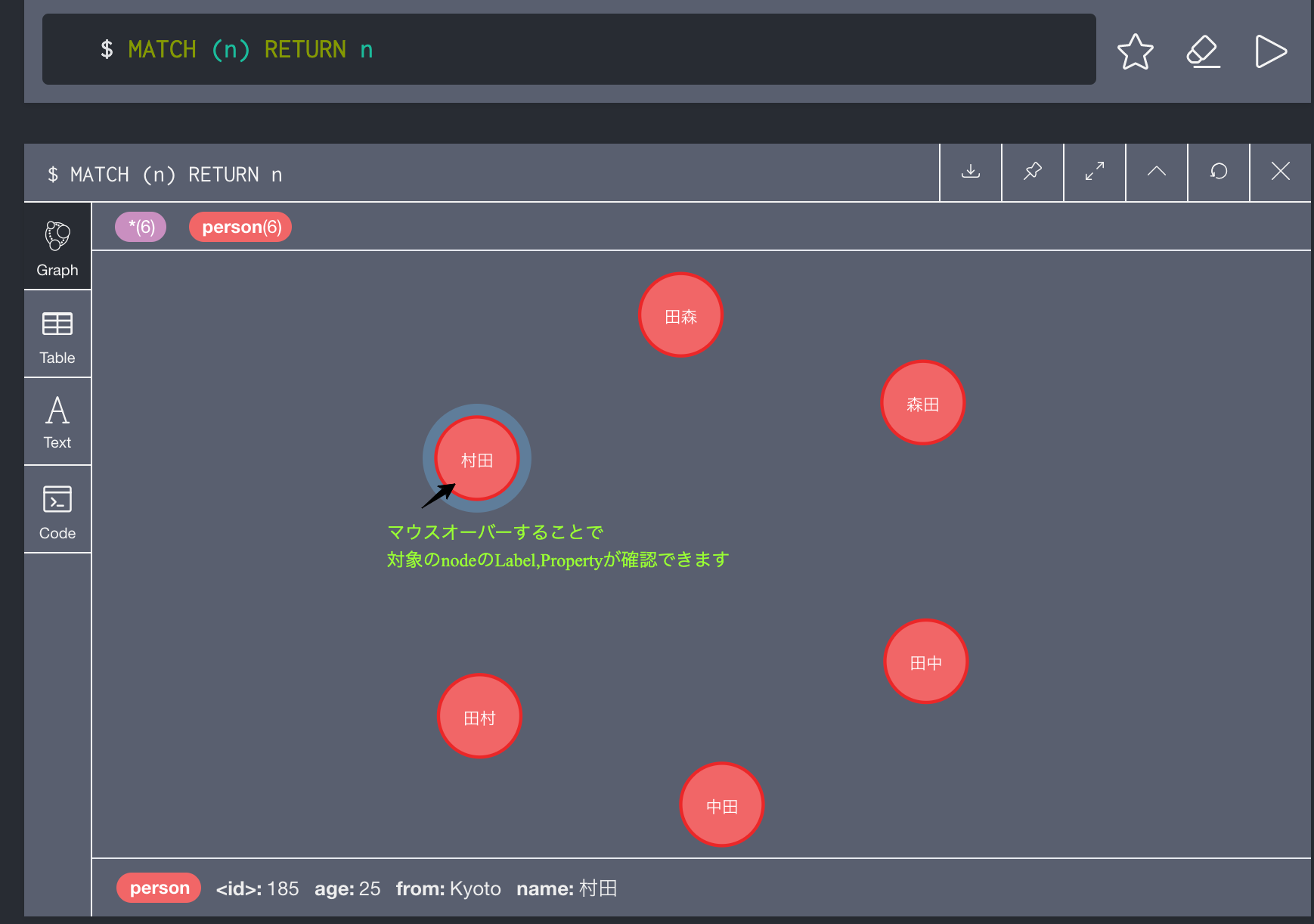
■全データを検索する
MATCH (n) RETURN n
■対象のラベルに含まるデータを検索する
MATCH (
p:person
)
RETURN
p
■対象のLabel,Propertyをもつデータを検索する
MATCH (
p_morita:person{
name:'森田'
}
)
RETURN
p_morita
WHERE
SQLのWHERE句と同様の使い方ができる。
演算子はAND/OR/XOR/NOTが使用可能
■WHEREでlabelを絞り込み
MATCH (n)
WHERE n:person
RETURN n.name, n.age
■WHERE句での絞り込み(完全一致検索)
MATCH (
p:person
)
WHERE
p.name = '村田'
AND p.from='Kyoto'
RETURN
p
■WHERE句での絞り込み(範囲検索)
MATCH (
p:person
)
WHERE
p.age >= 20
AND p.age < 30
RETURN
p
■WHERE句での絞り込み(LIKE検索)
MATCH (
p:person
)
WHERE
p.name =~ '.*田'
RETURN
p
ORDER BY
■結果をソートする
MATCH (
p:person
)
RETURN
p.name, p.age
ORDER BY
p.age, p.name
UNION
■複数の結果をUNIONで取得する(重複あり)
MATCH (
p_murata:person{
name:'村田'
}
)
RETURN
p_murata.name AS name
,p_murata.age AS age
UNION ALL
MATCH (
p_tamura:person{
name:'田村'
}
)
RETURN
p_tamura.name AS name
,p_tamura.age AS age
■複数の結果をUNIONで取得する(重複なし)
UNION ALLをUNIONに変更することで対応ができます
MATCH (
p_murata:person{
name:'村田'
}
)
RETURN
p_murata.name AS name
,p_murata.age AS age
UNION
MATCH (
p_tamura:person{
name:'田村'
}
)
RETURN
p_tamura.name AS name
,p_tamura.age AS age
削除関連
DELETE
削除関連では、検索関連と同様にMATCH句を使用します。
構文としては、RETURNを DETACH DELETEに変更することで基本的に対応できます。
■全てのnodeを削除する
MATCH (n) DETACH DELETE n
■対象のラベルに含まれるnodeを削除する
MATCH (
p:person
)
DETACH DELETE
p
■対象のLabel,Propertyを持つnodeを削除する
MATCH (
p_nakata:person{
name:'中田'
}
)
DETACH DELETE
p_nakata
■WHERE句を使用したnode削除
LIKE検索以外にも、検索で紹介したWHERE句が同様に使用できます。
MATCH (
p:person
)
WHERE
p.name =~ '.*田'
DETACH DELETE
p
REMOVE
■Labelを削除する
MATCH (
n { name: '村田' }
)
REMOVE
n:person
■Propertyを削除する
MATCH (
p_nurata:person {
name:'村田'
}
)
REMOVE
p_nurata.age
更新関連
DELETEでは、検索・削除関連と同様にMATCH句を使用します。
構文としては、RETURNをSETに変更することで基本的に対応できます。
■全てのnodeを更新する
使うことはほぼないですが、全nodeへの更新も可能です。
SETに記載したPropertyが既にあるnodeは値が更新。ないnodeは新規のPropertyが追加させれます。
MATCH (n) SET n.test = 'test_val'
RETURNを最後に記載することで、更新結果を出力できます。
MATCH (n) SET n.test = 'test_val' RETURN n
■特定のnodeを更新する
下記の例以外にも検索・削除関連で紹介したコマンドが使用することが可能です。
MATCH (
p:person
)
SET
p.group = 'RiceField'
■NULLを使用してPropertyを削除する
REMOVE以外にもSET xxx = NULLでPropertyを削除することができます
MATCH (
p_tamura:person{
name:'田村'
}
)
SET
p_tamura.age = NULL
全てのPropertyを削除する場合
MATCH (
p_murata:person{
name:'村田'
}
)
SET
p_murata = {}
■特定のnodeのLabelを追加する
Labelは追加されるため、既存のLabelをRemoveで削除
MATCH (
n {
name: '村田'
}
)
SET
n:human
特定のnodeにpropertyを追加する
MATCH (
p_nakata:person{
name:'中田'
}
)
SET
p_nakata += {
age:35
,from:'Okinawa'
}
Relationship
Relationshipの種類
-
無向性
関係性に向き先がない。例えば「友達」の関係は互いに友達であるため、方向関係がないものに使用が適しています。
('中田')-[友達]-('田中')
ただし、Neo4jでは無向性は提供されていません。
そのため、下記の有向性を使用して記載する必要があります。
参考:グラフの表現パターン -
有向性
関係性に向き先がある。例えば「上司」であれば、片方が上司→片方は部下の立場となる
('田村')-[上司]->('村田')
作成関連
CREATE
■対象のnode間にrelationを作成する
RETURN xxxを使用することで、作成したリレーションを確認できます。
MATCH (
p_1:person
)
,(
p_2:person
)
WHERE
p_1.name = '中田'
AND p_2.name = '田中'
CREATE
(p_1)-[r:Friend]->(p_2)
RETURN
p_1, p_2
RETURN TYPE(r)に変更するとrelationのみを確認できます。
■relationの重複しない形でCREATEを行う
CREATEをCREATE UNIQUEに変更するだけで、重複を許さずに作成ができます。
MATCH (
p_1:person
)
,(
p_2:person
)
WHERE
p_1.name = '田村'
AND p_2.name = '村田'
CREATE UNIQUE
(p_1)-[:Boss]->(p_2)
RETURN
p_1, p_2
■nodeとrelationを同時に作成する
CREATE(
:person{
name:'町田'
,age:20
}
)-[:Rival]->(
:person{
name:'田町'
}
)
■relationにpropertyを作成する
relationにもpropertyを0~設定することができます。
MATCH(
p_1:person{
name:'森田'
}
)
,(
p_2:person{
name:'田森'
}
)
CREATE UNIQUE(
(p_1)-[:Dinner{
start_time:'13:00'
,end_time:'15:00'
}]->(p_2)
)
RETURN
p_1, p_2
検索関連
RETURN
■すべてのnodeとrelationを表示する
MATCH (n) RETURN n
■すべてのrelationをもつnodeを表示する
MATCH (p_1)-[]-(p_2) RETURN p_1, p_2
■全てのrelationを表示する
MATCH ()-[r]-() RETURN r
■対象のnodeを指定して表示する
両方nodeを指定する
MATCH (
p_1:person{
name:'田中'
}
)-[r]-(
p_2:person{
name:'中田'
}
)
RETURN
p_1, p_2
片方のnodeのみを指定する
MATCH (
p_1:person{
name:'田中'
}
)-[r]-(p_2)
RETURN
p_1, p_2
relationの向きを指定して表示する
MATCH (
p_1:person{
name:'田中'
}
)-[r]->(p_2)
RETURN
p_1, p_2
■対象のrelationを指定して表示する
MATCH (p_1)-[r:Friend]->(p_2) RETURN p_1, p_2
nodeも指定する
MATCH (
p_1:person{
name:'中田'
}
)-[r:Friend]->(p_2)
RETURN
p_1, p_2
■起点からNnodeまでの階層を検索
田中さんの"友達"と"友達の友達"までを検索する場合
MATCH (
p_1:person{
name:'田中'
}
)<-[r:Friend*1..2]-(p_2)
RETURN
p_1, p_2
"友達の友達"のみを表示する場合
MATCH (
p_1:person{
name:'田中'
}
)<-[r:Friend*2]-(p_2)
RETURN
p_2
削除関連
DELETE
■nodeを指定してrelationを削除する
MATCH(
p_1:person{
name:'森田'
}
)-[r:Dinner]->(
p_2:person{
name:'田森'
}
)
DELETE
r
■propertyを指定してrelationを削除する
MATCH(
p_1:person{
name:'森田'
}
)-[r:Dinner{
start_time:'13:00'
,end_time:'15:00'
}]->(
p_2:person{
name:'田森'
}
)
DELETE
r
■片方のnodeのみを指定して該当するRelationを削除する
町田さんを始点にする"Rival"のrelationを全て削除することができます。
MATCH (
p_1:person{
name:'町田'
}
)-[r:Rival]->()
DELETE
r
田町さんを終点にする"Rival"のrelationを全て削除することができます。
MATCH (
p_1:person{
name:'田町'
}
)<-[r:Rival]-()
DELETE
r
■relationのlabelを指定せずに削除する
nodeを全て指定する
MATCH(
p_1:person{
name:'森田'
}
)-[r]->(
p_2:person{
name:'田森'
}
)
DELETE
r
片方のnodeのみを指定する
MATCH(
p_1:person{
name:'森田'
}
)-[r]->()
DELETE
r
■特定のnodeの持つrelationを全て削除する
田中さんのもつrelationを全て削除する
MATCH (
p_1:person{
name:'田中'
}
)-[r]-()
DELETE
r
■relationを全て削除する
MATCH ()-[r]-() DELETE r
更新関連
SET
■relationのpropertyを更新する
propertyを更新する場合 ※既存のpropertyは削除される
MATCH (
p_1:person{
name:'田中'
}
)-[r:Friend]-(
p_2:person{
name:'中田'
}
)
SET
r = {
where:'Tokyo'
,when:'2019/1/1'
}
RETURN
p_1, p_2
propertyを追加する場合 ※既存のpropertyは保持(propertyが同一のものは更新)
MATCH (
p_1:person{
name:'田中'
}
)-[r:Friend]-(
p_2:person{
name:'中田'
}
)
SET
r += {
where:'Kanagawa'
,How:'Lunch'
}
RETURN
p_1, p_2
■relationのlabelを変更する
MATCH (
p_1:person{
name:'田中'
}
)-[r:Friend]-(
p_2:person{
name:'中田'
}
)
SET
r:Best_Friend
RETURN
p_1, p_2
CSV関連
LOAD
■CSVファイルを取り込む
localにファイルを配置する場合には、インストールディレクトリ/neo4j-community-x.x.x/import/配下に格納する必要があります。
田中,25,Nagoya
中田,50,Kyoto
森田,20,Osaka
田森,60,Sendai
村田,25,Tokyo
田村,40,Hakata
LOAD CSV FROM
"file:///person_list.csv" AS line
CREATE(
p:person {
name:line[0]
,age:toInteger(line[1])
,from:line[2]
}
)
RETURN
p
■HEADER(1行目)を利用してCSVファイルを取り込む
Name,Age,From
田中,25,Nagoya
中田,,Kyoto
森田,20
田森,60,
村田,,Tokyo
田村,
LOAD CSV WITH HEADERS FROM
"file:///person_list_with_header.csv" AS line
CREATE(
p:person {
name:line.Name
,age:toInteger(line.Age)
,from:line.From
}
)
RETURN
p
■区切り文字を指定してCSVファイルを取り込む
田中;25;Nagoya
中田;50;Kyoto
森田;20;Osaka
田森;60;Sendai
村田;25;Tokyo
田村;40;Hakata
LOAD CSV WITH HEADERS FROM
"file:///person_list.csv" AS line
FIELDTERMINATOR ';'
CREATE(
p:person {
name:line.Name
,age:toInteger(line.Age)
,from:line.From
}
)
RETURN
p
■コミットする行数を指定してCSVファイルを取り込む
CSVファイルをLOADする場合は行数が多いため、コミットする行数を指定することができます。
デフォルトでは、コミットは1000行ごとに発生します。
USING PERIODIC COMMIT 5
LOAD CSV FROM
"file:///person_list.csv" AS line
CREATE(
p:person {
name:line[0]
,age:toInteger(line[1])
,from:line[2]
}
)
RETURN
p
参考URL
初心者でもCypherがわかりやすい
neo4j入門 Cypherクエリと使い方の具体例
Neo4j-グラフデータベースとは
Cypherについてまとまっており、参照しやすい
グラフDB - Neo4j のレファレンスをまとめる
Neo4j公式のCypherマニュアル
The Neo4j Cypher Manual v3.5