はじめに
テキストが埋め込まれたPDFファイルは、Pythonプログラム(pdfminer3)によって、テキストを抽出すると共に、その文字の座標位置を抽出することが出来ます。
その情報を使えば、座標位置から、エクセルに変換することが出来るのではないかと思い、PDFをエクセルに変換するプログラムを作成しました。
これによって、注文書や見積書など、文字情報が埋め込まれたPDFファイルをエクセル化でき、業務の効率がアップするのではないかと思います。
今回は、備忘録も兼ねて掲載します。
作成環境
Visual Studio Code
Python3.8.8
各種インストールライブラリー
pdfminer3
pandas
OpenPyXL
サンプルPDF:
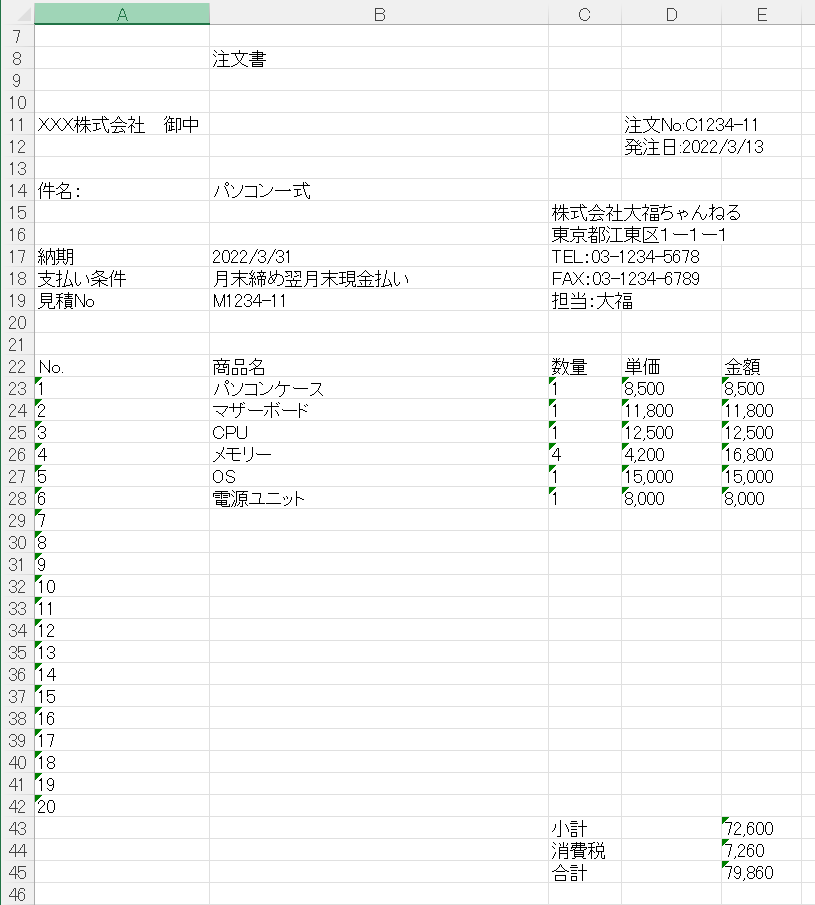
プログラム実行で用いたPDFファイルは、以下のような注文書のPDFファイルです。
このファイルにはテキスト情報が埋め込まれたPDFファイルで、元々、エクセルで作成し、PDFに変換したものです。
今回は、このPDFファイルをエクセルに変換し、表の部分をエクセルに抽出したいと思います。
YouTubeでの解説:
プログラムの詳細はYoutubeでも解説していますので、ぜひ、ご覧ください。
サンプル1:pdfminer3でpdfからテキストを抽出する。
YouTube動画のSTEP1で使っているプログラムソースです。
from pdfminer3.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer3.converter import PDFPageAggregator
from pdfminer3.pdfpage import PDFPage
from pdfminer3.layout import LAParams, LTTextContainer
resourceManager = PDFResourceManager()
device = PDFPageAggregator(resourceManager, laparams=LAParams())
pdf_file_name = './sample.pdf'
with open(pdf_file_name, 'rb') as fp:
interpreter = PDFPageInterpreter(resourceManager, device)
for page in PDFPage.get_pages(fp):
interpreter.process_page(page)
layout = device.get_result()
for lt in layout:
# LTTextContainerの場合だけ標準出力
if isinstance(lt, LTTextContainer):
print(lt.get_text())
device.close()
実行結果:サンプル1の実行結果です。
テキストの抽出は出来ていますが、文字がひと塊になっており、扱いにくい形式です。
注文書
XXX株式会社 御中
件名: パソコン一式
2022/3/31
納期
支払い条件 月末締め翌月末現金払い
見積No
M1234-11
注文No:C1234-11
発注日:2022/3/13
株式会社大福ちゃんねる
東京都江東区1ー1ー1
TEL:03-1234-5678
FAX:03-1234-6789
担当:大福
No.
商品名
数量
単価
金額
パソコンケース
マザーボード
CPU
メモリー
OS
電源ユニット
1
1
1
4
1
1
8,500
11,800
12,500
4,200
15,000
8,000
8,500
11,800
12,500
16,800
15,000
8,000
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
小計
消費税
合計
72,600
7,260
79,860
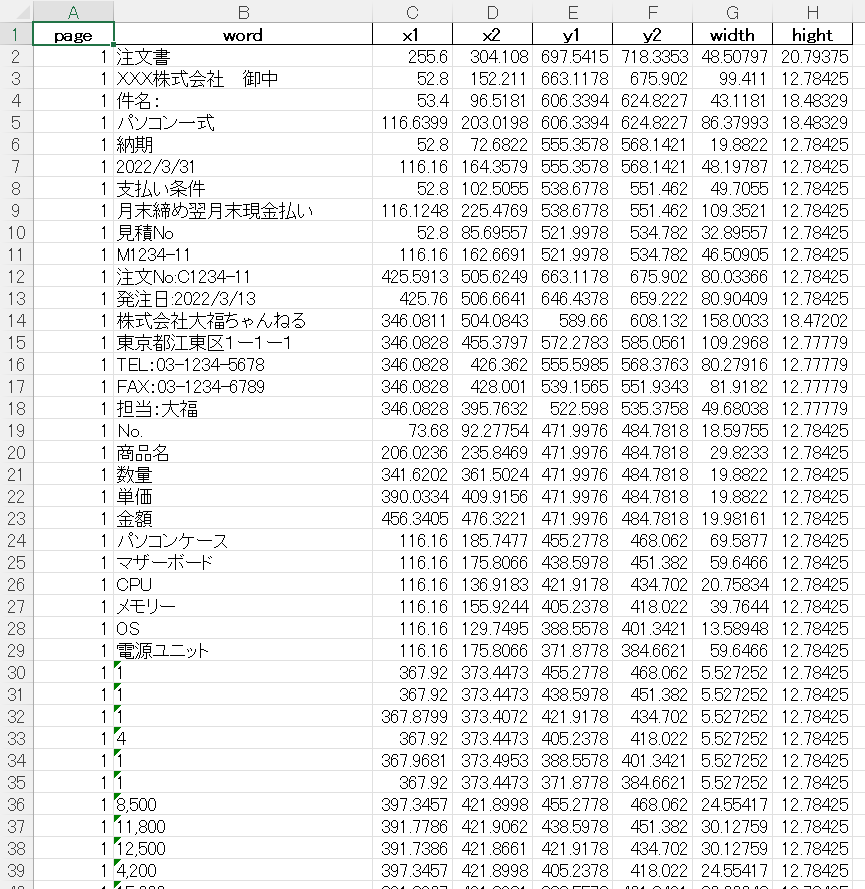
サンプル2:pdfminer3でpdfからテキストと座標位置を抽出しエクセル書き出し。
YouTubeのSTEP4で作成したプログラムです。
テキストは出来る限り分割させたい為、各種marginを設定しています。
from pdfminer3.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer3.converter import PDFPageAggregator
from pdfminer3.pdfpage import PDFPage
from pdfminer3.layout import LAParams, LTTextContainer
import pandas as pd
def pdfminer_config(line_overlap, word_margin, char_margin,line_margin, detect_vertical):
laparams = LAParams(line_overlap=line_overlap,
word_margin=word_margin,
char_margin=char_margin,
line_margin=line_margin,
detect_vertical=detect_vertical)
resource_manager = PDFResourceManager()
device = PDFPageAggregator(resource_manager, laparams=laparams)
interpreter = PDFPageInterpreter(resource_manager, device)
return (interpreter, device)
#resourceManager = PDFResourceManager()
#device = PDFPageAggregator(resourceManager, laparams=LAParams())
pdf_file_name = './sample.pdf'
work_file = './work_file.xlsx'
list1 = ['','','','','','','','']
df_x = pd.DataFrame([list1])
df_x.columns = ['page', 'word', 'x1','x2','y1','y2','width','hight']
int_page = 0
ii_index = 0
with open(pdf_file_name, 'rb') as fp:
#interpreter = PDFPageInterpreter(resourceManager, device)
interpreter, device = pdfminer_config(line_overlap=0.1, word_margin=0.1, char_margin=0.1, line_margin=0.1, detect_vertical=False)
for page in PDFPage.get_pages(fp):
int_page = int_page + 1
interpreter.process_page(page)
layout = device.get_result()
for lt in layout:
# LTTextContainerの場合だけ標準出力
if isinstance(lt, LTTextContainer):
df_x.loc[ii_index] = [int_page,lt.get_text().strip(), lt.x0 , lt.x1 ,\
lt.y0 ,lt.y1 ,lt.width ,lt.height ]
ii_index = ii_index + 1
device.close()
with pd.ExcelWriter(work_file) as writer:
df_x.to_excel(writer, sheet_name='sheet1', index=False)
実行結果:サンプル2の処理結果です。
文字がきれいに分割され、座標位置も取得できています。
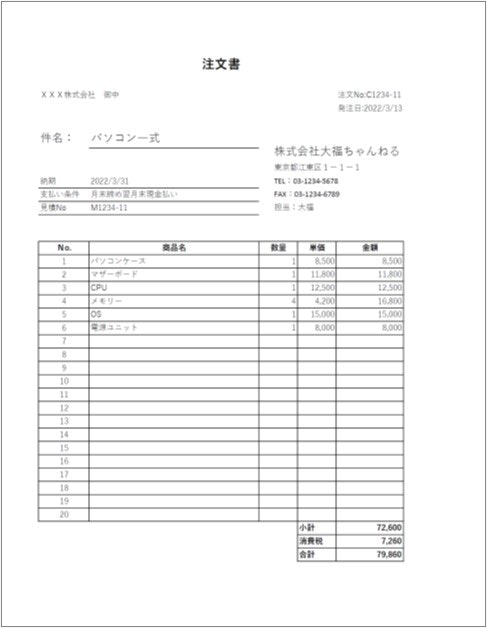
完成版:pdfminer3でpdfからテキストと座標位置を抽出しエクセルで元の表を再現
元のPDFファイルのレイアウトをエクセルに出力すると共に、PDFファイルをポップアップで選択できるようにしています。
また、ある程度の形式のPDFに対応できるように、縦のピッチを自動で計算しています。
ただし、万能では無いと思いますので、すべてのPDFファイルに対応できるわけではありません。
その場合、marginや縦のピッチのパラメータを変更してご利用ください。
from pdfminer3.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer3.converter import PDFPageAggregator
from pdfminer3.pdfpage import PDFPage
from pdfminer3.layout import LAParams, LTTextContainer
import pandas as pd
import openpyxl
import math
from tkinter import filedialog
import os
def pdfminer_config(line_overlap, word_margin, char_margin,line_margin, detect_vertical):
laparams = LAParams(line_overlap=line_overlap,
word_margin=word_margin,
char_margin=char_margin,
line_margin=line_margin,
detect_vertical=detect_vertical)
resource_manager = PDFResourceManager()
device = PDFPageAggregator(resource_manager, laparams=laparams)
interpreter = PDFPageInterpreter(resource_manager, device)
return (interpreter, device)
typ = [('pdfファイル','*.pdf')]
dir = './'
pdf_file_name = filedialog.askopenfilename(filetypes = typ, initialdir = dir)
work_file = os.path.splitext(pdf_file_name)[0] + '_work.xlsx'
excel_file_name = os.path.splitext(pdf_file_name)[0] + '.xlsx'
list1 = ['','','','','','','','']
df_x = pd.DataFrame([list1])
df_x.columns = ['page', 'word', 'x1','x2','y1','y2','width','hight']
int_page = 0
ii_index = 0
with open(pdf_file_name, 'rb') as fp:
interpreter, device = pdfminer_config(line_overlap=0.1, word_margin=0.1,
char_margin=0.1, line_margin=0.1, detect_vertical=False)
for page in PDFPage.get_pages(fp):
int_page = int_page + 1
interpreter.process_page(page)
layout = device.get_result()
for lt in layout:
# LTTextContainerの場合だけ標準出力
if isinstance(lt, LTTextContainer):
df_x.loc[ii_index] = [int_page,'{}'.format(lt.get_text().strip()), lt.x0 , lt.x1 ,\
841 - lt.y0 + (int_page - 1) * 841,841 - lt.y1 + (int_page - 1) * 841,lt.width ,lt.height ]
ii_index = ii_index + 1
device.close()
# x1でソート
df_s_x = df_x.sort_values(['x1','y2'], ascending=[True,True])
# 縦のピッチを計算
h_min = 100
for i in range(len(df_s_x)):
if i > 0:
if df_s_x.iloc[i-1,2] == df_s_x.iloc[i,2]:
h_sa = df_s_x.iloc[i,5] - df_s_x.iloc[i-1,5]
if h_sa > 1.0 and h_min > h_sa:
h_min = h_sa
# workファイルを書き出し
with pd.ExcelWriter(work_file) as writer:
df_s_x.to_excel(writer, sheet_name='sheet1', index=False)
wb = openpyxl.Workbook()
ws = wb.worksheets[0]
j = 1
width_x = 0
for i in range(len(df_s_x)):
y = df_s_x.iloc[i,5] // (math.ceil(h_min*10)/10) + 1
c1 = ws.cell(row=int(y), column=j)
if c1.value == None:
c1.value = df_s_x.iloc[i,1]
else:
#列幅調整
ws.column_dimensions[ws.cell(row=1, column=j).column_letter].width = (df_s_x.iloc[i,2]/5.98- width_x )
width_x = df_s_x.iloc[i,2]/5.98
j = j + 1
c1 = ws.cell(row=int(y), column=j)
c1.value = df_s_x.iloc[i,1]
wb.save(excel_file_name)
処理結果:完成版の処理結果
元のPDFファイルの表形式がうまく再現できています。