目的
パチスロデータサイトのグラフ画像から差枚数を算出したい。
その際、グラフ画像上に表記されている枚数が必要だった為、OCRで表記枚数を取得する。
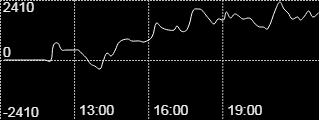
このようなグラフ画像。
取得したいのは左上に表記されている数値(この画像の場合は2410)
用意するもの
・Tesseract(4.0以降)
・PyOCR
インストール方法等は割愛。
ページ下部に参考リンクを載せておくのでそちらからお願いします。
OCRしてみる
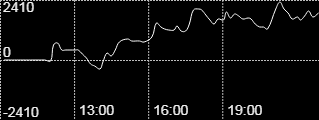
とりあえずこのグラフ画像をそのまま読み取ってみる。
from PIL import Image
import pyocr
import pyocr.builders
import sys
file_path = 'ファイルパス'
# ツール読み込み
tools = pyocr.get_available_tools()
# ツールが見付からない場合
if len(tools) == 0:
print('pyocrが見付かりません。pyocrをインストールして下さい。')
sys.exit(1)
tool = tools[0]
# 画像読み込み
img_org = Image.open(file_path)
# OCR
max_medals = tool.image_to_string(img_org, lang='jpn', builder=pyocr.builders.DigitBuilder(tesseract_layout=6))
print(f'max_medals:{max_medals}')
-
数値は何も取得出来ず。
色々調べてみたところ、数値のOCRは英語のデータセットでやった方が精度高いらしいので言語設定を英語に変更した。
言語設定を英語に変更
from PIL import Image
import pyocr
import pyocr.builders
import sys
file_path = 'ファイルパス'
# ツール読み込み
tools = pyocr.get_available_tools()
# ツールが見付からない場合
if len(tools) == 0:
print('pyocrが見付かりません。pyocrをインストールして下さい。')
sys.exit(1)
tool = tools[0]
# 画像読み込み
img_org = Image.open(file_path)
# OCR
max_medals = tool.image_to_string(img_org, lang='eng', builder=pyocr.builders.DigitBuilder(tesseract_layout=6))
print(f'max_medals:{max_medals}')
2410 1300160019.00
今度は表記されている数字をある程度取得出来た。
ただ、必要でない部分も読み取ってしまっているので読み取りたい部分のみを切り取ってから処理をする形に書き換え。
読み取り箇所を切り取ってからOCR
from PIL import Image
import pyocr
import pyocr.builders
import sys
file_path = 'ファイルパス'
# ツール読み込み
tools = pyocr.get_available_tools()
# ツールが見付からない場合
if len(tools) == 0:
print('pyocrが見付かりません。pyocrをインストールして下さい。')
sys.exit(1)
tool = tools[0]
# 画像読み込み
img_org = Image.open(file_path)
# 枚数表記部分を切り取り
max_medals_img = img_org.crop((0, 0, 45, 15))
# OCR
max_medals = tool.image_to_string(max_medals_img , lang='eng', builder=pyocr.builders.DigitBuilder(tesseract_layout=6))
print(f'max_medals:{max_medals}')
max_medals:2410
上手く行った!
精度を上げる
先程のコードで上手く行ったので読み取るグラフ画像の枚数を増やして再度実行してみた。
from PIL import Image
import pyocr
import pyocr.builders
import sys
from glob import glob
file_path = 'ファイル格納ディレクトリ'
# 読み込むファイルリスト作成
file_list = [file for file in glob(f'{file_path}*.png')]
for file_path in file_list:
# ツール読み込み
tools = pyocr.get_available_tools()
# ツールが見付からない場合
if len(tools) == 0:
print('pyocrが見付かりません。pyocrをインストールして下さい。')
sys.exit(1)
tool = tools[0]
# 画像読み込み
img_org = Image.open(file_path)
# 枚数表記部分を切り取り
max_medals_img = img_org.crop((0, 0, 45, 15))
# OCR
max_medals = tool.image_to_string(max_medals_img, lang='eng', builder=pyocr.builders.DigitBuilder(tesseract_layout=6))
print(f'max_medals:{max_medals}')
max_medals:2410
max_medals:
max_medals:490
max_medals:2717
max_medals:689
max_medals:504
max_medals:1013
max_medals:
max_medals:862
max_medals:979
max_medals:835
max_medals:1683
max_medals:1587
max_medals:1010
max_medals:7
max_medals:1586
max_medals:1653
max_medals:413
max_medals:1167
max_medals:527
いくつか正常に読み取れていない画像が出てきた。
以前、別の形式の画像でOCRを試した事があってその時はエラーが全く出なかったのですが、その時の形式が
「背景色:白、文字色:黒」
という形式の画像だったので背景色と文字色を反転させてみた。
背景色と文字色を反転させる
from PIL import Image, ImageOps
import pyocr
import pyocr.builders
import sys
from glob import glob
file_path = 'ファイル格納ディレクトリ'
# 読み込むファイルリスト作成
file_list = [file for file in glob(f'{file_path}*.png')]
for file_path in file_list:
# ツール読み込み
tools = pyocr.get_available_tools()
# ツールが見付からない場合
if len(tools) == 0:
print('pyocrが見付かりません。pyocrをインストールして下さい。')
sys.exit(1)
tool = tools[0]
# 画像読み込み
img_org = Image.open(file_path)
# 枚数表記部分を切り取り
max_medals_img = img_org.crop((0, 0, 45, 15))
# 背景色と文字色を反転(白文字→黒文字へ変換)
max_medals_img = ImageOps.invert(max_medals_img.convert('RGB'))
# OCR
max_medals = tool.image_to_string(max_medals_img, lang='eng', builder=pyocr.builders.DigitBuilder(tesseract_layout=6))
print(f'max_medals:{max_medals}')
max_medals:2410
max_medals:440
max_medals:490
max_medals:2717
max_medals:689
max_medals:504
max_medals:1013
max_medals:791
max_medals:862
max_medals:979
max_medals:835
max_medals:1683
max_medals:1587
max_medals:1010
max_medals:1132
max_medals:1586
max_medals:1653
max_medals:413
max_medals:1167
max_medals:527
先程まで正常認識出来ていなかった画像も正常に認識出来た。
このコードで更に画像読み取りサンプルを増やしてみたところ…
max_medals:1908.
max_medals:
max_medals:1000-
max_medals:10
このように表記されていない文字が混入していたり桁数がおかしかったりそもそも数字を認識出来ないケースがまだ稀に存在。
(約10000件中7件)
更に精度を上げる為にOCRのモードを変更。
モードを6から8へ変更(画像を単語とみなすモード)
from PIL import Image, ImageOps
import pyocr
import pyocr.builders
import sys
from glob import glob
file_path = 'ファイル格納ディレクトリ'
# 読み込むファイルリスト作成
file_list = [file for file in glob(f'{file_path}*.png')]
for file_path in file_list:
# ツール読み込み
tools = pyocr.get_available_tools()
# ツールが見付からない場合
if len(tools) == 0:
print('pyocrが見付かりません。pyocrをインストールして下さい。')
sys.exit(1)
tool = tools[0]
# 画像読み込み
img_org = Image.open(file_path)
# 枚数表記部分を切り取り
max_medals_img = img_org.crop((0, 0, 45, 15))
# 背景色と文字色を反転(白文字→黒文字へ変換)
max_medals_img = ImageOps.invert(max_medals_img.convert('RGB'))
# OCR
max_medals = tool.image_to_string(max_medals_img, lang='eng', builder=pyocr.builders.DigitBuilder(tesseract_layout=8))
print(f'max_medals:{max_medals}')
1枚の画像自体が単語とみなすモードに変更。
(枚数表記部分のみを切り取ってからOCRしている為このモードが最適なはず)
このモードの方が精度が良くなった。
(約10000件中4件程度まで減った)
しかし、まだ正常認識出来ていないケースがあったのでとりあえず数値以外の文字を除外するコードを追加。
数値以外の文字を除外
import re
from PIL import Image, ImageOps
import pyocr
import pyocr.builders
import sys
from glob import glob
file_path = 'ファイル格納ディレクトリ'
# 読み込むファイルリスト作成
file_list = [file for file in glob(f'{file_path}*.png')]
for file_path in file_list:
# ツール読み込み
tools = pyocr.get_available_tools()
# ツールが見付からない場合
if len(tools) == 0:
print('pyocrが見付かりません。pyocrをインストールして下さい。')
sys.exit(1)
tool = tools[0]
# 画像読み込み
img_org = Image.open(file_path)
# 枚数表記部分を切り取り
max_medals_img = img_org.crop((0, 0, 45, 15))
# 背景色と文字色を反転(白文字→黒文字へ変換)
max_medals_img = ImageOps.invert(max_medals_img.convert('RGB'))
# OCR
max_medals = tool.image_to_string(max_medals_img, lang='eng', builder=pyocr.builders.DigitBuilder(tesseract_layout=8))
# 数値以外の文字を除去
max_medals = re.sub(r'\D', '', max_medals)
print(f'max_medals:{max_medals}')
これで「-」や「.」等の表記されていない数値以外の文字が余計に混入してしまうケースを回避。
ただし、まだ稀に数値自体が認識出来ていなかったり桁数がおかしいケースがあった。
どうしようかなぁと色々と改善策を練って
画像左上と左下の両方の枚数表記を取得
↓
両者を比較
↓
正常と思われる方を採用
等々何パターンかロジックを考えたがコードが長い+複雑になった為、ここで少し考え直す。
「そもそもOCRでの認識精度をもっと上げる事が出来れば面倒なコードを書く必要が無いのでは」
と当たり前っちゃ当たり前な考えに至り、OCRの前処理の枚数表記切り取りサイズを色々と変更して試した。
最終的なコード
import re
from PIL import Image, ImageOps
import pyocr
import pyocr.builders
import sys
from glob import glob
file_path = 'ファイル格納ディレクトリ'
# 読み込むファイルリスト作成
file_list = [file for file in glob(f'{file_path}*.png')]
for file_path in file_list:
# ツール読み込み
tools = pyocr.get_available_tools()
# ツールが見付からない場合
if len(tools) == 0:
print('pyocrが見付かりません。pyocrをインストールして下さい。')
sys.exit(1)
tool = tools[0]
# 画像読み込み
img_org = Image.open(file_path)
# 枚数表記部分を切り取り
max_medals_img = img_org.crop((0, 0, 44, 14))
# 背景色と文字色を反転(白文字→黒文字へ変換)
max_medals_img = ImageOps.invert(max_medals_img.convert('RGB'))
# OCR
max_medals = tool.image_to_string(max_medals_img, lang='eng', builder=pyocr.builders.DigitBuilder(tesseract_layout=8))
# 数値以外の文字を除去
max_medals = re.sub(r'\D', '', max_medals)
print(f'max_medals:{max_medals}')
色々なサイズで試したところ、このコードで手元にあったグラフ画像の認識率が100%になった!
ロジック考えるよりも切り取りサイズのベストプラクティスを見付ける方が良かったという結果(笑)
結論
上手く文字認識出来ない場合は
画像そもそもを疑う > 設定等を見直す > 別のロジックを付け加えて調整
この優先順位で詰めていくとハマりにくくなるかと思う。
今回は数値だけの認識とはいえ凄い精度ですね、OCR。