はじめに
前回の記事では、Instana 大規模言語モデル(LLM)モニタリングの概要と主要なメリットについて説明しました。
今回は、具体的な設定方法と実践的な使用例に焦点を当て、より詳しく解説していきます。この記事を通じて、Instana LLMモニタリングを実際に導入し、効果的に活用するための手順を学んでいただけます。
モニタリングアーキテクチャの概要
Instana LLM モニタリングのアーキテクチャを以下の図で示します:
このアーキテクチャは以下の主要コンポーネントで構成されています:
- LLMアプリケーション層: 監視対象のLLMアプリケーション
-
モニタリングデータ収集層:
- OpenLLMetry (Traceloop SDK ): トレースの生成
- OpenTelemetry Data Collector for LLM (ODCL): メトリクスの収集
- データ処理・転送層: Instana Agent
- Instanaバックエンド: データの分析と可視化
本記事で紹介した方法は、Instanaエージェントを経由してInstanaバックエンドにデータを送信する手順となっています。ただし、トレースデータについては、Instanaエージェントを介さずに直接Instanaバックエンドに送信することも可能です。このエージェントレスを選択することで、LLMアプリケーションのモニタリングをより柔軟に構成できます。
コンポーネントの役割
ODCL(OpenTelemetry Data Collector for LLM)
- 主な役割:メトリクスの収集
- LLMアプリケーションから生成されるメトリクスデータ(トークン使用量、レイテンシー、コストなど)を収集し、Instanaに送信します。
- システムレベルで動作し、アプリケーションに依存しない汎用的なメトリクス収集を行います。
OpenLLMetry(Traceloop SDK)
- 主な役割:トレースの生成
- LLMアプリケーション内の各処理ステップ(プロンプト生成、API呼び出し、応答処理など)のトレース情報を生成します。
- アプリケーションコードに直接組み込まれ、詳細な実行フローを可視化します。
前提条件
- Instanaエージェントがインストールされていること
- Python 3.10以上がインストールされていること
- 監視対象のLLMアプリケーションが稼働していること
セットアップ手順
Instana LLMモニタリングをセットアップするには、主に以下の3つのステップが必要です:
- OpenTelemetry (OTel) Data Collector for LLM (ODCL)のインストール
- LLMアプリケーションの計装(インストルメンテーション)
- 環境変数の設定
それでは、各ステップを詳しく見ていきましょう。
1. ODCLのインストール
ODCLは、LLMアプリケーションからOpenTelemetryメトリクスを収集するためのコンポーネントです。
前提条件
-
Java SDK 11以上がインストールされていることを確認してください。以下のコマンドでバージョンを確認できます:
java -version -
Instanaエージェントの設定
Instanaエージェントの設定でOpenTelemetryのデータ受信が有効になっていることを確認してください。
configuration.yamlでcom.instana.plugin.opentelemetryが有効になっていて、gRPC、HTTPの通信が許可されていることを確認してください。(条件によっては両方)- gRPCを有効にすると4317ポートでListen
- HTTPを有効にすると4318ポートでListen
以下の設定を追加して、OpenTelemetryの設定ファイルを作成します:
com.instana.plugin.opentelemetry: grpc: enabled: true http: enabled: true設定ファイルの編集後、エージェントを再起動してください。
注意: エージェントの再起動方法は、インストール環境によって異なる場合があります。詳細はInstanaのドキュメントを参照してください。
インストール手順
-
インストールパッケージをダウンロードします:
wget https://github.com/instana/otel-dc/releases/download/v1.0.0/otel-dc-llm-1.0.0.tar -
パッケージを展開します:
tar xf otel-dc-llm-1.0.0.tar -
設定ファイルを編集します:
cd otel-dc-llm-1.0.0 vi config/config.yamlconfig.yamlファイルで以下の項目を設定します:-
otel.backend.url: Instanaエージェントのアドレス(例:http://<instana-agent-host>:4317) -
otel.service.name: データコレクタの名前(任意の文字列) -
otel.service.port: データコレクタがメトリクスデータを受信するためのリスニングポート(デフォルトは8000) -
<ai-system>.price.prompt.tokens.per.kilo: プロンプトトークン1000個あたりの単価 -
<ai-system>.price.complete.tokens.per.kilo: 生成トークン1000個あたりの単価
config.yamlファイルのサンプル
llm.application: LLM_DC instances: - otel.backend.url: http://localhost:4317 otel.service.name: Tokyo-DC1 otel.service.port: 8000 #使用するAIプロバイダーの設定のみ構成してください watsonx.price.prompt.tokens.per.kilo: 0.0 watsonx.price.complete.tokens.per.kilo: 0.0 openai.price.prompt.tokens.per.kilo: 0.0 openai.price.complete.tokens.per.kilo: 0.0 anthropic.price.prompt.tokens.per.kilo: 0.0 anthropic.price.complete.tokens.per.kilo: 0.0以下は、各AIプロバイダーの設定値例です。実際の使用時には、各プロバイダーの最新の価格情報を確認してください。
-
# WatsonX
watsonx.price.prompt.tokens.per.kilo: 1.5
watsonx.price.complete.tokens.per.kilo: 6.0
# OpenAI (GPT-3.5-turbo)
openai.price.prompt.tokens.per.kilo: 1.5
openai.price.complete.tokens.per.kilo: 2.0
# Anthropic (Claude)
anthropic.price.prompt.tokens.per.kilo: 11.02
anthropic.price.complete.tokens.per.kilo: 32.68
注意事項
価格は頻繁に変更される可能性があるため、定期的に各プロバイダーの公式情報を確認してください。
使用するモデルやサービスレベルによって価格が異なる場合があります。
一部のプロバイダーでは、入力(プロンプト)と出力(完了)トークンで異なる価格を設定している場合があります。
実際の使用時には、これらの値を自身のユースケースと契約に基づいて調整してください。
-
Javaのログ設定を行います:
vi config/logging.propertieslogging.propertiesファイルで、必要に応じてJavaのログ設定を行います。 -
データコレクタを起動します:
nohup ./bin/otel-dc-llm >/dev/null 2>&1 &注:
tmuxやscreenなどのツールを使用して、このプログラムをバックグラウンドで実行することもできます。
2. LLMアプリケーションの計装
LLMアプリケーションを計装するには、OpenLLMetryのTraceloop SDKを使用します。以下の手順で設定を行います:
※2024年7月7日時点の手順
# Traceloop SDKのインストール
pip install traceloop-sdk==0.24.0
# 必要な依存関係のインストール(例:OpenAIの場合)
pip install openai==1.35.10
アプリケーションコードに以下の行を追加して、Traceloopを初期化します:
from traceloop.sdk import Traceloop
Traceloop.init()
複雑なワークフローやチェーンがある場合は、@workflowデコレータを使用して注釈を付けることができます:
from traceloop.sdk.decorators import workflow
@workflow(name="suggest_answers")
def suggest_answers(question: str):
# 関数の実装
3. 環境変数の設定
以下の環境変数を設定して、トレースとメトリクスのエクスポートを構成します:
export TRACELOOP_BASE_URL=<instana-agent-host>:4317
export TRACELOOP_METRICS_ENABLED="true"
export TRACELOOP_METRICS_ENDPOINT=<otel-dc-llm-host>:8000
export TRACELOOP_HEADERS="api-key=DUMMY_KEY"
export OTEL_EXPORTER_OTLP_INSECURE=true
export OTEL_METRIC_EXPORT_INTERVAL=10000
各環境変数の説明:
-
TRACELOOP_BASE_URL: Instanaエージェントのホストとポートを指定します。これはトレースデータの送信先です。
例:export TRACELOOP_BASE_URL="localhost:4317"
注意:IPアドレスを使用すると警告が表示される場合があります。その場合は、localhostを使用してください。 -
TRACELOOP_METRICS_ENABLED: メトリクス収集を有効にするかどうかを指定します。"true"に設定することで有効になります。 -
TRACELOOP_METRICS_ENDPOINT: OpenTelemetry (OTel) Data Collector for LLM (ODCL)のホストとポートを指定します。これはメトリクスデータの送信先です。 -
TRACELOOP_HEADERS: APIキーなどの追加ヘッダーを指定します。この例では、ダミーのAPIキーを使用しています。
例:export TRACELOOP_HEADERS="api-key=YOUR_INSTANA_AGENT_KEY"
実際の環境では、DUMMY_KEYの箇所をInstanaのエージェントキーに置き換えてください。 -
OTEL_EXPORTER_OTLP_INSECURE: OpenTelemetry エクスポーターが安全でない接続(非SSL)を使用するかどうかを指定します。開発環境では "true" に設定することがありますが、本番環境では適切なセキュリティ設定を行ってください。 -
OTEL_METRIC_EXPORT_INTERVAL: メトリクスのエクスポート間隔をミリ秒単位で指定します。この例では10秒(10000ミリ秒)に設定しています。
また、使用するLLMプロバイダーに応じて、以下の環境変数も設定します:
-
OpenAIの場合:
export OPENAI_API_KEY=<openai-api-key> -
IBM watsonxの場合:
export IAM_API_KEY=<watsonx-iam-api-key> export PROJECT_ID=<watsonx-project-id> -
Anthropicの場合:
export ANTHROPIC_API_KEY=<anthropic-api-key>
これらのAPIキーは、各LLMサービスへのアクセスに必要です。適切なキーを使用し、セキュリティに注意して管理してください。
環境変数を正しく設定することで、Instana LLM モニタリングは適切にデータを収集し、Instanaバックエンドに送信することができます。これにより、LLMアプリケーションの詳細なモニタリングと分析が可能になります。
実践的な使用例
ここでは、OpenAIのGPTモデルを使用した簡単なチャットボットアプリケーションを例に、Instana LLM モニタリングの使用例を紹介します。
まず、以下のコードをchatbot.pyというファイル名で保存してください:
import os
import time
from openai import OpenAI
from traceloop.sdk import Traceloop
from traceloop.sdk.decorators import workflow
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
Traceloop.init(app_name="chatbot_service")
@workflow(name="chatbot_response")
def generate_response(prompt):
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": prompt}],
max_tokens=150
)
return response.choices[0].message.content
def chatbot():
print("ChatGPTを使用したチャットボットです。終了するには 'quit' と入力してください。")
while True:
user_input = input("あなた: ")
if user_input.lower() == 'quit':
break
response = generate_response(user_input)
print(f"ボット: {response}")
time.sleep(1) # APIレート制限を考慮
if __name__ == "__main__":
chatbot()
チャットボットの実行手順
-
必要な環境変数が設定されていることを確認します(特に
OPENAI_API_KEY)。 -
ターミナルで以下のコマンドを実行してチャットボットを起動します:
python3 chatbot.py -
プロンプトが表示されたら、質問を入力します。
-
チャットボットの応答を確認します。
-
終了するには、'quit'と入力します。
チャットボットの出力例
以下は、チャットボットを実行した際の出力例です:
ChatGPTを使用したチャットボットです。終了するには 'quit' と入力してください。
あなた: こんにちは、今日の天気はどうですか?
ボット: 今日の天気は晴れで、気温は20度です。気持ちの良い一日になりそうですね。何か予定がありますか?
あなた: この暑日の過ごし方を教えてください。
ボット: 1. 水分補給を忘れずに、こまめに水やスポーツドリンクを飲むようにしましょう。
2. 熱中症対策として、涼しい場所で過ごしたり、こまめに休憩を取ることが大切です。
3. 日差しを避けるために、帽子や日傘、日焼け止めなどを使用して肌の保護をしましょう。
あなた: quit
このチャットボットを実行することで、Instana LLM モニタリングがアプリケーションの動作を自動的に監視し始めます。各リクエストとレスポンスがトレースされ、設定したメトリクスが収集されます。
次のセクションでは、これらの収集されたデータをInstana UIで確認する方法について説明します。
モニタリング結果の確認
アプリケーションを実行後、Instana UIで以下の手順でモニタリング結果を確認できます:
アプリケーションビュー
- Instana UIを開き、「アプリケーション」をクリックします。
- アプリケーションの画面にて「サービス」タブをクリックします。
- フィルターを使用して「service name: chatbot_service」で検索し、サービスのリストから「chatbot_service」を選択します。

4.「chatbot_service」 のサービス画面では、以下のような重要なメトリクスを確認できます :
- 1秒あたりの呼び出し数
- エラー率
- 平均待ち時間
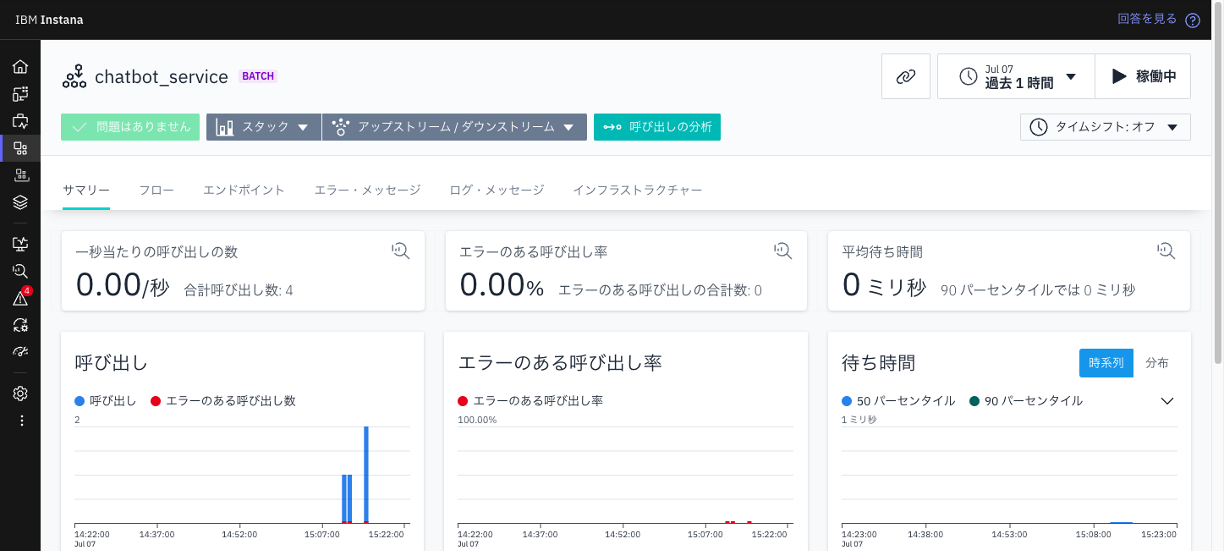
5.「呼び出しの分析」ボタンをクリックし、「アプリケーション / 呼び出し」画面を確認します。ここでは、「chatbot_service」の全ての呼び出しが一覧表示されます。
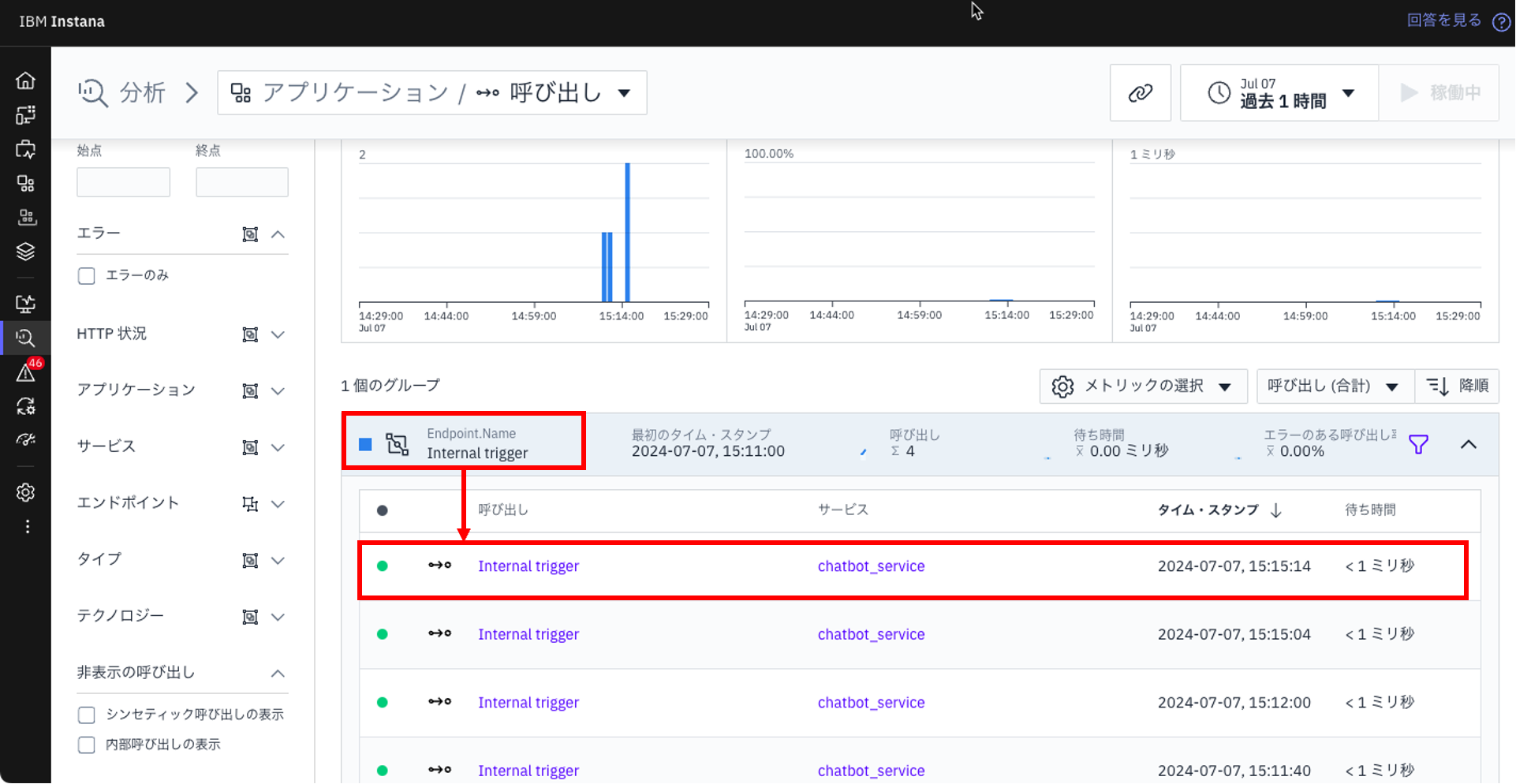
特定の呼び出しを確認したい場合は、例えば「Endpoint.name : Internal trigger」をクリックし、呼び出しの一覧から該当する項目をクリックして詳細を確認します。
6.分析 / 呼び出し」の画面で「chatbot_service」の詳細を確認できます。
画面中央の「呼び出し」の「Internal trigger」、「chatbot_response」、「openai.chat」と順番にクリックします。
「openai.chat」をクリックすると右側に、呼び出しの詳細が表示されます。
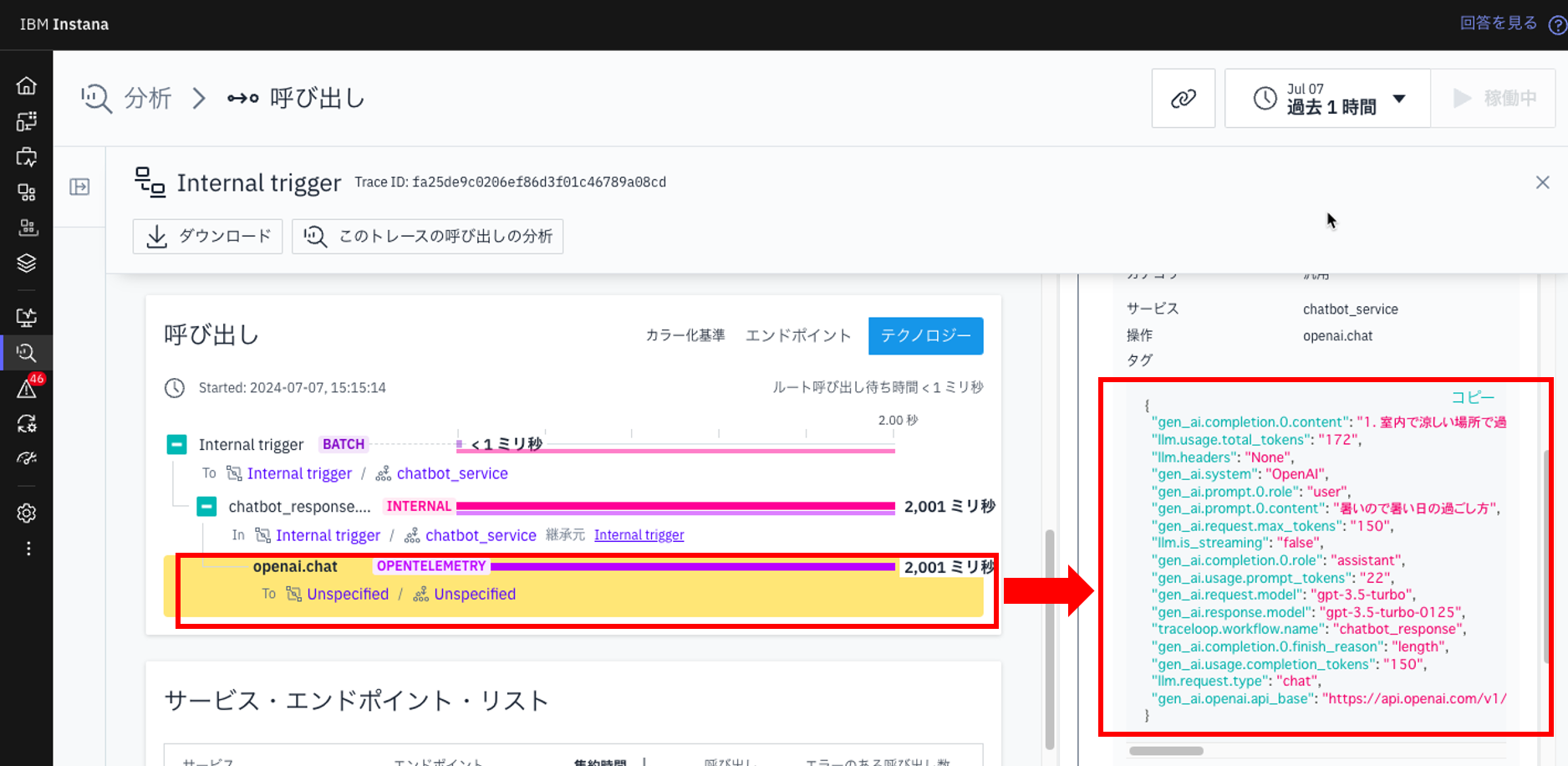
7.openai.chatの処理に関する情報を確認できます。具体的には以下の情報を把握できます:
- 消費トークン数
- 質問と回答(入出力)
- 使用モデル
- APIエンドポイント

これにより、LLMアプリケーションの開発から本番利用まで、すべての実行結果を詳細に確認しながら開発・運用することが可能です。
インフラストラクチャビュー
-
Instana UIを開き、「インフラストラクチャー」をクリックします。
-
「インフラストラクチャーの分析」をクリックします。
-
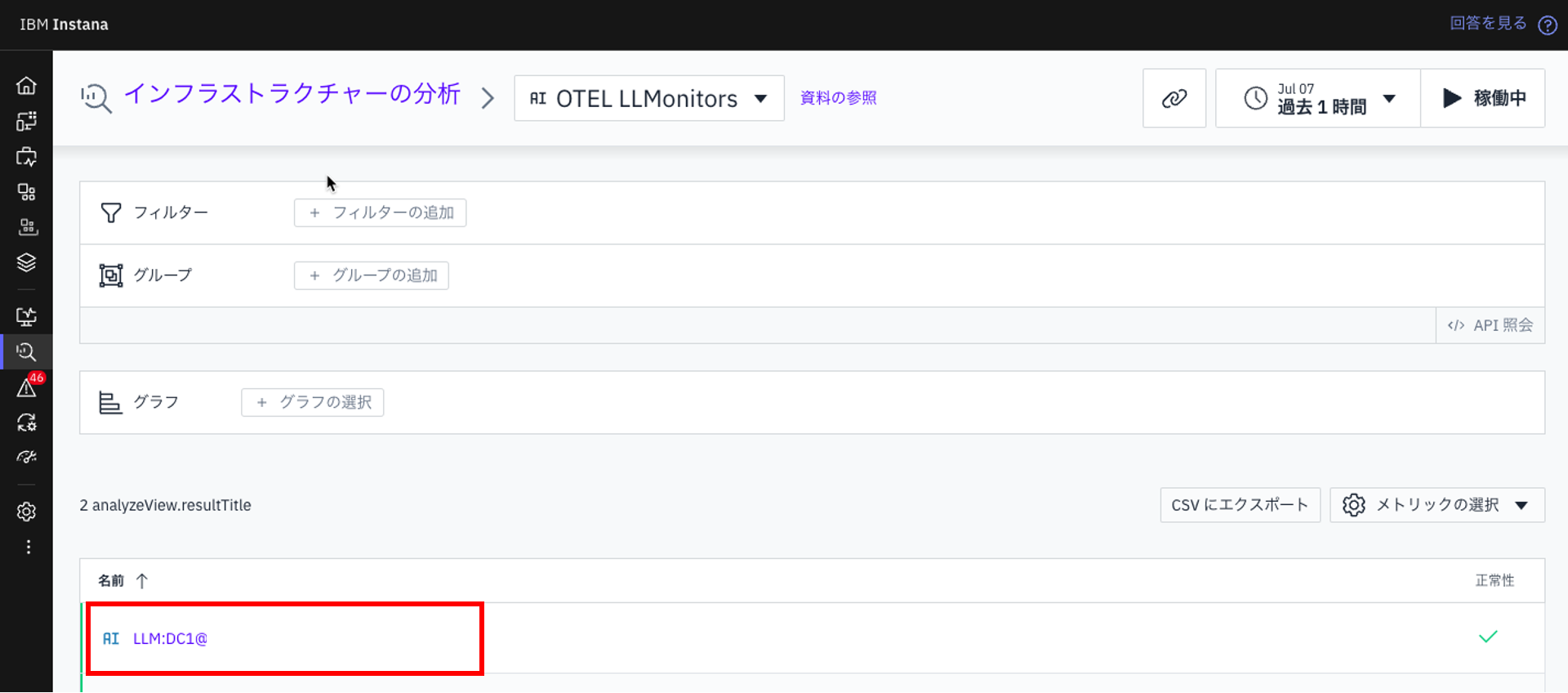
エンティティタイプのリストから「OTEL LLMonitor」を選択します。
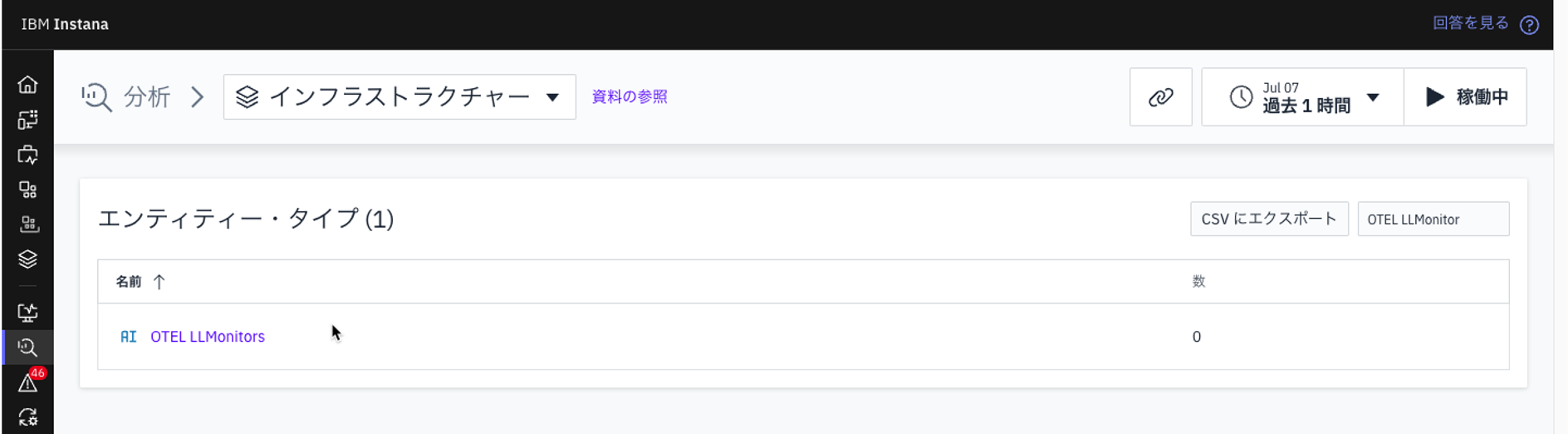
-
「OTEL LLMonitor」エンティティタイプのインスタンスをクリックして、関連するダッシュボードを開きます。
-
このダッシュボードでは、以下のような重要なメトリクスを確認できます:
- 合計トークン数
- 合計コスト
- 合計要求数
- 平均応答時間
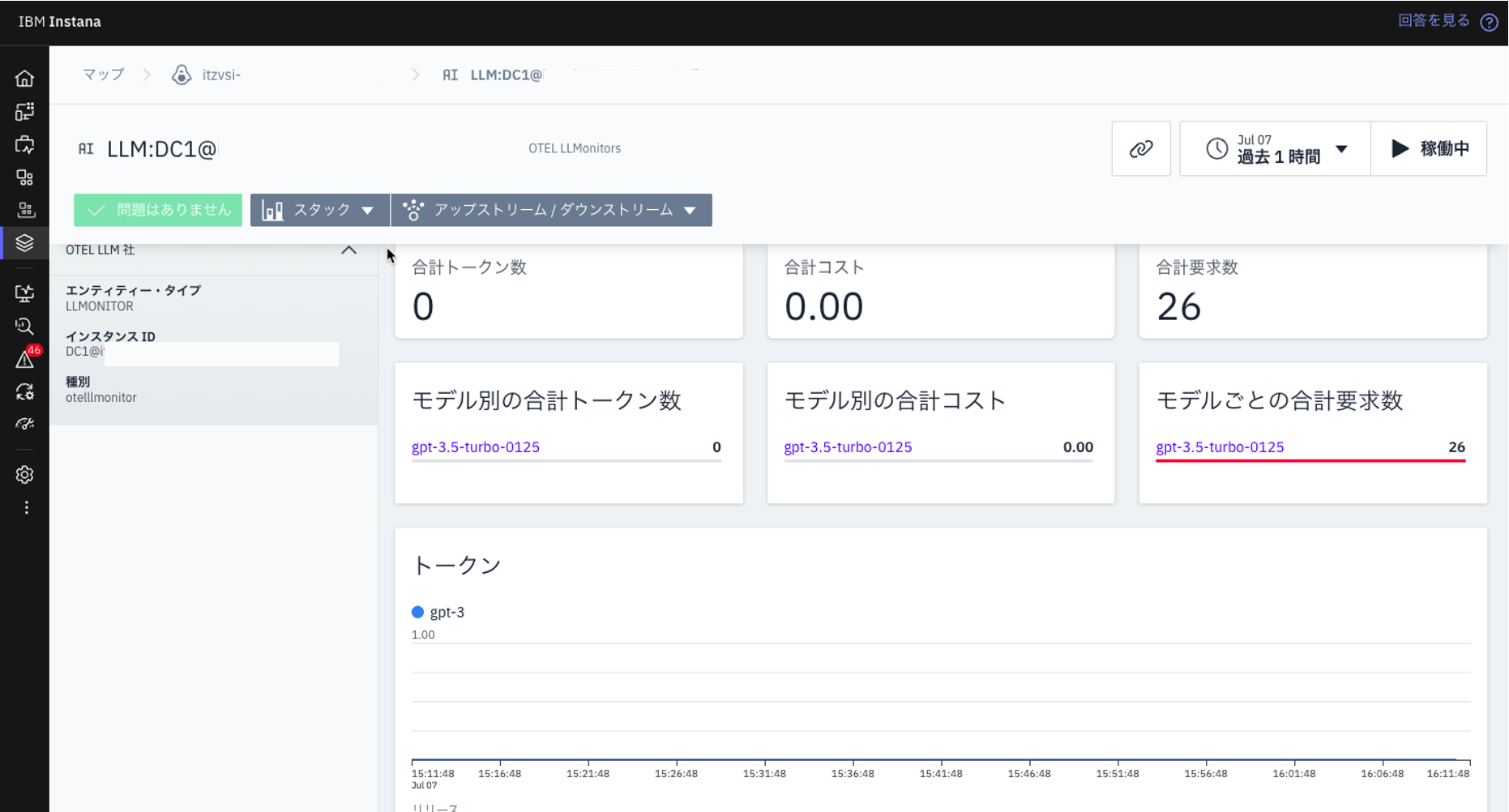
これらのメトリクスを分析することで、LLMアプリケーションのパフォーマンス、コスト効率、利用状況などを詳細に把握することができます。
まとめ
この記事では、Instana LLM モニタリングのセットアップ手順と実践的な使用例を紹介しました。OpenTelemetry Data Collectorのインストール、アプリケーションの計装、環境変数の設定など、具体的な手順を解説しました。
Instana LLM モニタリングを導入することで、LLMアプリケーションの動作を詳細に可視化し、パフォーマンスの最適化、コスト管理、異常検知などを効果的に行うことができます。特に、分散トレーシング機能を活用することで、アプリケーションの動作をより深く理解し、問題の迅速な特定と解決が可能になります。
次回の記事では、今回導入したモニタリング環境を使用して、より高度な分析技術や実際のトラブルシューティング事例について詳しく解説する予定です。チャットボットアプリケーションのパフォーマンス最適化や問題解決の実践的なアプローチを紹介しますので、お楽しみに。