Seonghyeon Nam, Yunji Kim, and Seon Joo Kim
Yonsei University
NeurIPS 2018
arXiv, pdf, GitHub
以前読んだ論文が比較手法として登場していたので読んでみた.
どんなもの?
画像とテキストを入力とし,テキストの属性をもつ画像に修正するGAN, TAGAN (Text-Adaptive Generative Adversarial Network) を提案.

先行研究との差分
- 従来手法ではオリジナル画像内のコンテンツが崩れることが多かった.提案手法では与えられたテキストで言及されていない部分は保持した画像を生成する.
- Word-level の discriminator を提案.
技術や手法のキモ
- $x$ : 画像
- $t$ : 画像とマッチしたテキスト
- $\hat{t}$ : 画像とマッチしていないテキスト
目標は,$x$ と $\hat{t}$ が与えられたときに,$\hat{t}$ の属性が加えられ,一方で $\hat{t}$ で言及されていない属性については $x$ のコンテンツを保持した画像 $\hat{y} = G(x, \hat{t})$ を生成すること.
Generator
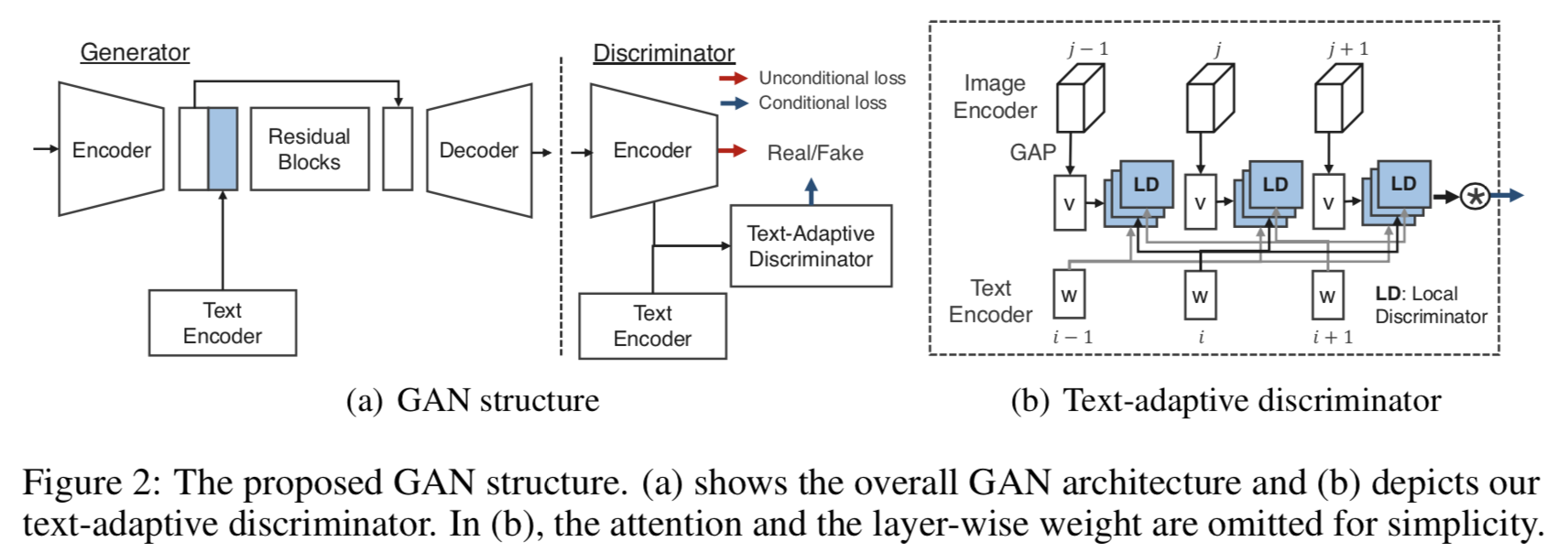
上の画像は,提案手法の全体図.
Generator はこの Figure 2 (a) の encoder-decoder network.
encoder-decoder network は [15] の ものを使用.
テキストは bidirectional GRU でエンコード.
さらに StackGAN[12] の conditional augmentation method を適用することで,滑らかなテキスト表現と生成された出力に多様性を持たせる.
しかし,このままではテキストで言及されていない新たなコンテンツが生成されてしまうので,reconstruction loss [27] $L_{rec}$ を導入する.
テキストとして入力画像とマッチした $t$ が与えられたときに,入力画像を生成させるようなロス.
L_{rec} = || x - G(x, t) ||
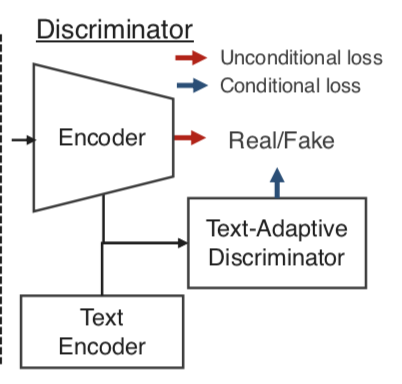
Text-adaptive discriminator
Figure 2 (b) が Text-adaptive discriminator.
generator と同様に,discriminator も text encoder (bidirectional GRU) を同時に学習する.
ここで, $i$ 番目の単語をエンコードした word vector $w_i$ を入力とする 1D sigmoid local discriminator $f_{w_i}$ を導入する.
f_{w_i} = \sigma(W(w_i) \cdot v + b(w_i))
$W(w_i), b(w_i)$ は $w_i$ に依存する重みとバイアス.
$v$ は image encoder の出力に global average pooling を適用して計算した 1D image vector.
word ごとの attention $\alpha_i$ は,
\alpha_i = \frac{\exp{(u^Tw_i)}}{\sum_i \exp{(u^Tw_i)}}
で計算する($u$ は $w_i$ の時間平均(?))
$x, t$ が与えられたときの最終的な discriminator の出力 $D(x, t)$ は
D(x, t) = \prod_{i=1}^T\bigl[f_{w_i}(v)\bigr]^{\alpha_i}
$T$ はテキスト中の単語数.
さらに,複数スケールの画像特徴を考慮するために,以下のように書き換え.
D(x, t) = \prod_{i=1}^T \bigl[
\sum_j \beta_{ij} \ f_{w_i, \ j}(v_j) \bigr]^{\alpha_i}
$v_j$ は image encoder の $j$ 層目の image vector,$\beta_{ij}$ は $j$ 層目の $w_i$ の softmax weight.
ここまでで定義した $D(x, t)$ を text-conditional loss とする.
GAN objective
目的関数は,
- unconditional adversarial loss $D(x)$
- text-conditional loss $D(x, \hat{t})$
- reconstruction loss $L_{rec}$
で構成される.
L_D = \mathbb E_{x, t, \hat{t} \sim p_{data}} \bigl[ \log{D(x) + \lambda_1(\log{D(x, t) + \log{(1 - D(x, \hat{t}))}})}\bigr] \\
+ \mathbb E_{x, \hat{t}\sim p_{data}} \bigl[ \log{(1 - D(G(x, \hat{t})))}\bigr]
L_G = \mathbb E_{x, \hat{t}\sim p_{data}} \bigl[ \log{D(x)} + \lambda_1 \log{D(G(x, \hat{t}), \hat{t})}\bigr] + \lambda_2 L_{rec}
$L_D$ に $D(G(x, \hat{t}), \hat{t})$ が無いのは,学習の安定化のため.
$L_D, L_G$ を最大化するように学習(のはず).
どうやって有効性を検証したか
-
Dataset
-
Baseline methods
Quantitative results
Human evaluation.
test set から 10枚の画像と 10個のテキストを選び,2つのデータセットから100枚ずつ(計200枚)の画像を生成.
20人に評価してもらい,3つの手法に順位を付けてもらう.
Worker には2つの基準で評価してもらう.
- Accuracy
- whether the visual attributes (colors, textures) of the manipulated image match the text, and the background irrelevant to the text is preserved
- Naturalness
- whether the manipulated image looks natural
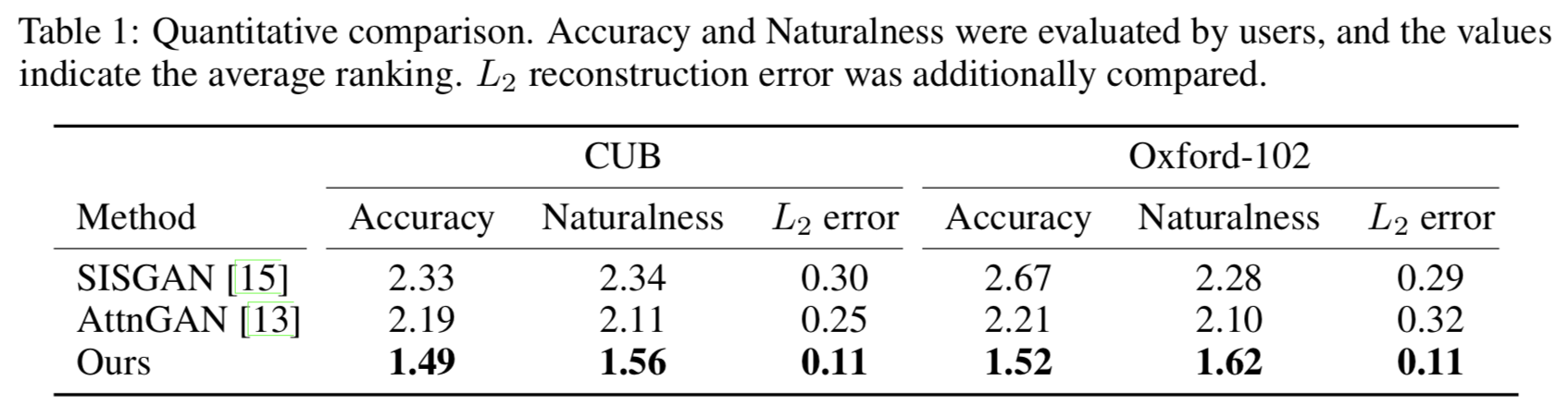
以下は Human evaluation の結果.
AccuracyとNaturalnessは各手法の平均順位.
$L_2$ reconstruction error は「オリジナル画像」と「オリジナル画像とpositive textを入力した時の生成画像」の $L_2$ error.
どの指標,データセットにおいても提案手法が最も好まれていることが分かる.
Qualitative results
以下は提案手法による生成画像.
テキストに従った的確な変化が加えられている.

以下は従来手法との比較.
どちらの従来手法もオリジナル画像のポーズとレイアウトを保持できているが,テキストで言及されていないコンテンツが保持されない傾向がある.
一方で提案手法では,的確な属性の変更が加えられ,テキストで言及されていないコンテンツについては保持されていることが分かる.
右端は失敗例で,テキストで新たなshapeの記述がされている.
「オリジナルのコンテントを保持すること」と「新たなコンテンツを生成すること」が trade-off の関係にあるからだと述べている.

Component analysis
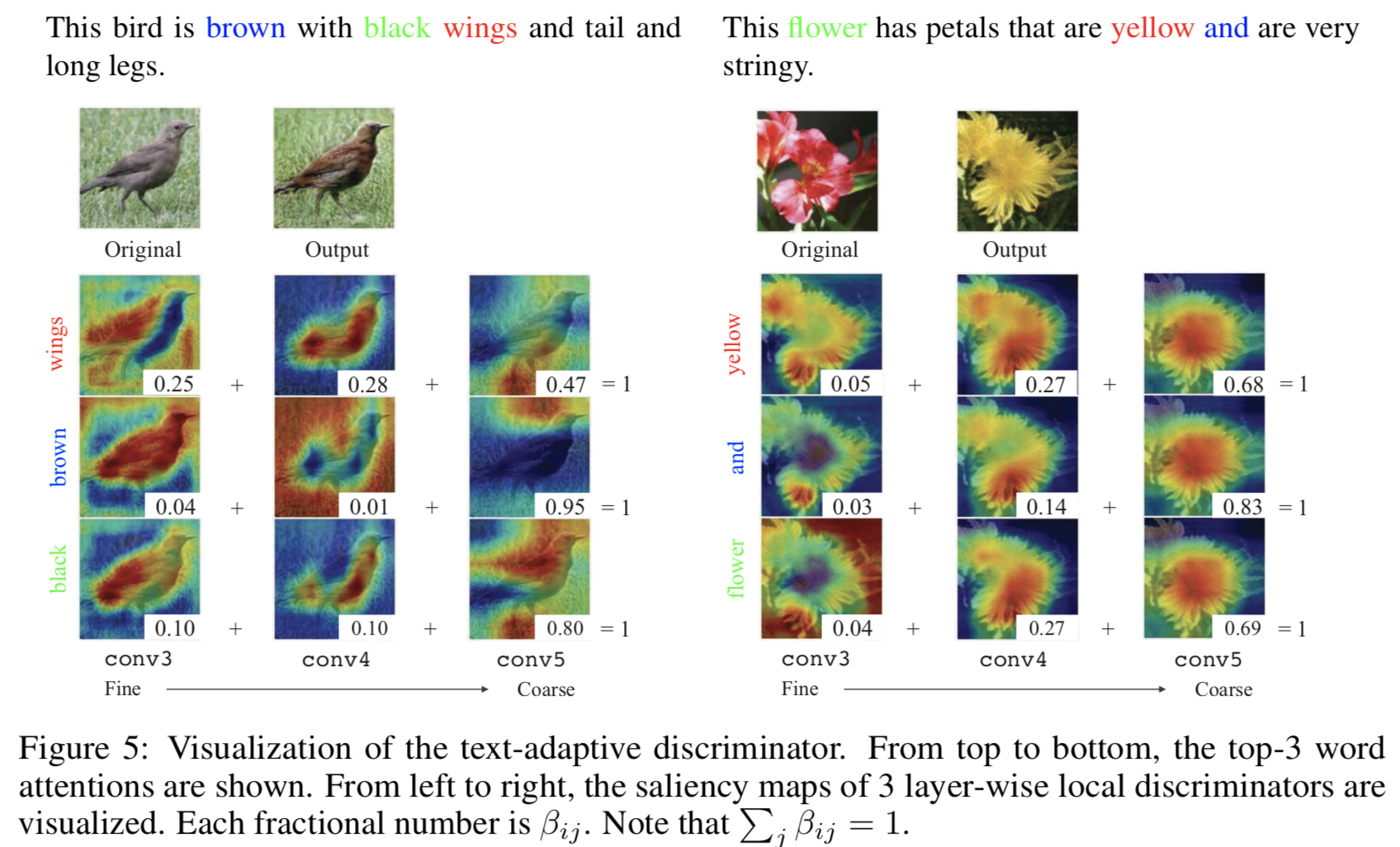
以下は local discriminator の saliency map を Class Activation Maps (CAMs) [31] で可視化したもの.
3つの畳み込み層における top-3 の word attentions を可視化している.
この画像から,テキスト内の視覚属性とそれに対応してどの層における情報に重きを置くかを学習していることが分かる.
以下が text-conditional loss に使用する畳み込み層を変更した場合の比較.
conv3, 4, 5と異なるレベルの情報(疎な情報からきめ細かな情報まで)を用いた場合が最も良いことが分かる.

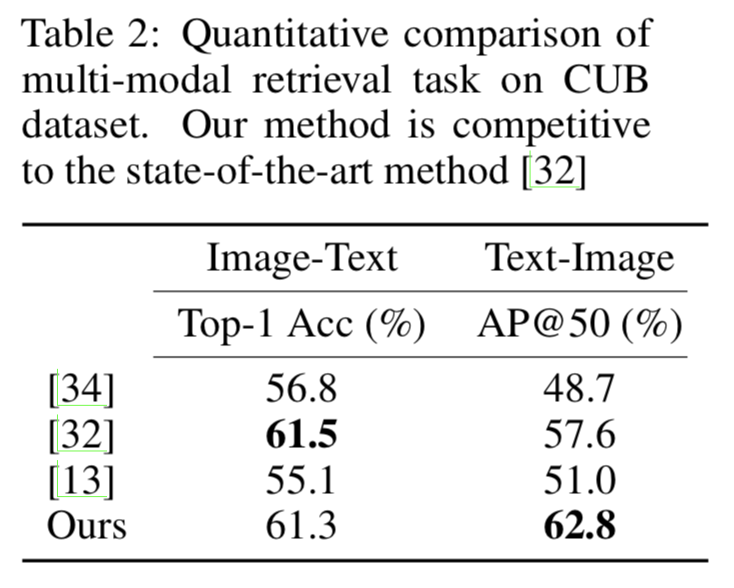
以下の表は,CUB dataset における top-1 の image-to-text retrieval accuracy (Top-1 Acc) と top-50 の text-to-image retrieval results (AP@50) の結果.
text-to-image で特に大幅な向上が見られるが,これは word-level の discriminator と そこでmulti-scale layers を使用していることによるらしい.
最後に,異なる2つのテキストのベクトル間を補完し,画像を生成した結果.
オリジナル画像のコンテンツは保持したまま,妥当な画像が生成されていることが分かる.

議論はあるか
- 画像とテキストを入力とし,テキストの属性をもつ画像に修正するGAN, TAGAN (Text-Adaptive Generative Adversarial Network) を提案
- word-level local discriminators を使用することで,テキストからきめ細かな視覚属性を得られるように学習が可能
- 提案手法では,テキストで言及されていない部分はオリジナルのコンテンツを保持したまま修正を加えることが可能
次に読む論文
- Person Re-identification に GAN を使用した論文