Data Science VM (Ubuntu) on Azure の学習のためのディスク構成
背景
Deep Learning の学習用に Data Science VM (Ubuntu) が良く使われています。Azure の仮想マシンを使う際には、ディスクに特徴がある点を抑えてあることを意識して、ファイルの置き場所を検討します。
- 永続化 :
/にマウント。 - 非永続化 :
/mntにマウント。要は再起動したら、ファイルが失われる 可能性がある!「一時ストレージ」
Azureのストレージについて:
https://docs.microsoft.com/ja-jp/azure/virtual-machines/linux/about-disks-and-vhds
Deep Learning の学習用のファイル(データセット)は、100GBを超えるものも多くあります。空き容量などのディスク構成を都度調べるのは多少でも費用と時間はかかりますので、ダンプしたものを記します。
前提
- Standard HDD (SSDも同じです)
- Managed Disk
- NC6
注意点
Azure の仮想マシンイメージは、何の予告なく変更される可能性がありますので、最新の状態を正としてください。
Data Science VM (Ubuntu)
dahatake@dahatakedsvm:~$ df -h
Filesystem Size Used Avail Use% Mounted on
udev 28G 0 28G 0% /dev
tmpfs 5.6G 9.1M 5.5G 1% /run
/dev/sda1 49G 44G 4.6G 91% /
tmpfs 28G 108K 28G 1% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
tmpfs 28G 0 28G 0% /sys/fs/cgroup
/dev/sdc1 99G 17G 77G 18% /data
/dev/sdb1 335G 67M 318G 1% /mnt
tmpfs 5.6G 32K 5.6G 1% /run/user/120
tmpfs 5.6G 0 5.6G 0% /run/user/1003
dahatake@dahatakedsvm:~$ lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sdb 8:16 0 340G 0 disk
└─sdb1 8:17 0 340G 0 part /mnt
sr0 11:0 1 628K 0 rom
sdc 8:32 0 100G 0 disk
└─sdc1 8:33 0 100G 0 part /data
sda 8:0 0 50G 0 disk
└─sda1 8:1 0 50G 0 part /
dahatake@dahatakedsvm:~$
Ubuntu Server 18.04 LTS
dahatake@dahatakestd:~$ df -h
Filesystem Size Used Avail Use% Mounted on
udev 28G 0 28G 0% /dev
tmpfs 5.6G 696K 5.6G 1% /run
/dev/sda1 29G 1.3G 28G 5% /
tmpfs 28G 0 28G 0% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
tmpfs 28G 0 28G 0% /sys/fs/cgroup
/dev/sda15 105M 3.4M 102M 4% /boot/efi
/dev/sdb1 334G 69M 317G 1% /mnt
tmpfs 5.6G 0 5.6G 0% /run/user/1000
dahatake@dahatakestd:~$ lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 30G 0 disk
├─sda1 8:1 0 29.9G 0 part /
├─sda14 8:14 0 4M 0 part
└─sda15 8:15 0 106M 0 part /boot/efi
sdb 8:16 0 340G 0 disk
└─sdb1 8:17 0 340G 0 part /mnt
sr0 11:0 1 628K 0 rom
dahatake@dahatakestd:~$
Data Science VM は、通常のLinux 仮想マシンとは構成が異なることがわかりますね! /data が追加されています。
Azure Portal で 仮想マシンのディスクを確認すると、永続ディスクが追加されていることを確認できます。
- Data Science VM

- Linux 仮想マシン

Standard HDD と表記があります。これは更に高速化ができます。
Azureの Linux 仮想マシンのストレージの選択肢:
https://docs.microsoft.com/ja-jp/azure/virtual-machines/linux/disk-scalability-targets
Deep Learning 用のデータ置き場所候補
Azureの仮想マシンでは、永続ストレージは、ローカルキャッシュを使うものでも、ネットワーク越しに Azure Storage に書き込みます。
/data 以下 (Data Science VM のみ) のディスクサイズを増やす
data は、100GB あり、/home/user なども含まれています。ですが、100GB ですと不足することもありますので、1TBくらいまでサイズを増やしましょう!
Azure CLI より
これはドキュメントの通り。
Azure CLI を使用して Linux VM の仮想ハード ディスクを拡張する方法:
https://docs.microsoft.com/ja-jp/azure/virtual-machines/linux/expand-disks
Azure ポータルから
実は、Azureポータルからも簡単に出来ますので、その手順を。
- 仮想マシンの停止 (割り当て解除)
Azure ポータル 上から停止をします。
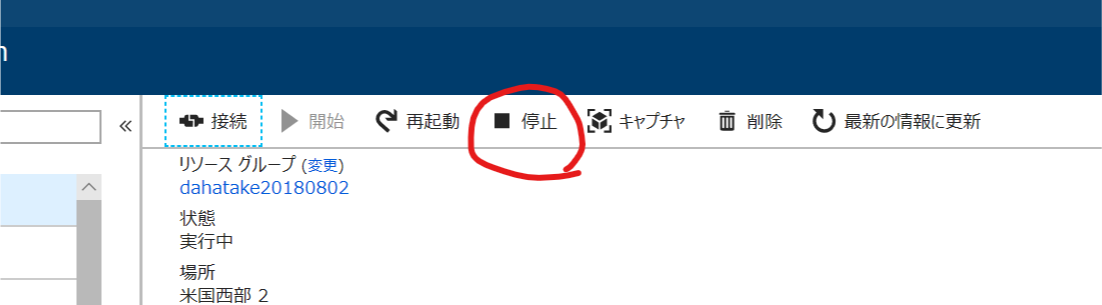
割り当て解除中と表示されます。数分 待ちます。

割り当て解除が完了すると 開始 ボタンが押せる状態になります。
-
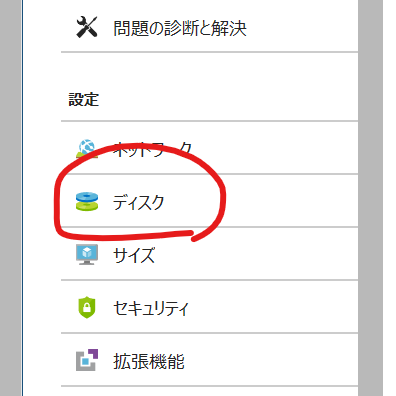
ディスクのサイズ変更
ディスクをクリックします。
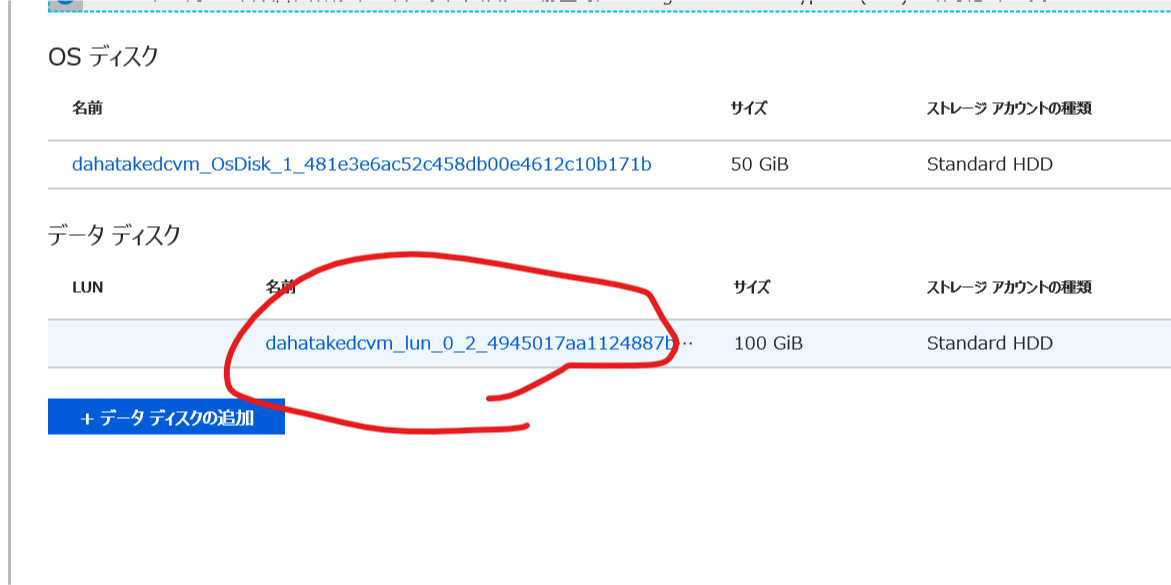
データ ディスク に追加されている 100GB のディスクを選択します。
サイズ (GiB) を適切なサイズにします。私はいつも 1023 (1TB) にしていますw
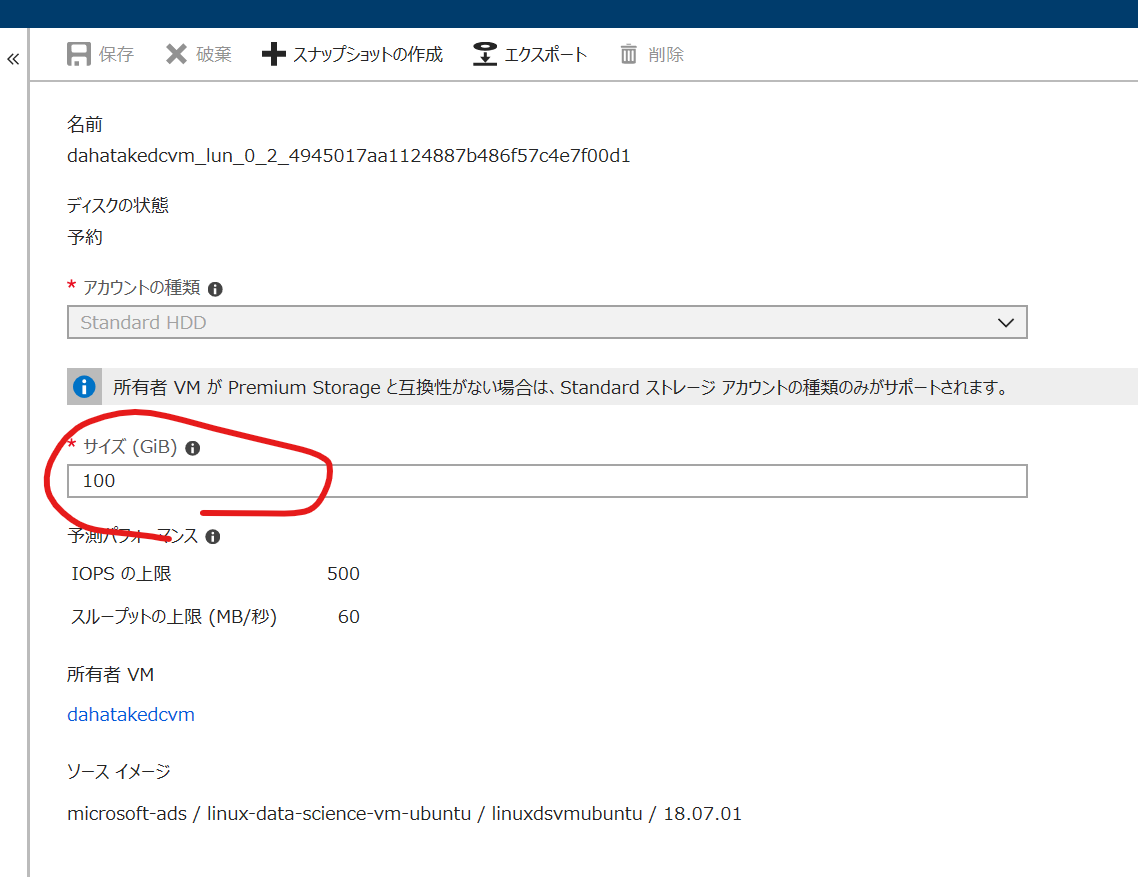
画面上部の保存を押します。
- 仮想マシンの開始
仮想マシンを開始してください。
その後、sshなどでログインして、当該ディスクのサイズが変わっている事を確認します。
一時ストレージ
Deep Learning の学習で使用する事を考えると、学習のジョブが動いている時だけファイルが存在していればよいため、ローカルでかつ必ずSSDアクセスの 一時ストレージ も有力な選択肢です。
GPU インスタンス の場合のデフォルトの一時ストレージについて:
https://docs.microsoft.com/ja-jp/azure/virtual-machines/linux/sizes-gpu
制限
- サイズ変更ができない
一時ストレージへのファイルコピー手順
ファイル (データセット)をBlob Storageに置いている場合は、AzCopy でのファイルコピーがオススメです。Data Science VM には残念ながらインストールされていませんので、sudo apt-get install azcopy にて、インストールしてください。
詳細は、こちらを。
AzCopy on Linux:
https://docs.microsoft.com/ja-jp/azure/storage/common/storage-use-azcopy-linux?toc=%2fazure%2fstorage%2fblobs%2ftoc.json
Blobfuse - ファイルコピー不要の可能性大!
Blob StorageにあるファイルをLinuxファイルシステムからアクセスするファイルシステムドライバーです。ローカルキャッシュもうまく使っているようで、非常に高速に動作します。まだプレビューではありますが...
AzCopy とどちらが良いか迷うところですが...ベンチマークしてみたいところ。
blobfuse を使用して Blob Storage をファイル システムとしてマウントする方法:
https://docs.microsoft.com/ja-jp/azure/storage/blobs/storage-how-to-mount-container-linux
Linux 仮想マシンのストレージに関しての FAQ はこちら
Azure IaaS VM ディスクと Premium 管理ディスクおよび非管理ディスクについてよく寄せられる質問:
https://docs.microsoft.com/ja-jp/azure/virtual-machines/linux/faq-for-disks