研究者がAIを使い倒す時代、ならば“AI研究チーム”を作ったらどうなるのか?
TL;DR
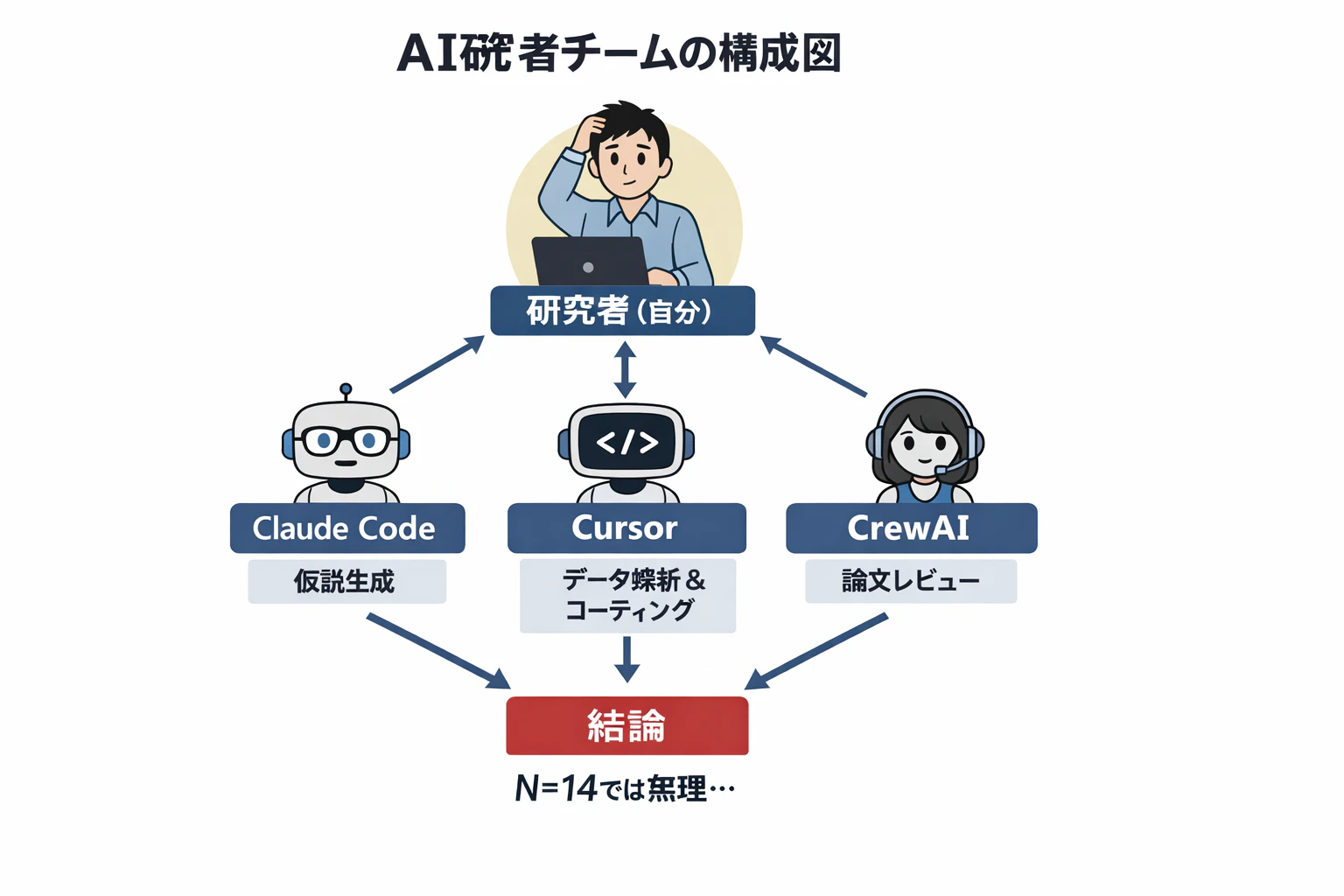
Claude Code + Cursor + CrewAI で AI研究チームを作ってみた。
AIは
- 仮説生成
- 研究レビュー
- 研究計画
全部できた。
しかし最後に判明したのはこれだった。
「N=14では統計的に検出できない」
検出力シミュレーション30秒で研究が終わった。
統計の世界では
AIより計算のほうが強い。
AI研究チームを作ってみた
AI同士を連携させて研究をさせたらどうなるのか。
ふと思った。
最近は
- Claude Code
- Cursor
- CrewAI
などAIツールが急速に増えている。
ならば
AI研究チームを作れるのでは?
という実験をしてみた。
構成
今回作った「AI研究チーム」はこれ。
Claude Code (司令塔)
|
|-- CrewAI + Gemini (研究チーム)
|
|-- Cursor (批判的レビュアー)
役割はこう。
ツール 役割
Claude Code: 司令塔・実装・判断
CrewAI: 仮説生成・研究議論
Cursor: 批判的レビュー
つまり
AIがAIをレビューする研究体制。
ワークフロー
研究フローはこう。
CrewAI → 研究レポート生成
↓
Claude Code → レビュープロンプト生成
↓
Cursor → 批判的レビュー
↓
Claude Code → 実装判断
半自動の研究ワークフロー。
CrewAIの提案
CrewAIが提案した前兆指標TOP5。
- b値 (Gutenberg-Richter)
- GNSS非定常変位
- 地震活動率異常
- フラクタル次元
- 深発-浅発結合
いかにも研究っぽい。
Cursorレビュー
Cursorの評価。
観点 評価
物理的妥当性: B
統計的厳密性: C
Phase1反映: C
実装可能性: D
文献引用: B
指摘は鋭かった。
- 既に棄却された指標の焼き直し
- 空間窓が未定義
- N=14の検出力分析がない
つまり
そもそも検出できるのか?
AIに聞いてみた
AIに聞いた。
「この指標は有意差が出ますか?」
AIの答え
有意差が出る可能性があります
しかしこれは
何も言っていないのと同じ。
30秒の計算
そこで検出力シミュレーションを回した。
N=14, Wilcoxon signed-rank test
d=0.3 → power 25%
d=0.5 → power 51%
d=0.8 → power 86%
d=1.0 → power 97%
つまり
かなり大きな効果量でないと検出できない。
ここで研究の前提が崩れた。
実データ
実際に計算すると
Valid events: 7/14
delta_b mean: -0.018
p = 0.289
Cohen's d = -0.437
当然
有意差なし。
しかしもっと大きな問題があった。
致命的な問題
有効イベント7件。
しかも
全部東北沖リージョン。
つまり
同じ地域の地震を
7回測っただけ。
統計的に独立サンプルではない。
研究終了。
AI研究チームの限界
今回の実験で分かったこと。
AIは
できること 理由
仮説生成: 発想が豊富
レビュー: 論理チェック
研究議論: 整理が得意
しかし
できないこと 理由
統計的有意性: 計算が必要
データ制約: 実データ依存
検出力判断: 数値解析が必要
最大の教訓
AIは論理を作れる。
しかし
統計は作れない。
統計的な正しさは
AIに聞いても出てこない。
結論
AI研究チームは確かに便利だった。
仮説は大量に出る。
レビューも鋭い。
しかし最後に研究を決めたのはこれだった。
検出力シミュレーション
実行時間:30秒
統計の世界では
AIより計算のほうが強い。