はじめに
OpanAI社の音声文字認識エンジンのWhisperを使って、音声文字起こしするプログラムを作成しました。
プログラムはPythonからAPIでWhisperを使って、音声文字認識する形式です。
約2分の音声を試したところは、Whisperの音声文字認識の精度は99%とAmiVoiceCloudPlatform(96%)以上の精度でした。
2分の動画を約9秒で変換できるなど、非常に使い勝手の良いAPIです。
価格は1分あたり0.9円(0.006ドル)です。
ただし、Whisperのインプットの音声ファイルの容量は25Mバイトですので、それ以上のファイルは分割する必要があります。
環境
Windows10
Python3.8.8
VSCode
使用ライブラリー
openai
pydub
tkinter
openpyxl
pandas
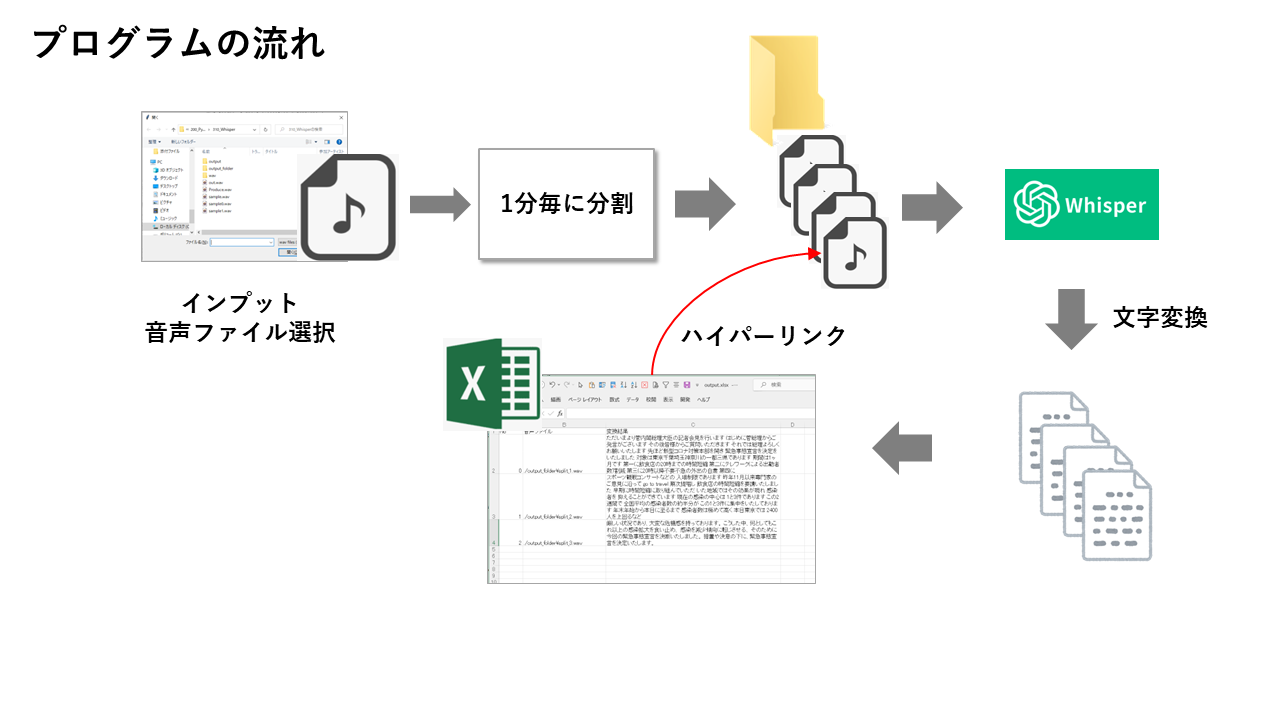
処理の流れ:
今回作成した処理は、音声ファイルをインプットに、1分単位に音声を分割し、その音声をOpenAIのWhisperという音声文字認識エンジンをAPIで接続し、文字認識した文字をエクセルにセットするプログラムです。
また、1分単位に分割したファイルへのハイパーリンクを設定することで、変換後の文字を見ながら、音声ファイルをすぐに開ける構成にしています。
YouTubeでの解説:
上記の作業の流れをYoutubeで詳しく解説していますので、ぜひ、ご覧ください。
サンプルソース
YouTubeで紹介している1つ目の処理のプログラムソースです。
import openai
import os
openai.api_key = os.getenv("OPENAI_API_KEY")
audio_file= open("./sample1.wav", "rb")
transcript = openai.Audio.transcribe("whisper-1", audio_file)
print(str(transcript["text"]))
完成版プログラム
完成プログラムは、以下のYoutubeの概要欄に限定公開したQiitaのURLを公開していますので、そちら経由でご覧ください。
https://youtu.be/RikW7r1zIy8
最後に:
今回は、音声ファイルをインプットに音声を文字変換するプログラムをご紹介しました。
今後も、役立ちそうなプログラムをご紹介していきたいと思います。