ニュースのワード分析①
~スクレイピングからBigQueryに挿入まで~
きっかけ
野球ニュースをスクレイピングし, そのニュースで使用されている言葉を分析したいと思いました(私は阪神ファンであるが, たしか開幕1勝14敗?という奇跡的なの記録を刻んだ. この負け込んでいるニュースの分析を行いたいと思いっています)
目次
- 分析フロー
- 対象サイトの決定
- スクレイピング
- BigQueryでの作業
- スクレイピングしたデータをテーブルに挿入
- 課題
- 次回以降の作業
- 参考文献
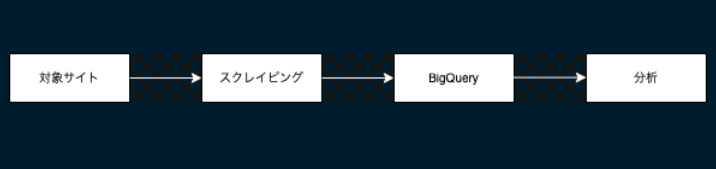
1. 分析フロー
画像では大まかな作業内容を示しました. 対象となるウェブサイトからスクレイピングを行い, その内容をBigQueryに適宜挿入します. その後BigQueryに格納されているデータを使用して, PythonもしくはBIツールで分析を行います.
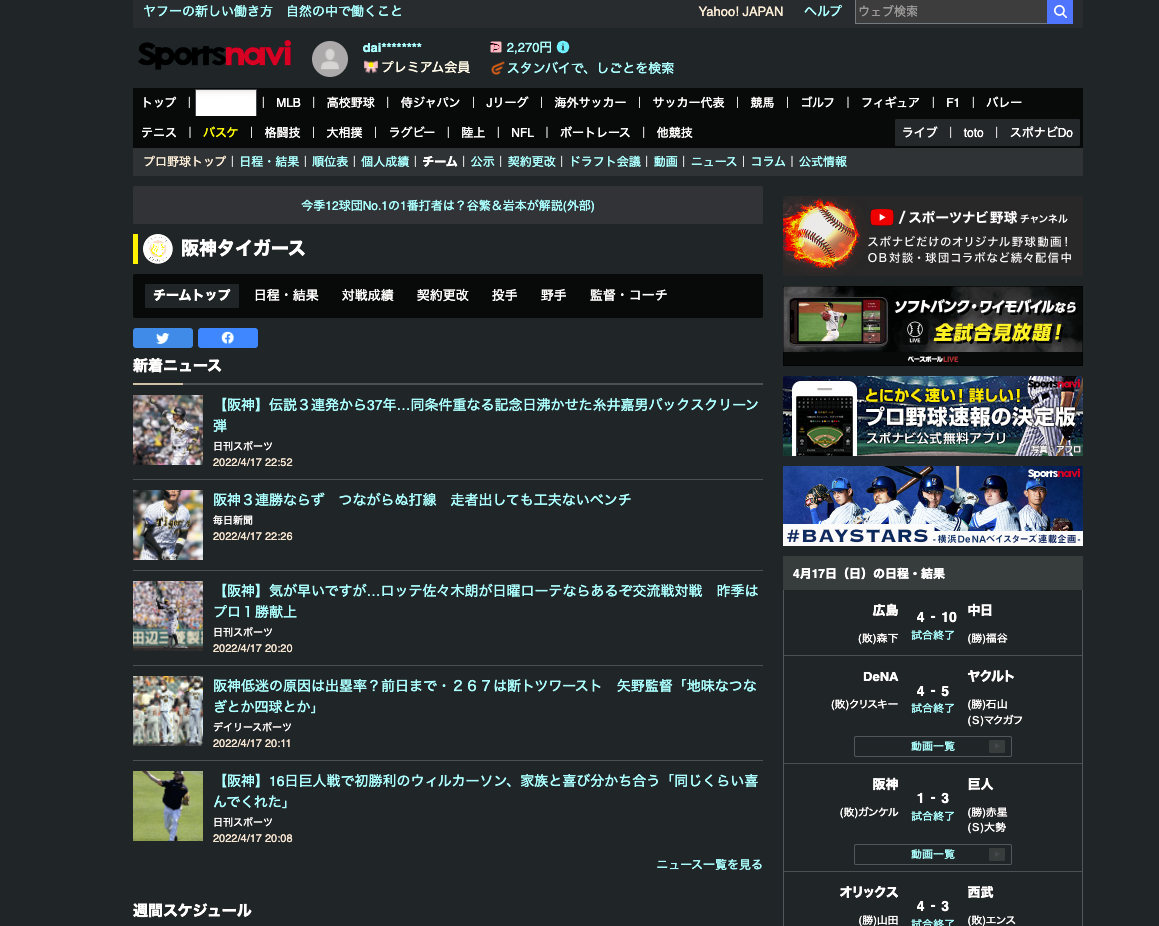
2. 対象サイトの決定
分析するウェブサイトは阪神に関するニュースとします(現在3勝16敗です!).
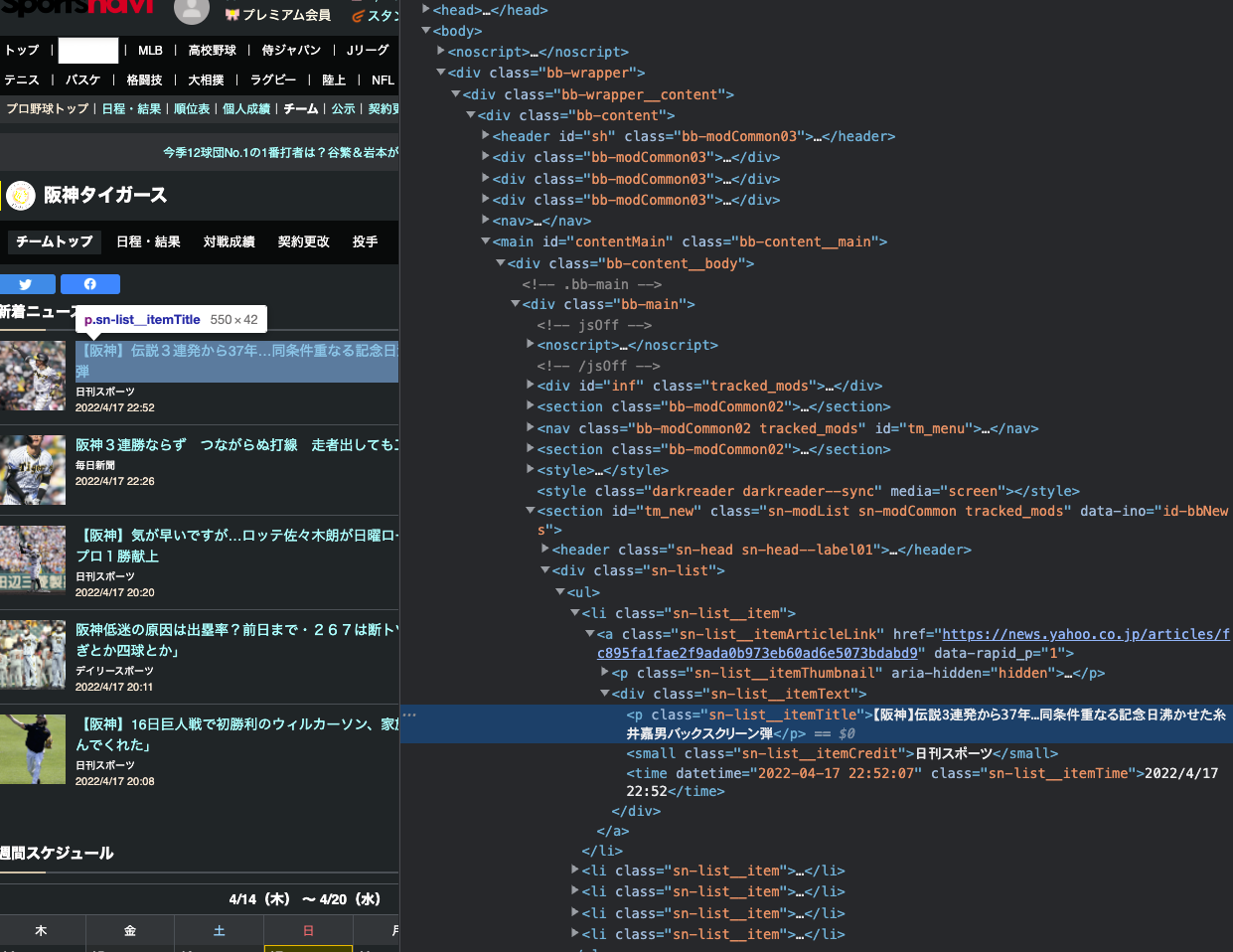
今回スクレイピングを行うのは, 各ニュースのタイトルになります.htmlで確認すると, <p class>... </p>に囲まれている箇所になります. MacならF12を押下することで確認できます.
3. スクレイピング(Python)
図解!Python BeautifulSoupの使い方を徹底解説!の記事を参考にスクレイピングの作業を進めていきます. Google Colabの環境を想定しています.
1 . まずは必要となるライブラリをインポートします.
pip install beautifulsoup4
pip install requests
pip install pandas
import requests
from bs4 import BeautifulSoup
import pandas as pd
2 . 今回使用するウェブサイトのurlを取得します. その後, BeautifulSoupの第1引数に対象サイトのurlを, 第2引数に使用するパーサーを選択します.
url = 'https://baseball.yahoo.co.jp/npb/teams/5/'
res = requests.get(url)
# BeautifulSoup(解析対象のHTML, 利用するパーサー)
soup = BeautifulSoup(res.text, "html.parser")
3 . htmlタグで指定されている <p class> ... </p> の範囲を指定してスクレイピングを行います. htmlタグの確認はF12で行うことができます. 使用するメソッドはfind_all()メソッドで引数に一致する全ての要素を抽出できます. 詳細はfind_all()に関する公式ドキュメントを参照してください. 引数には”p”, classは”sn-list__itemTitle”を指定します.
import pandas as pd
elems = pd.DataFrame(soup.find_all("p", class_="sn-list__itemTitle"), columns = ["news"])
df = pd.DataFrame(elems["news"], dtype="string")
4 . またデータを取得した日時も同様に取得したいため”date”カラムを作成し, 格納します.
import datetime
d_today = datetime.date.today()
df["date"] = d_today
df["date"] = pd.to_datetime(df["date"])
df.dtypes
--------------
news string
date datetime64[ns]
dtype: object
4. BigQueryでの作業
次に取得したデータを格納するためにBigQyery側でテーブルを作成します.
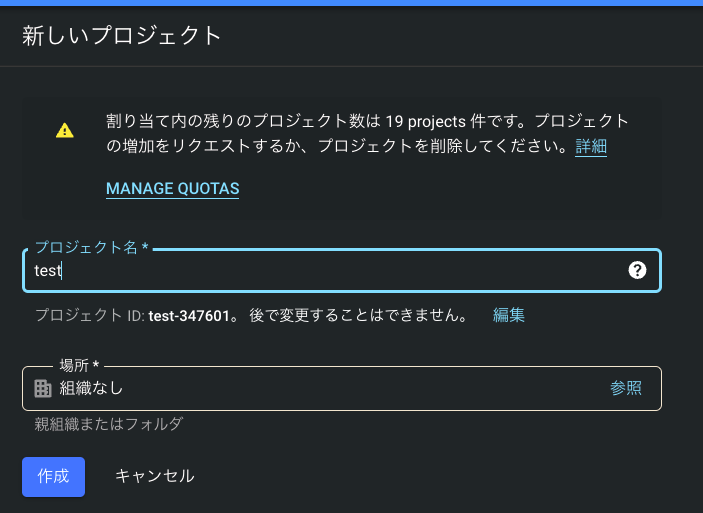
1 . 「新しいプロジェクト」を押下, プロジェクト名を入力後「作成」から新規のプロジェクトを作成します.
2 . 「プロジェクト名」(figure5ではbigdataSQL)を押下し, 新規作成した「test」オブジェクトを指定します.
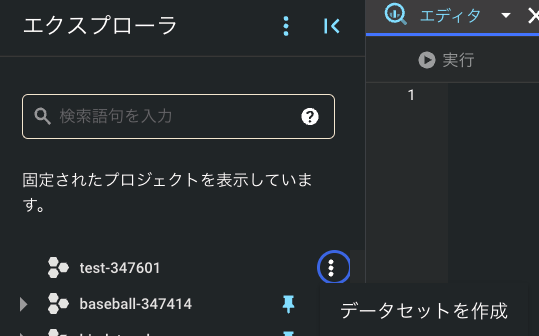
3 . 「エクスプローラ」に新規作成したプロジェクト名が表示されるので, 3点リーダーから「データセットの作成」を押下し, データセットを作成してください.
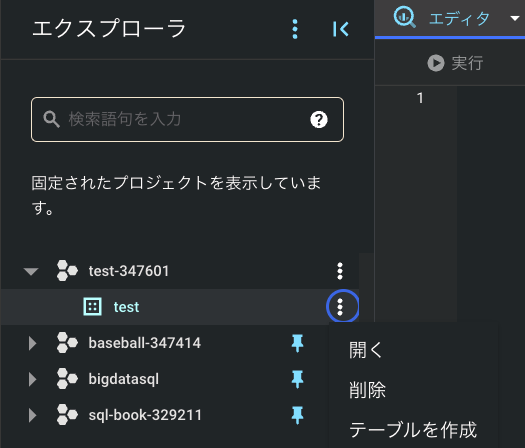
4 . データセット作成後, 再度エクスプローラを確認すると「test」のデータセットを確認できます. 再度3点リーダーから「テーブルを作成」を押下します.
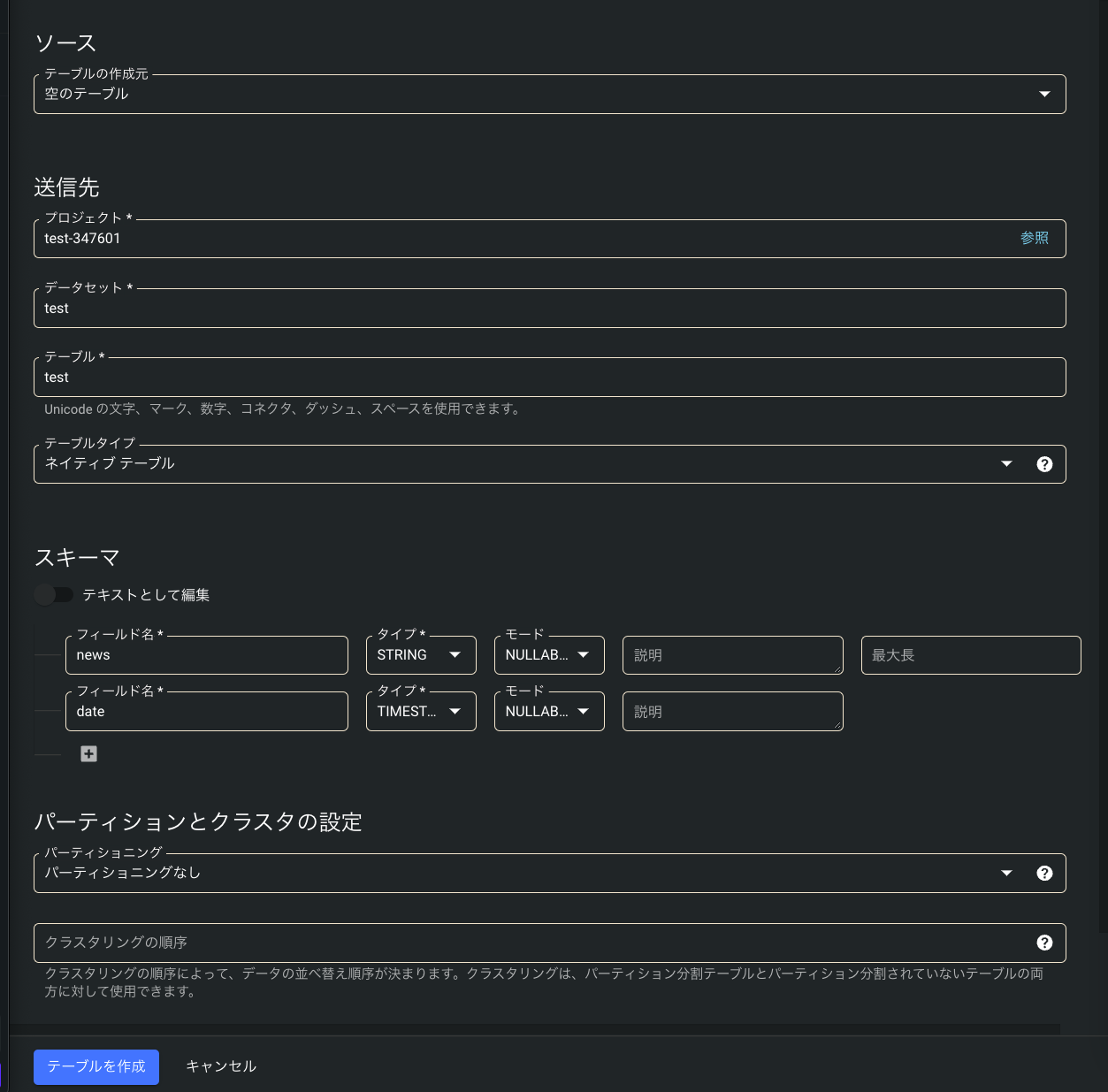
5 . 「テーブル」でテーブル名を, 「スキーマ」から今回作成した「news」と「date」カラムを入力してください. (注意: dateのカラムタイプはTIMESTAMPを指定してください. DATETIMEだと型が一致しないというエラーが帰ってきます. 参考: Pandas/Google BigQuery: Schema mismatch makes the upload fail, (機械翻訳)Pandas/Google bigquery :スキーマの不一致は、アップロードに失敗します)
5. スクレイピングしたデータをテーブルに挿入
- 再度 Google colabに戻り, データを挿入するためのクエリを書きます. to_gbqメソッドを使用することで, BigQueryにデータを格納することができます. 第1引数は「データセット.テーブル」, 第2引数は「プロジェクトid」,第3引数は「テーブルが存在する際にどのように処理を行うか」となっており”append”とすることでテーブルにデータを追記するようにします.
df.to_gbq("test.test", project_id="test-347601", if_exists="append")
2 . BigQueryに戻り, 「test」テーブルの確認を行います. 以下のように無事データが格納されていれば成功です
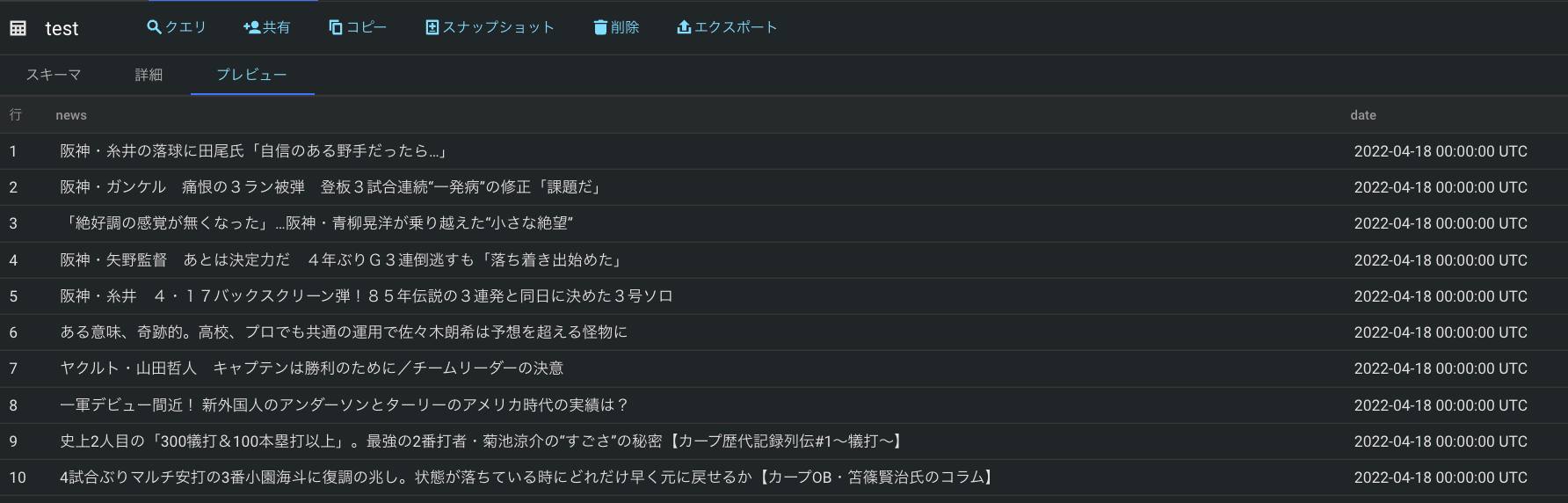
6. 課題
・Google Colabを定期実行したい 解決策をを模索中
7. 次回以降の作業
・作成したテーブルをクレンジングする
・そのテーブルを元に, PythonやBIツールで分析を行う
8. 参考文献
1 . 図解!Python BeautifulSoupの使い方を徹底解説!
https://ai-inter1.com/beautifulsoup_1/
2 . Beautiful Soup Documentation 公式ドキュメント
https://www.crummy.com/software/BeautifulSoup/bs4/doc/
<使用したクエリ>
import requests
from bs4 import BeautifulSoup
import pandas as pd
url = 'https://baseball.yahoo.co.jp/npb/teams/5/'
res = requests.get(url)
soup = BeautifulSoup(res.text, "html.parser")
elems = pd.DataFrame(soup.find_all("p", class_="sn-list__itemTitle"), columns = ["news"])
df = pd.DataFrame(elems["news"], dtype="string")
import datetime
d_today = datetime.date.today()
df["date"] = d_today
df["date"] = pd.to_datetime(df["date"])
df.to_gbq("test.test", project_id="test-347601", if_exists="append")