初めまして。Daimonji-Bucketと申します。
Qiitaというかブログ系自体初投稿です。
記念すべき初投稿がまさかこんなに地味な内容になるとは思いもよりませんでした・・・
マサカリは歓迎ですが、プラスチック製のものを優しく投げてください。
____ みなさん、numpyのfunctionの***as_strided***はお使いになったことがありますでしょうか。
私は音声処理を行うまで見ることはありませんでした。
扱いに注意しなければなりませんが(公式ドキュメントによると**'extreme care'**)
便利な時もあるので紹介いたします。
公式ドキュメントの説明はこちらです。
何をする関数なのか
さて、とりあえずas_stridedがどう動くか
確認してみます。
import numpy as np
from numpy.lib.stride_tricks import as_strided
x = np.arange(100, dtype=np.float64)
view = as_strided(x, (3, 3), (16, 8))
print(view)
こちらのコードを実行すると以下の結果が出力されます。
[[ 0. 2. 4.]
[ 3. 5. 7.]
[ 6. 8. 10.]]
一見元のarrayを読み飛ばしながら抜き出し、
新しいarrayを作っているように見えます。
しかし実際はas_stridedは
元のarrayのviewを作っています。
viewの中の値の実体はあくまで
元のarrayが確保したメモリーの場所にあります。
参照型の配列をshallow copyした感覚に近いかもしれません。
このviewは普通のnumpyのarrayと同じように扱えます。
a = view + np.ones((3, 3))
print(a)
[[ 1. 3. 5.]
[ 4. 6. 8.]
[ 7. 9. 11.]]
※注意点
要素の値を変更すると、元のarrayの値まで変わってしまいます。
view[0, 0] = 100
print(view)
[[ 100. 2. 4.]
[ 3. 5. 7.]
[ 6. 8. 10.]]
print(x)
[ 100. 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11.
12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 23.
24. 25. 26. 27. 28. 29. 30. 31. 32. 33. 34. 35.
36. 37. 38. 39. 40. 41. 42. 43. 44. 45. 46. 47.
48. 49. 50. 51. 52. 53. 54. 55. 56. 57. 58. 59.
60. 61. 62. 63. 64. 65. 66. 67. 68. 69. 70. 71.
72. 73. 74. 75. 76. 77. 78. 79. 80. 81. 82. 83.
84. 85. 86. 87. 88. 89. 90. 91. 92. 93. 94. 95.
96. 97. 98. 99.]
そのため、作られたviewには原則値の変更は行わないほうがよさそうです。特に公式ドキュメントで書かれているように、ベクトル化された書き込み(例: x[0, :] = np.ones(1, 3))は予期せぬ結果を生みかねないので避けるべきです。
writeable オプションをFalseにすることで書き込み自体を防ぐことができます
どう使うのか
ではas_stridedはどのように使うのでしょうか。
公式ドキュメントには以下のようにあります。
as_strided(x, shape=None, strides=None, subok=False, writeable=True)
最初の引数は元になるarray、shapeは生成されるviewの形というのは
なんとなく想像がつくかと思います。
一見分かりにくいのはstridesです。
(strideはこの分野での適切な訳が見つからなかったのですが、
日常的な使い方ですと歩幅とか一跨ぎを意味します。)
それを説明するにはnumpy.ndarrayの内部構造に
言及する必要があります。
そもそもndarrayは、
メモリに一つの地続きのセグメントとして、確保されています。
x = np.array([[0, 1], [2, 3]], dtype=np.float64)
x.tobytes()
b'\x00\x00\x00\x00\x01\x00\x00\x00\x02\x00\x00\x00\x03\x00\x00\x00'
要素ごとの区切りの領域を持っていません。(floatですので、指数部と仮数部が存在しています。)
ではあるindexの要素の値を取得する時は、
どのようにしているのでしょうか。
ndarrayにはstridesとitemsizeというattributeがあります。
x = np.arange(6, dtype=np.float64)
x = x.reshape(3, 2)
print(x.strides)
print(x.itemsize)
(16, 8) # (列方向, 行方向)
8
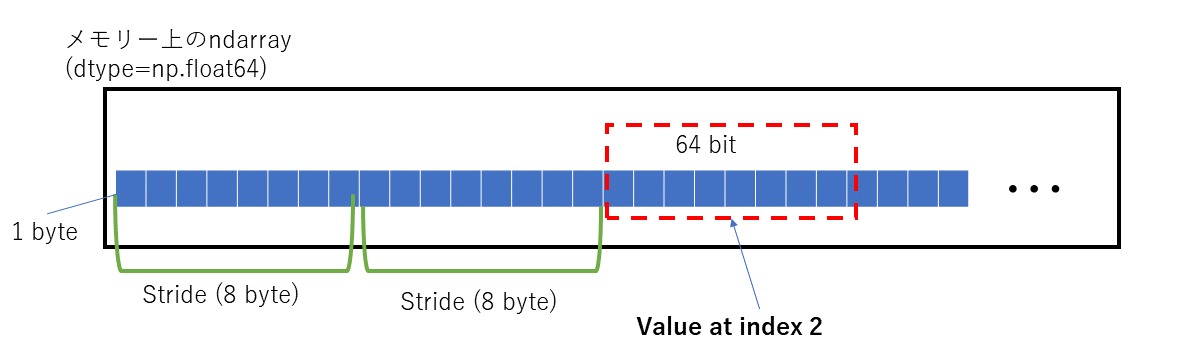
stridesはindexが一つ増えたとき移動するbyte数を示しています。
itemsizeは要素当たりのbyte数です。np.float64なら64bit=8byteですね。
あるindexの要素を取得するには、
このstridesとitemsizeを使います。
例えば
x[2, 1] #xはex6と同じ
の場合、
メモリーに確保されている領域の先頭から
16 byte x 2 + 16 byte x 1 = 48 byte分
進んだ部分へ移動し
そこからitemsizeで指定されている8 byte分の領域を取得します。
図にするとこうなります。
as_stridedは,
普段隠蔽されているこれらの操作を
stridesを指定することで行えます。
そのため、ex1のようにitemsizeと違うstridesの値を指定して、
飛び飛びで要素を取得するといったことも可能になります。
※注意点
うっかり元の領域のサイズをはみ出してしまうと、
予期せぬ値を取得します。
print(as_strided(x, (3, 3), strides=(16, 8))) # 危険なので真似しないでください。xはex6と同じ
[ 0.00000000e+000 1.00000000e+000 2.00000000e+000]
[ 2.00000000e+000 3.00000000e+000 4.00000000e+000]
[ 4.00000000e+000 5.00000000e+000 8.43666793e-312]]
この値に上書きでも行おうものなら・・・どうなるか分かりません。
また、stridesの値はitemsizeの倍数以外も指定できます。
print(as_strided(x, (3, 3), strides=(4, 4))) # xはex6と同じ
[[ 0.00000000e+000 0.00000000e+000 1.00000000e+000]
[ 0.00000000e+000 1.00000000e+000 5.29980882e-315]
[ 1.00000000e+000 5.29980882e-315 2.00000000e+000]]
こういった使い方は特に危険ではありませんが・・・使いどころはあるのでしょうか?
使用シーン
すぐに思いつくのは、windowを使った処理でしょうか。
画像処理や信号処理ではそういった処理はよく出てきます。
高速フーリエ変換、畳込み、poolingなどの実装で使えそうです。
こちらのstackoverflowの記事に
移動平均の例があります。
参考
- [numpy.lib.stride_tricks.as_strided — NumPy v1.13 Manual]
(https://docs.scipy.org/doc/numpy-1.13.0/reference/generated/numpy.lib.stride_tricks.as_strided.html) - [The N-dimensional array (ndarray) — NumPy v1.13 Manual]
(https://docs.scipy.org/doc/numpy-1.13.0/reference/arrays.ndarray.html)