背景
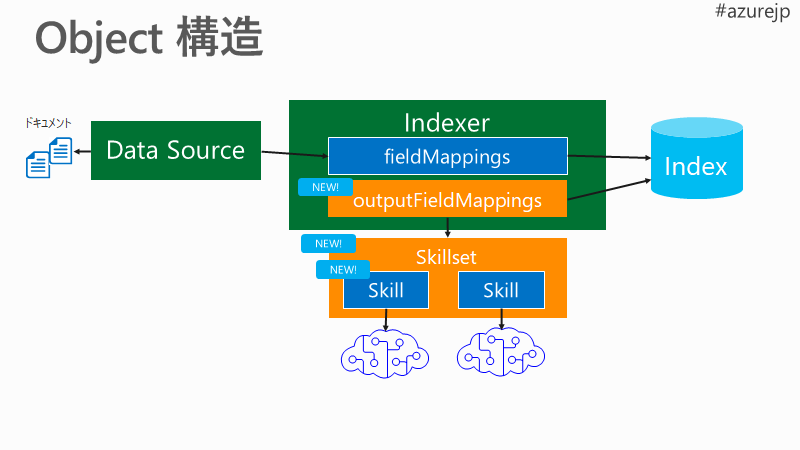
Azure Cognitive Search には、Azure Cognitive Services や REST call 出来る任意の API経由でドキュメント解析処理を追加できます。AI エンリッチメント と呼ばれています。
Blob Storage などの元のデータソースを、Indexer がクローリングして、転置インデックス と Knowledge Store に格納します。そのクローリングの際ににSkillsetとして、幾つかの処理を Skill として呼び出すことが出来ます。
-
この図では、Index で「転置インデックス」のみ表現しています😅
-
良い点😍
- 対象ドキュメントの定期的なクローリング
- ドキュメントのパーサー : 意味をもった文章として処理ができる
- 高い生産性
- Cognitive Services 利用 - Computer Vision も NLP も
- REST Call での任意のサービスの組み込み
-
今後の改善点😭
- 開発ツールが揃っていない
- 独自の開発スタイルなので、学んだスキルが全て他のPlatformで活かせるわけではない。ただ、応用は効く
Microsoft.Skills.Text.CustomEntityLookupSkill
執筆時点 Preview です。公式アナウンスもありません😅
実装が簡単な上に、効果も大変高いので、早期に取り扱ってみます。
カスタム エンティティの参照認知スキル (プレビュー):
https://docs.microsoft.com/ja-jp/azure/search/cognitive-search-skill-custom-entity-lookup
前準備
まずは、Azure Cognitive Service の AIエンリッチメント 機能を実装します。
以下、ご参考までに。
Azure Search の Cognitive Search 機能を使って、ドキュメントの言語解析のプロトタイプ作成:
https://qiita.com/dahatake/items/2dc3f279340280d2b0cb
Blob に置くファイル数は、1-2個くらいにしましょう。うまく動く前に、多くのデータを入れると、処理時間がかかるだけでなく、デバッグも対象範囲が増えるので、大変になります。1つが個人的にはおススメ。動いたら増やしましょう😎
手順
ざっくり以下の通り。
- 言語処理パイプライン処理に入出力をする
Skillを定義し、 -
Indexに出力を受け付ける器を定義し、 - それらのマッピングを行う
Indexerを定義します。 - ここまで出来れば、クローリングのジョブとして、
Indexerを実行します。
1. Entity ファイルの準備
CustomEntityLookup で Entity データを参照するには、以下の2つの方式があります。いずれかを、スキル設定時のパラメーターとして指定をします。
- スキル設定の内部:
inlineEntitiesDefinition - ファイル参照:
entitiesDefinitionUri
ここでは、メンテナンスのしやすさを考慮して、ファイル参照を選択します。
ファイルは CSV もしくは JSON のファイル形式で用意します。ファイルの文字コードはUTF-8 で作成してください。
JSON ファイル例:
[
{"name":"機械学習"},
{"name":"Azure Machine Learning"},
{"name":"Deep Learning"},
{"name":"Tensorflow"},
{"name":"Hackfest"}
]
これを、Blob Storage に置きます。
-
Azure Storage Explorerを使うのが便利ですね。
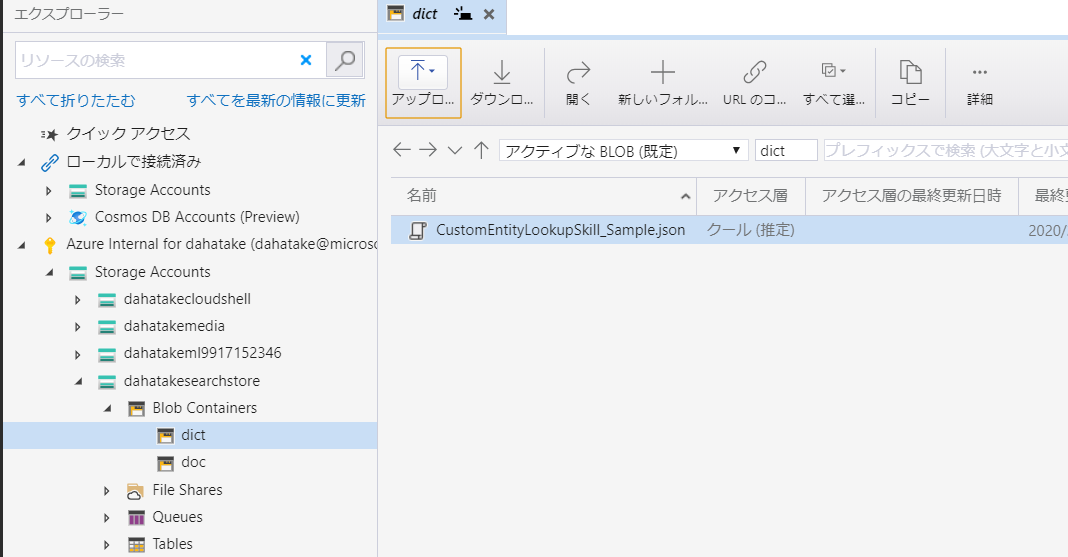
ファイルの SAS URL を取得します。
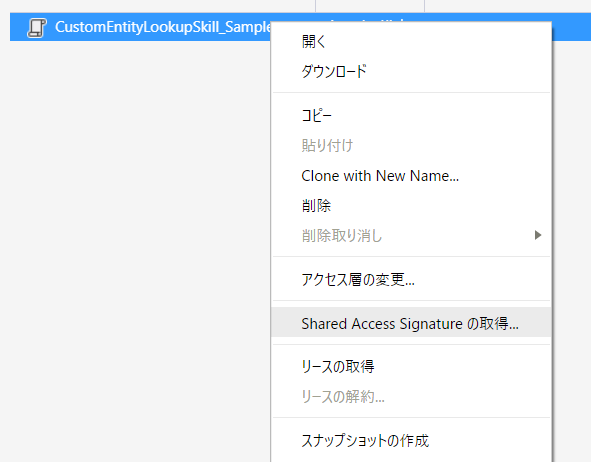
SAS URL例:
https://dahatakesearchstore.blob.core.windows.net/dict/CustomEntityLookupSkill_Sample.json?st=2020-02-10T16%3A47%3A53Z&se=2020-02-17T10%3A47%3A00Z&sp=rl&sv=2018-03-28&sr=b&sig=w6FQkA1B6vjoJxsAstbETD99D0ydXfGbHW7evDMMuGA%3D
- 注意: 単なるサンプルなので、この文字列は動きません!!!
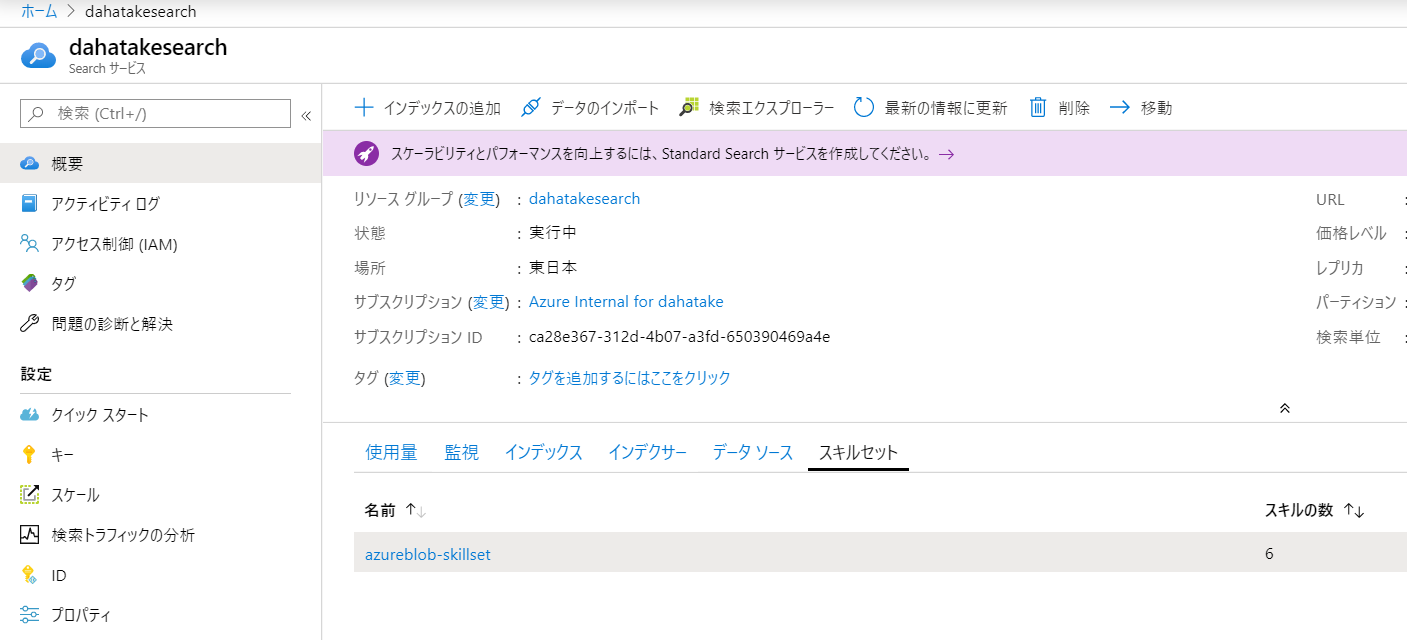
2. Skillset 変更
Azure の Portal 上で、作業をしていきます。
-
[Search サービス] - [スキルセット] から
-
[スキルセットの定義 (JSON)] へ
-
[スキル定義テンプレート] の Text 中に [カスタム エンティティの参照スキル] があります。
以下の様なテンプレート文字列が容易されています。
{
"@odata.type": "#Microsoft.Skills.Text.CustomEntityLookupSkill",
"defaultLanguageCode": "",
"entitiesDefinitionUri": "",
"inlineEntitiesDefinition": [
{
"name": "",
"description": "",
"type": "",
"subtype": "",
"id": "",
"caseSensitive": true,
"accentSensitive": true,
"fuzzyEditDistance": 0,
"defaultCaseSensitive": true,
"defaultAccentSensitive": true,
"defaultFuzzyEditDistance": 0,
"aliases": ""
}
],
"name": "",
"description": "",
"context": "",
"inputs": [
{
"name": "text",
"source": ""
}
],
"outputs": [
{
"name": "entities",
"targetName": "entities"
}
]
}
以下のように置き換えます。
{
"@odata.type": "#Microsoft.Skills.Text.CustomEntityLookupSkill",
"name": "customEntityLookup",
"description": "",
"context": "/document/content/sentences/*",
"defaultLanguageCode": "en",
"entitiesDefinitionUri": "<<Blob SAS URL>>",
"inputs": [
{
"name": "text",
"source": "/document/content/sentences/*"
}
],
"outputs": [
{
"name": "entities",
"targetName": "mlentities"
}
]
}
大事なところだけ。
| 項目 | 内容 | 説明 |
|---|---|---|
| name | 何でもいいです | skillset の中で一意になるようにしてください |
| context | /document/content/sentences/* |
最後のsentences は、エンリッチメントの追加画面で、選択した 粒度レベル で変わります。文章を選択しましたので、sentences になっています。 |
| defaultLanguageCode | en | 残念ながら、日本語対応はしていない...ただ、動くは動く |
| input - source | /document/content/sentences/* |
同上 |
| outputs - name | entities | 固定です。出力名は事前定義済み |
| outputs - targetName | 任意 | その後のエンリッチ処理で参照される名称 |
-
[データのインポートウィザード] の [エンリッチメントの追加画面]
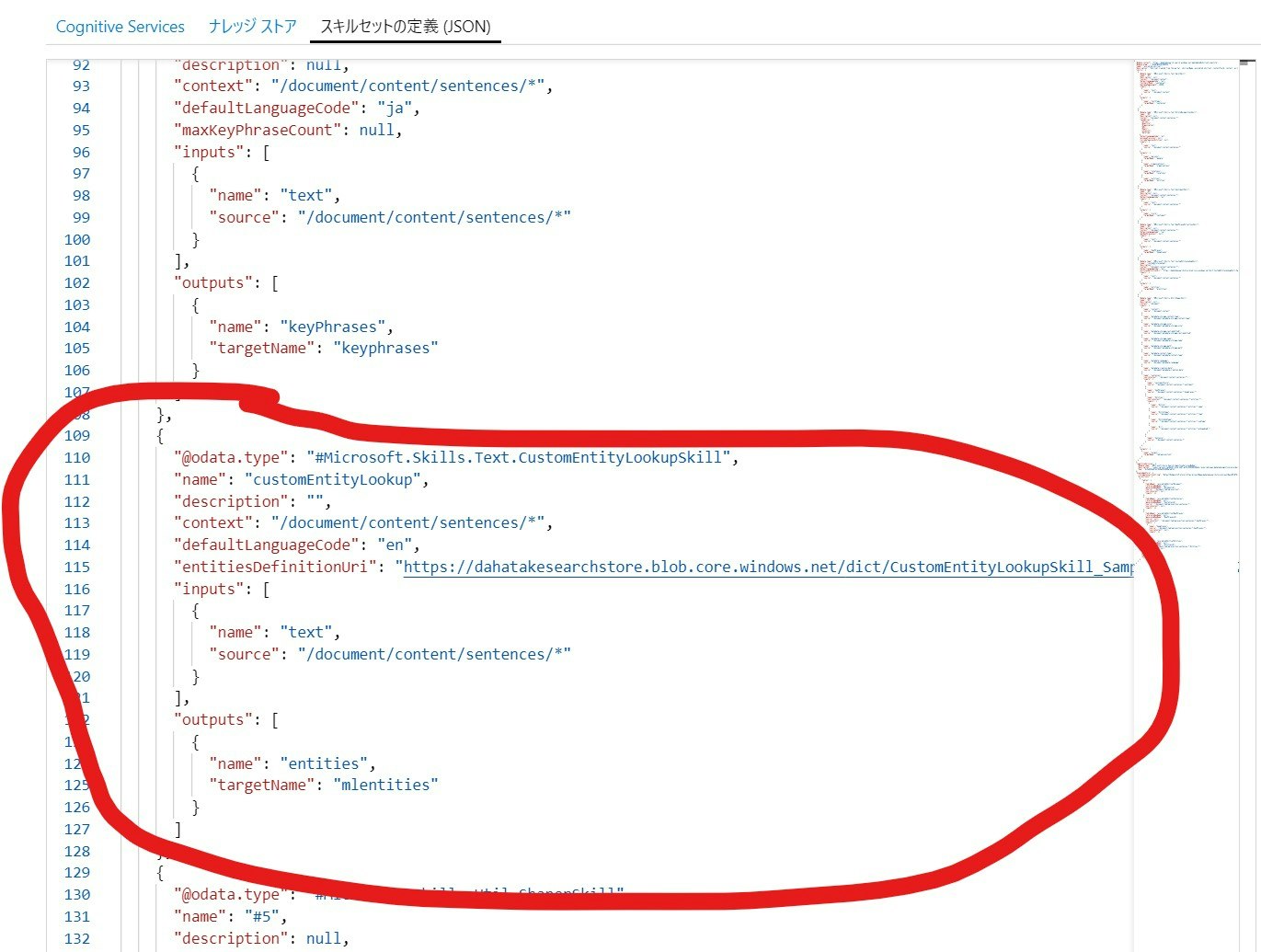
そして、[スキルセットの定義(JSON)] の中に入れます。
ウィザードで作成したものですと、#Microsoft.Skills.Util.ShaperSkillの前 に入れるのが良いかと思います。
3. Index 変更
同じく Azure Portal から行います。
-
[Search サービス] - [インデックス]
-
[インデックス定義 (JSON)]
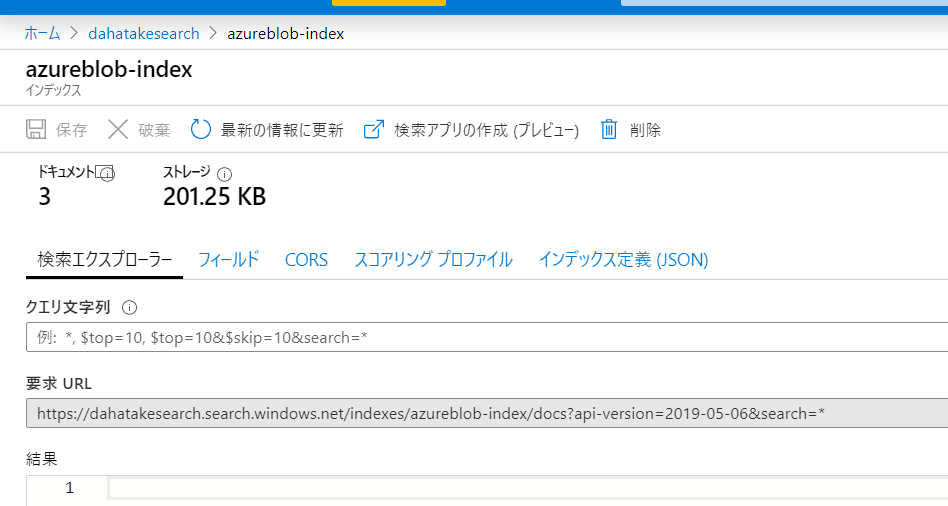
-
以下の文字列を適時変更して追加します。
{
"name": "mlentities",
"type": "Collection(Edm.String)",
"facetable": true,
"filterable": true,
"retrievable": true,
"searchable": true,
"analyzer": "ja.lucene",
"indexAnalyzer": null,
"searchAnalyzer": null,
"synonymMaps": [],
"fields": []
}
| 項目 | 値 | 説明 |
|---|---|---|
| name | Indexの中で一意にしてください | Skill の Output と同じにするのがおススメです。一貫性という観点だけですが |
| analyzer | ja.lucene | 言語にあった Analyzer を指定ください |
- Azure Cognitive Search インデックスの文字列フィールドに言語アナライザーを追加する
https://docs.microsoft.com/ja-jp/azure/search/index-add-language-analyzer
そして、[インデックス定義(JSON)]の中に入れます。
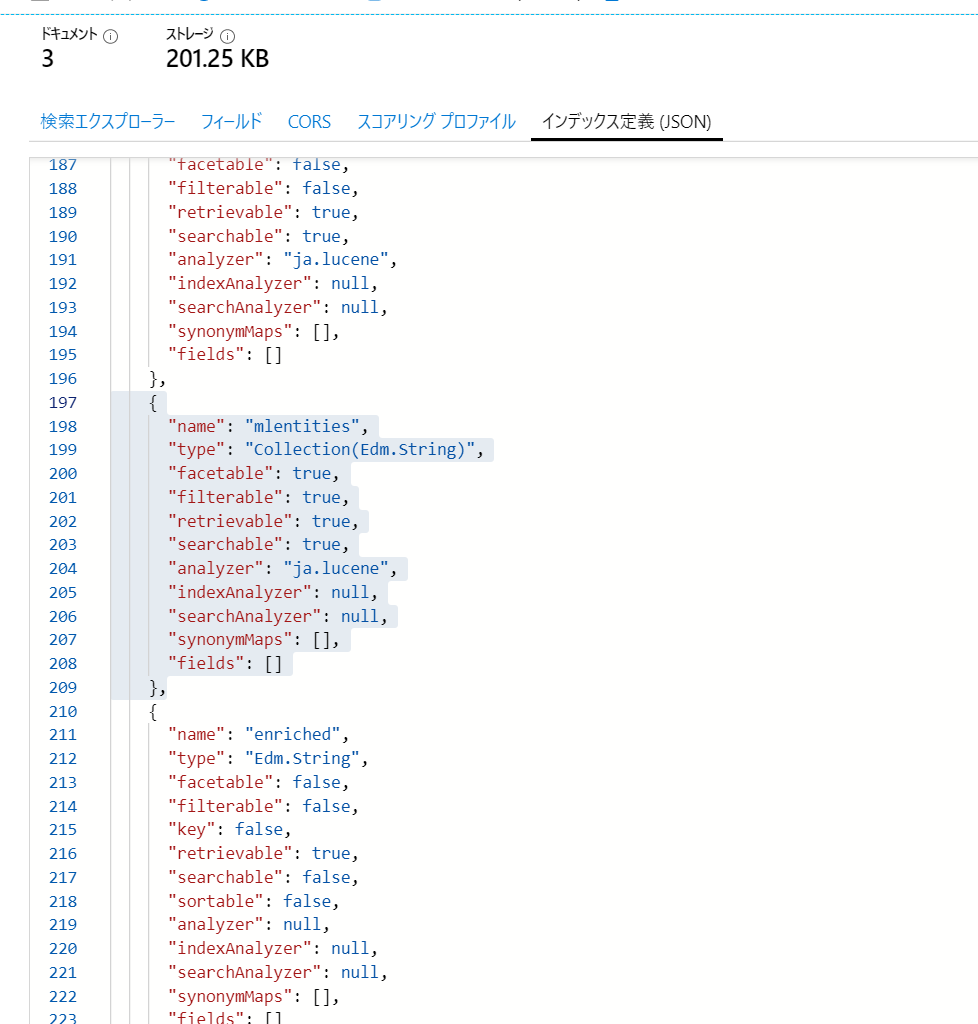
4. Indexer の変更
ここも同じく Azure Portal からです。
-
[Search サービス] - [インデクサー]
-
[インデクサー定義 (JSON)]
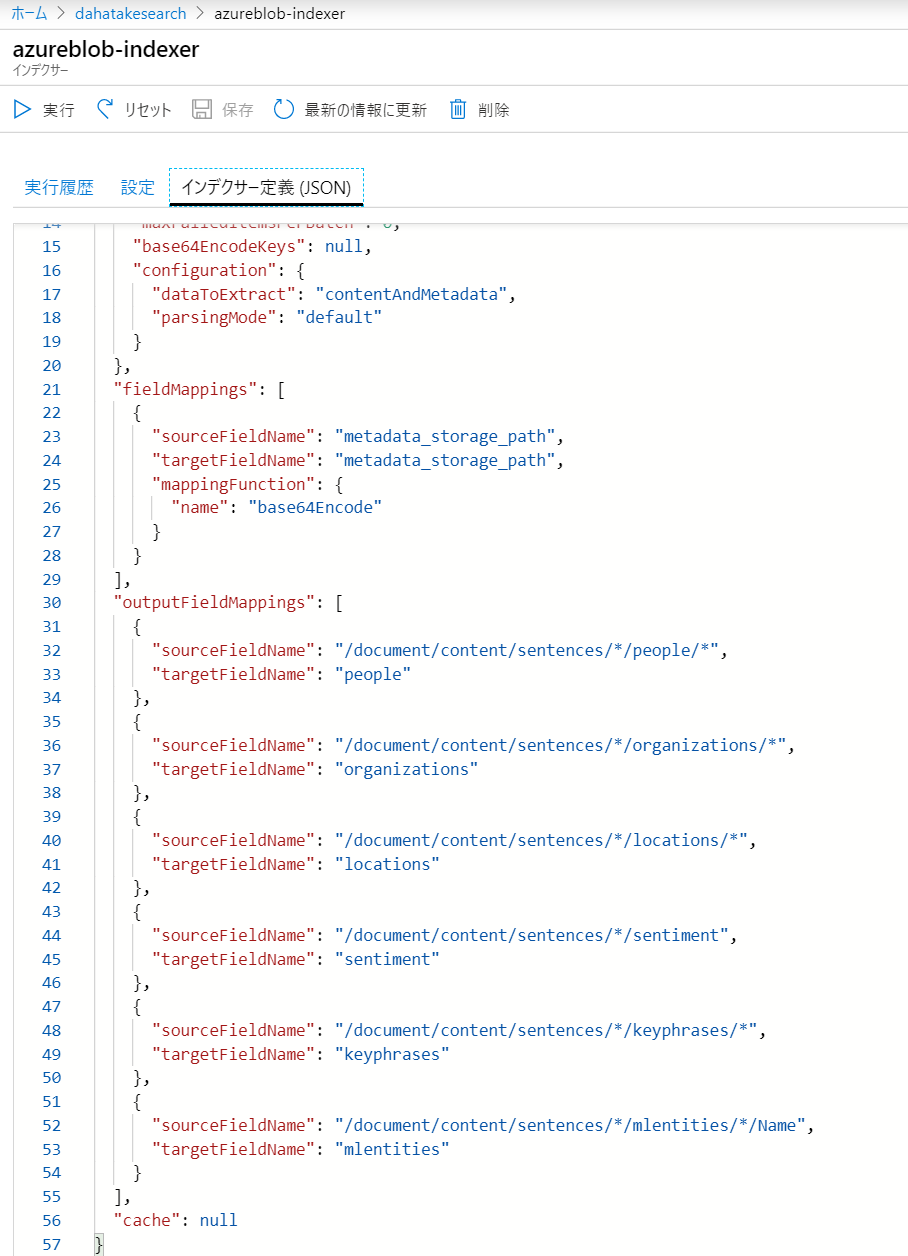
-
以下の文字列を追加します。
{
"sourceFieldName": "/document/content/sentences/*/mlentities/*/name",
"targetFieldName": "mlentities"
}
| 項目 | 値 | 説明 |
|---|---|---|
| sourceFieldName | /document/content/sentences/*/mlentities/*/name |
* が複数アイテムを示しています。name は、出力項目に定義されています。 |
| targetFieldName | mlentities | 出力としてのIndex のフィールド名です |
そして、[インデクサー定義(JSON)]の中に入れます。
4. Indexer 実行
新規にIndexにフィールドも加えましたので、既存のデータを全てクリアして、再度クローリングします。
- 一度リセット をしてから、実行 をします。
5. 結果の確認
Azure Portal に組み込まれている [検索エクスプローラー] で見ていきましょう。
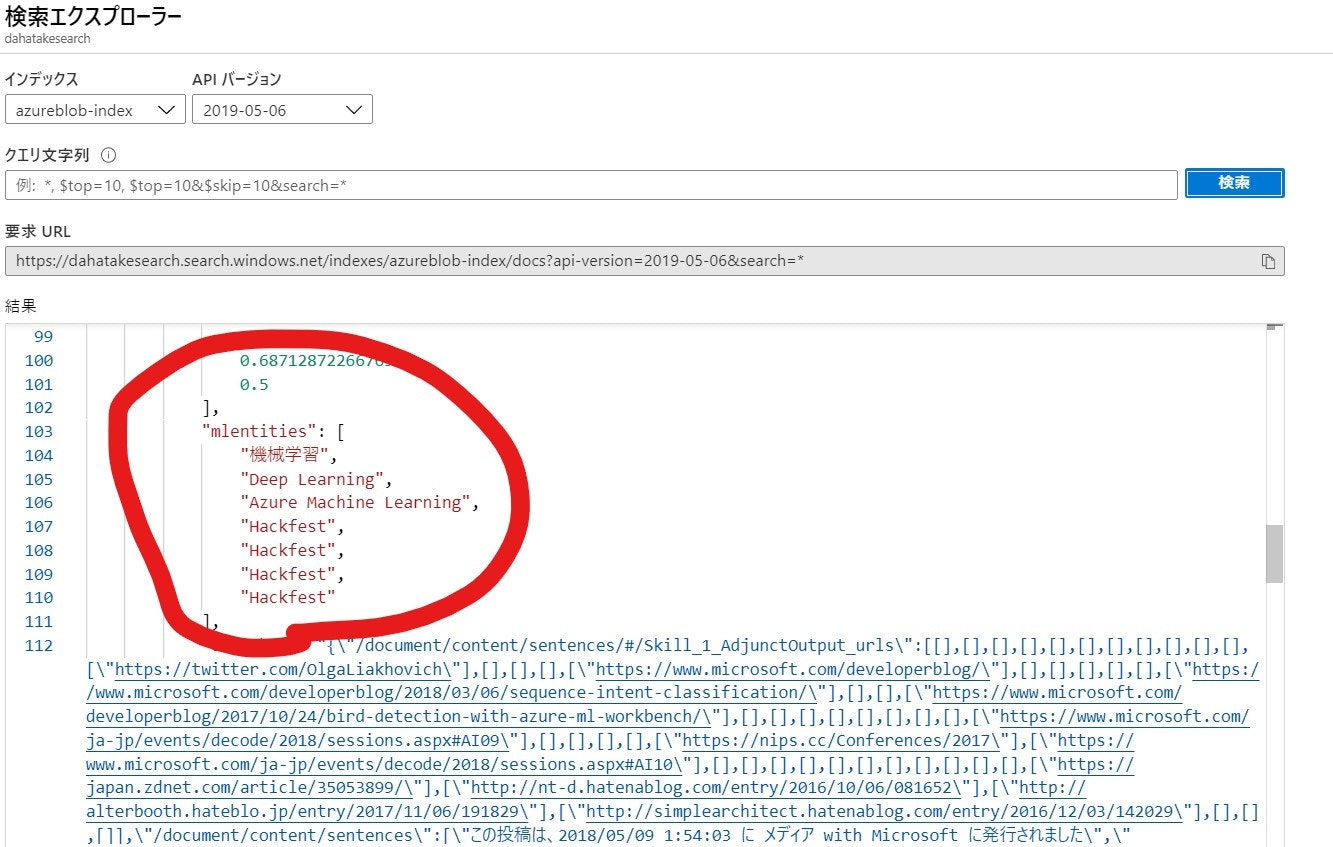
mlentities に結果が抽出できているのが分かります!
これで、検索時に使えますね!
カスタマイズの検討事項
Azure Cognitive Services の Skillset の開発は、以下の順序で行うのがおススメです。いずれも Azure Functions に載せるのをおススメします。課金、開発生産性 (デバッグも出来る!)、各種ログ出力など何せ便利です。
モデルの開発だけでなく、モデルは運用に載せるための、画面・自動化などの方がずっと大事ですので。既存のあるものは使い倒しましょう!
- 標準の組み込み Skillset 群
- Vision, NLP, 翻訳, PII検出 などコア機能がある程度揃っている。文書をスキャンして、画像ファイルで管理しているケースも十二分にあり得る
- Utility としてのテキスト処理群もある
- Cognitive Services には、帳票しそうな
Form RecognizerやLUISなど、組み込みやすいサービスもある - Container 化させ、独自の Azure Functions上で動作も選択肢
- CustomEntityLookup
- まずは、単語ベース
- かなりのシナリオをカバーできる
- JSON であれば、Type / SubTypeなどメタデータの設定も可能
- Cognitive Services の各種カスタマイズ関連
- LUIS | Custom Vision Services | Speech Service
- Classification | Entity Extraction | 諸々
- 何せ管理ポータルあり
- それらでも不足していたら、BERT など Deep Learning
- NLP on Azure Best Practice
- BERT on Azure Machine Learning
- Computer Vision on Azure Best Practice
- https://github.com/microsoft/computervision-recipes
それら全てが カスタムスキル という扱いです。
こちらのドキュメントが参考になるでしょう。
Azure コグニティブ検索エンリッチメント パイプラインにカスタム スキルを追加する方法:
https://docs.microsoft.com/ja-jp/azure/search/cognitive-search-custom-skill-interface
開発中の Tips
これは、ほぼ必須といっていいです😅
Skillsetの処理途中のデータを見る手段が殆どありません。Indexに enriched という名前のフィールドを追加してください。これによって、データの確認ができます。
{
"name": "enriched",
"type": "Edm.String",
"facetable": false,
"filterable": false,
"key": false,
"retrievable": true,
"searchable": false,
"sortable": false,
"analyzer": null,
"indexAnalyzer": null,
"searchAnalyzer": null,
"synonymMaps": [],
"fields": []
}