TL;DR
2018 年に Google Brain から発表された論文 「Music Transformer: Generating Music with Long-Term Structure」 は、Transformerを音楽生成に応用し、長期的なフレーズ構造を捉えることに成功しました。特に Relative Position Representation (RPR) を導入することで、旋律や和声の自然さが大きく改善される点が注目されています。本記事ではMusic Transformer論文Sec 4.1「J.S. Bach Chorales」のAbsolute Position Representationのみを再現します。
※ RPRの比較は別稿予定・本稿では扱いません。
この記事でできるようになること
- 対象:Music Transformer 論文 Sec 4.1 の Absolute Position Representationのみを Hugging Face/GPT-2系で再現
- 出力:MIDIとFigure 3 風プロットで可視化
- 次回:Relative Position Representation(RPR)を同条件で比較して改善幅を検証
0. この記事で扱う範囲
- 本記事は Absolute Position Representation のベースライン確立が目的です。
- RPRの背景説明や実装比較は次回に回します(本稿では最小限の言及のみ)。
- 再現環境は Google Colab/L4 を前提にします(ローカルでも可)。
1. 実装環境
今回の実験を再現するにあたり、私は Google Colab Pro+(GPU: L4) を使用しました。
ローカルでも実行できますが、学習時間や依存関係の解決を考えると、最初は Colab 環境がおすすめです。
Python & ライブラリのバージョン
実行した環境の主要なバージョンは以下の通りです:
- Python: 3.12.11
- PyTorch: 2.8.0 + CUDA 12.6
- Transformers: 4.56.2
- Accelerate: 1.10.1
- Datasets: 2.20.0
- fsspec: 2024.5.0
- gcsfs: 2024.5.0
- music21: 最新版(コラール可視化用)
特に注意が必要なのは Transformers / Tokenizers / Accelerate の組み合わせです。
バージョンがずれると Trainer が動かなかったり ImportError が発生する可能性があります。
Colab 起動直後に以下のようなセルを実行しました:
# PyTorch (CUDA 12.6 対応ビルド)
!pip install --index-url https://download.pytorch.org/whl/cu126 \
"torch==2.8.0" "torchvision==0.23.0" "torchaudio==2.8.0"
!pip -q install "transformers==4.56.2"
!pip -q install "fsspec[http]==2024.5.0"
!pip -q install "accelerate>=1.4.0"
!pip -q install "datasets==2.20.0" "gcsfs==2024.5.0" sentencepiece scipy music21
!pip -q install "peft==0.17.1" "sentence-transformers==5.1.0"
これにより、学習・推論・可視化まで一貫して動作する環境が整います。補足ですが、実際にインストールしたaccelerateのバージョンは1.10.1です。 また、今回の実験では sentencepiece は結局使いませんでした。
ハードウェア
- GPU: NVIDIA L4
- VRAM: 約 24GB(環境によっては 48GB の場合もあり)
- CPU/RAM: Colab 標準(十分に余裕あり)
L4 であればブロックサイズ 512 / バッチサイズ 8 でも問題なく学習が回ります。
2. データ表現とトークン化
狙い
- JSB Chorales を 16分グリッドに量子化し、各ステップを S→A→T→B の順に直列化します。
- 音の持続は HOLD で表現し、可視化で“水平の伸び”が出るようにします。
- Round-Trip(往復変換) でバグを潰し、学習前にデータ健全性を担保します。
データセット
-
JSB Chorales
- バッハの四声コラールコーパス。機械学習用に整形されたデータセットでは 229曲 (train) / 76曲 (valid) / 77曲 (test) に分割されています。
- 各曲は SATB (Soprano, Alto, Tenor, Bass) の 4 声部で構成され、声部間の和声関係が明確なので「音楽的正しさ」を評価しやすい題材です。
前処理
- 楽譜を 16 分音符のグリッド に量子化
→ 4/4拍子の場合、1小節 = 16ステップに統一されます。 - 1 タイムステップごとに Soprano → Alto → Tenor → Bass の順でトークン化
例:[S_67, A_60, T_55, B_48] - HOLD 記号を用いて「音の持続」を表現(同じ音を繰り返すのではなく、伸ばしていることを明示)。
- 最終的に「1曲 = SATBトークン列」としてモデルに入力します。
例:1小節だけをトークン化して戻す
4/4で1小節=16ステップ、最初の2ステップだけ抜粋:SATBピッチ系列(HOLDは保持を意味)
t=0: [S=72, A=67, T=60, B=48]
t=1: [S=HOLD, A=67, T=HOLD, B=48]
直列化すると"S_72","A_67","T_60","B_48","S_HOLD","A_67","T_HOLD","B_48", ...逆変換では HOLD を直前値で展開するので、同音連打にならず“伸びる" 動作になります。──なぜ16分グリッド+HOLDかというと和声の整合性が視覚・聴覚で検証しやすいからです。
ステップ 1. データの取得と前処理
JSB Chorales データセットは、以下の GitHub リポジトリから取得可能です:
import torch
# --- CUDA 前提の環境チェック&共通 device 変数 ---
assert torch.cuda.is_available(), "CUDA GPU が必要です"
device = torch.device("cuda:0") # 単一GPU前提なら固定でOK
import os, json, math, numpy as np
from pathlib import Path
import datasets
# JSB Chorales データを取得(czhuang/JSB-Chorales-dataset に .mat がある想定)
if not os.path.exists("JSB-Chorales-dataset"):
!git clone -q https://github.com/czhuang/JSB-Chorales-dataset
# Load data from JSON file instead
with open("JSB-Chorales-dataset/Jsb16thSeparated.json", 'r') as f:
data = json.load(f)
この JSON には 16分音符ごとに SATB(Soprano/Alto/Tenor/Bass)が記録された配列 が含まれています。例えば [74, 70, 65, 58] のように、各時点の4声部の MIDI ピッチを持ちます。
トークン化関数
ここでは、入力が dict / [S_part, A_part, T_part, B_part] / [[S,A,T,B], ...] のいずれでも処理できるよう、汎用的な chorale_to_tokens_from_any を実装しました。
import numbers
# --- ユーティリティ ---
def _is_scalar_pitch(x):
# int(numpy.int含む) or "HOLD" をスカラ音高とみなす
return isinstance(x, numbers.Integral) or (isinstance(x, str) and (x == "HOLD" or x.isdigit()))
def _deep_flatten(seq):
out = []
stack = [seq]
while stack:
cur = stack.pop()
if isinstance(cur, (list, tuple)):
for e in reversed(cur): stack.append(e)
else:
out.append(cur)
return out
def _has_nested(seq):
return any(isinstance(e, (list, tuple)) for e in seq)
def _looks_like_events(seq):
# 例: [[start, dur, pitch], ...] or [{"s":..,"d":..,"p":..}, ...]
if not seq: return False
# list/tuple or dict が多ければイベントとみなす(最初要素だけでなく全体を見る)
structured = [e for e in seq if isinstance(e, (list, tuple, dict))]
if len(structured) < max(1, len(seq) // 2): # 半数未満ならイベントとは限らない
return False
# 代表一つで三つ組チェック
e = structured[0]
if isinstance(e, dict):
return any(k in e for k in ("s","start")) and any(k in e for k in ("d","dur")) and any(k in e for k in ("p","pitch"))
if isinstance(e, (list, tuple)) and len(e) >= 2:
# 2〜3要素が数値のものが続けばイベントらしい
return all(isinstance(x, numbers.Integral) for x in e[:2])
return False
# --- イベント→16分グリッド ---
def rasterize_voice_events(events, hold_token="HOLD"):
def as_triplet(e):
if isinstance(e, (list, tuple)) and len(e) >= 3:
return int(e[0]), int(e[1]), int(e[2])
elif isinstance(e, dict):
s = int(e.get("s", e.get("start", 0)))
d = int(e.get("d", e.get("dur", 1)))
p = int(e.get("p", e.get("pitch", 60)))
return s, d, p
else:
raise ValueError(f"Unsupported event format: {e}")
if not events: return []
tri = [as_triplet(e) for e in events]
T = max(s + d for s, d, _ in tri)
grid = [hold_token] * T
for s, d, p in tri:
if s < 0 or d <= 0: continue
grid[s] = p
for t in range(s+1, s+d):
if 0 <= t < T: grid[t] = hold_token
return grid
def to_timesteps_4parts(chorale, hold_token="HOLD"):
"""
入力の可能性:
(A) dict で S/A/T/B キーがある → そのまま4声部取得
(B) [S_part, A_part, T_part, B_part] の part-major
(C) [[S,A,T,B], [S,A,T,B], ...] の time-major ← ★今回これ
出力: {"S":[...], "A":[...], "T":[...], "B":[...]}(同一長にパディング)
"""
# --- (A) dict 形式 ---
if isinstance(chorale, dict):
keymap_candidates = [
("S","A","T","B"),
("s","a","t","b"),
("Soprano","Alto","Tenor","Bass"),
("soprano","alto","tenor","bass"),
]
part_seqs = None
for ks in keymap_candidates:
if all(k in chorale for k in ks):
part_seqs = [chorale[ks[0]], chorale[ks[1]], chorale[ks[2]], chorale[ks[3]]]
break
if part_seqs is None:
vals = [v for v in chorale.values() if isinstance(v, (list, tuple))]
if len(vals) < 4:
raise ValueError("Cannot infer SATB parts from dict.")
part_seqs = vals[:4]
# --- (C) time-major 形式: [[S,A,T,B], ...] を検出して転置 ---
elif (
isinstance(chorale, list)
and len(chorale) > 0
and isinstance(chorale[0], (list, tuple))
and len(chorale[0]) >= 4
and all(isinstance(x, numbers.Integral) or (isinstance(x, str) and (x == "HOLD" or x.isdigit()))
for x in chorale[0][:4])
):
# 4声部を取り出して転置
S = []
A = []
T = []
B = []
for step in chorale:
# step = [S,A,T,B,...] を想定
s, a, t, b = step[0], step[1], step[2], step[3]
S.append(int(s) if isinstance(s, numbers.Integral) or (isinstance(s, str) and s.isdigit()) else s)
A.append(int(a) if isinstance(a, numbers.Integral) or (isinstance(a, str) and a.isdigit()) else a)
T.append(int(t) if isinstance(t, numbers.Integral) or (isinstance(t, str) and t.isdigit()) else t)
B.append(int(b) if isinstance(b, numbers.Integral) or (isinstance(b, str) and b.isdigit()) else b)
part_seqs = [S, A, T, B]
# --- (B) part-major([S_part, A_part, T_part, B_part]) ---
else:
part_seqs = chorale # そのまま想定
parts = ["S","A","T","B"]
out = {}
# 各声部をスカラ化&長さ合わせ
for name, seq in zip(parts, part_seqs):
if not seq:
out[name] = []
continue
# ネストしていたらフラット化
if isinstance(seq, (list, tuple)) and any(isinstance(e, (list, tuple)) for e in seq):
flat = []
stack = [seq]
while stack:
cur = stack.pop()
if isinstance(cur, (list, tuple)):
for e in reversed(cur): stack.append(e)
else:
flat.append(cur)
else:
flat = list(seq)
def to_pitch(x):
if isinstance(x, numbers.Integral): return int(x)
if isinstance(x, str): return int(x) if x.isdigit() else x # "HOLD"など
return hold_token
out[name] = [to_pitch(x) for x in flat]
# 長さそろえ
T = max(len(out[p]) for p in parts)
for p in parts:
if len(out[p]) < T:
out[p] += [hold_token] * (T - len(out[p]))
return out
def chorale_to_tokens_from_any(chorale, hold_token="HOLD"):
"""
chorale: [[S,A,T,B], ...] (各要素は int もしくは "HOLD" など)
出力: ["S_60","A_55","T_HOLD","B_43", ...]
直前と同じ実音なら HOLD を出力。先頭で直前が無い場合は実音があれば実音、無ければ HOLD。
"""
# time-major -> SATB 各列(あなたの to_timesteps_4parts を使う場合は置き換え可)
# ここでは chorale がすでに [[S,A,T,B], ...] 前提で処理
parts = ["S","A","T","B"]
last = {p: None for p in parts}
seq = []
for step in chorale:
# step = [S,A,T,B] を想定(余分な列があれば先頭4つ)
S, A, T, B = step[:4]
cur = {"S":S, "A":A, "T":T, "B":B}
for p in parts:
v = cur[p]
# v が数値なら実音、文字列なら "HOLD" 等を許容
if isinstance(v, int):
if (last[p] is not None) and (v == last[p]):
seq.append(f"{p}_{hold_token}")
else:
seq.append(f"{p}_{v}")
last[p] = v
else:
# "HOLD" や None など非数値は保持扱い
if last[p] is not None:
seq.append(f"{p}_{hold_token}")
else:
# 先頭から HOLD が来た場合は、とりあえず HOLD を出す
# 逆変換側で None として扱われ、可視化/MIDI では休符か前値なしとして処理される
seq.append(f"{p}_{hold_token}")
return seq
ステップ 2. 語彙の構築
全データから一意なトークン集合を抽出し、ID に変換します:
# 語彙 & ID 作成(上書き)
vocab = set()
for split in (data['train'], data['valid'], data['test']):
for c in split:
vocab.update(chorale_to_tokens_from_any(c))
itos = sorted(vocab)
stoi = {s:i for i,s in enumerate(itos)}
print("vocab:", len(stoi))
train_token_ids = [[stoi[t] for t in chorale_to_tokens_from_any(c)] for c in data['train']]
valid_token_ids = [[stoi[t] for t in chorale_to_tokens_from_any(c)] for c in data['valid']]
test_token_ids = [[stoi[t] for t in chorale_to_tokens_from_any(c)] for c in data['test']]
lens_train = [len(x) for x in train_token_ids]
lens_valid = [len(x) for x in valid_token_ids]
print("train lens min/med/max:", min(lens_train), sorted(lens_train)[len(lens_train)//2], max(lens_train))
print("valid lens min/med/max:", min(lens_valid), sorted(lens_valid)[len(lens_valid)//2], max(lens_valid))
この実験では 約 100 種類のトークン(SATB 各音高と HOLD)が得られました。
3. モデルと学習
設計方針(最短で安定して学習が収束する構成)
- アーキテクチャ:GPT-2(絶対位置)
- n_layer=6 / n_head=8 / d_model=512 / n_inner=1024
- コンテキスト長:512 トークン(= 16分グリッド換算で 約32小節(4/4))
- データ切り出し:全曲連結 → ストライド窓切り(学習=BLOCK//2、評価=BLOCK)
- オプティマイザ:AdamW + Cosine decay + Warmup 5%
- 正則化:dropout=0.1 / weight_decay=0.01
- 安定化:EarlyStopping + load_best_model_at_end=True
ハイパーパラメータ表(この記事の既定値)
| 項目 | 値 | コメント |
|---|---|---|
| n_layer / n_head / d_model | 6 / 8 / 512 | 論文の“中規模”感に合わせた設計 |
| n_inner | 1024 | FFN 内次元 |
| block size | 512 | ≒ 32小節(4/4) |
| batch size | 8 | L4(24GB)で余裕。厳しければ 4 に |
| lr / スケジューラ | 5e-4 / cosine | warmup_ratio=0.05 |
| dropout | 0.1 | embd/attn/resid すべて |
| weight_decay | 0.01 | 典型値 |
| 早期終了 | patience=4 | 過学習や無駄学習の抑止 |
| 精度モード | bf16=True | L4 で安定。AMP 競合時は fp16=False 維持 |
データセット作成
import torch
from torch.utils.data import Dataset
class ChoraleLM(Dataset):
def __init__(self, token_ids, block_size=512, stride=None, concat=True):
self.samples = []
if stride is None:
stride = block_size
if concat:
# 全曲連結 → 大きなストリームから窓切り
stream = []
for ids in token_ids:
stream += ids
L = len(stream)
for i in range(0, max(0, L - block_size - 1), stride):
x = stream[i:i+block_size]
y = stream[i+1:i+1+block_size]
self.samples.append((x, y))
else:
# 曲ごと窓切り(短曲はスキップ)
for ids in token_ids:
if len(ids) < block_size + 1:
continue
for i in range(0, len(ids) - block_size - 1, stride):
x = ids[i:i+block_size]
y = ids[i+1:i+1+block_size]
self.samples.append((x, y))
def __len__(self):
return len(self.samples)
def __getitem__(self, idx):
x, y = self.samples[idx]
return {"input_ids": torch.tensor(x), "labels": torch.tensor(y)}
学習(HF Trainer:ログと再現性のスイッチ込み)
Hugging Face Trainer を用いて、クロスエントロピー損失で学習します。
# 1) 置き換えインポート
from transformers import GPT2Config, GPT2LMHeadModel
BLOCK = 512 # まずは安定重視。あとで512に上げてもOK
# 2) コンフィグ(Transfo-XL相当の容量感に近づける)
gconf = GPT2Config(
vocab_size=len(stoi),
n_positions=BLOCK, # あなたの block_size に合わせる
n_ctx=BLOCK,
n_embd=512,
n_layer=6, # Transfo-XL で 6層にしていたので揃える
n_head=8,
n_inner=1024, # FFN内次元(任意)
resid_pdrop=0.1,
embd_pdrop=0.1,
attn_pdrop=0.1,
bos_token_id=0, # 適当でOK(未使用なら気にしない)
eos_token_id=1, # 同上
)
model = GPT2LMHeadModel(gconf)
from transformers import Trainer, TrainingArguments, default_data_collator
from transformers.trainer_utils import IntervalStrategy # enum使う場合はこれ
from transformers import EarlyStoppingCallback
train_dataset = ChoraleLM(train_token_ids, block_size=BLOCK, stride=BLOCK//2, concat=True)
eval_dataset = ChoraleLM(valid_token_ids, block_size=BLOCK, stride=BLOCK, concat=True)
args = TrainingArguments(
output_dir="./out_jsb_gpt2",
learning_rate=5e-4,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
num_train_epochs=50, # 余裕を持たせつつ
eval_strategy=IntervalStrategy.EPOCH,
save_strategy="epoch",
load_best_model_at_end=True,
metric_for_best_model="eval_loss",
greater_is_better=False,
report_to="none",
bf16=True, fp16=False,
weight_decay=0.01,
label_smoothing_factor=0.1,
lr_scheduler_type="cosine",
warmup_ratio=0.05,
save_total_limit=3, # 直近3つだけ保持
logging_strategy=IntervalStrategy.EPOCH,
)
trainer = Trainer(
model=model,
args=args,
data_collator=default_data_collator,
train_dataset=train_dataset, # ← 既に作った BLOCK/concat=True のものを渡す
eval_dataset=eval_dataset, # ← 同上
callbacks=[EarlyStoppingCallback(early_stopping_patience=4)],
)
print("train_samples:", len(train_dataset), "eval_samples:", len(eval_dataset))
trainer.train()
print(trainer.evaluate()) # eval_loss = note-wise NLL/token
EarlyStopping を加えると無駄なエポックを省けます。学習ログを見ると、eval_loss ≈ 1.29 付近で安定しました。(論文でもクロスエントロピーに基づいた評価を報告しています)
実行結果の記録
train_samples: 861 eval_samples: 143 [1296/5400 00:48 < 02:33, 26.67 it/s, Epoch 12/50]
| Epoch | Training Loss | Validation Loss |
|---|---|---|
| 1 | 3.112500 | 2.506540 |
| 2 | 2.220400 | 1.673153 |
| 3 | 1.497600 | 1.388014 |
| 4 | 1.354800 | 1.338771 |
| 5 | 1.304700 | 1.311881 |
| 6 | 1.267900 | 1.301745 |
| 7 | 1.239000 | 1.296911 |
| 8 | 1.217800 | 1.294962 |
| 9 | 1.194100 | 1.295989 |
| 10 | 1.171900 | 1.295714 |
| 11 | 1.149100 | 1.308151 |
| 12 | 1.128700 | 1.315805 |
{'eval_loss': 1.2949620485305786, 'eval_runtime': 0.1887, 'eval_samples_per_second': 757.885, 'eval_steps_per_second': 95.398, 'epoch': 12.0}
4. 生成と論文 Figure 3 風のプロット
目的
- 学習済み(
load_best_model_at_end=Trueでロード済み)の Absolute Position モデルから SATB トークン列を生成 - 論文 Figure 3 風プロット と MIDI で “耳と目”により整合性を確認
- 任意で
LogitsProcessorを使って、声部順序・音域・保持・跳躍の制御を追加
前提(プロンプトと長さの扱い)
- プロンプトは 4 の倍数長(
S→A→T→Bの1ステップ=4トークン)に切るとズレを防げます。 - 生成長は
4 * (小節数 * 16)を目安に。例:8 小節 →4*8*16 = 512トークン。 - JSB の 16 分グリッドでは、4トークン=1ステップ, 16ステップ=1小節(4/4想定)。
LogitsProcessor で“壊れにくくする”
以下は 任意 です。Absolute Positionのみでも動きますが、
-
PartOrder(今出すべき声部だけ許可) -
Range(S/A/T/B の音域制限) -
HoldBias(保持に微ボーナス) -
MaxIntervalClip(跳躍の最大幅制限)
を入れると ギザギザ連打/声部交差/急跳躍 が抑えられ、論文Figure 3 風のプロットの安定度が上がります。
# 1) 語彙をパート別に仕分け
import re, numbers # Import re and numbers
from transformers.generation.logits_process import LogitsProcessor
import math
part_regex = re.compile(r'^(S|A|T|B)_(.+)$')
tok2part = {}
tok2pitch = {}
for tok, idx in stoi.items():
m = part_regex.match(tok)
if m:
part, val = m.group(1), m.group(2)
tok2part[idx] = part
# "HOLD" は None、数字なら int
tok2pitch[idx] = None if val == "HOLD" else (int(val) if val.isdigit() else None)
# 2) 音域(お好みで調整)
ranges = {
"S": (60, 84), # Soprano
"A": (55, 77), # Alto
"T": (48, 72), # Tenor
"B": (40, 67), # Bass
}
class IntervalPenaltyProcessor(LogitsProcessor):
"""
直前ピッチからの跳躍に罰則(各声部ごと)。
・中心0、σ=2〜3半音のガウス:±2〜3半音は許容、±5半音超は強めに減点
"""
def __init__(self, tok2part, tok2pitch, sigma=2.5, max_penalty=2.5):
self.tok2part = tok2part
self.tok2pitch = tok2pitch
self.sigma2 = sigma * sigma
self.max_pen = float(max_penalty)
self.vocab_size = len(tok2pitch)
def _expected_part(self, L_ctx):
# S,A,T,B の順で4トークン=1ステップ
return ["S","A","T","B"][L_ctx % 4]
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor):
L_ctx = input_ids.size(1)
part = self._expected_part(L_ctx)
# その声部の直前ピッチ(同一声部で一番近い過去を走査)
last_pitch = None
for t in range(L_ctx-1, -1, -1):
idx = input_ids[0, t].item()
if self.tok2part.get(idx) == part:
last_pitch = self.tok2pitch.get(idx)
break
if last_pitch is None:
return scores # 開始直後などは何もしない
# 各トークンに跳躍ペナルティ
pen = torch.zeros_like(scores)
for idx in range(self.vocab_size):
if self.tok2part.get(idx) != part:
continue
p = self.tok2pitch.get(idx)
if p is None: # HOLD は対象外(ここでは罰則しない)
continue
interval = abs(float(p) - float(last_pitch))
# ガウス: exp(-d^2 / (2σ^2)) を 0..1 → ロス加算に変換
w = math.exp(-(interval*interval) / (2.0*self.sigma2))
penalty = (1.0 - w) * self.max_pen # 跳躍ほど大
pen[0, idx] -= penalty
return scores + pen
class HoldBiasProcessor(LogitsProcessor):
"""
同音保持(HOLD)に微ボーナス:滑らかさを増す。
"""
def __init__(self, stoi, tok2part, tok2pitch, bonus=0.8):
self.stoi = stoi
self.tok2part = tok2part
self.tok2pitch = tok2pitch
self.bonus = float(bonus)
# 各声部の HOLD トークンID
self.hold_ids = {p: stoi.get(f"{p}_HOLD") for p in ["S","A","T","B"]}
def _expected_part(self, L_ctx):
return ["S","A","T","B"][L_ctx % 4]
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor):
L_ctx = input_ids.size(1)
part = self._expected_part(L_ctx)
hid = self.hold_ids.get(part, None)
if hid is None:
return scores
# 直前のその声部が実音(数値)なら、HOLDにボーナス
last_pitch = None
for t in range(L_ctx-1, -1, -1):
idx = input_ids[0, t].item()
if self.tok2part.get(idx) == part:
last_pitch = self.tok2pitch.get(idx)
break
if isinstance(last_pitch, numbers.Integral):
scores[0, hid] += self.bonus
return scores
class MaxIntervalClipProcessor(LogitsProcessor):
def __init__(self, tok2part, tok2pitch, max_ivl=5):
self.tok2part, self.tok2pitch = tok2part, tok2pitch
self.max_ivl = max_ivl
self.vocab = len(tok2pitch)
def __call__(self, input_ids, scores):
L = input_ids.size(1)
part = ["S","A","T","B"][L % 4]
last = None
for t in range(L-1, -1, -1):
idx = input_ids[0,t].item()
if self.tok2part.get(idx)==part:
last = self.tok2pitch.get(idx); break
if last is None: return scores
mask = torch.full_like(scores, float("-inf")) # Use full_like for device compatibility
for i in range(self.vocab):
if self.tok2part.get(i)!=part: continue
p = self.tok2pitch.get(i)
# Handle None for HOLD and check for integer before comparison
if (p is None) or (isinstance(p, numbers.Integral) and isinstance(last, numbers.Integral) and abs(p - last) <= self.max_ivl):
mask[0,i] = 0.0
return scores + mask
class BeatAwareHoldBonus(HoldBiasProcessor):
def __init__(self, *args, beat=4, offbeat_bonus=0.6, downbeat_bonus=0.2, **kw):
super().__init__(*args, **kw); self.beat=beat
self.offbeat_bonus, self.downbeat_bonus = offbeat_bonus, downbeat_bonus
def __call__(self, input_ids, scores):
L = input_ids.size(1)
part = ["S","A","T","B"][L % 4]
hid = self.hold_ids.get(part);
if hid is None: return scores
bonus = self.downbeat_bonus if ((L//4) % self.beat == 0) else self.offbeat_bonus
# 直前が実音なら付与(同音保持を促進)
last = None
for t in range(L-1,-1,-1):
idx=input_ids[0,t].item()
if self.tok2part.get(idx)==part:
last=self.tok2pitch.get(idx); break
if isinstance(last, numbers.Integral): scores[0,hid] += bonus
return scores
class PartOrderAndRangeProcessor(LogitsProcessor):
def __init__(self, stoi, tok2part, tok2pitch, ranges, order=("S","A","T","B")):
self.stoi = stoi
self.tok2part = tok2part
self.tok2pitch = tok2pitch
self.ranges = ranges
self.order = order
self.vocab_size = len(stoi)
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor) -> torch.FloatTensor:
# いま何トークン目か(バッチ1想定)
L_ctx = input_ids.size(1)
# プロンプトの長さに応じてオフセット(S,A,T,B のどこから始まるか)
# 例: プロンプトに S,A,T,B の4つがあれば offset=0 で S から再開
offset = L_ctx % 4
expected_part = self.order[offset]
# マスクを作成
mask = torch.full((self.vocab_size,), float("-inf"), device=scores.device, dtype=scores.dtype)
lo, hi = self.ranges[expected_part]
for idx in range(self.vocab_size):
part = self.tok2part.get(idx, None)
if part != expected_part:
continue
pitch = self.tok2pitch.get(idx, None)
# HOLD は常に許可、数値は音域チェック
if pitch is None or (isinstance(pitch, numbers.Integral) and lo <= pitch <= hi):
mask[idx] = 0.0
# 期待パート以外のロジットを -inf
scores = scores + mask
return scores
class AllowlistLogitsProcessor(torch.nn.Module):
def __init__(self, allow_ids, vocab_size: int):
super().__init__()
# allow_ids は buffer に保持(forward で device に合わせる)
self.register_buffer("allow_ids", torch.as_tensor(allow_ids, dtype=torch.long), persistent=False)
self.vocab_size = int(vocab_size)
def forward(self, input_ids, scores):
V = scores.size(-1)
# ★ device/dtype を scores に合わせる
mask = torch.full((V,), float("-inf"), device=scores.device, dtype=scores.dtype)
allow = self.allow_ids.to(scores.device)
allow = allow[(allow >= 0) & (allow < V)]
mask[allow] = 0.0
return scores + mask
allowed = set()
for p in ["S","A","T","B"]:
allowed.update([f"{p}_{v}" for v in range(48, 85)])
allowed.add(f"{p}_HOLD")
allowed_ids = torch.tensor([stoi[t] for t in allowed if t in stoi]) # device 指定を外す
allow_proc = AllowlistLogitsProcessor(allowed_ids, len(stoi))
order_proc = PartOrderAndRangeProcessor(stoi, tok2part, tok2pitch, ranges)
interval_proc = IntervalPenaltyProcessor(
tok2part, tok2pitch,
sigma=2.8, # ← 2.5 → 2.8(±3半音はより許容)
max_penalty=2.2 # ← 2.5 → 2.2(罰則をわずかに弱める)
)
hold_proc = HoldBiasProcessor(stoi, tok2part, tok2pitch, bonus=0.8)
clip_proc = MaxIntervalClipProcessor(tok2part, tok2pitch, max_ivl=5)
beat_hold = BeatAwareHoldBonus(
stoi, tok2part, tok2pitch,
bonus=0.0, # baseは0
beat=4,
offbeat_bonus=0.30, # ← 0.6 → 0.30
downbeat_bonus=0.20 # ← 0.2 そのまま
)
import math
from transformers.generation.logits_process import LogitsProcessor
model.eval().to("cuda")
start_tokens = ["S_60","A_55","T_52","B_43"]
start_ids = torch.tensor([[stoi[t] for t in start_tokens]], device=model.device) # ★ model に合わせる
max_new = max(1, model.config.n_positions - start_ids.size(1) - 4)
# 生成パラメータ
TEMP = 0.65
TOP_P = 0.82
TOP_K = 10
out = model.generate(
input_ids=start_ids,
attention_mask=torch.ones_like(start_ids),
max_new_tokens=max_new,
do_sample=True, temperature=TEMP, top_p=TOP_P, top_k=TOP_K,
pad_token_id=gconf.eos_token_id, use_cache=True,
logits_processor=[allow_proc, order_proc, clip_proc, interval_proc, beat_hold],
)
gen_ids = out[0].tolist()[start_ids.size(1):]
gen_tokens = [itos[i] for i in gen_ids]
steps = [gen_tokens[i:i+4] for i in range(0, len(gen_tokens), 4)]
print(steps[:8]) # 最初の8ステップ
チューニングの目安
- まとまりが弱い →
TEMPを 0.6 前後に下げる、TOP_Pを 0.8 付近に - 単調・伸びすぎ →
TEMPを 0.7 前後、TOP_Pを 0.9 付近に
論文 Figure 3 風プロット(SATB の“水平”と区切りを見る)
-
HOLDを直前値で展開してから、ステップ線(steps-pre) で描くのがコツ - 4 ステップごと(拍)& 16 ステップごと(小節)に縦線を引いて、周期性や終止の“気配” を目視
可視化例(論文のFigure 3 に似せたプロット):
# --- Figure3 風プロット: 時間(横) × pitch(縦) for SATB ---
import re, math
import numpy as np
import matplotlib.pyplot as plt
def tokens_to_grid_satb(tokens, hold_token="HOLD"):
"""
入力: tokens = ["S_60","A_55","T_52","B_43","S_60", ...]
4トークンで1タイムステップ(16分)を構成する前提
出力: dict {"S": [p_t...], "A": [...], "T": [...], "B": [...]}
HOLDは直前値を保持、先頭がHOLDなら None のまま
"""
# 4の倍数に切り落とし
n = (len(tokens) // 4) * 4
tokens = tokens[:n]
parts = {"S": [], "A": [], "T": [], "B": []}
last = {"S": None, "A": None, "T": None, "B": None}
# 4つずつ(S,A,T,B)の順で1ステップ
for i in range(0, n, 4):
step = tokens[i:i+4]
names = ["S","A","T","B"]
for name, tok in zip(names, step):
m = re.match(r"([SATB])_(.+)", tok)
if not m:
val = None
else:
_, valstr = m.groups()
if valstr == hold_token:
val = last[name]
else:
try:
val = int(valstr)
except:
val = last[name]
parts[name].append(val)
last[name] = val
# 長さを揃えるだけ(全て同じ長さのはず)
return parts
def plot_satb_grid(parts, step_ms=0, title="Generated (JSB 16th-note grid)"):
"""
parts: {"S":[...], "A":[...], "T":[...], "B":[...]} ピッチ系列
step_ms は任意(JSBは固定16分なので0でもOK)。x軸はステップ番号で表示。
"""
T = len(parts["S"])
x = np.arange(T) # 0,1,2,... 16分ステップ
fig, ax = plt.subplots(figsize=(12, 4))
colors = {"S":"tab:red", "A":"tab:orange", "T":"tab:green", "B":"tab:blue"}
labels = {"S":"Soprano", "A":"Alto", "T":"Tenor", "B":"Bass"}
# ステップ状の線で持続を可視化(HOLD 展開済み)
for p in ["B","T","A","S"]: # 下から重ねると見やすい
y = np.array(parts[p], dtype=float)
# None は欠損としてプロットしない(冒頭HOLDなど)
# 連続線を維持するため、None を NaN に
y[np.array([v is None for v in parts[p]])] = np.nan
ax.plot(x, y, drawstyle="steps-pre", lw=1.5, color=colors[p], alpha=0.9, label=labels[p])
# 開始点にマーカー(ノートオンらしさ)
# ノートオン= 直前と値が変わった地点
onset_idx = [0] + [i for i in range(1, T) if (not np.isnan(y[i]) and (np.isnan(y[i-1]) or y[i] != y[i-1]))]
ax.scatter(np.array(onset_idx), y[onset_idx], s=12, color=colors[p], alpha=0.9)
# 拍/小節グリッド(目安)
# 4ステップ=四分音符、16ステップ=小節(4/4想定)。楽曲により異なる場合あり
for t in range(0, T, 4):
ax.axvline(t, color="#cccccc", lw=0.5, alpha=0.6)
for t in range(0, T, 16):
ax.axvline(t, color="#888888", lw=0.8, alpha=0.7)
ax.set_xlim(0, T-1 if T>0 else 1)
ax.set_xlabel("Time steps (16th notes)")
ax.set_ylabel("MIDI pitch")
ax.set_title(title)
ax.legend(loc="upper right", ncol=4, fontsize=9, frameon=False)
ax.grid(axis="y", color="#eeeeee")
plt.tight_layout()
plt.show()
# ==== 使い方 ====
parts = tokens_to_grid_satb(gen_tokens, hold_token="HOLD")
plot_satb_grid(parts, title="Your generated sample (Figure 3 style)")
プロットの例
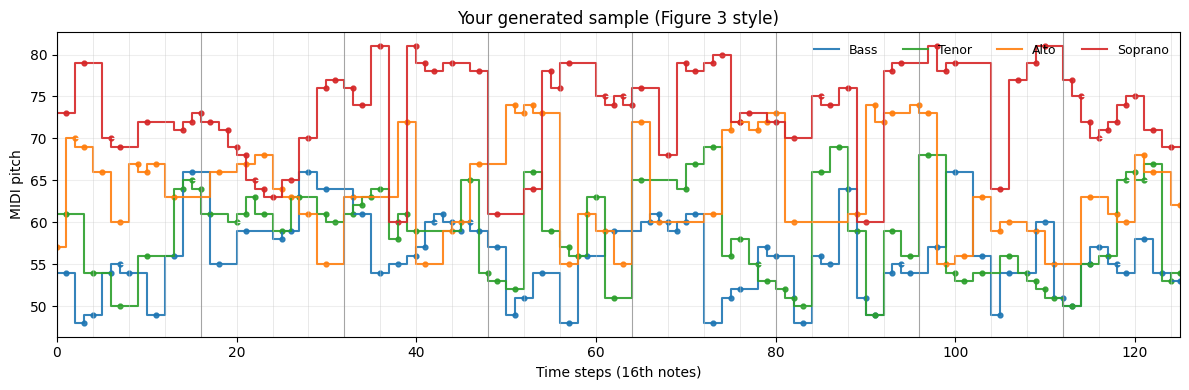
論文 Figure 3 風プロットの“見どころ”チェックリスト
- HOLDが効いているか:同音の“連打”でギザギザにならず、滑らかに水平に保たれている箇所がある。
- 音域の自然さ:S/A/T/B がそれぞれの妥当なレンジ内に収まっている(外声の過度な交差が少ない)。
- 拍/小節の規則性:小節線(16step)の前後で終止/区切りが現れやすい(とくにB, Tの“止まり”)。
- 跳躍の頻度:内声(A/T)は小さな動き中心、外声(S/B)は要所で跳躍が出る程度。
- カデンツの気配:節終端で同度/完全五度に収束するような動きが複数声部で同時に覗ける。
MIDI 出力(耳でのチェック)
最後にMIDIデータの生成です。
from music21 import stream, note, chord, midi
def tokens_to_stream(tokens, hold_token="HOLD"):
# SATBごとに展開
parts = {"S": [], "A": [], "T": [], "B": []}
last_pitch = {"S": None, "A": None, "T": None, "B": None}
for i in range(0, len(tokens), 4):
step = tokens[i:i+4] # S,A,T,B
for name, tok in zip(["S","A","T","B"], step):
_, val = tok.split("_")
if val == hold_token:
pitch = last_pitch[name]
else:
pitch = int(val)
last_pitch[name] = pitch
parts[name].append(pitch)
# music21 の stream に変換
score = stream.Score()
for name in ["S","A","T","B"]:
part = stream.Part(id=name)
for p in parts[name]:
if p is None:
part.append(note.Rest(quarterLength=0.25)) # 16分音符相当
else:
part.append(note.Note(p, quarterLength=0.25))
score.append(part)
return score
# 生成結果をMIDIに保存
s = tokens_to_stream(gen_tokens)
mf = midi.translate.streamToMidiFile(s)
mf.open("generated.mid", 'wb')
mf.write()
mf.close()
print("saved: generated.mid")
5. 参考
- Huang et al., Music Transformer: Generating Music with Long-Term Structure (2018), https://arxiv.org/abs/1809.04281
- JSB Chorales Dataset: https://github.com/czhuang/JSB-Chorales-dataset (利用規約/ライセンスは各リポジトリ記載に従ってください)