結論
まじで、すごい
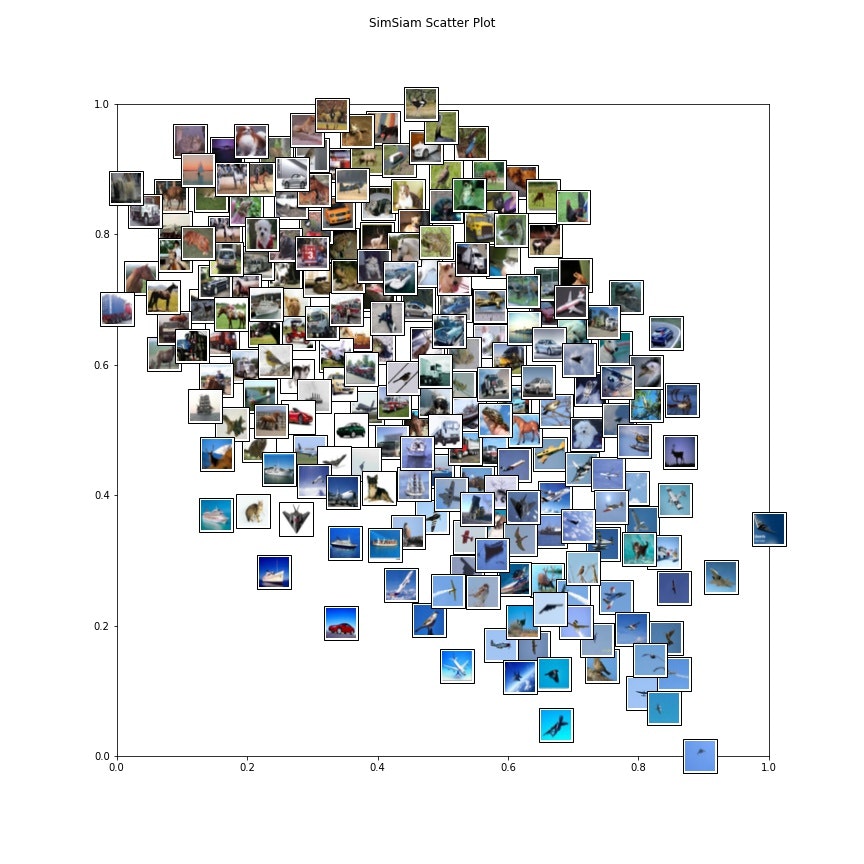
まずは結果から見てみる。
先んじて言っておくが、データのラベルは使っていない。かなり似たような画像が集まっていることがわかる
同様のものをラベルでも見てみる。ラベル単位でみるとあまり被ってない笑
背景が同じような色のものをまとめている感じになっているが、そうはいっても「似た画像は近くに行く」ということは学習できている

ついでに言うと、この手法、なんと実装が簡単!
プラスワンポイン
簡単に手法紹介
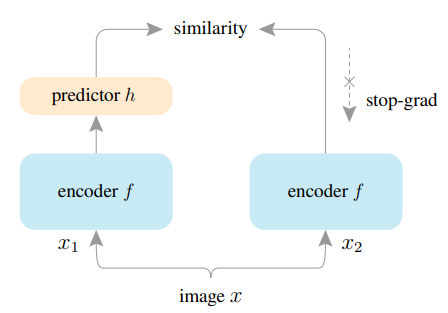
image xをaugmentationに二回かけてx1とx2を得る。それぞれをencoder(Resnetなど)に通しf1とf2を得る。さらにpredictor(浅いNN)に通してh1とh2を得る。
あとはf1とh2コサイン類似度ロスを取る。そうすると、別々のaugmentationを通した少し異なる画像が同じようなベクトルの特徴量になるように学習がされているイメージ。同様にf2とh1でもロスを取る。
他の手法との差分は
・勾配停止(ロスを取るときのf片方だけ止めるのがいいらしい)
・predictorを用意する(f1とf2でロスを取ってもダメらしい)
ことらしい。
簡単なコードの紹介
実際のコードは下にリンクを貼っておきます。独特な部分だけ簡単に触れます。
TwoCropsTransform
class TwoCropsTransform:
"""Take two random crops of one image as the query and key."""
def __init__(self, base_transform):
self.base_transform = base_transform
def __call__(self, x):
q = self.base_transform(x)
k = self.base_transform(x)
return [q, k]
名前の通りですが、画像一枚に対して2回augmentationをかけて2枚の画像にする関数で、この作業でx1とx2に分離させます。公式実装にもあるクラスです。引数で通常のaugmentationを渡しておきます。
Datasetクラス
class SimsiamDataset(torch.utils.data.Dataset):
def __init__(self, base_dataset, transform = None):
self.transform = transform
self.base_dataset = base_dataset
self.len = len(base_dataset)
def __len__(self):
return self.len
def __getitem__(self, idx):
x, _ = self.base_dataset[idx]
x0, x1 = self.transform(x)
return x0, x1
transformにあるのは先程のTwoCropsTransformです。今回はtorchvisionから呼び出したCIFA10をbase_datasetとして入力してます。本来ならpathを通してImage.openなどするところなので若干特殊仕様。
モデル構造
class SimSiam(nn.Module):
def __init__(self, base_encoder, dim=2048, pred_dim=512):
super(SimSiam, self).__init__()
self.encoder = base_encoder(num_classes=dim, zero_init_residual=True)
prev_dim = self.encoder.fc.weight.shape[1]
self.encoder.fc = nn.Sequential(nn.Linear(prev_dim, prev_dim, bias=False),
nn.BatchNorm1d(prev_dim),
nn.ReLU(inplace=True), # first layer
nn.Linear(prev_dim, prev_dim, bias=False),
nn.BatchNorm1d(prev_dim),
nn.ReLU(inplace=True), # second layer
self.encoder.fc,
nn.BatchNorm1d(dim, affine=False)) # output layer
self.encoder.fc[6].bias.requires_grad = False
self.predictor = nn.Sequential(nn.Linear(dim, pred_dim, bias=False),
nn.BatchNorm1d(pred_dim),
nn.ReLU(inplace=True), # hidden layer
nn.Linear(pred_dim, dim)) # output layer
def forward(self, x1, x2):
z1 = self.encoder(x1) # NxC
z2 = self.encoder(x2) # NxC
p1 = self.predictor(z1) # NxC
p2 = self.predictor(z2) # NxC
return p1, p2, z1.detach(), z2.detach()
base_encoderはtorchvisionなどから得られるtorchvision.models.resnet18などインスタンス化しないで渡してあげればいいです。
最後のz1.detach(), z2.detach()が提案手法の「勾配停止」です。勾配を停止させるのってdetach()するだけでいいんですね笑
ロス関数
criterion = nn.CosineSimilarity(dim=1)
...
loss = -(criterion(p1, z2).mean() + criterion(p2, z1).mean()) * 0.5
二つのベクトルのコサイン類似度をとります。コサイン類似度は1であるほど正の相関、-1であるほど負の相関を取ります。-1倍することで、正の相関が-1になります。ロスを下げる = 正の相関になるように学習が行われます。ロスの値は-1を目指してbackwardされます。ロスがマイナスなのってなんか新鮮
公式実装
著者のKaming He氏はどこかで。。。と思ったらあのMask RCNNの方ですね。
https://github.com/facebookresearch/simsiam
notebook
コピペベースでコーディングしてしまったので一部表記が揺れてたり無駄な変数あるのはすいません。。。
https://colab.research.google.com/drive/1H05Yhxfi3Tg3YWE8TWOhSN8mg2Ffc6iR?usp=sharing
参考
facebookの実装
https://github.com/facebookresearch/simsiam