Retty Advent Calendar2018の9日目の記事です。
昨日は@PONTA-N のReactNativeを利用したOTAの仕組みについての記事でした。
はじめまして!Rettyデータ分析チームの19卒内定者の二見と申します!
Rettyのデータ分析チームでは、日々の意思決定をデータ・ドリブンで行うために膨大なデータを分析しています。
Rettyでのデータ分析内容は様々ですが、大きく分けて以下の3つに大別できると考えています。
- ユーザーの現状を定量的に分析する
- 出てきた仮説に対して、定量的に検証する
- 行なった施策に対して、どれくらいの効果があったかを分析する
今回の記事では業務でも利用しているBigQueryとGoogle Colaboratoryを連携し、アプリユーザーの現状を決定木とランダムフォレストを用いて特徴量抽出しようと思います。
本記事では決定木とランダムフォレストのさわりの部分しか書いていません。数式は基本的に省略する方向性で書いていきたいと思います。ご了承ください。
Google Colaboratoryとは
今回利用するGoogle Colaboratoryを説明します。Google Colaboratoryは簡単に言うとブラウザ上で実行できるJupyter notebookです。誰でも無料で利用でき、Pythonや周辺ライブラリの環境構築を行わず済みます。
Google Colaboratoryは下記リンクから利用することができます。
Google Colaboratory
Google Colaboratory公式ドキュメント
また同じGoogle製品ということもあって、GCP関連との連携が容易なのも特徴です。Rettyのデータ分析チームではBigQueryを利用しているので、直接ColaboratoryからBigQueryを叩けるのが魅力だと思い採用しました。
BigQueryとColaboratoryを連携する
BigQueryとColaboratoryは簡単に連携することができます。Colaboratoryを開いて、下記コマンドでGCPの認証を通します。
from google.colab import auth
auth.authenticate_user()
指示にしたがって認証を通すと、以下のようにColaboratory上でBigQueryを叩くことができます。
%%bigquery --project bigqueryのproject_id 出力したいdataframe名(ex df)
# standardSQL
select
*
from
`各テーブル`
ただしBigQueryはスキャンごとに課金されるため、スキャン量には十分注意してください。セルを実行するたびに課金されるので、一度スキャンしたデータはどこかにとっておくか、期間を短くするPARTITIONTIMEなどを利用することをオススメします。
スキャン料金に関しては下記リンクからどうぞ
Rettyアプリのユーザー現状を分析する
今回はColaboratory上からBigQueryを実行し、Rettyアプリのユーザー行動を定量的に分析します。具体的にはアプリ内で検索したユーザーが実際にRettyアプリ内で予約を行うのかどうかのデータを用意し、その特徴量を抽出します。
Rettyの検索種類とUDF化
Rettyでは様々な飲食店を探せるように多岐にわたる検索種類が存在します。BigQueryで検索ごとのデータを取ってくるにはそれぞれを場合分けする必要があります。Rettyには主に以下の検索種類が存在します。
| 検索種類 | 説明 | 例 |
|---|---|---|
| エリアのみ | エリアのみで検索 | 渋谷駅 |
| 現在地のみ | 現在地のみで検索 | 現在地 |
| ジャンルのみ | ジャンルのみで検索 | 居酒屋 |
| 目的のみ | 目的のみで検索 | ランチ |
| フリーワードのみ | フリーワードのみで検索 | ワンコインランチ |
| エリア * ジャンル | エリアとジャンルの両方で検索 | 渋谷駅 居酒屋 |
| 現在地 * ジャンル | 現在地 * ジャンルの両方で検索 | 現在地 居酒屋 |
| ワンタップ | トップ画面からすぐ検索できる機能 | 現在地 |
| 店名 | 店名で直接検索 | - |
この他にもそれぞれの組み合わせで検索場合分けができます。場合分けを全てSQLで記述すると冗長になる上、複雑になるのでUDFで独自関数を定義しています。SQLのUDF例は下記のようになります。
## エリアのみ検索
create temp function onlyArea(event_name string,page_type string,prev_page_type string,prefecture_codes string, area_ids string,sub_area_ids string, station_ids string, category_type int64,large_category_type_jp int64,purpose_id int64,keyword_freeword string, lat float64, lng float64) as (
if(event_name = "pageview" and page_type = "search_result_list" and prev_page_type = "search_condition" and (prefecture_codes like "______" or prefecture_codes like "__" or prefecture_codes like "__" or area_ids like "___" or area_ids like "__" or area_ids like "_" or area_ids like "____" or sub_area_ids like "___" or sub_area_ids like "____" or sub_area_ids like "_____" or station_ids like "____" or station_ids like "_" or station_ids like "__" or station_ids like "___") and category_type is null and large_category_type_jp is null and purpose_id is null and keyword_freeword is null and lat is null and lng is null, 1,0)
)
;
## 店名検索
create temp function suggest(event_name string, page_type string, prev_page_type string) as (
if(event_name = "pageview" and page_type = "restaurant_top" and prev_page_type in ("search_condition","suggest_list"),1,0)
)
;
それぞれの検索のデータの入り方を定義しています。UDFではこの他にもjavascriptで細かな関数を定義することもできます。
このUDFを検索の種類だけ定義し、SQLでセッションごとの検索種類と最終的に予約を行なったかどうかのデータを取ってきます。SQLは300行を越えるため省略します。
|id|session_id|エリア|エリア * 駅|エリア * フリーワード|店名|ワンタップ|is_cv|
|:----:|:----:|:----:|:----:|:----:|:----:|:----:|:----:|:----:|:----:|:---:|
|1|afdaef34fd|3|0|0|0|0|0|
|2|gra33dabxs|0|0|0|0|3|1|
|3|nra8eadhhd|0|0|1|0|0|0|
|4|7fgngxzdjt|0|0|1|0|2|1|
|5|msfrrj91fd|2|1|0|0|1|0|
|6|ccghtd6hnd|0|0|0|1|1|0|
一部省略していますが、それぞれの検索種類について1セッションのidごとに回数が入っています。またis_cvに実際に予約をしたかどうかのデータを持たせています。1がアプリ内で予約をした、0がアプリ内で予約をしなかったという分類になっています。(上記表はダミーデータです)
ColaboratoryでRettyアプリの現状分析
いきなりランダムフォレストで特徴量を抽出する前にデータの分布や特徴を簡単に見ていきます。ColaboratoryはJupyterライクに直接pythonでゴリゴリ書けます。
# 必要なライブラリを通す
import numpy as np
import pandas as pd
import scipy as sp
from scipy import stats
# グラフ用ライブラリ
from matplotlib import pyplot as plt
import seaborn as sns
sns.set()
# 決定木とランダムフォレスト用のライブラリ
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import (roc_curve, auc, accuracy_score)
%matplotlib inline
%precision 3
必要なライブラリをimportします。また先ほどBigQueryから持ってきたデータはdfというDataFrameに格納されています。
## search_countはSQLの条件で便宜上出しただけなので、削除
df = df.drop("search_count",axis=1)
# 検索したかどうかのグループごとにそれぞれの検索の種類を出してみる
group_df = df.groupby("is_reserve")
pd.set_option('display.max_rows', 200) #colabで表示する行すうを拡張
group_df.describe().T.round(3)

上記画像のように予約をしたセッションとそうでないセッションで検索ごとの数値をみることができます。
実際のデータを公開することはできないのですが、実はどの検索種類を見ても四分位偏差は概ね0になっています。一部の検索をたくさん使うセッションに検索回数が偏っていることがわかりました。
それぞれの検索回数の相関関係をヒートマップで図示化しています。
ex_iscv = df.drop("is_cv",axis=1)
plt.figure(figsize=(13,13))
sns.heatmap(ex_iscv.corr(),annot=True)
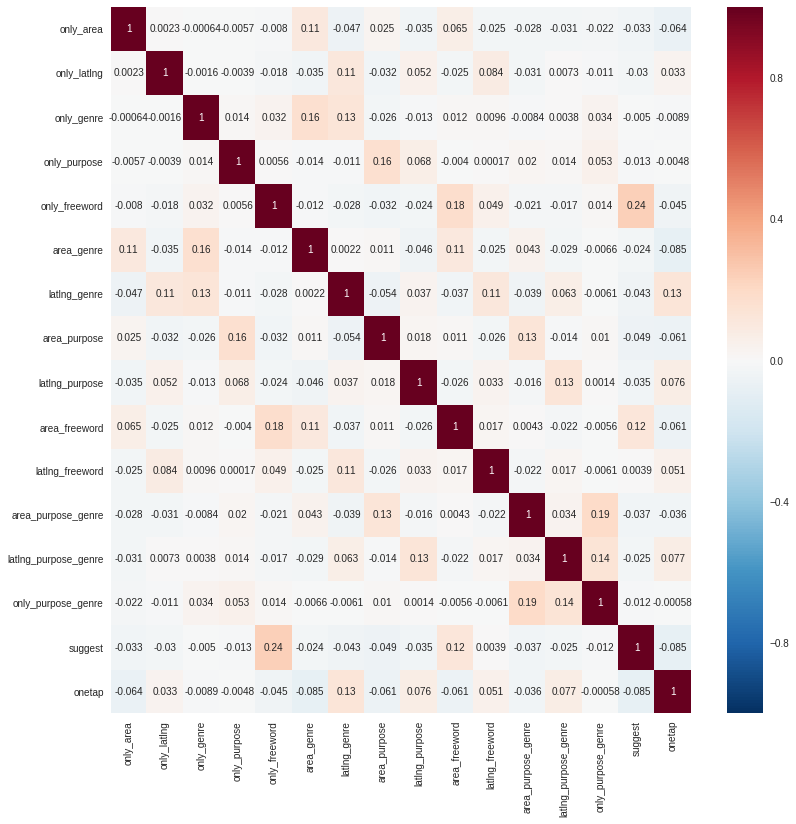
それぞれの検索種類ごとの相関関係を一気に確認することができます。suggest(店名検索)とonly_freeword(フリーワード検索)はどちらかが増えたらもう片方の検索も増えやすい傾向にあると言えそうです。
これは店名を自由入力で検索する体験と、そのまま店名から直接検索する体験が似ているので何となく感覚的に理解することができます。
ランダムフォレストでアプリユーザーの特徴量を抽出
決定木とは
決定木はデータ群に対して、条件分岐を行い分類する手法です。簡単な決定木を作ってみると以下のような感じになります。
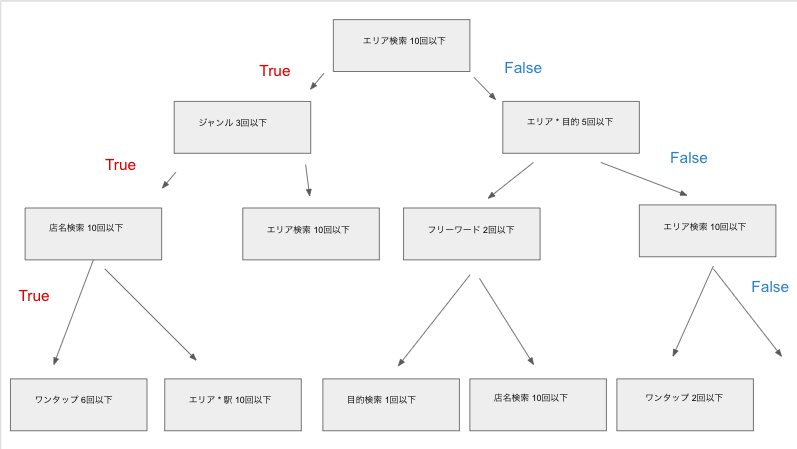
Trueが予約したセッションの検索回数の特徴、Falseが予約しなかったセッションの検索回数の特徴です。分類の基準はジニ係数という不純度で、分割前との不純度の差が大きい変数が選択されていきます。
ランダムフォレストとは
ランダムフォレストは主に分類問題や回帰問題で利用される分析手法です。ランダムフォレストは決定木の集合になっており、データの特徴量と重要度を抽出することができます。イメージとしては下記の図のような感じです。
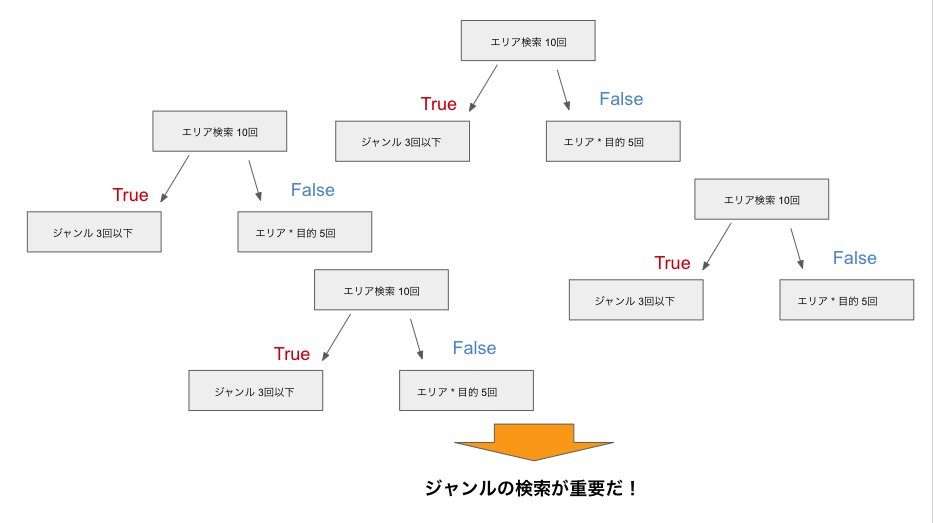
決定木との大きな違いは以下のようになっています。
- ブートストラップサンプリングを採用している
- 特徴量を抽出できる
- 複数の分類器から計算するので過学習しにくい
決定木をcolaboratory上で実装
Pythonではscikit-learnを利用することで決定木を簡単に実装できます。実装コードは下記になります。
# セッションidは不要なので、削除
df = df.drop("pvisit_id",axis=1)
# アプリ上で予約したかどうかで訓練用データとテストデータを分割
train_X = df.drop('is_cv',axis=1)
train_y = df.is_cv
(train_X, test_X ,train_y, test_y) = train_test_split(train_X, train_y, test_size = 0.5, random_state = 1)
# 決定木を作成
clf = DecisionTreeClassifier(random_state=0)
clf = clf.fit(train_X, train_y)
pred = clf.predict(test_X)
# 予測
pred = clf.predict(test_X)
fpr, tpr, thresholds = roc_curve(test_y, pred, pos_label=1)
auc(fpr, tpr)
accuracy_score(pred, test_y)
Colaboratory上で決定木を可視化するためにいくつかのライブラリをpipとaptでColaboratoryに取り込みます。
!pip install pydotplus
!pip install graphviz
!apt-get -qq install -y graphviz
最後に下記のコードで作成した決定木をcolaboratory上で可視化できます。
import pydotplus
from IPython.display import Image
from graphviz import Digraph
from sklearn import tree
from sklearn.externals.six import StringIO
dot_data = StringIO()
tree.export_graphviz(clf, out_file=dot_data,feature_names=train_X.columns, max_depth=3)
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
graph.write_pdf("graph.pdf")
Image(graph.create_png())
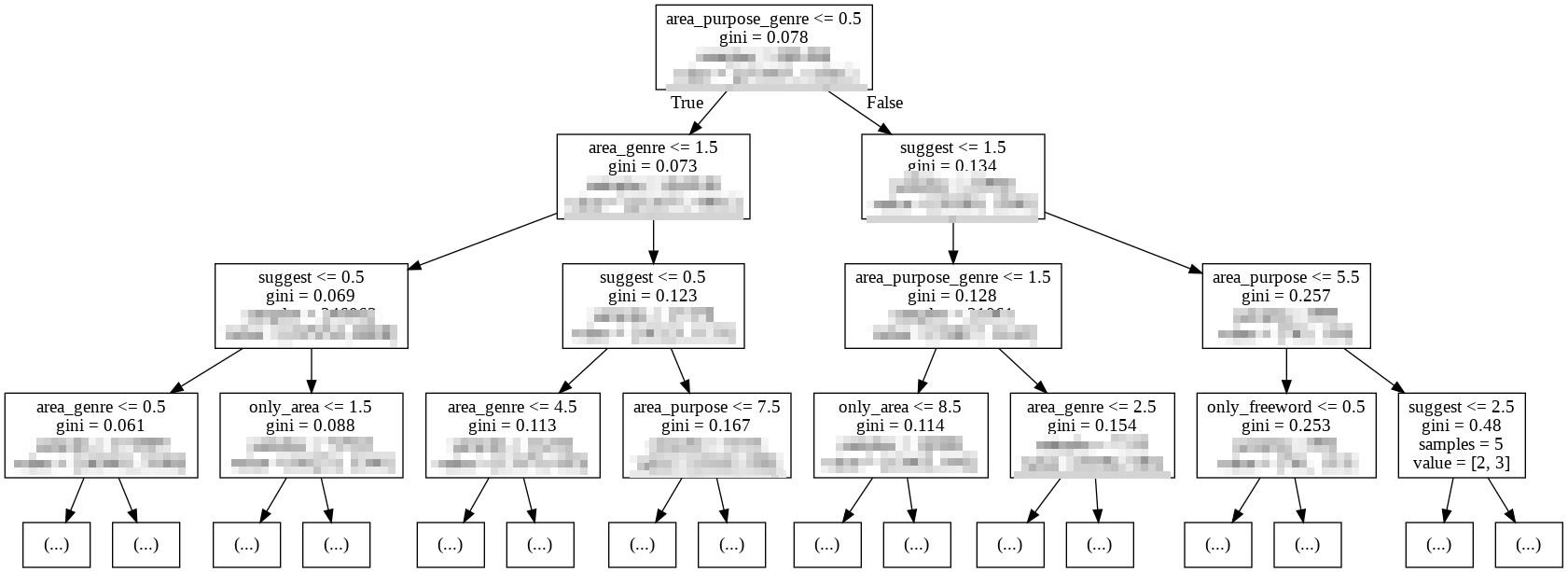
実際に可視化した決定木を見てみると、エリアと目的とジャンルの混ざった検索が0.5回以下かつエリアとジャンルの検索が1.5回以下、サジェストが0.5回以下だと予約する傾向にあることがわかります。
今回はデータの前処理を満足に行わなかったので、それぞれの傾向がバラバラのままのようです。
ランダムフォレストをcolaboratory上で実装
決定木一つだけだといまいち傾向が見えてこなかったので、複数の決定木を合わせて特徴量と重要度抽出してみます。また今回作成するランダムフォレストがどれくらい当てはまるのか平均二乗誤差と決定係数も計算します。
from sklearn.ensemble import RandomForestClassifier
## 200個の決定木からランダムフォレストで分類
clf = RandomForestClassifier(n_estimators=200, max_depth = 5)
clf = clf.fit(train_X, train_y)
pred = clf.predict(test_X)
fpr, tpr, thresholds = roc_curve(test_y, pred, pos_label=1)
auc(fpr, tpr)
accuracy_score(pred, test_y)
今回は決定木を200個作成して、ランダムフォレストで特徴量を抽出します。また下記のコードで平均二乗誤差(MSE)1と決定係数(R2)2も同時に算出します。
# 予測値を計算
y_train_pred = clf.predict(train_X)
y_test_pred = clf.predict(test_X)
# MSEの計算
from sklearn.metrics import mean_squared_error
print('MSE train : %.5f, test : %.5f' % (mean_squared_error(train_y, y_train_pred), mean_squared_error(test_y, y_test_pred)) )
# R^2の計算
from sklearn.metrics import r2_score
print('r2 score : %.5f, test : %.5f' % (r2_score(train_y, y_train_pred), r2_score(test_y, y_test_pred)) )
算出された値は下記のようになりました。

MSEは低いですが、R2がマイナスですね...
つまり今回抽出された特徴量と重要度を鵜呑みにするのは危険そうだということがわかります。
最後にどういう検索をすると予約しやすいかの特徴量を抽出し、可視化します。
# 特徴量をカラム名別で抽出
features = train_X.columns
importances = clf.feature_importances_
indices = np.argsort(importances)
f = pd.DataFrame({'number': range(0, len(importances)),
'feature': importances[:]})
f2 = f.sort_values('feature',ascending=False)
f3 = f2.ix[:, 'number']
for i in range(len(importances)):
print(str(i + 1) + " " + str(features[indices[i]]) + " " + str(importances[indices[i]]))
# 特徴量の重要度を図示化
plt.figure(figsize=(13,13))
plt.barh(range(len(indices)), importances[indices], color='lightblue', align='center')
plt.yticks(range(len(indices)), features[indices])
plt.show()
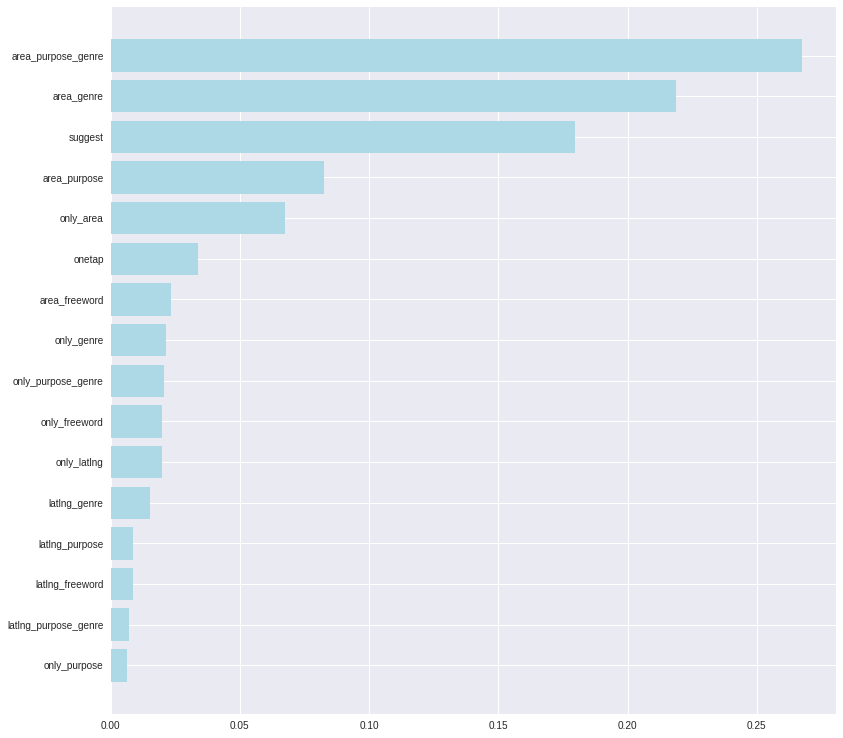
先ほど作った決定木とほとんど同じ順番で重要な変数だということがわかります。エリア・目的・場所で検索する人は検索回数によって予約するかどうかの結果を大きく左右することがわかります。
エリア・ジャンルの検索は回数割合が大きいので特徴量としても出やすいですね。suggestは店名検索ですが、具体的な店舗名で検索する人は予約するしないに大きく左右するということがわかりました。
今回の分析の問題点
今回は決定木とランダムフォレストを用いて特徴量可視化を行いましたが、今回の分析は以下のような問題があります。
- 決定係数がマイナス
- 当てはまりの良いモデルとは言えないので、そのまま施策は打てない
- データの前処理を行なっていないので、外れ値などは事前に除外した方が良さそう
- パラメータチューニングを行なっていない
- 他の変数を取り入れたり、除外するともう少し制度の良いランダムフォレスト作れるかも
- ハイパーパラメータを調整すると結果の改善が期待できるかも
ランダムフォレストは分類問題の他に回帰問題に利用することができます。今回は予約したかどうかのデータを1,0で分類しましたが、CVRなどのデータから回帰モデルを作ると別の要素が見えてくるかもしれません。
記事まとめ
Rettyの分析チームでは今回の記事のようにBigQueryから出てきたデータからユーザーの現状を分析したり、施策を打つ意思決定を行なっています。
今回の分析はBigQueryとColaboratoryの連携から決定木とランダムフォレストの入門まででした。大まかな特徴量は抽出できたのですが、パラメータ調整などができなかったので別の機会にゴリゴリやってみたいなと思います。
皆さんも何かのデータ群を分類したり、データを回帰で表したいときに決定木とランダムフォレスト使えるかもなと思い出してもらえたらと思います!
今後も様々な分析を行いながら日本最大級の実名制グルメサービスをグロースさせていきたいと思います。