Taesung Park, Ming-Yu Liu, Ting-Chun Wang, Jun-Yan Zhu
UC Berkeley, NVIDIA, MIT CSAIL
CVPR2019
arXiv, pdf, GitHub, project page, YouTube, GauGAN記事
gigazineでインタラクティブなソフトウェア「GauGAN」が紹介されていたので,その元論文を読んでみました.


どんなもの?
画像生成のための新しい conditional normalization 手法,SPatially-Adaptive (DE)normalization (SPADE) を提案.
segmentation mask からの画像生成タスクで,pix2pixHD(前回記事)を上回る成果.

先行研究との差分
- 新たな正規化手法を提案
- 提案するSPADE generator は一般的なencoder decoder networkではなく,decoder部分のみで構成される
技術や手法のキモ
SPADE generator
提案するSPADE generator では segmentation mask を各スケールにダウンサンプリングしてからそれぞれの SPADE Residual block に入力する.
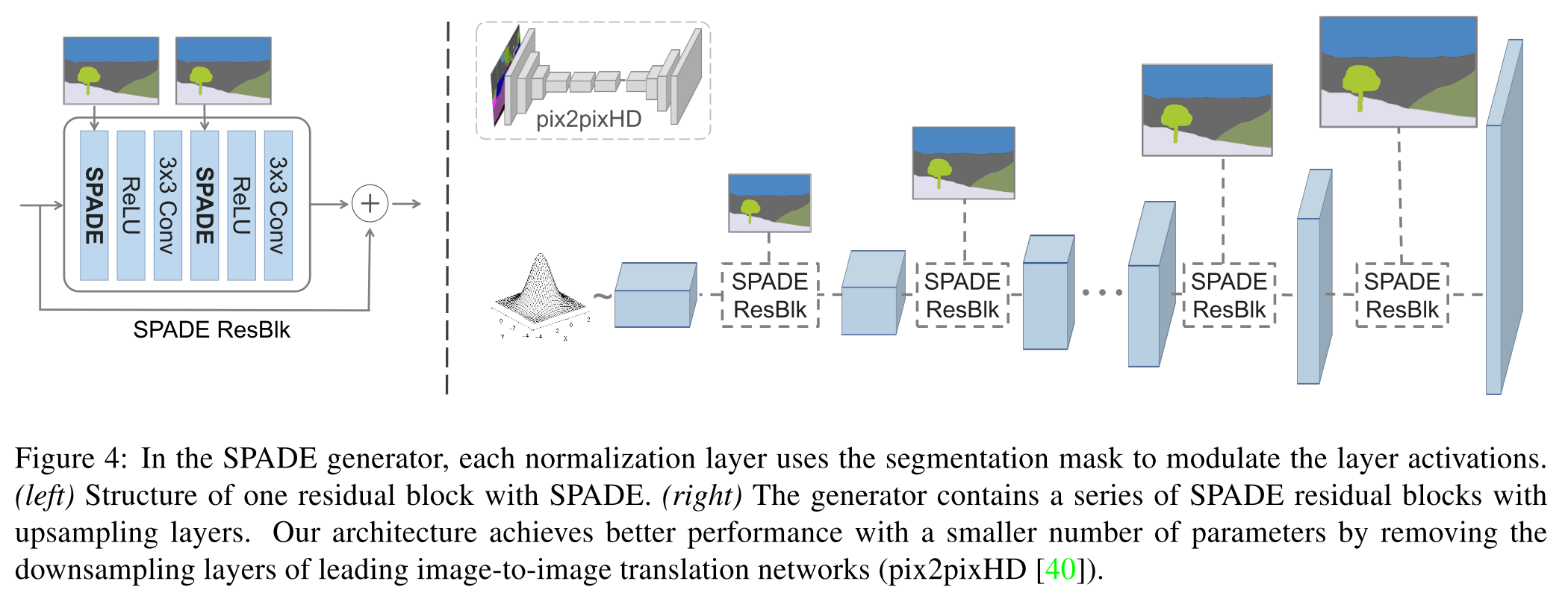
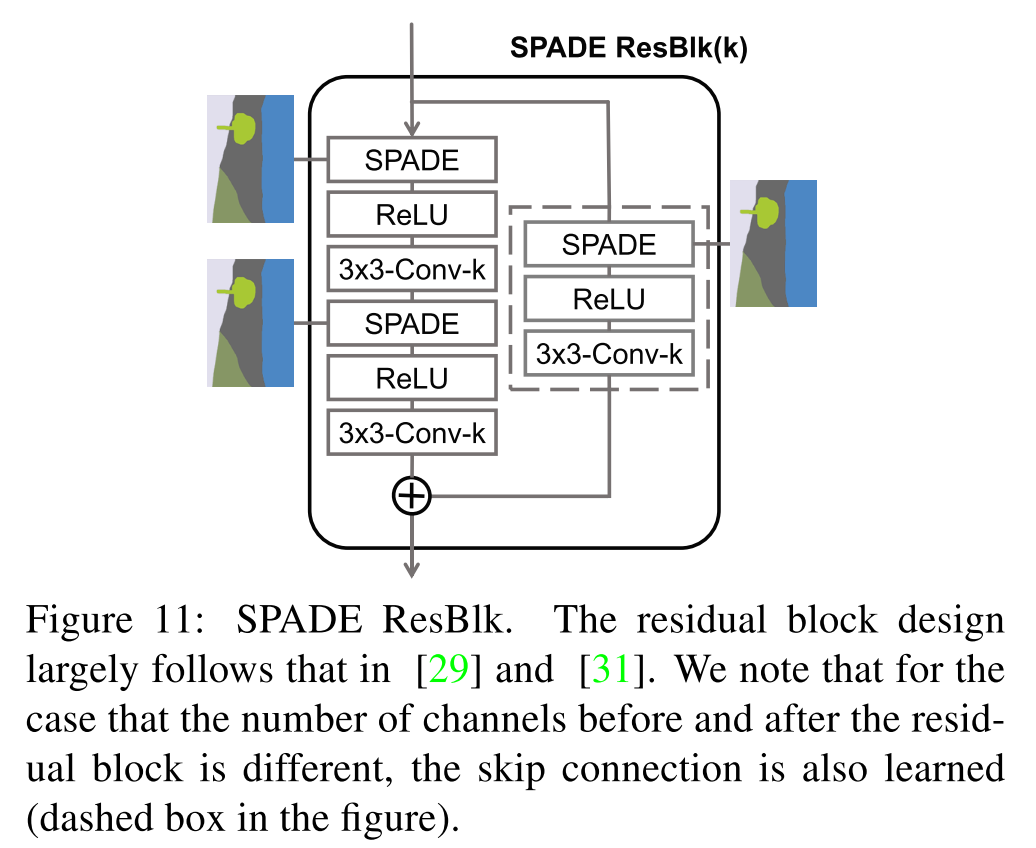
SPADE Residual block の内部と SPADE は以下のような構造になっている.(SPADE の説明は後ほど)
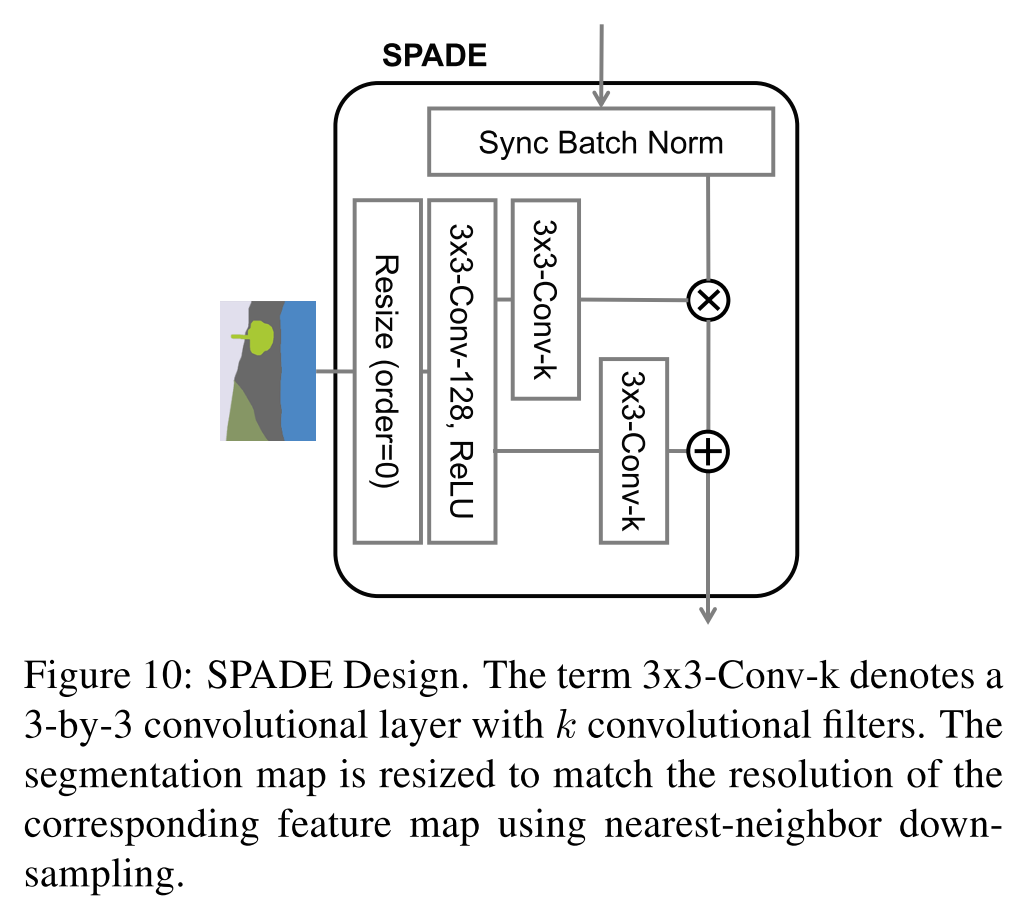
Spatially-adaptive denormalization
提案する SPADE の模式図は以下.
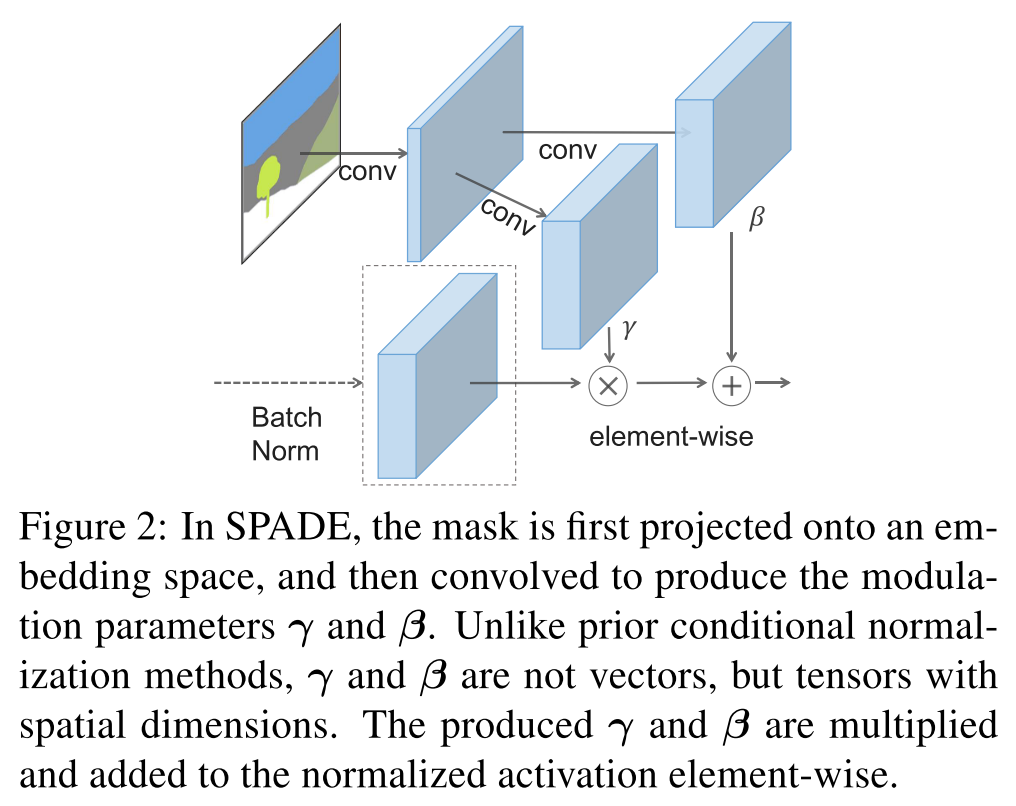
segmentation mask に対して初めのconvでembedding space に射影し,後のconvで $\gamma, \beta$ を計算する.この $\gamma, \beta$ はテンソルで表現される.
$h^i$ を $i$ 番目の層の activation,バッチサイズ $N$,特徴マップのチャネル数,縦,横の大きさを $C^i, H^i, W^i$ として,segmentation mask $m$ を入力したときの $n, c, y, x$ ($n\in N, c\in C^i, y\in H^i, x\in W^i$)の activation は以下の式で表される.
\gamma_{c, y, x}^{i}(\mathbf{m}) \frac{h_{n, c, y, x}^{i}-\mu_{c}^{i}}{\sigma_{c}^{i}}+\beta_{c, y, x}^{i}(\mathbf{m})
$\gamma_{c, y, x}^{i}, \beta_{c, y, x}^{i}$は segmentation maskから scaling $\gamma$, bias $\beta$ を計算する2層のconv.
$\mu_{c}^{i}, \sigma_{c}^{i}$ はそれぞれ以下の式で表される.
\begin{aligned}
\mu_{c}^{i} &= \frac{1}{N H^{i} W^{i}} \sum_{n, y, x} h_{n, c, y, x}^{i} \\ \sigma_{c}^{i} &= \sqrt{\frac{1}{N H^{i} W^{i}} \sum_{n, y, x}\left(h_{n, c, y, x}^{i}\right)^{2}-\left(\mu_{c}^{i}\right)^{2}}
\end{aligned}
Figure 2中のBatch Norm は Spectral Normalization [30]を指す.
SPADE は従来の normalization と比べて semantic information を保持することができるらしく,以下の Figure 3のようにクラスが一様な segmentation mask を入力した際に違いが現れる.

どうやって有効性を検証したか
Datasets
- COCO-Stuff [5]
- 118,000 for train, 5,000 for validation
- ADE20K [48]
- 20,210 for train, 2,000 for validation
- ADE20K-outdoor
- Subset of the ADE20K
- Cityscapes dataset [8]
- 3,000 for train, 500 for validation
- Flickr Landscapes
- 40,000 for train, 1,000 for validation
Performance metrics
生成した画像に対してセマンティックセグメンテーションを行い,その
- mean IoU
- pixel accuracy
で比較する.
セグメンテーションのモデルとして,
を使用する.
また,学習した分布の距離の指標である
- Frechet Inception Distance (FID) [15]
でも比較する.
Baselines
生成結果は
- pix2pixHD model [40,前回記事]
- cascaded refinement network model (CRN) [7]
- semi-parametric image synthesis model (SIMS) [35]
と比較.
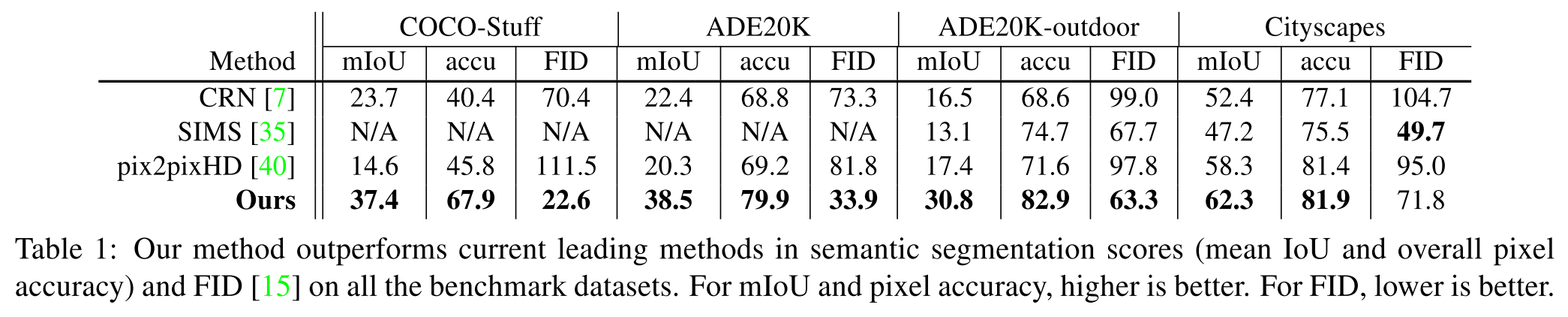
Quantitative comparisons
以下は定量的な結果をまとめたもの.
どの評価指標においても提案手法ではより良い結果が得られている.
COCO-Stuff における mIoU では SOTA と比べて 1.5倍,FID においては 2.2倍向上している.
Qualitative results
以下の Figure 5, 6 はそれぞれのデータセットにおける生成結果.
提案手法では多様なシーンが含まれている COCO-Stuff と ADE20K においてアーティファクトが少なくなり,画像の質が特に向上したらしい.


以下の Figure 7, 8 は Flickr Landscape と COCO-Stuff を用いた様々な生成結果例.
提案手法では多様なシーンが忠実に再現できていることが分かる.


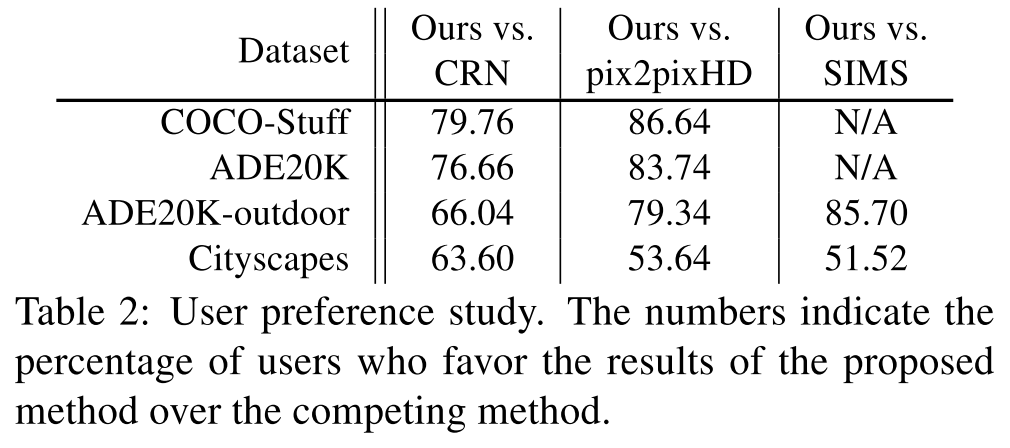
Human evaluation
以下は人間にどちらのモデルで生成した画像が好ましいかを選んでもらった結果.
どのデータセットでも提案手法が好ましいと選ばれているが,とりわけチャレンジングなデータセットである COCO-Stuff と ADE20K において際立っている.
The effectiveness of SPADE
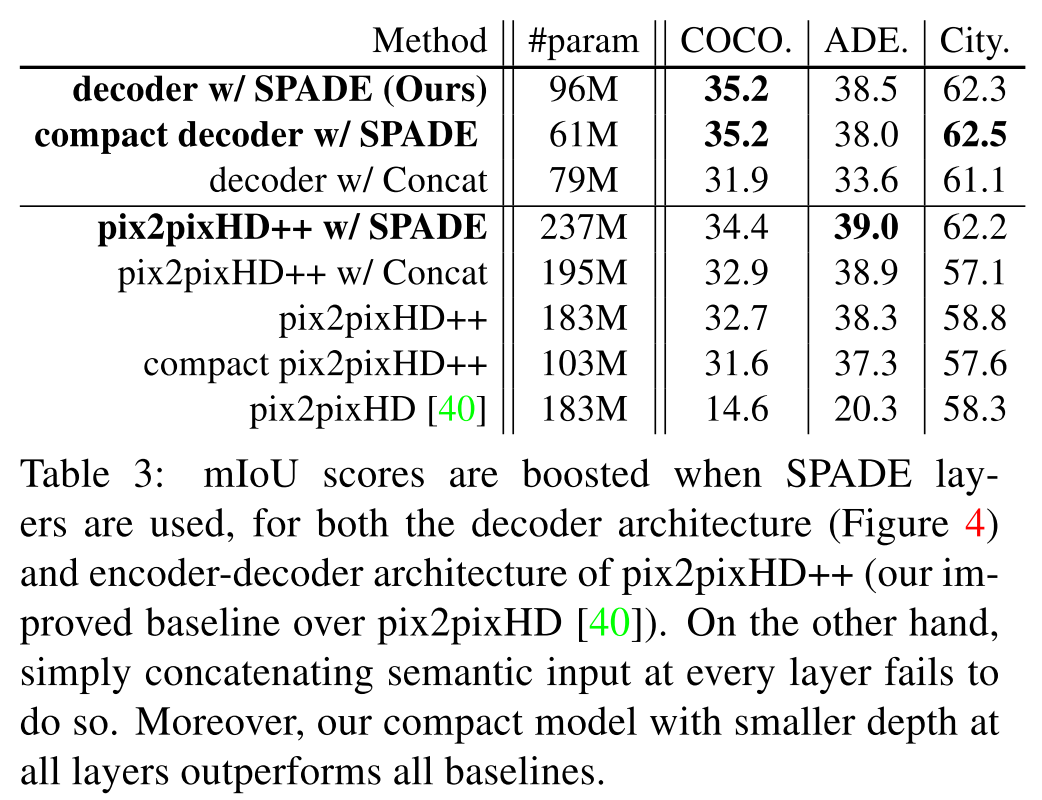
以下の Table 3 は微妙に変化,例えば
- pix2pixHD に様々な enhancement を加えたもの(pix2pixHD++)
- pix2pixHD++ に concatenate で segmentation mask を入力したもの(pix2pixHD++ w/ Concat)
- pix2pixHD++ に SPADE でsegmentation mask を入力したもの(pix2pixHD++ w/ SPADE)
- generator の conv filter の数を変化させたもの(compact ~)
と提案手法(decoder w/ SPADE)を比較した結果をまとめたもの.
表の上側が decoder-style architecture,下側が encoder-decoder architecture.
どちらの architecture においても,SPADEを用いたものの性能が大きく上回っていることが分かる.
この表から
- segmentation mask の concatenate と SPADE とでは,異なる結果につながる
- decoder-style SPADE generator のコンパクトモデル(compact decoder w/ SPADE)でも比較手法を上回る
ということが分かる.
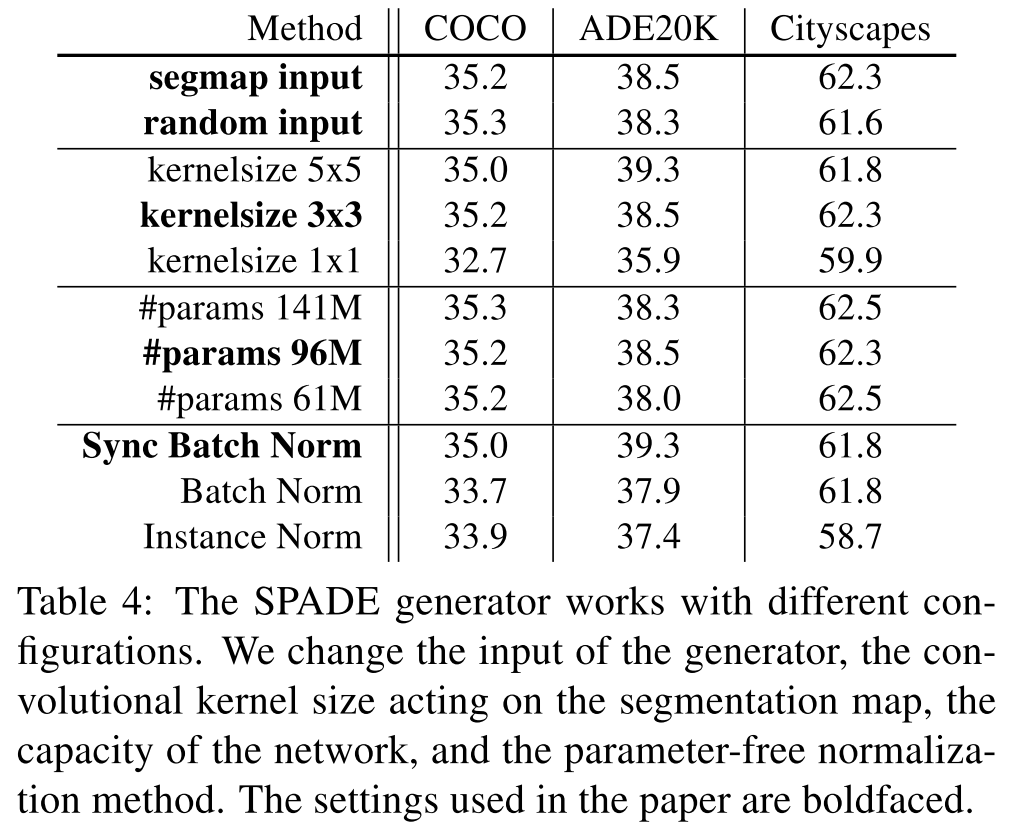
Variations of SPADE generator
以下の Table 4 は様々な要素,パラメータを変化させた場合の結果.
提案手法では表中の太字の要素が採用されている.
Multi-modal synthesis
以下の Figure 9 は multimodal image synthesis の結果.
同じ segmentation mask を入力しても,異なるノイズをサンプリングするため,様々な生成画像が得られる.

議論はあるか
- spatially-adaptive normalization を提案
- 提案した生成モデルでは indoor, outdoor, landscape, street scenes など多様なシーンの photorealistic な画像が生成できる
- multi-modal synthesis, guided image synthesis に応用可能