はじめに&目的
研究会コミュニティTeam AIアンケート調査で、お悩みのトップだったのが、
"どのデータにどの機械学習モデルを適用すれば良いのかが初心者にはわかりにくい”というものでした。
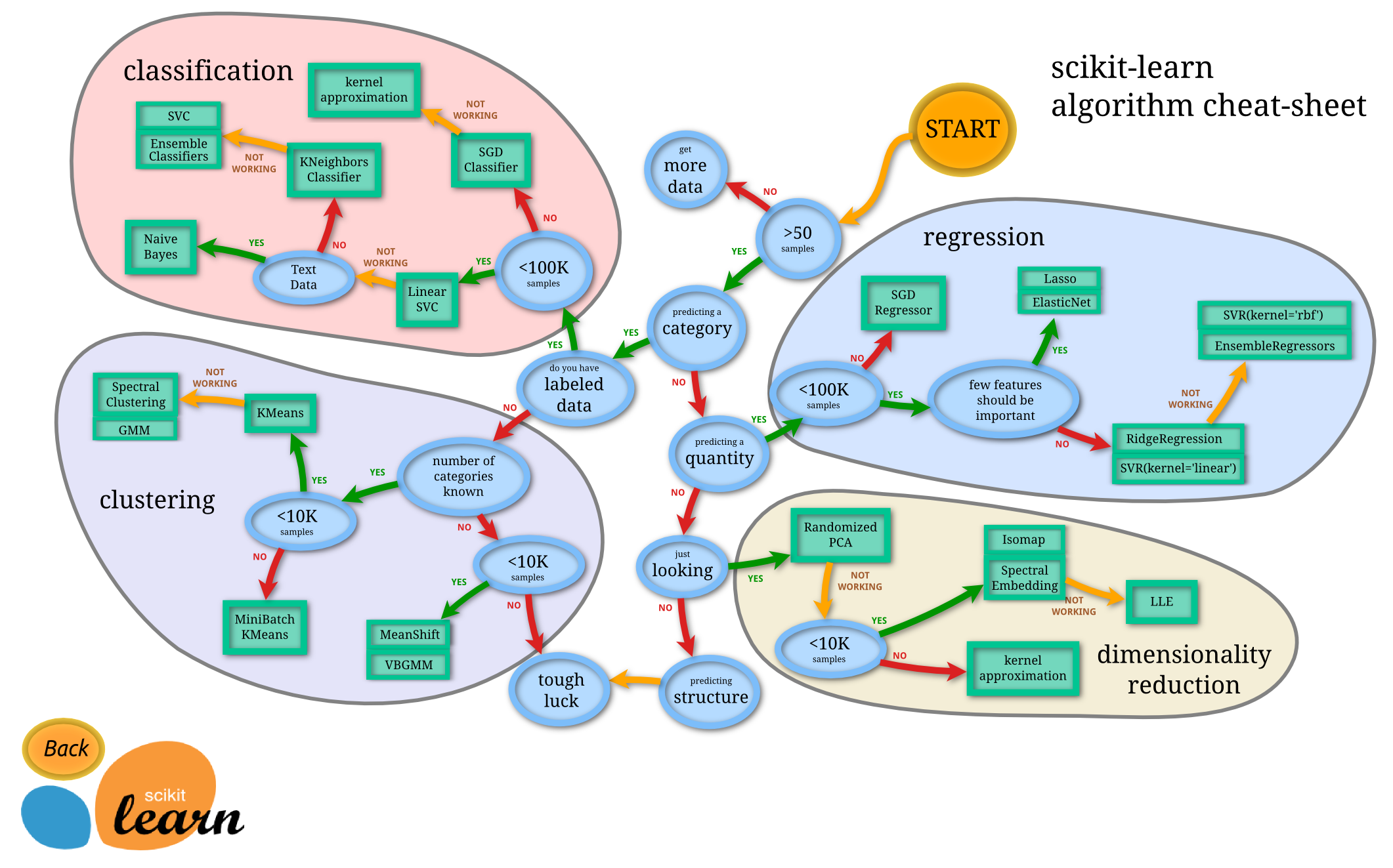
下記は有名なScikit-learnの分析フローチャート(カンニングペーパー=CheatSheet)で、
非常に初心者にわかりやすいので、
Scikit-learnで使える以外の機械学習モデルを網羅したバージョンをTeam AIのコミュニティメンバーと議論しながら作っていきたいと思っています。
まずは機械学習の数理モデルをMECE(もれなくダブりなく)羅列するところから始めていきます。時間がなく全部翻訳できなかったので、Google翻訳 for Chromeを活用ください。
1/20キックオフでイベントをやりますので、随時更新していきますね。
イベントはこちらから:
www.team-ai.com
春頃に完成すると、皆さんにとって役に立つCheatSheetになるのでは、と思っています。
2019/1/20更新
CheatSheetを作るなら下記の構造、という仮説が立った。
1)CSV形式(構造化データ) => 教師あり => 回帰 / 分類
教師なし => クラスタリング / 主成分分析
2)非構造化データ => DeepLearning
注)上記をベースにそれぞれのモデルの長所短所を記入する
できれば該当モデルのKaggleコードURLを併記
いちばんやさしい機械学習プロジェクト(ブレインパッドさん)に便利なフローチャートが載っている
1)Scikit-learnのフローチャート中身
Predicting Category カテゴリ予測
Labeled Data = Classification 分類
SGD Classifier
Kernel Approximation
Unlabeled Data = Clustering クラスタリング
Try first = Linear SVC
Text = Naive Bayes
Non-text = K neighbors Classifier
Predicting Quantity 数値予測
Sample is less than 100K = SGD Regressor
Sample is more than 100K = LASSO / ElasticNet / RidgeRegression / SVR
Just Looking = Dimensionality Reduction 次元削減
Try first = Randamized PCA
Sample is less than 10K = Kernel Approximation
Sample is more than 10K = ISOMAP / Spectral Embedding
2)DataCategory vs Model データ種類別 使用できる数理モデル&手法&ツール
Text 自然言語
tfidf
count features
logistic regression
naive bayes
svm
xgboost
grid search
word vectors
LSTM
GRU
Ensembling
Actual Code of above;
https://www.kaggle.com/abhishek/approaching-almost-any-nlp-problem-on-kaggle
Image 画像
CNN! - example: AlexNet? ImageNet?
Video(Image + Time Series) 映像
Time Series 時系列
Moving Average
ARIMA
Linear Regression
Neural Network(RNN/LSTM?)
Others その他データ種類
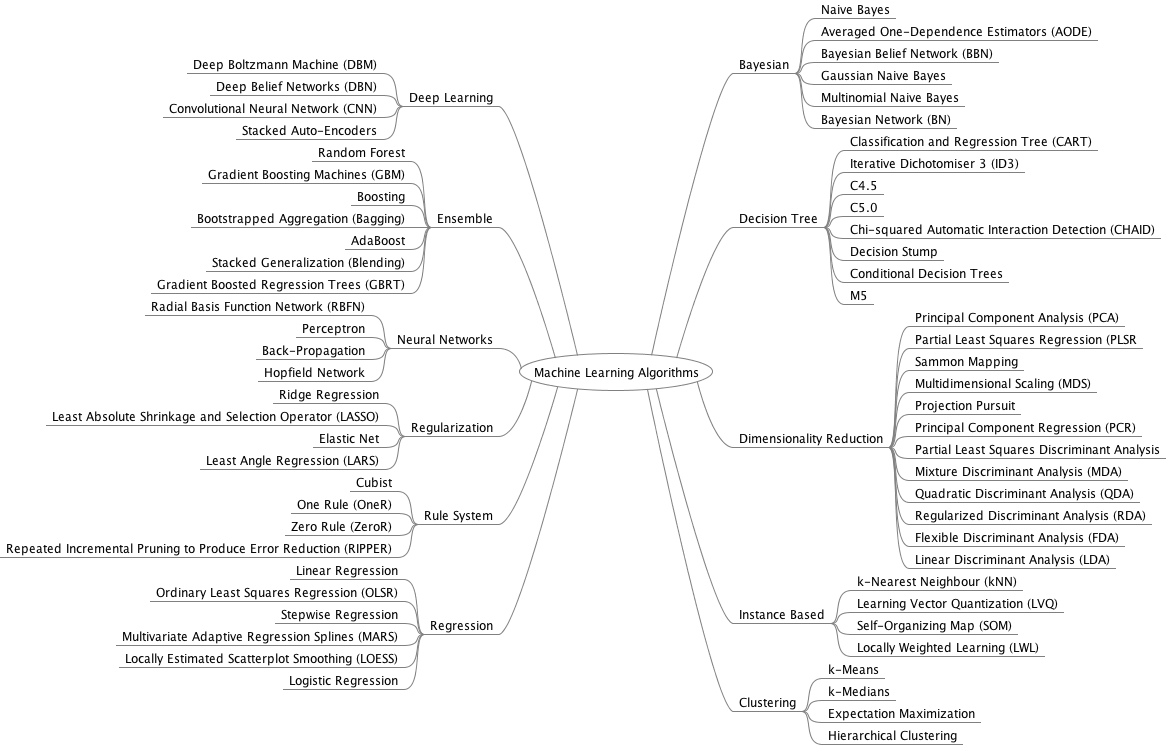
3)機械学習の全モデル一覧
Regression 回帰
Linear Regression 線形回帰
Generalised Linear Models (GLMs)
Locally Estimated Scatterplot Smoothing (LOESS)
Ridge Regression リッジ回帰
Least Absolute Shrinkage and Selection Operator (LASSO) ラッソ回帰
Logistic Regression ロジスティック回帰
Bayesian ベイジアン
Naive Bayes ナイーブベイズ
Multinomial Naive Bayes
Bayesian Belief Network (BBN)
Dimensionality Reduction 次元削減
Principal Component Analysis (PCA) 主成分分析
Partial Least Squares Regression (PLSR)
Principal Component Regression (PCR)
Partial Least Squares Discriminant Analysis
Quadratic Discriminant Analysis (QDA)
Linear Discriminant Analysis (LDA)
Instance Based インスタンスベース(意味確認中)
K-nearest Neighbors(KNN) K-近傍法
Learning Vector Quantization (LVQ)
Self-Organising Map (SOM)
Locally Weighted Learning (LWL)
Decision Tree 決定木
Random Forest ランダムフォレスト
Classification and Regression Tree (CART)
Gradient Boosting Machines (GBM) 勾配ブースティング法 (XGBoostなど?)
Conditional Decision Trees 条件付き決定木
Gradient Boosted Regression Trees (GBRT)
Clustering クラスタリング
Algorithms
Hierarchical Clustering
k-Means
k-Medians
Fuzzy C-Means
Self-Organising Maps (SOM)
Expectation Maximization
DBSCAN
Validation
Data Structure Metrics
Stability Metrics
Neural Networks
Feedforward
Autoencorder
Probalistic
Time Delay
Convolutional
Regulatory feedback
Radial basis function(RBF)
Recurrent neural network
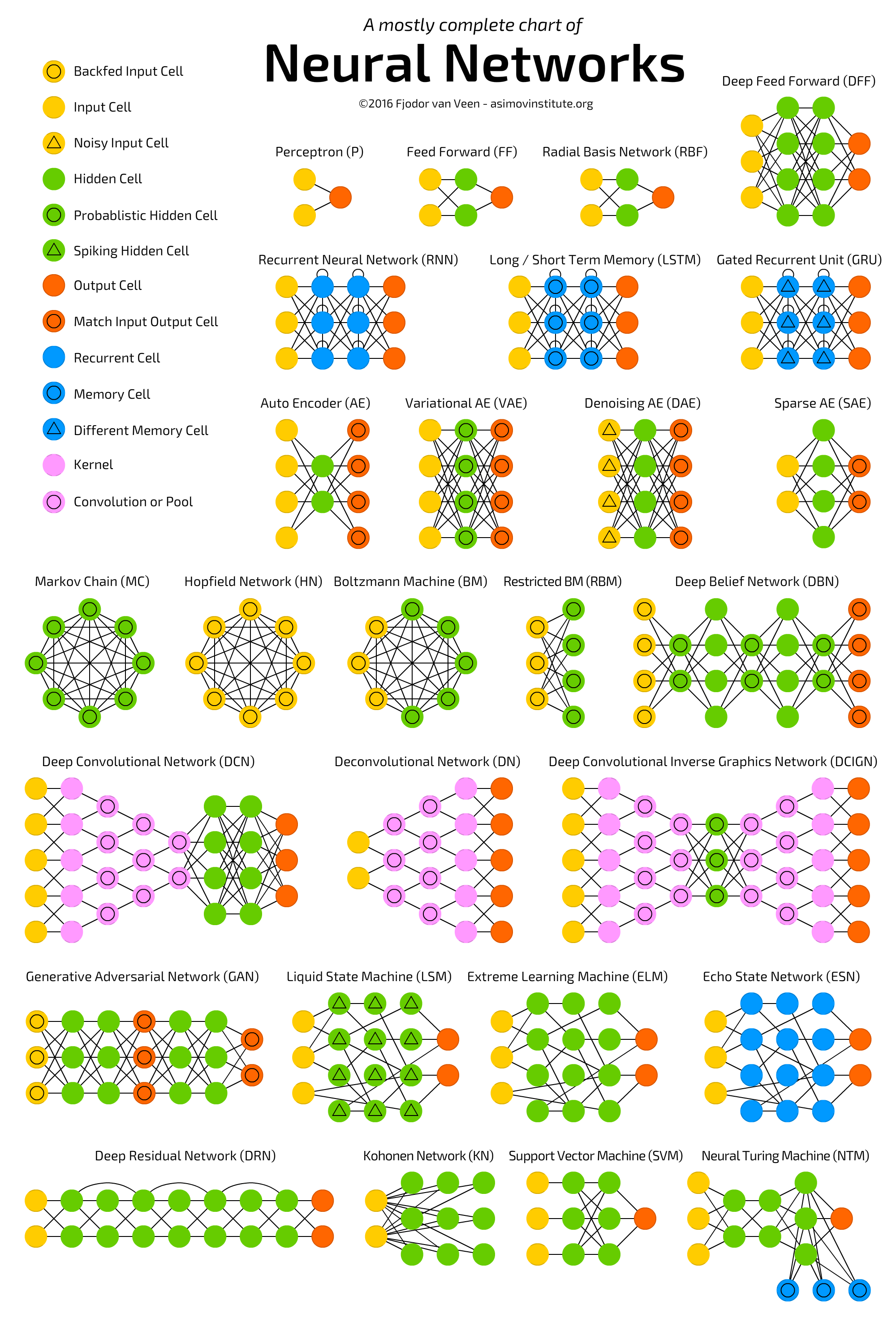
4)学会で発表される最新モデルの歴史
ObjectDetection

CNN architectures - LeNet AlexNet VGG GoogleNet ResNet
https://medium.com/@sidereal/cnns-architectures-lenet-alexnet-vgg-googlenet-resnet-and-more-666091488df5
情報ソース
Machine Learning Mind Map
https://github.com/dformoso/machine-learning-mindmap
Neural Network Map
https://jenstirrup.com/2017/08/01/how-do-you-evaluate-the-performance-of-a-neural-network-focus-on-azureml/
The Learning Machine
https://www.thelearningmachine.ai/ml
The mostly compelete chart of neural networks explained
https://towardsdatascience.com/the-mostly-complete-chart-of-neural-networks-explained-3fb6f2367464
Machine Learning Algorigorithms