概要
累積ゲイン図と累積リフト図は二値分類タスクにおける予測モデルの性能を評価する指標です。各図は、ターゲット(予測を試みる対象のラベル)への予測確率に基づいて順位が付けられたデータセットにおいて「その順位に基づいて、どれだけ早期に、どれだけ多くのターゲットの特定が可能か」という観点でその順位を評価します。
マーケティング分野での活用例を紹介します。特定の行動(例:購買)を起こす見込みが高い顧客群を設定し、効率的な施策の実施を試みる状況を想定します。この時、予測モデルが算出した予測確率を見込みと捉えて順位を付けることによって、見込みの高い顧客群の作成が可能です。このような状況で、予測モデルに基づいて算出された順位を評価する指標として、累積ゲイン図と累積リフト図の活用が可能です。
累積ゲイン図
累積ゲイン図は、ターゲットの予測確率に基づいて順位が付けられたデータセットに対して、その順位を閾値とした真陽性率(累積ゲイン)を表します。つまり、データセットにおけるターゲットの総数に対する特定の閾値までのターゲットの累積数の割合です。累積ゲイン図は、横軸をデータセット全体に対する順位に基づく上位からの割合、縦軸を真陽性率(累積ゲイン)としてプロットしたものです。以下に例を示します。
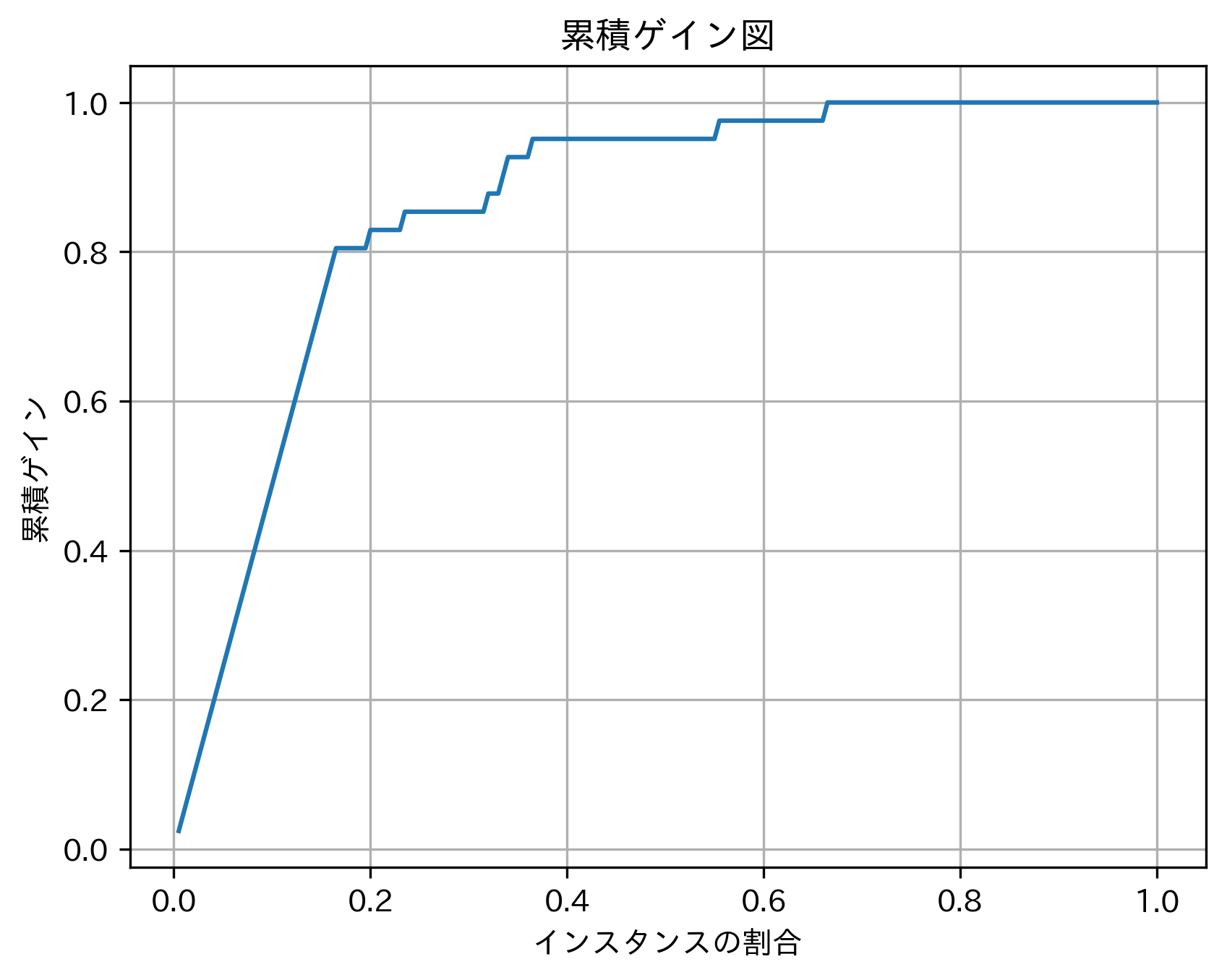
この図からは、例えば「上位20%のインスタンスは80%以上のターゲットが含まれている」と読み取ることが可能です。
続いて、Pythonのスクリプトによって累積ゲイン図を作成する例を紹介します。まず、以下のようなインスタンスごとにターゲットを示すラベル(label)と予測確率(predict_proba)が格納されたデータフレームを用意します。
label_and_predict_proba
| label | predict_proba | |
|---|---|---|
| 0 | 1 | 0.999475 |
| 1 | 0 | 0.00736806 |
| 2 | 0 | 0.0060101 |
| 3 | 0 | 0.0400943 |
| 4 | 0 | 0.0731952 |
| ... | ... | ... |
| 199 | 1 | 0.976242 |
今回は、データセット全体に対して、ターゲットに該当するインスタンスの割合が20%の不均衡な例を想定しています。
このデータフレームに対して以下の処理により累積ゲイン図を作成できます。
import pandas as pd
# 予測確率(predict_proba)に基づいて並び替え(順位付け)
ranked = label_and_predict_proba.sort_values(
by="predict_proba",
ascending=False
).reset_index()
# インスタンスの割合に対する累積ゲインを算出
cg = pd.DataFrame(
{
"インスタンスの割合": (ranked.index + 1)/len(ranked),
"累積ゲイン": ranked["label"].cumsum()/ranked["label"].sum(),
}
)
# 累積ゲイン図を描画
import matplotlib.pyplot as plt
import japanize_matplotlib
plt.rcParams["axes.axisbelow"] = True
plt.plot(cg["インスタンスの割合"], cg["累積ゲイン"])
plt.title("累積ゲイン図")
plt.xlabel("インスタンスの割合")
plt.ylabel("累積ゲイン")
plt.rcParams["axes.axisbelow"] = False
plt.grid(visible=True)
plt.show()
累積リフト図
累積リフト図は、予測モデルに基づく累積ゲインと予測モデルを使わないランダムな順位に基づく累積ゲインを比較した係数(累積リフト)を表します。つまり、ランダムな順位に基づいた選択と比較して予測モデルから算出された順位に基づいた選択は何倍のターゲットの捕捉が可能かが示されます。累積ゲイン図は、横軸をデータセット全体に対する順位に基づく上位からの割合、縦軸をランダムな順位と比較した係数(累積リフト)としてプロットしたものです。以下に例を示します。
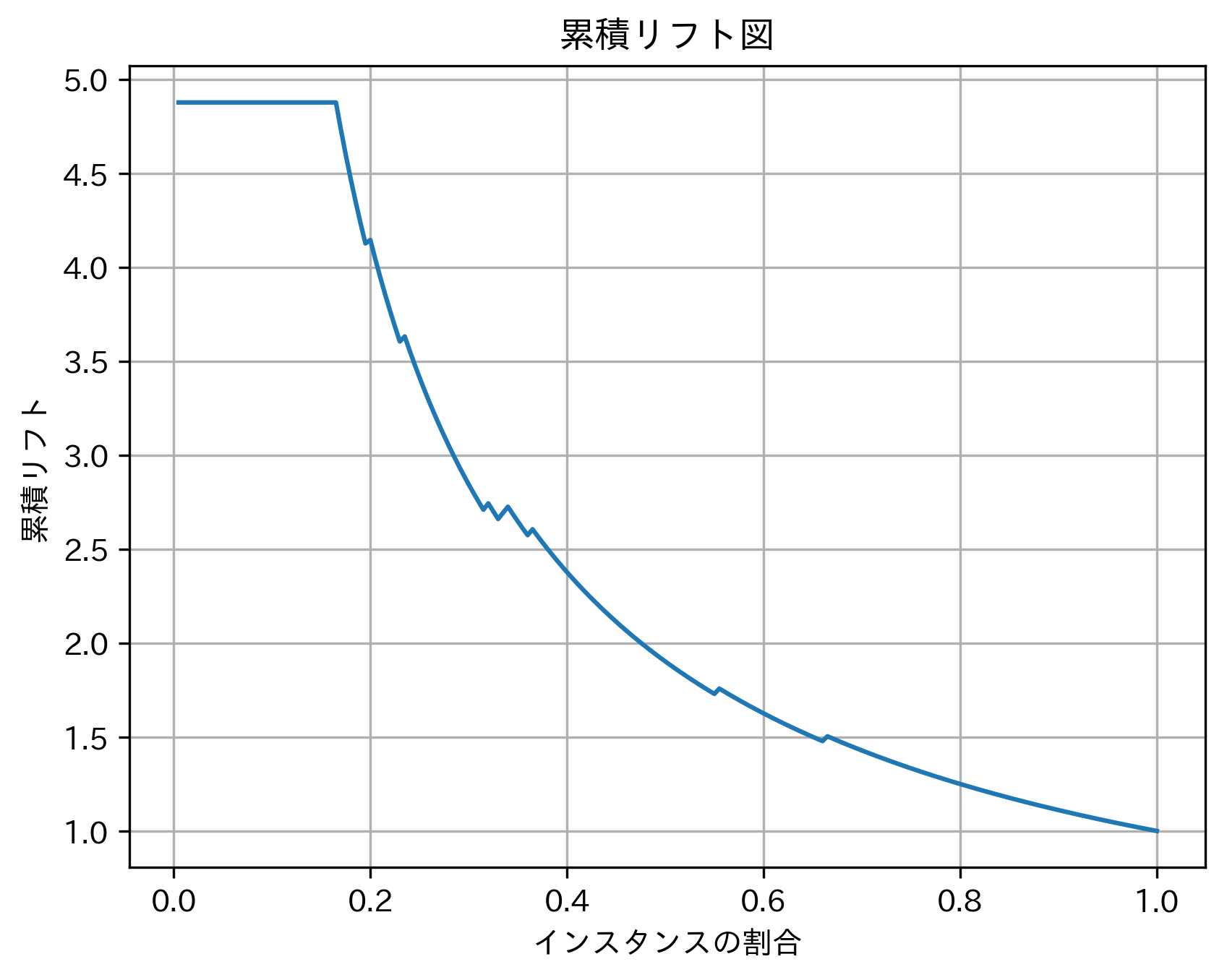
この図からは、例えば「上位20%のインスタンスにおいて、ランダムな順位に基づいた選択と比べて予測モデルから得られた順位に基づいた選択は4倍以上のターゲットが含まれている」と読み取ることが可能です。
続いて、Pythonのスクリプトによって累積リフト図を作成する例を紹介します。累積ゲイン図で挙げた例と同様のデータフレームを用意します。
このデータフレームに対して以下の処理により累積ゲイン図を作成できます。
import pandas as pd
# 予測確率(predict_proba)に基づいて並び替え(順位付け)
ranked = label_and_predict_proba.sort_values(
by="predict_proba",
ascending=False
).reset_index()
# インスタンスの割合に対する累積リフトを算出
cl = pd.DataFrame(
{
"インスタンスの割合": (ranked.index + 1)/len(ranked),
"累積リフト": ranked["label"].cumsum()/ranked["label"].sum()/((ranked.index + 1)/len(ranked)),
}
)
# 累積リフト図を描画
import matplotlib.pyplot as plt
import japanize_matplotlib
plt.rcParams["axes.axisbelow"] = True
plt.plot(cl["インスタンスの割合"], cl["累積リフト"])
plt.title("累積リフト図")
plt.xlabel("インスタンスの割合")
plt.ylabel("累積リフト")
plt.rcParams["axes.axisbelow"] = False
plt.grid(visible=True)
plt.show()
まとめ
二値分類タスクにおける予測モデルの性能を評価する指標として、累積ゲイン図と累積リフト図について紹介しました。それぞれ、予測モデルに基づいて算出された順位を評価する指標としての活用が可能です。