背景
RAGのお手軽検証環境として Azure AI FoundryのPlaygroundは本当に便利です。私もよく使っています。
- PlayGroundでの動作確認
- 複数のモデルの切り替え
- 複数のモデルの評価環境。MLOps含む
デフォルトのままですと、幾つかやりづらい点もあったりします。そのために、ここでは独自のAzure AI Searchを追加する手順をメモしておきます。
Azure AI Search のサービス レベルを選択する:
- Azure AI SearchのSKUの選択が柔軟ではない。デフォルト設定のStandardの能力ほど、利用しない。
- Azure AI Searchでは、Standardで作成すると、それ以下のBasicやFreeに変更できない。以上には出来る
- Azure AI Foundryで作成する Azure AI SearchのIndexer (クローラー的なもの) が参照する先データソースのBlob Storageなどが、扱いづらい...ファイル追加などの際に不便
- 独自に作成したAzure AI SearchをAzure AI Foundryに追加する際にアクセス権設定が煩雑
- この手順書 (チュートリアル) はあるものの。SDKベース。Portalのみではない。
ポイント
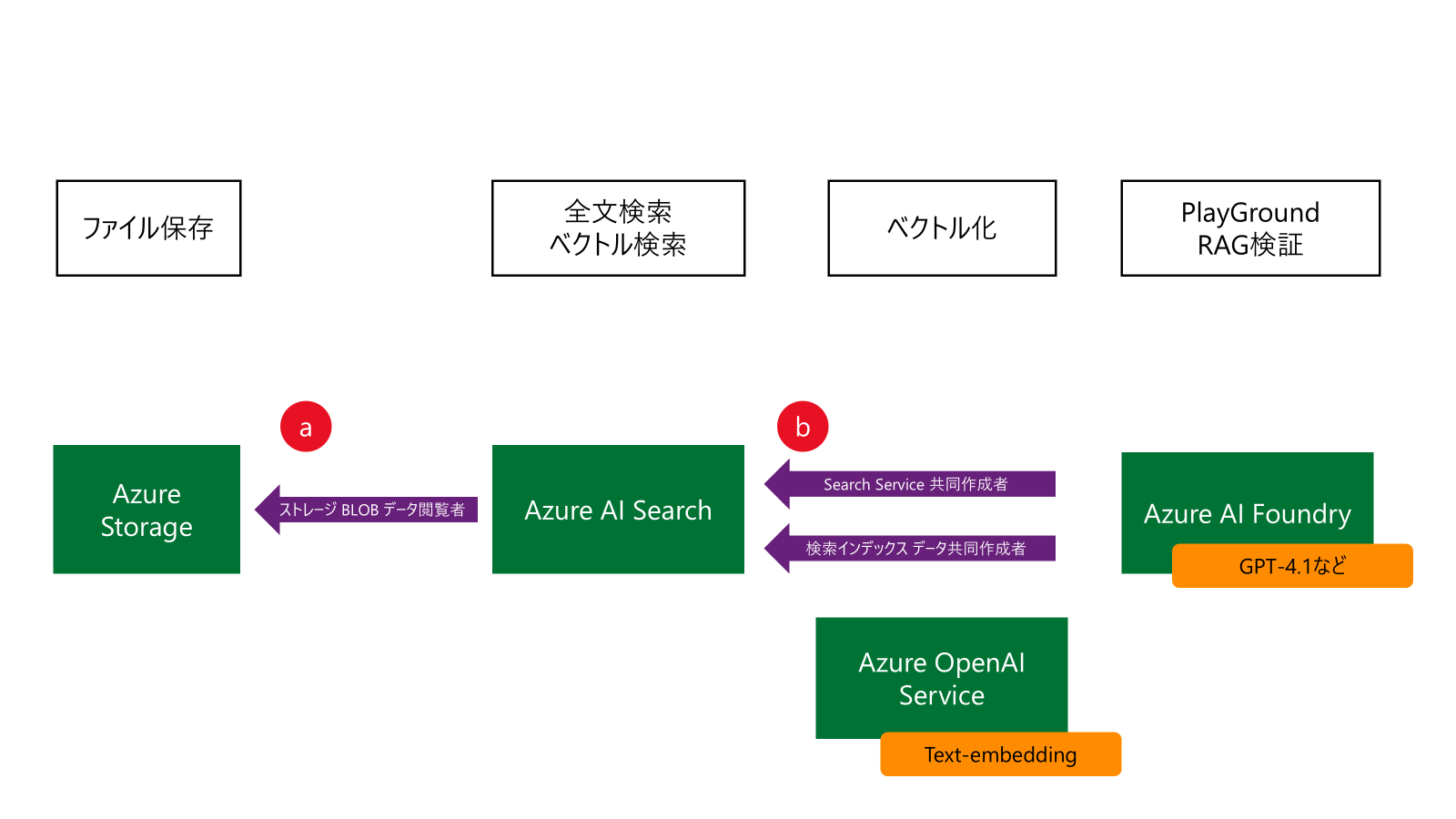
こちらが全体像ですね。
ファイルはBlob Storageに置きます。一番簡単なので
-
Azure OpenAI Service は別に
- Azure AI Searchの Wizardでは、Azure AI Foundry で Azure OpenAI ServiceのEmbedding Modelが使えません。Azure AI Foundryとは別で Azure OpenAI Service を作成します。
-
Cohere-embed-v3-multilingual については、敬愛する花ケ崎さん (@nohanaga) のBlog Postを参照してください😊
- モデルカタログ で Cohere-embed-v3-multilingual をデプロイして Azure AI Search でベクトル検索する
- https://qiita.com/nohanaga/items/fd04e2223b8a237cf335
-
権限設定は 1 度です
- Azure AI Searchが、Azure Storage Accountを読めるように
- Blob以外にファイルを置く場合は、そちらへの設定が必要ですね
- Azure AI Foundryが、Azure AI SearchのIndex操作が出来るように
- こちらはAzure AI Foundry 作成時に、既存の Azure AI Searchを選択すれば行う必要はありません。
- もし、作成後に追加する場合は、手動で設定してください。
- Azure AI Searchが、Azure Storage Accountを読めるように
必要なもの
- Microsoft Azure の Subscription
- お持ちでない方は、こちらからどうぞ!
- https://azure.microsoft.com/ja-jp/pricing/free-services/
- RAG対象のデータ
- なんでも。
- 最初は5つ程度など少量で行うことをお勧めします
- もし手持ちがなければ、敬愛する花ケ崎さん (@nohanaga) の鎌倉武将で。
-https://qiita.com/nohanaga/items/f710cac82072b63bc73f#%E3%83%89%E3%82%AD%E3%83%A5%E3%83%A1%E3%83%B3%E3%83%88%E3%81%AE%E3%82%A2%E3%83%83%E3%83%97%E3%83%AD%E3%83%BC%E3%83%89
手順
やっていきますね。
同じリソースグループに作成します。
後で、まとめて削除できるように。
1. Azure Storage Account 作成
ご参考。
1.1. ファイルのアップロード
手元のファイルをBlob Storageにアップロードします。
少量であれば、Azure Portalのストレージ ブラウザーで十分です😊
はい。楽勝ー

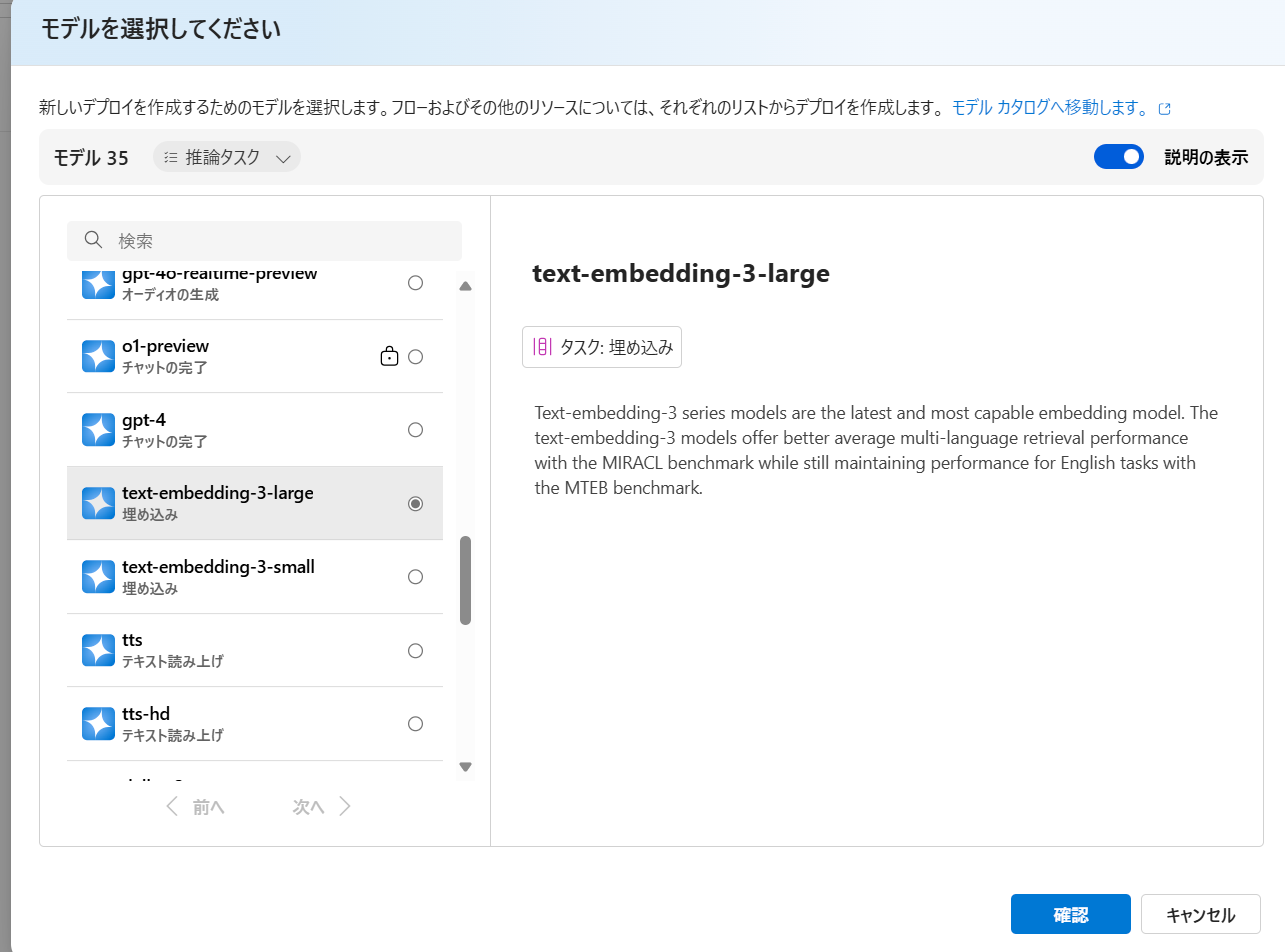
2. Azure OpenAI Service の作成
ベクトル化。つまり、Embedding 用です。Azure AI Search から参照させます。
text-embedding-3-small をデプロイします。
ご参考
Azure OpenAI Serviceでのモデルのデプロイは、Azure AI Foundry | Azure OpenAI Service の画面から行えます。
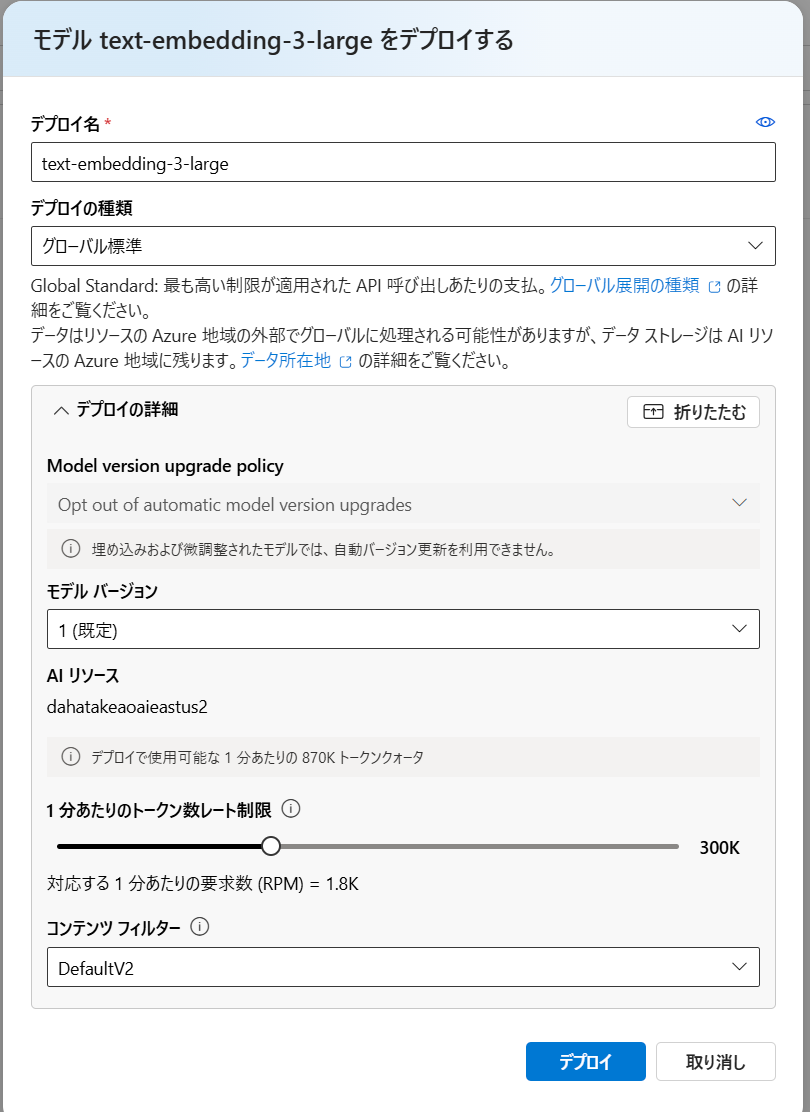
デフォルトのままですと、検索エンジンでのIndex作成時に、一度に大量にAPI呼び出しをする可能性があります。
1分あたりのトークン数レート制限を少し多めにしておきます。この数字は、課金には影響しませんが、自分のSubscription全体での上限があるので、大きくし過ぎると、別のデプロイ時に、そちらは少ししか処理できない可能性があります。
並列実行の観点で、どうするか考えたいですね😊
3. Azure AI Search の作成
さて。いよいよコアのSearchです。
ここではSKUを無料のFreeにします。
- 無償版はコンピューター能力や機能に制限があります。ベクトル化を含むRAG検証で、大量のデータからの検索時などには適さない場合がある点は十二分に留意しましょう。
- 1つのSubscriptionで、FreeのSKUは1つだけ作成できます。
- 無償版の Azure AI Searchから、Azure Storage アカウントへの認証は、キー認証のみ。ロールベースのアクセスはサポートしていない。

こちらを適時参照ください。
3.1. Azure AI Search のアカウント作成
さて、ここから Azure AI Searchを使って、検索用のIndexを作成します。
まず、Entra IDにAzure AI Searchのアカウントを作成します。
デフォルトですと作成されていません。
Azure AI Searchの画面に移動します。
- [ID]に移動します
- [システム割り当て済み]が、オフになっています。「オン」にして[保存]を押します。

作成が終わると以下の画面の様にオブジェクト(プリンシパル)IDが作成されます。

- 無償版のSKUから、Azure Storageアカウントにアクセスするために、キー認証を有効化します。

3.2. Azure AI SearchにAzure Storageアカウントのアクセス権を設定
Azure Storage Accountの画面に移動します。
- [アクセス制御]に移動します。
- ここで、ユーザーや各種Azureのリソースなどのアクセス権設定を行います。この画面は、Subscriptionやリソースグループなど、Azureのリソースの各層で同じ操作で設定ができます。

- [ロール]の検索用のテキストボックスを使って、ストレージ BLOB データ閲覧者 を検索します。

- [メンバー]の画面でAzure AI Searchを検索します
- [マネージドID]を選択
- 画面右側に出てくる[マネージドIDの選択]の[マネージドID]で「Search Services」を選択します。
- 先ほど作成した Azure AI Search が見つかります。サービス名とアカウント名が同じになります。これを選択します。選択すると、下の[選択したメンバー]に移動します。
- [選択]ボタンを押します。
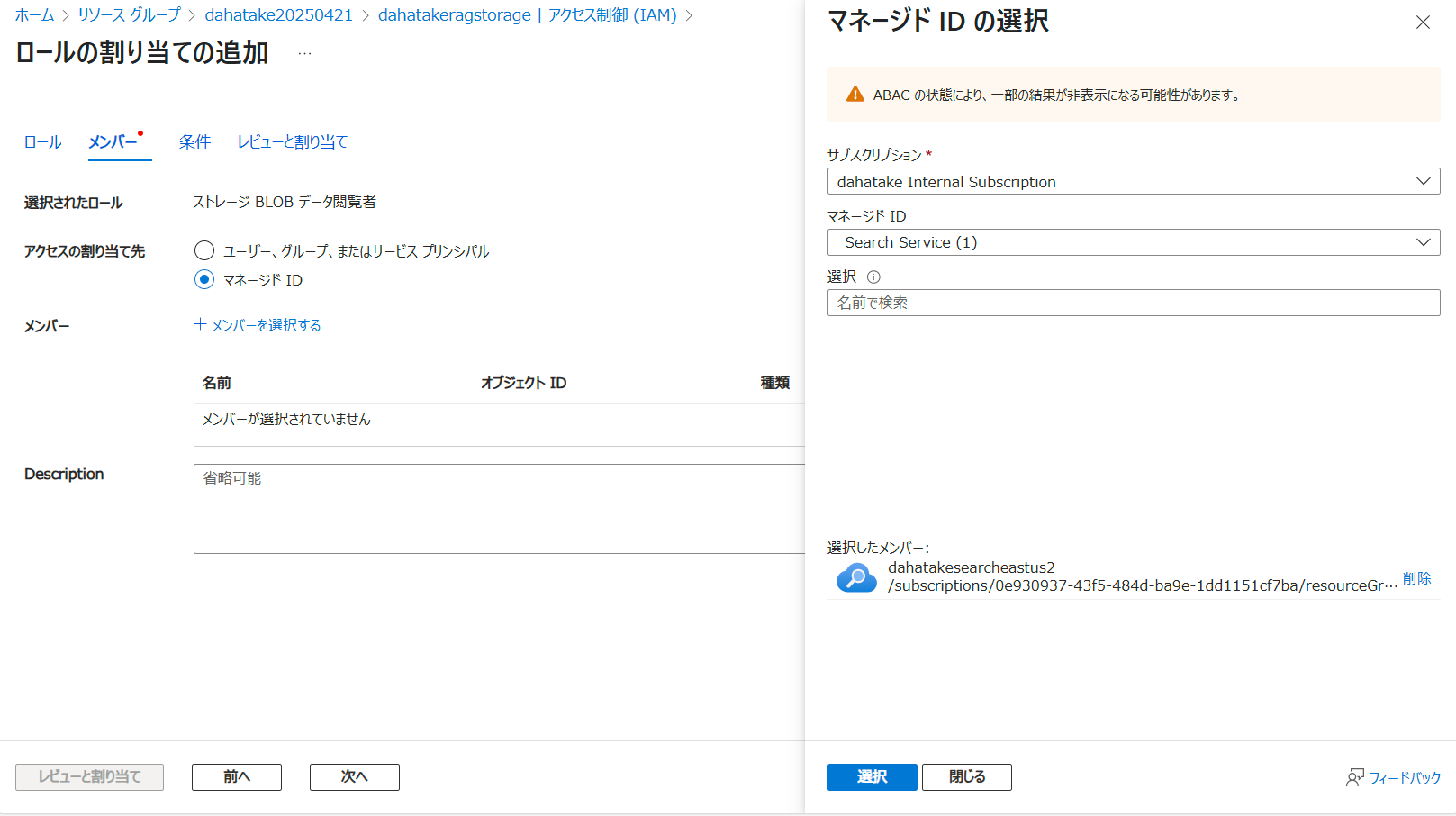
- [レビューと割り当て]を押して、アクセス権を設定します。
3.2. インデックス作成
Azure AI SearchのPortal画面上から、Indexerの設定を行います。
こちらのドキュメントを適時参考にしてください。
クイックスタート: Azure portal を使用してテキストと画像をベクトル化する:
- Azure Storage 作成時に階層型名前空間の設定が、オンなのかオフなのかで、Azure Blob Storage なのか、Azure Data Lake Storage Gen2なのかが変わります。注意してください。
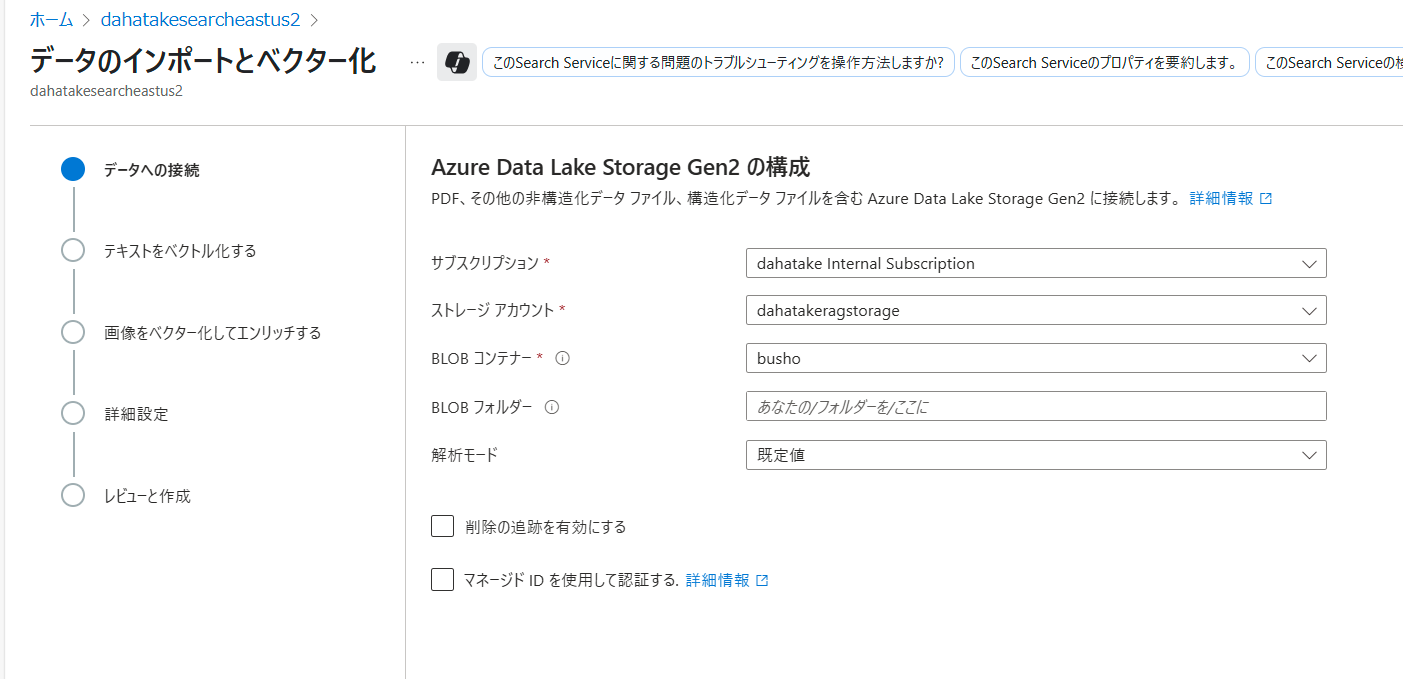
Embedding (ベクトル化) のAPI設定で、先にデプロイしたAzure OpenAI ServiceのEmbeddingモデルを選択します。

今回は画像を扱いません。
その後はデフォルト設定のまま進めます。
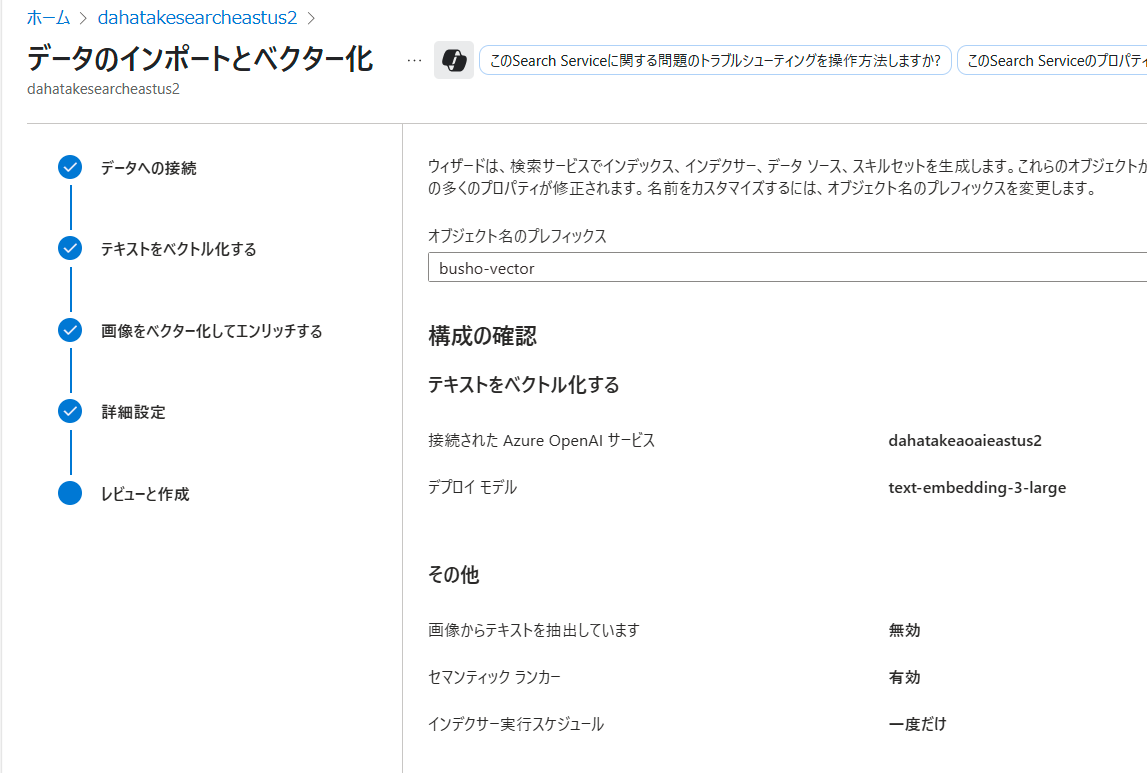
数分待つと、Indexingが終了します。

インデックスのジョブが正しく終了したかを確認します。
Azure AI Searchの[インデックサー]の画面から、成功したドキュメントなどを確認します。
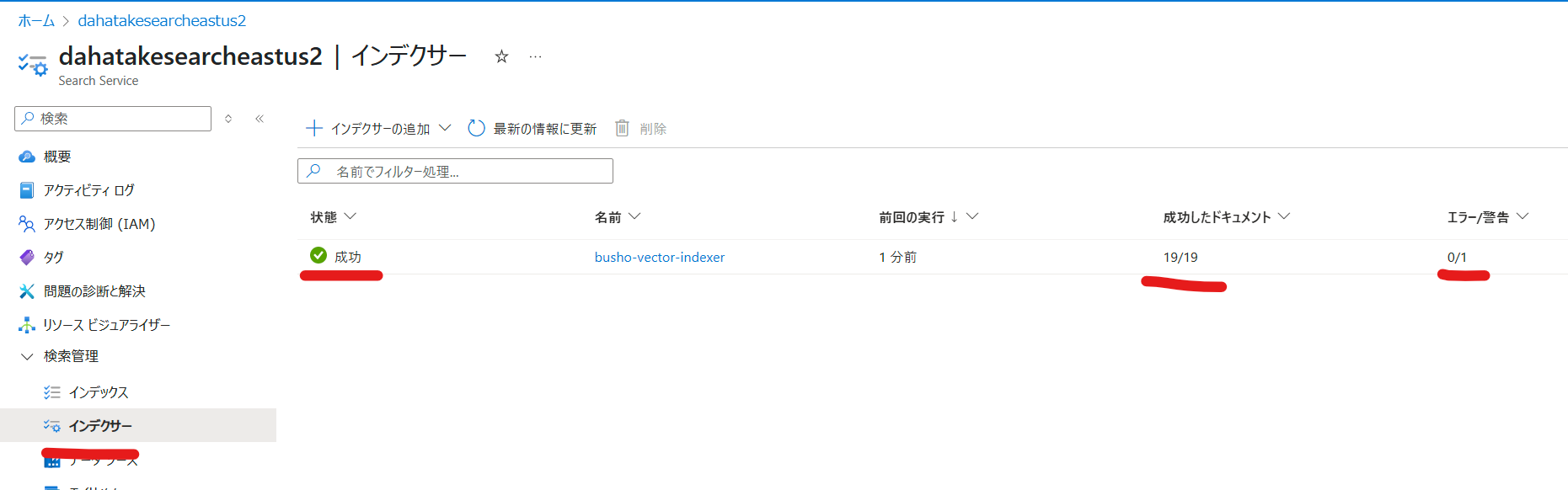
大丈夫そうであれば、実際に検索を試してみましょう。
[インデックス]から、作成したIndexを選択します。
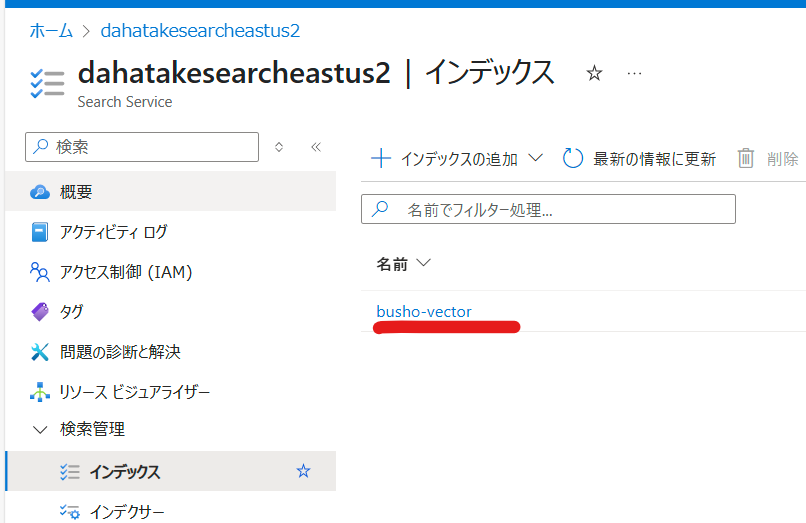
早速「文章」で検索をしてみます。
鎌倉武将に関連するものであれば、なんでもいいです。

RAG 実施時の大事な点
- 本来は、ここで検索の精度の確認を行います。上位n件に何がヒットしているかを確認します
- デフォルトで取得できているデータ項目、フィールドに注目してください。
- chunk に取得できたデータの内容が入っています。そうなんです、デフォルトで元ファイルを分割しています
- title にファイル名が入っています。Indexerは、特定のフォルダー以下を検索していますからね。特定ということは固定のURLになるわけで。このtitleと合わせて、データソースになります
4. Azure AI Foundry の作成
いよいよ Azure AI Foundry の作成を行います。
諸々関連リソースも作成されるため、 ai.azure.com から行うのがおススメです。
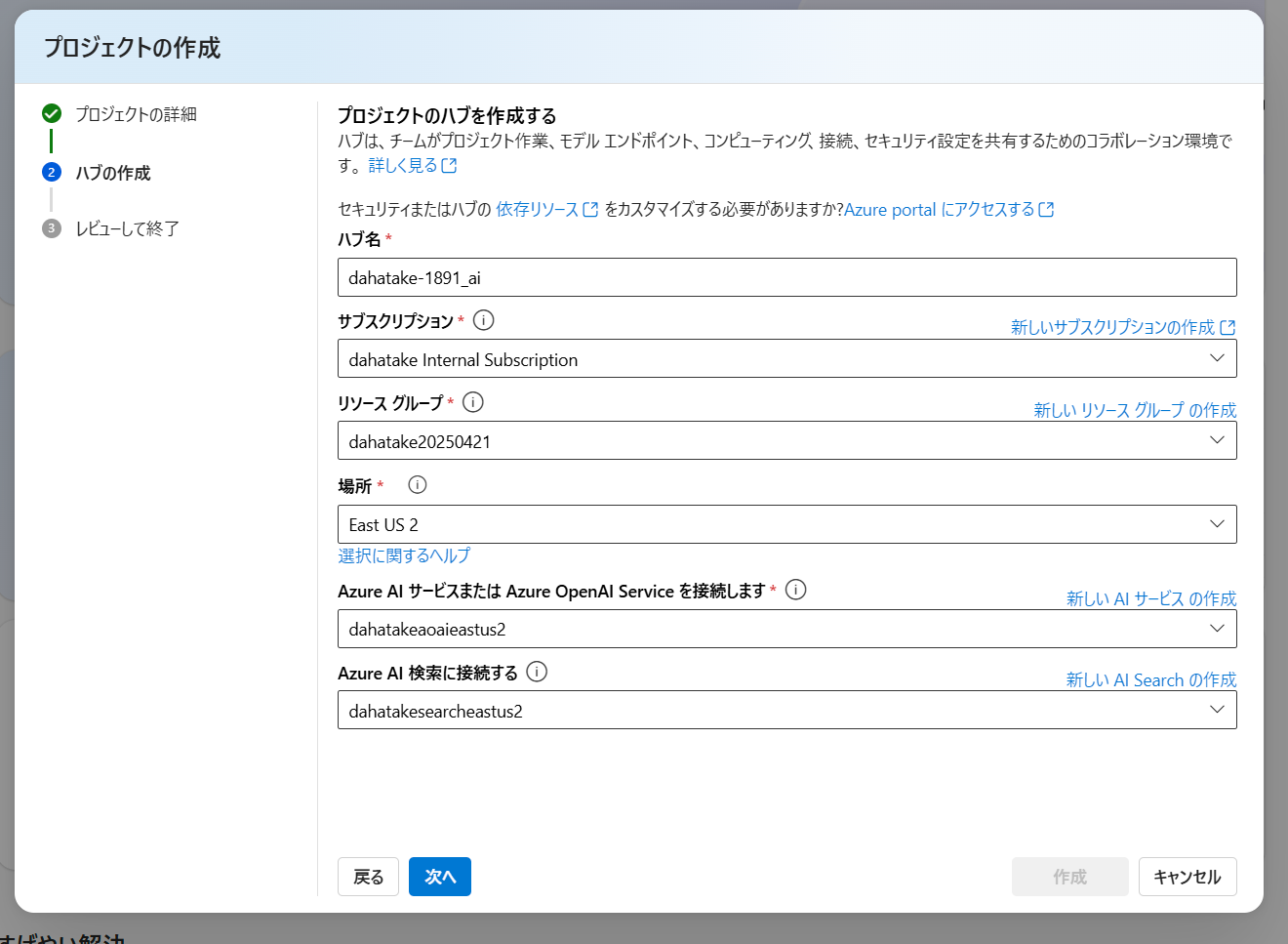
画面右上の [プロジェクトの作成] から行います。

プロジェクトの作成画面です。ここでは、これまで作成してきたリソースと同じリソースグループに保存をしたいので[カスタマイズ]を押します。

実は、ここでは既存のリソースを全て選択します。新規に何かの作成を行いません。
いろんな関連リソースの作成状況を確認できます。

3-5分くらいで出来ました!
4.1. Modelのデプロイ
Chat の PlayGround で利用するModelをデプロイします。
ここでは、GPT-4.1 を選択します。

4.2. Index の追加
Azure AI Foundryの画面の左側のメニューからIndexの追加画面に移動します。
- [データとインデックス] - [インデックス]
- [新しいインデックス]

ベクトルインデックスを作成するから[Azure AI 検索]を選択します。
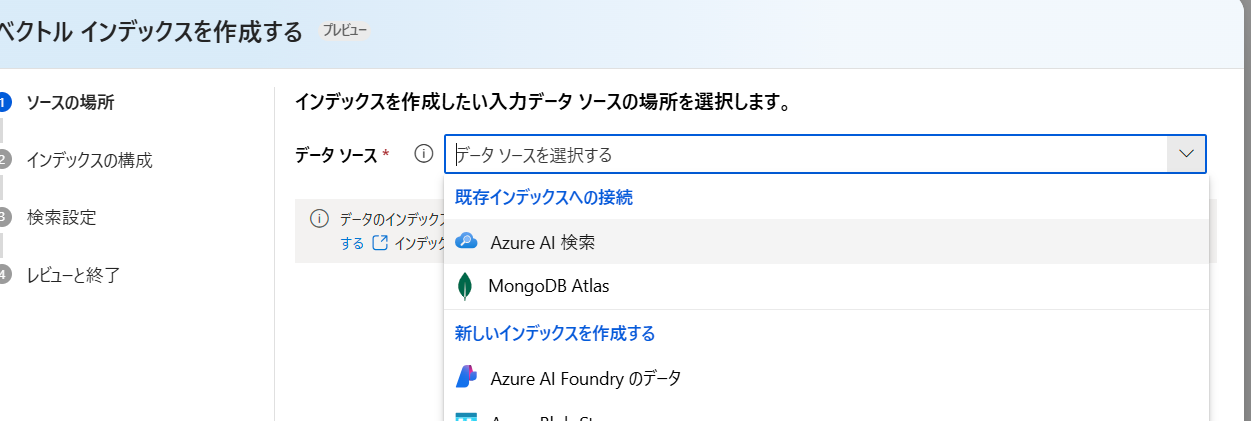
外部インデックスの画面で、先に作成した Azure AI Service と Index を選択します。
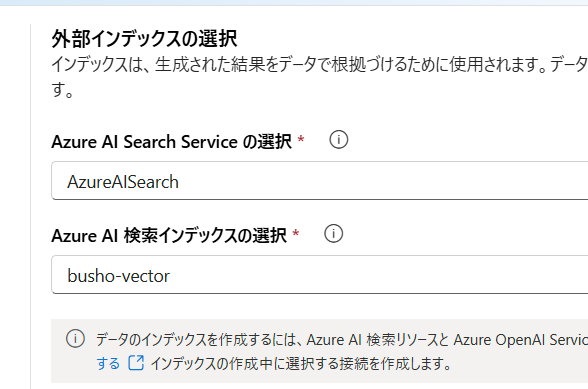
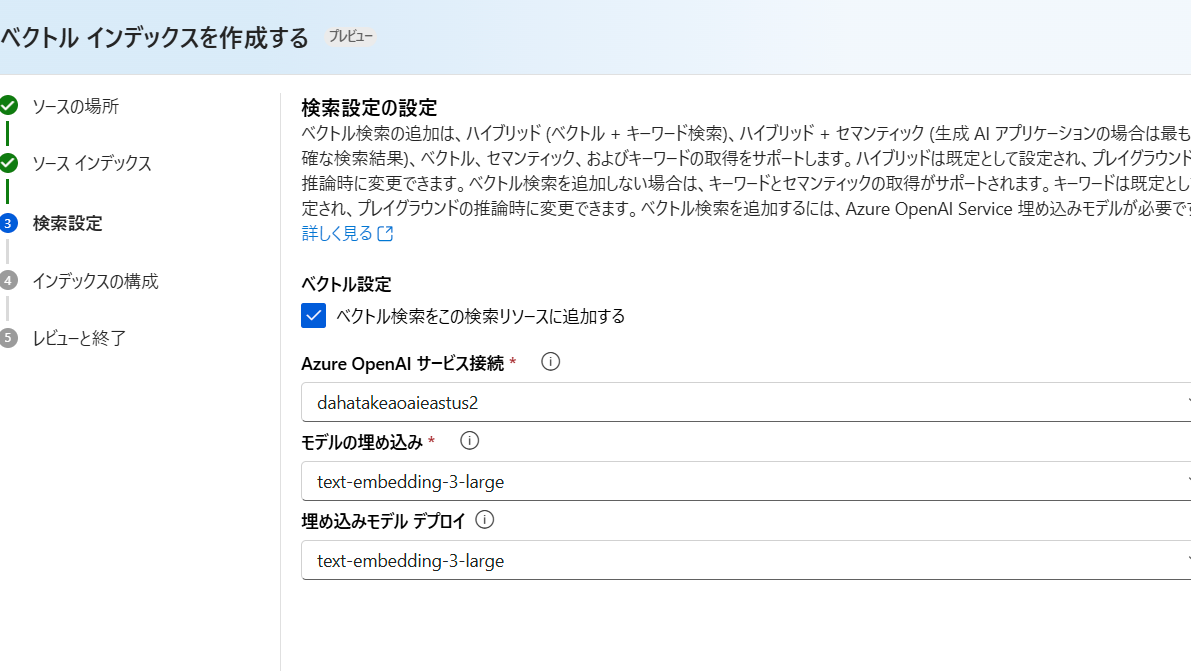
ストアがベクトルで保存されています。そのため、[検索設定の設定]画面で、Azure OpenAI ServiceのEmbeddingモデルを選択します。
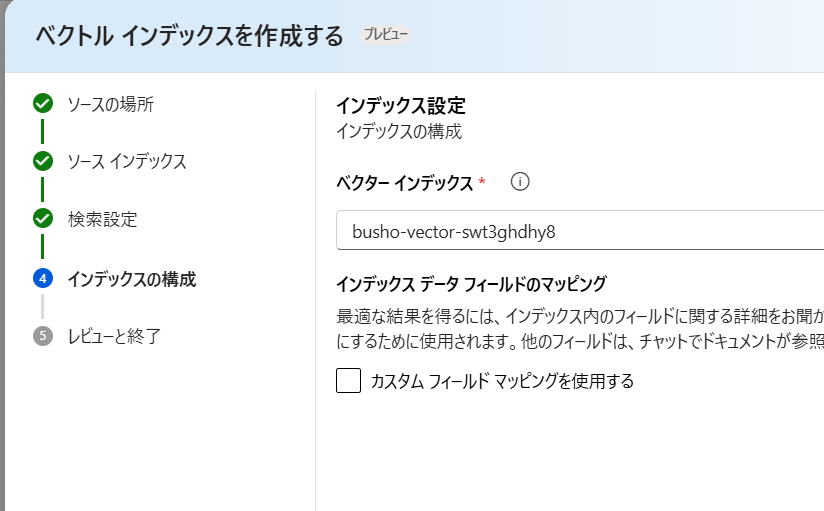
ベクターインデックスの画面です。
ちょっと混乱しますね。先にIndexは作成済みなんですがね..
ベクターインデックス名は、適時変更してください。
作成できました!

5. Azure AI Foundry の PlayGround で動作確認
これで PlayGround の画面で、インデックスが参照できるようになります。
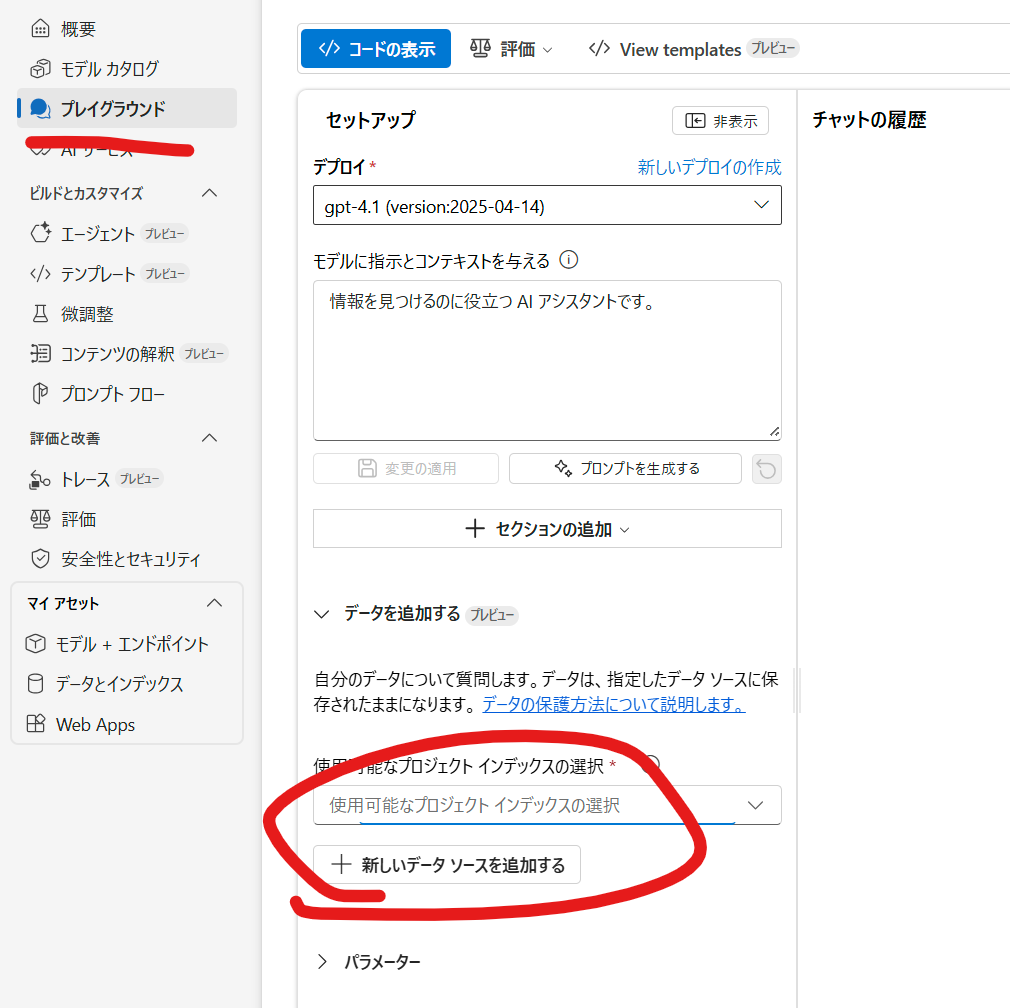
先に Azure AI Search で作成したインデックスではなく、Azure AI Foundryで作成したインデックスですね。

PlayGournd では、デフォルトの出力トークン数が800と大変少ないです!
ここは、max にしておきましょう😊

Prompt:
源頼朝が行ったことについて要点をリストアップしてください。
相当適当です...

動作の確認ができるかと思います。
チャンクしたファイルが見えますね。
まとめ
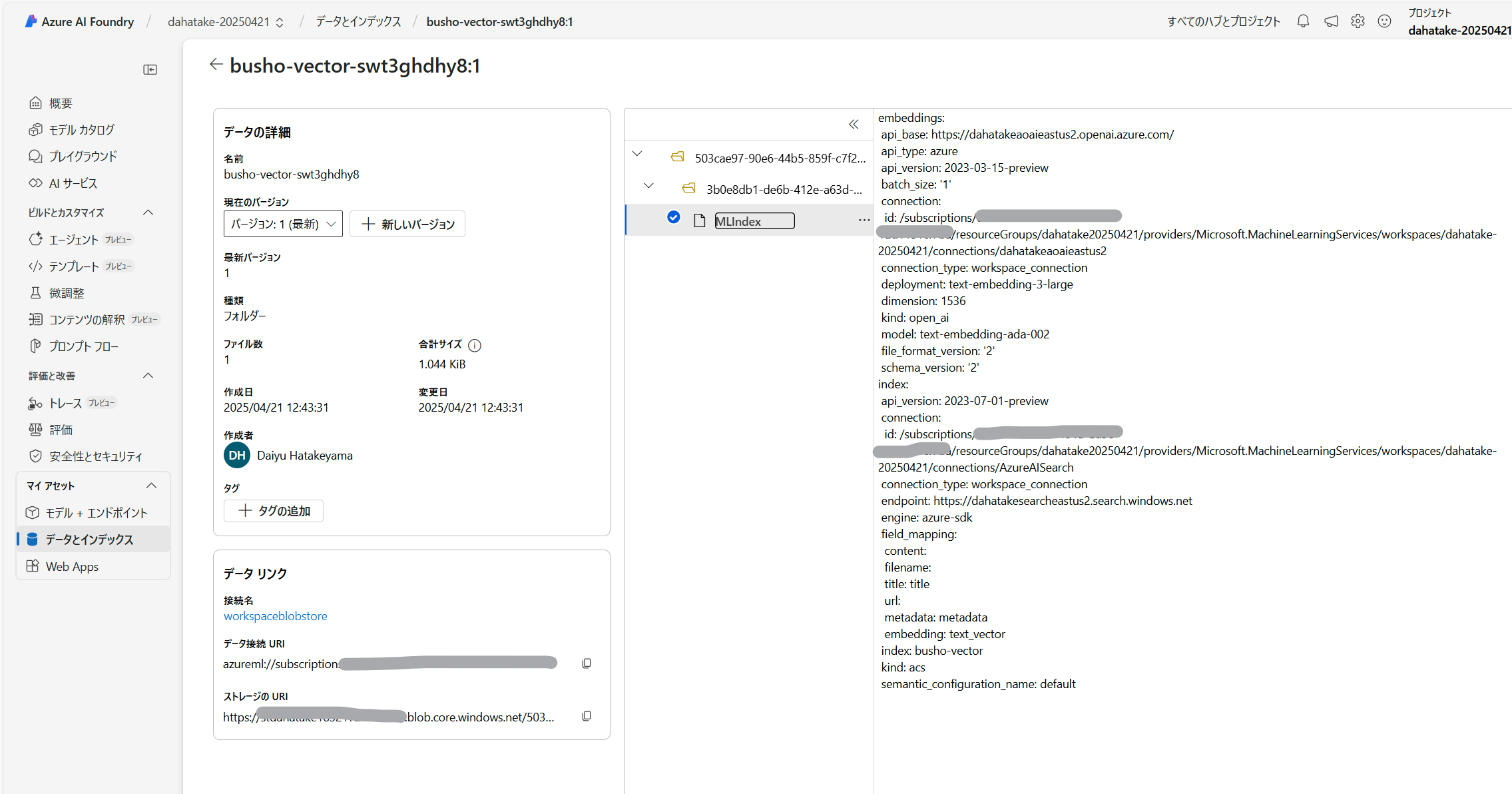
こちらが今回作成したリソースたちです。

特に気になる Azure AI Search のIndexは、1つだけですね。

Azure AI FoundryのPlayGroundから見えているIndexについては、参照されているBlobに格納されているファイルを見てみても。事前作成したIndexへのリンクが見えているのみです。
数日放置してみましたが、特に課金もされず、モニター上も確認ができず、でした。
この辺りは追加の調査が必要とは思いますが。
これで、初期のRAGの挙動など、楽しんでください!!!!