Tao Xu, Pengchuan Zhang, Qiuyuan Huang, Han Zhang, Zhe Gan, Xiaolei Huang, Xiaodong He
CVPR2018
pdf, arXiv, github
どんなもの?
テキストから画像を生成するGAN, AttnGANを提案.
単語レベルのアテンションと複数回のrefineで,より詳細な画像を生成する.

先行研究との差分
- AttnGANにおける重要な2つの要素であるattentional generative networkとDeep Attentional Multimodal Similarity model (DAMSM)を提案
- state-of-the-artのGAN modelsを超える性能
- AttnGANのattention layersで単語レベルのアテンションを可能に
技術や手法のキモ
Attentional Generative Network
テキストから段階的に画像を生成する.
Attentional Generative Network内の $F^{ca}$, $F^{attn}_i$, $F_i$, $G_i$ はneural networks.
$F^{ca}$はConditioning Augmentation [36] .
図中の"Attention models"の説明は無かったが,おそらく複数の$F^{attn}_i$を差すだけで特に意味は無いと思う.
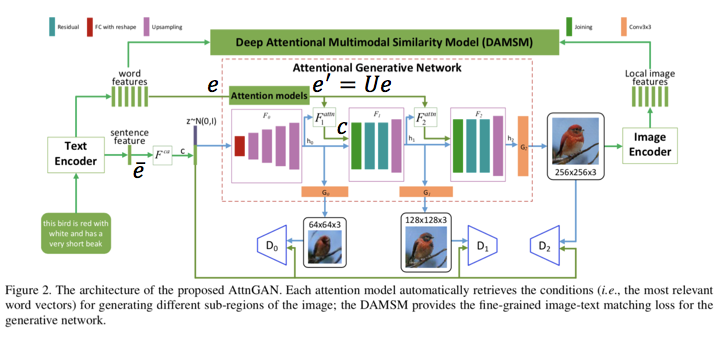
※論文中Figure2を加工
$F$の出力$h$のcolumnは画像のsub-regionの特徴ベクトルに相当する.
$D$ : dimension of the word vector
$\hat D$ : $U \in \mathbb{R}^{\hat D \times D}$によって,$e$は$e^{'} \in \mathbb{R}^{\hat D \times T}$に射影
$N$ : $h \in \mathbb{R}^{\hat D \times N}$
$T$ : number of words
F^{attn}(e, h) = (c_0, c_1, \cdots, c_{N-1}) \\
c_j = \sum_{i=0}^{T-1}\beta_{j, i}e_{i}^{'}, \beta_{j, i} = \frac{exp(s_{j, i}^{'})}{\sum_{k=1}^{T-1}exp(s_{j, k}^{'})} \\
s_{j, i}^{'} = h_{j}^{T}e_{i}^{'}
ロス関数は以下で定義.
各段階のGANのロスの和($L_G$)になっている.
L = L_G + \lambda L_{DAMSM}, L_G = \sum_{i = 0}^{m-1}L_{G_i}
それぞれ$L_{G_i}$, $L_{D_i}$は以下で定義される.
$x$がreal画像,$\hat x$がfake画像
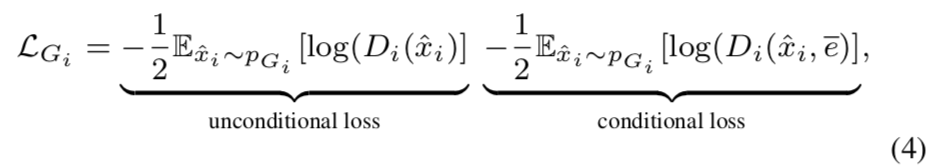

unconditional lossの部分が「画像がreal or fake」に関するロス,conditional lossの部分が「画像と文がmatch or not」に関するロスになるらしい.
Deep Attentional Multimodal Similarity Model (DAMSM)
DAMSMでは画像と文の単語レベルでの類似度を測る.
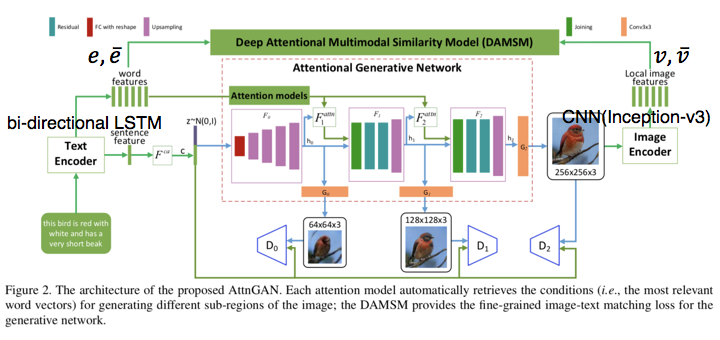
※論文中Figure2を加工
The text encoder
bi-directional LSTMでテキスト特徴にエンコード.
feature matrix of all wordsは
e \in \mathbb{R}^{D \times T}
$D$は特徴ベクトルの次元数,$T$は単語の数.
最後の隠れ状態をconcatenateしてglobal sentence vector $\bar e$とする.
\bar e \in \mathbb{R}^{D}
The image encoder
CNN (Inception-v3)で画像特徴にエンコード.
local feature matrix $f$として"mixed_6e" layerの出力.特徴ベクトルの次元数が768,sub-regionの数が289.(結局sub-regionが何者かよく分からない.画像をいくつかに分割?)
f \in \mathbb{R}^{768 \times 289}
global feature vector $\bar f$として最後の平均値プーリング層の出力.
\bar f \in \mathbb{R}^{2048}
text featureと特徴の次元を合わせるため変換.
v = Wf, \bar v = \bar W \bar f \\
v \in \mathbb{R}^{D \times 289}, \bar v \in \mathbb{R}^{D}
The attention-driven image-text matching score
s = e^Tv \\
\bar s_{i, j} = \frac{exp(s_{i, j})}{\sum_{k=0}^{T-1}exp(s_{k, j})}
$s$で$i$番目の単語と,$j$番目のsub-regionの類似度.$\bar s$は$s$を,単語の数で正規化.
region-context vector $c$を定義.$\gamma_1$は関連するsub-regionの特徴にどれだけアテンションするか具合.
c_i = \sum_{j=0}^{288} \alpha_j v_j, \alpha_j = \frac{exp(\gamma_1\bar s_{i, j})}{\sum_{k=0}^{288} exp(\gamma_1\bar s_{i, k})}
画像全体(Q),テキスト全体(D)のattention-driven image-text matching score $R(Q, D)$を定義.右辺$R(c_i, e_i)$はコサイン類似度.$gamma_2$は関連度の強いペア(wordとregion)をどれだけ強調するか具合.
R(Q, D) = log(\sum_{i=1}^{T-1}exp(\gamma_2 R(c_i, e_i)))^{\frac{1}{\gamma_2}}
文章$D_i$が画像$Q_i$とmatchingする事後確率は
P(D_i | Q_i) = \frac{exp(\gamma_3R(Q_i, D_i))}{\sum_{j=1}^{M} exp(\gamma_3R(Q_i, D_i))}
$\gamma_3$はsmoothing factor.
ロス関数は以下のようになる.$w$はwordの意.
L_1^w = -\sum_{i=1}^Mlog P(D_i | Q_i)
L_2^w = -\sum_{i=1}^Mlog P(Q_i | D_i)
sentence vector $\bar e$, global image vector $\bar v$においても以上の計算を同様に行い,$L_1^s, L_2^s$を求める.$s$はsentenceの意.
最終的なDAMSMのロス関数は
L_{DAMSM} = L_1^w + L_2^w + L_1^s + L_2^s
どうやって有効性を検証したか
attentional generative network, DAMSMの有効性の検証,従来手法との比較.
使用したデータセットは以下の2つ.
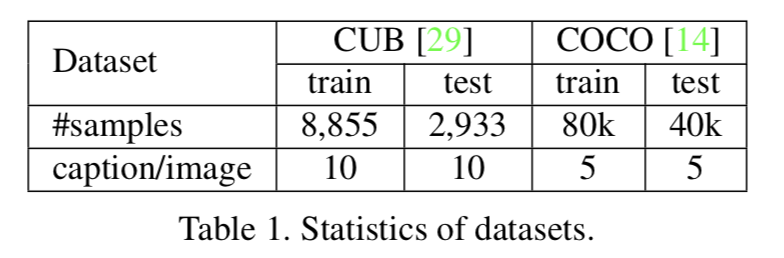
評価指標はInception scoreとR-precision (r/R).R-precisionは情報検索の評価でよく用いられ,R個の検索結果に占める,関連する検索結果r個の割合.
Component analysis
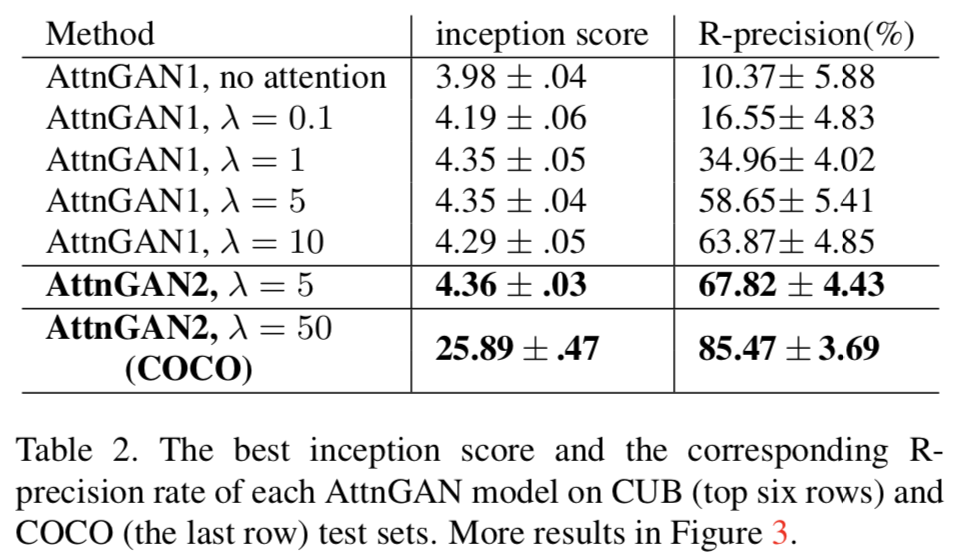
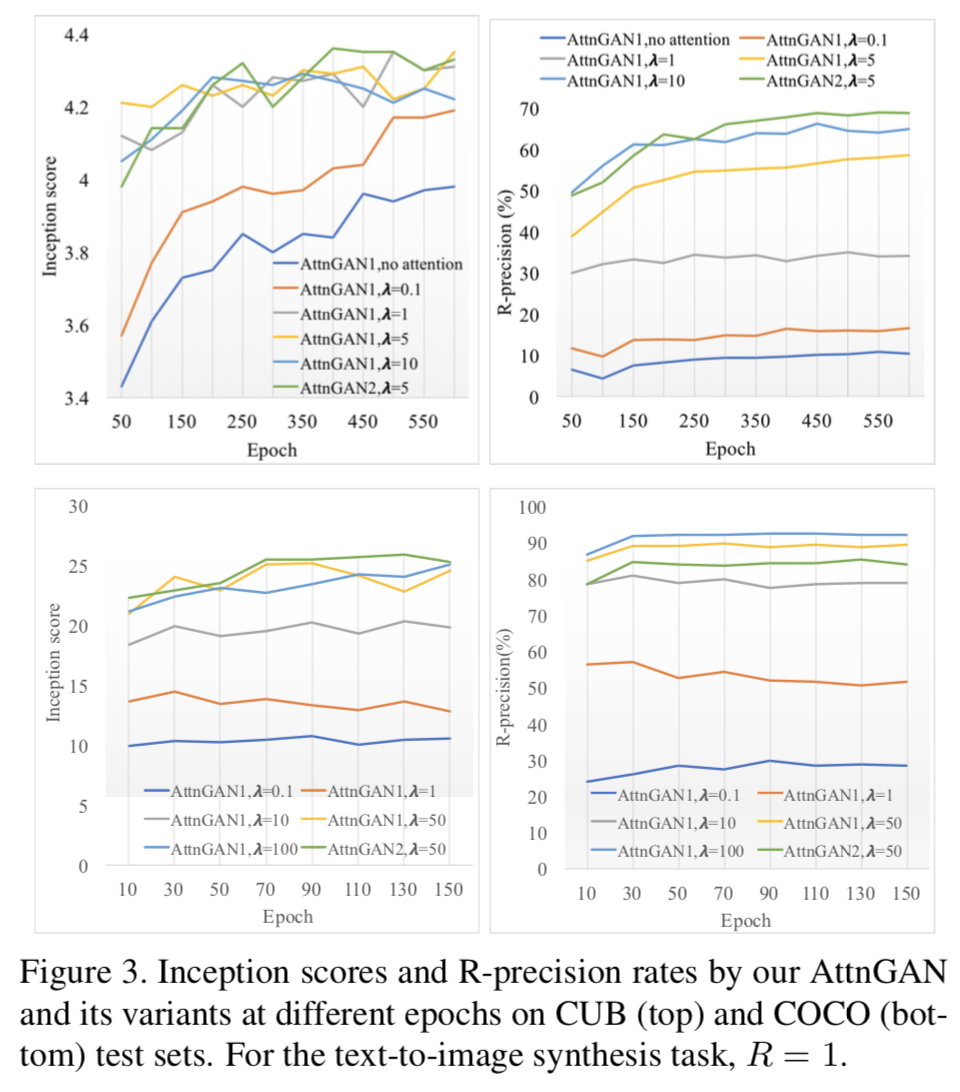
表の上から6行がCUB dataset,最後の1行がCOCO datasetに対する結果.
"AttnGAN1" : 1 attention model, 2 generators
"AttnGAN2" : 2 attention model, 3 generators (Figure 2)
$\lambda$は全ロスに占める$L_{DAMSM}$の大きさを操作するパラメータ.
- $\lambda$を大きくするほどスコアが高くなる
- 複数のattention model, generatorをstackするほど良い結果
- attentionは必要
上がCUB dataset,下がCOCO datasetの結果.
画像はgenerator0 ~ 2の出力とattention1, 2の可視化結果.
- 初めは大雑把な(形や色だけ捉えた)画像を生成し,徐々にrefine
- 左上の"black"のように,attention1と2で異なる単語に注目できている(これにより,より解像度の高い画像を出力するのに重要な単語が捉えられている)
- 右下のkiwi, bananaのように,異なるsub-regionに注目できている(テキストの持つ意味が学習できている?)

注目度の高い単語を入れ替えてみた結果.

現実には起こりそうにないテキストを入力した結果.

sharpで詳細な画像だが,現実にはあり得なさそうな出力結果(複数の頭,目,尻尾).
この結果から,まだ完璧にはグローバルな一貫した構造を捉えられていないことが分かる.

Comparison with previous methods
- どの比較手法よりも良いスコアが得られた
- 特にCOCO datasetの結果から,提案手法はattentionによってより詳細な単語レベル,sub-regionレベルで情報を捉えることができ,より複雑なシーンの生成ができている

議論はあるか
- テキストから画像を生成するGAN, AttnGANを提案
- attention, multi-stage processで高い質の画像を生成できる
- 提案したDAMSMロスが有効だった
- CUB dataset, COCO datasetで state-of-the-artの結果を上回った
- 4.1の結果のように,グローバルで一貫した構造が捉えきれていないところに改良の余地がある
次に読むべき論文
フォントのstyle transfer
Multi-Content GAN for Few-Shot Font Style Transfer